机器学习——利用PCA来简化数据
降维技术的好处:
1.使得数据集更易使用
2.降低很多算法的计算开销
3.取出噪声
4.使得结果易懂
在已标注和未标注的数据上都有降维技术,降维的方法:
1.主成分分析(Principal Component Analysis,PCA)。在PCA中,数据从原来的坐标系转换到新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差的方向。该过程中一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此,我们就可以忽略余下的坐标轴,即对数据进行了降维处理。
2.因子分析(Factor Analysis)。在因子分析中,我们假设在观察数据的生成中有一些观察不到的隐变量(latent variable)。假设观察数据是这些隐变量和某些噪声的线性组合。那么隐变量的数据可能比观察数据的数目少,也就是说通过找到隐变量就可以实现数据的降维。
3.独立成分分析(Independent Component Analysis,ICA)。ICA假设数据是从N个数据源生成的,这一点和因子分析有些类似。假设数据为多个数据源的混合观察结果,这些数据源之间在统计上相互独立的,而在PCA中只假设数据是不相关的。同因子分析一样,如果数据源的数目少于观察数据的数目,则可以实现降维过程。
主成分分析
优点:降低数据的复杂度,识别最重要的多个特征
缺点:不一定需要,且可能损失有用信息
适用数据类型:数值型数据
对于下图中的二维数据,这个二维数据是随机生成的
# coding:utf-8
# !/usr/bin/env python '''
Created on Jun 1, 2011 @author: Peter
'''
from numpy import *
import matplotlib
import matplotlib.pyplot as plt n = 1000 #number of points to create
xcord0 = []
ycord0 = []
xcord1 = []
ycord1 = []
markers =[]
colors =[]
fw = open('testSet.txt','w')
for i in range(n):
[r0,r1] = random.standard_normal(2) #随机生成一组二维数据(fFlyer,tats)
fFlyer = r0 + 9.0
tats = 1.0*r1 + fFlyer + 0
xcord0.append(fFlyer)
ycord0.append(tats)
fw.write("%f\t%f\n" % (fFlyer, tats)) #将二维数据(fFlyer,tats)写入文件中 fw.close()
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord0,ycord0, marker='^', s=90)
plt.xlabel('hours of direct sunlight')
plt.ylabel('liters of water')
plt.show()
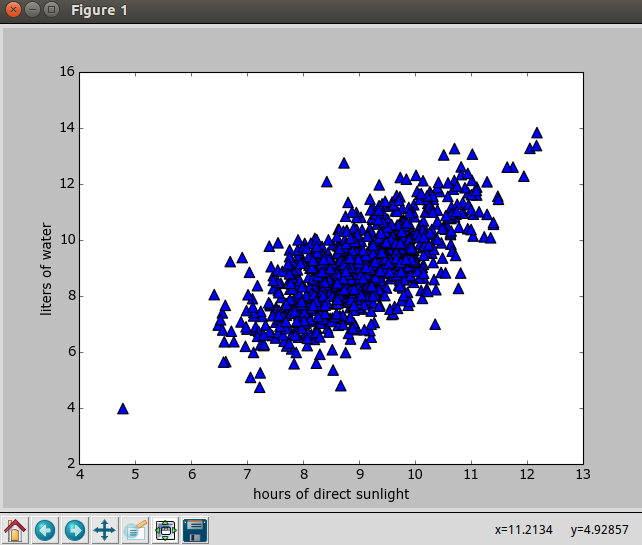
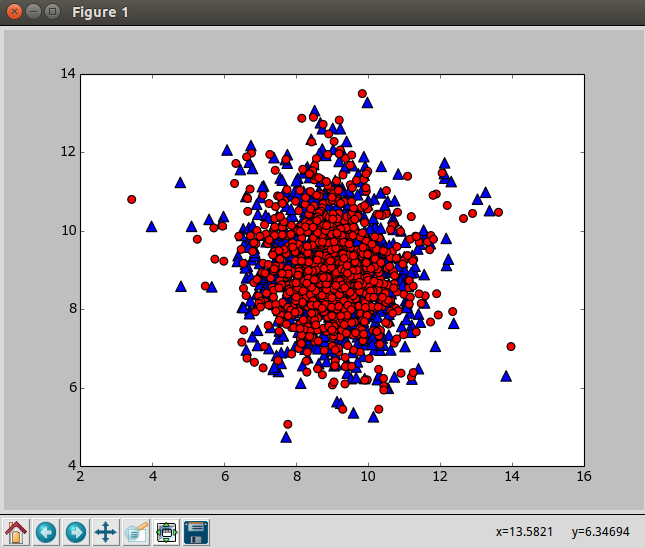
使用下面的程序对二维数据进行主成分分析,输出原始数据重构之后的矩阵lowDDataMat(蓝色),第一主成分reconMat(红色)
def pca(dataMat, topNfeat=9999999): #数据矩阵, 输出前topNfeat个特征,如果topNfeat=1就是降维成1维
meanVals = mean(dataMat, axis=0) #求平均值
meanRemoved = dataMat - meanVals #去除平均值
covMat = cov(meanRemoved, rowvar=0) #计算协方差矩阵
eigVals,eigVects = linalg.eig(mat(covMat)) #计算协方差矩阵的特征值和特征向量
eigValInd = argsort(eigVals) #排序, 找出特征值大的. 其实就是与其他的变化最不相符
eigValInd = eigValInd[:-(topNfeat+1):-1] #保留最上面的N个特征
redEigVects = eigVects[:,eigValInd] #保留最上面的N个特征向量
lowDDataMat = meanRemoved * redEigVects #将数据转换到上述N个特征向量构建的新空间中
reconMat = (lowDDataMat * redEigVects.T) + meanVals
return lowDDataMat, reconMat #lowDDataMat是原始数据重构之后的矩阵(蓝色),reconMat是第一主成分(红色)
# coding:utf-8
# !/usr/bin/env python '''
Created on Jun 1, 2011 @author: Peter
'''
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
import pca dataMat = pca.loadDataSet('testSet.txt')
lowDMat, reconMat = pca.pca(dataMat, 1) #lowDDataMat是原始数据重构之后的矩阵(蓝色),reconMat是第一主成分(红色) fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(dataMat[:,0], dataMat[:,1], marker='^', s=90)
ax.scatter(reconMat[:,0], reconMat[:,1], marker='o', s=50, c='red')
plt.show()
# coding:utf-8
# !/usr/bin/env python '''
Created on Jun 1, 2011 @author: Peter
'''
from numpy import *
import matplotlib
import matplotlib.pyplot as plt
import pca n = 1000 #number of points to create
xcord0 = []; ycord0 = []
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
markers =[]
colors =[]
fw = open('testSet3.txt','w')
for i in range(n): #随机生成1000个二维数据,这1000个二维数据会被标记上0/1/2三个标签
groupNum = int(3*random.uniform())
[r0,r1] = random.standard_normal(2)
if groupNum == 0:
x = r0 + 16.0
y = 1.0*r1 + x
xcord0.append(x)
ycord0.append(y)
elif groupNum == 1:
x = r0 + 8.0
y = 1.0*r1 + x
xcord1.append(x)
ycord1.append(y)
elif groupNum == 2:
x = r0 + 0.0
y = 1.0*r1 + x
xcord2.append(x)
ycord2.append(y)
fw.write("%f\t%f\t%d\n" % (x, y, groupNum)) fw.close()
fig = plt.figure() ax = fig.add_subplot(211) #第一幅图
ax.scatter(xcord0,ycord0, marker='^', s=90)
ax.scatter(xcord1,ycord1, marker='o', s=50, c='red')
ax.scatter(xcord2,ycord2, marker='v', s=50, c='yellow') ax = fig.add_subplot(212) #第二幅图
myDat = pca.loadDataSet('testSet3.txt')
#myDat是(100,3),降维之后lowDDat是(100,1)
lowDDat,reconDat = pca.pca(myDat[:,0:2],1) #lowDDat是原始数据重构降维之后的矩阵,reconDat是第一主成分
label0Mat = lowDDat[nonzero(myDat[:,2]==0)[0],:2][0] #get the items with label 0
label1Mat = lowDDat[nonzero(myDat[:,2]==1)[0],:2][0] #get the items with label 1
label2Mat = lowDDat[nonzero(myDat[:,2]==2)[0],:2][0] #get the items with label 2 #ax.scatter(label0Mat[:,0],label0Mat[:,1], marker='^', s=90)
#ax.scatter(label1Mat[:,0],label1Mat[:,1], marker='o', s=50, c='red')
#ax.scatter(label2Mat[:,0],label2Mat[:,1], marker='v', s=50, c='yellow')
ax.scatter(label0Mat[:,0].flatten().A[0],zeros(shape(label0Mat)[0]), marker='^', s=90)
ax.scatter(label1Mat[:,0].flatten().A[0],zeros(shape(label1Mat)[0]), marker='o', s=50, c='red')
ax.scatter(label2Mat[:,0].flatten().A[0],zeros(shape(label2Mat)[0]), marker='v', s=50, c='yellow')
plt.show()
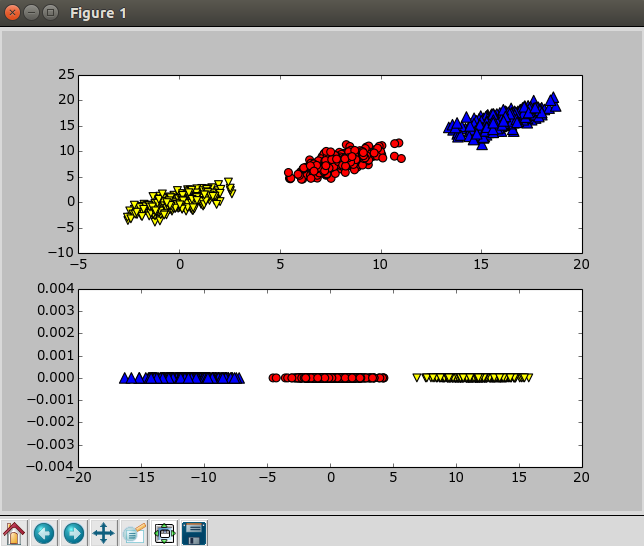
PCA可以从数据中识别其主要特征,它是通过沿着数据最大方差方向旋转坐标轴来实现的。选择方差最大的方向作为第一条坐标轴,后续坐标轴则与前面的坐标轴正交。协方差矩阵上的特征值分析可以用一系列的正交坐标轴来获取。
机器学习——利用PCA来简化数据的更多相关文章
- 机器学习实战 - 读书笔记(13) - 利用PCA来简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第13章 - 利用PCA来简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. ...
- 【机器学习实战】第13章 利用 PCA 来简化数据
第13章 利用 PCA 来简化数据 降维技术 场景 我们正通过电视观看体育比赛,在电视的显示器上有一个球. 显示器大概包含了100万像素点,而球则可能是由较少的像素点组成,例如说一千个像素点. 人们实 ...
- 《机器学习实战》学习笔记第十三章 —— 利用PCA来简化数据
相关博文: 吴恩达机器学习笔记(八) —— 降维与主成分分析法(PCA) 主成分分析(PCA)的推导与解释 主要内容: 一.向量內积的几何意义 二.基的变换 三.协方差矩阵 四.PCA求解 一.向量內 ...
- 利用PCA来简化数据
13.2.2 在NUmpy中实现PCA 将数据转换成前N个主成分的伪代码大致如下: 去除平均值 计算协方差矩阵 计算协方差矩阵的特征值和特征向量 将特征值从大到小排列 保留最上面的N个特征向量 将数据 ...
- 利用主成分分析(PCA)简化数据
一.PCA基础 线性映射(或线性变换),简单的来说就是将高维空间数据投影到低维空间上,那么在数据分析上,我们是将数据的主成分(包含信息量大的维度)保留下来,忽略掉对数据描述不重要的成分.即将主成分维度 ...
- 机器学习:PCA(高维数据映射为低维数据 封装&调用)
一.基础理解 1) PCA 降维的基本原理 寻找另外一个坐标系,新坐标系中的坐标轴以此表示原来样本的重要程度,也就是主成分:取出前 k 个主成分,将数据映射到这 k 个坐标轴上,获得一个低维的数据集. ...
- 《机器学习实战》学习笔记第十四章 —— 利用SVD简化数据
相关博客: 吴恩达机器学习笔记(八) —— 降维与主成分分析法(PCA) <机器学习实战>学习笔记第十三章 —— 利用PCA来简化数据 奇异值分解(SVD)原理与在降维中的应用 机器学习( ...
- 机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据
机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据 关键字:PCA.主成分分析.降维作者:米仓山下时间:2018-11-15机器学习实战(Ma ...
- 机器学习实战 - 读书笔记(14) - 利用SVD简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第14章 - 利用SVD简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. 基 ...
随机推荐
- poj1182(种类并查集好题)
不得不说,我得感谢@驱动幽灵百鬼夜行小肆,正是因为看明白了他给出的解析,我才完全弄懂种类并查集的,这里,我也不想去改其他的,就直接引用他的解题报告吧 转载:http://blog.csdn.net/c ...
- css3 data-attribute属性打造漂亮的按钮
之前介绍了几款css3实现的按钮,今天为网友来款比较新鲜的,用css3的data-attribute属性开发按钮,当鼠标经过显示按钮的详细信息.而且实现过程很简单,几行代码就搞定.大家试一试吧.如下图 ...
- kafka demo
public static void main(String[] args) { Properties props = new Properties(); props.put("bootst ...
- C#中Attribute和Property
XAML是XML派生而来的语言,所以很多XML中的概念在XAML中是通用的. 为了表示同类标签中的某个标签与众不同,可以给它的特征(Attribute)赋值,为特征值赋值的语法如下: 非空标签:< ...
- Linux里提示cannot find -lsocket解决办法
今天在我的Linux make时提示我找不到 -lsocket,我就去lib库里查了一下,根本没有这个东东,然后在网上看了好多都是说缺少这个库要安装,或是要改libsock.so,试了半天都没有用. ...
- dlib实现人脸landmark点检测以及一些其他的应用
首先从中这里下载下代码: https://github.com/ageitgey/face_recognition#face-recognition 然后安装所以必须的组件,我用的Python3.5 ...
- Nexus 7更换NFC控制器,导致不再支持读取Mifare Classic NFC 1k Tags
In a review conducted by Anandtech, it was found that the Nexus 4 makes use of the Broadcom BCM20793 ...
- 用stringr包处理字符串
<Machine Learning for Hackers>一书的合著者John Myles White近日接受了一个访谈.在访谈中他提到了自己在R中常用的几个扩展包,其中包括用ggplo ...
- Python __init__函数的使用
class Cat: def __init__(self,_name): self.name = _name def eat(self): print("i am eating ." ...
- (笔记)Mysql命令update set:修改表中的数据
update set命令用来修改表中的数据. update set命令格式:update 表名 set 字段=新值,… where 条件; 举例如下:mysql> update MyClass ...