关于hadoop集群管理系统搭建的规划说明
Hadoop集群管理系统搭建是每个入门级新手都非常头疼的事情,因为你可能花费了很久的时间在搭建运行环境,最终却不知道什么原因无法创建成功。但对新手来说,运行环境搭建不成功的概率还蛮高的。
在之前的分享文章中给hadoop新手入门推荐的大快搜索DKHadoop发行版,在运行环境安装方面的确要比其他的发行版hadoop要简单的多,毕竟DKHadoop是对底层重新集成封装的,对与研究hadoop尤其是入门级新手来说是非常友好的一个发行版!关于DKHadoop的安装留在后面再给大家分享,本篇就跟大家聊一聊关于Hadoop集群管理系统搭建。
1、分布式机器架构图:
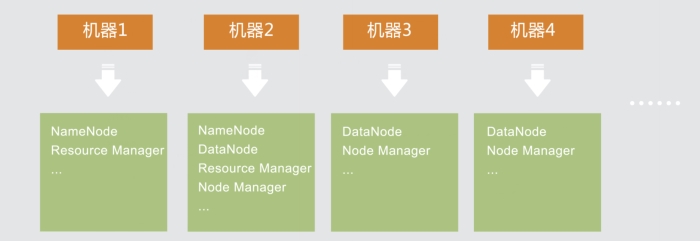
其中机器1主节点,机器2从节点,机器3、机器4等都是计算节点。当主节点宕机后从节点代替主节点工作,正常状态是从节点和计算节点一样工作。这种架构设计保证数据完整性。
首先我们保证每台计算节点上分别有一个DataNode节点和NodeManager节点。因为都是计算节点,真正干活的。在数量上我们要保证。那么NameNode和ResourceManager是两个非常重要的管理者,我们客户端的请求,第一时间与NameNode和ResourceManager打交道。NameNode负责管理HDFS文件系统的元数据,客户端不管是读文件还是写文件,都要首先找到NameNode获取文件的元数据,再进行文件的操作。ResourceManager也是如此,它负责管理集群中的资源和任务调度,你也可以把它视为“大数据操作系统”。客户端能否提交应用并运行,就看你的ResourceManager是否正常。
2、达到多大规模的数据,才值得用大数据的方式来处理?
第一,从数据量角度,但是并无确定的答案,一般定性角度来说,你觉得这个数据量单机处理不了,比如内存限制,时间过久等,就用集群,但是要降低时间,你的处理逻辑必须能分布式处理,定量就是一般数据或者未来的数据量会达到PB级别(可能GB)或以上就要用分布式,当然前提也是你的处理逻辑可以进行分布式。
第二,从算法角度,或者处理逻辑的时间复杂度来说,比如虽然你的数据记录不是很多,但是你的算法或者处理逻辑的时间复杂度是n的平方,甚至更高,同时你的算法可以进行分布式设计,那么就考虑用分布式,比如你的记录虽然只有1w, 但是时间复杂度确是n的平方,那么你想想单机要多久,要是你的算法可以进行分布式处理,那么就考虑用分布式。
3、制约大数据处理能力的几个问题
a、网络带宽
网络是联接计算机的纽带,这个纽带当然越宽越好,这样可以在计算机资源许可的情况下,在单位时间内传输更多的数据,让计算机处理更多的数据。现在企业网络中,普遍采用的多是百兆网络,也有千兆,万兆虽然有,但是用得不多。
b、磁盘
所有数据,不管它从哪里来,最终都要存进不同的硬盘里面,或者闪存盘。闪存盘的读写效率比硬盘高得多,但是缺点也明显:价格贵、容量小。现在的存储介质主要还是硬盘,硬盘有顺序读写和随机读写两种模型。顺序读写是磁头沿着磁道,好象流水线一样,有规律的向前滚动进行。随机读写是磁头跳跃着,找到磁道上留空的地方,把数据写进去。很明显,顺序读写比随机读写效率高,所以系统架构师在设计大数据存储方案时,都是以顺序读写为主要选择。
c、计算机的数量
分布式的集群环境下,计算机的规模当然越大越好。这样在数据等量的情况下,计算机数量越多,分配给每台计算机的数据越少,处理效率自然就高了。但是计算机的数量也不是可以无限增加,集群对计算机规模的容纳有一个峰值,超过这个峰值,再提升就很困难,处理不好还会下降。原因主要来自木桶短板效应、边界效应、规模放大效应。根据多年前的一个测试,当时以Pentium 3和Pentium 4芯片为基础平台,配合100M网络,在上面运行LAXCUS大数据系统。当达到千台计算机的规模时,瓶颈开始显露出来。如果现在用新的X86芯片,加上更高速的网络,应该是能够容纳更多的计算机。
d、代码质量
这不是关键问题,但是是企业必须关注的一个问题。这和程序员编写的计算机代码质量有关。实际上,每个大数据产品都是半成品,它们只是提供了一个计算框架,要实际应用到企业生产中,里面还有大量业务编码需要程序员来实现。要使大数据应用达到高质量,技术负责人要做好前期设计,清楚和规范业务流程,程序员拿到方案后,用统一格式编写代码。这是双方互相配合的过程。或者说,要做好协同和协调的事情。
关于hadoop集群管理系统搭建的规划说明的更多相关文章
- Hadoop集群初步搭建:
自己整理了一下Hadoop集群简易搭建的过程,感谢尚观科技贾老师的授课和指导! 基本环境要求:能联网电脑一台:装有Centos系统的VMware虚拟机:Xmanager Enterprise 5软件. ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群的搭建与配置(2)
对解压过后的文件进行从命名 把"/usr/hadoop"读权限分配给hadoop用户(非常重要) 配置完之后我们要创建一个tmp文件供以后的使用 然后对我们的hadoop进行配置文 ...
- hadoop集群的搭建
hadoop集群的搭建 1.ubuntu 14.04更换成阿里云源 刚刚开始我选择了nat模式,所有可以连通网络,但是不能ping通,我就是想安装一下mysql,因为安装手动安装mysql太麻烦了,然 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- hadoop集群的搭建(分布式安装)
集群 计算机集群是一种计算机系统,他通过一组松散集成的计算机软件和硬件连接起来高度紧密地协同完成计算工作. 集群系统中的单个计算机通常称为节点,通常通过局域网连接. 集群技术的特点: 1.通过多台计算 ...
- Hadoop集群上搭建Ranger
There are two types of people in the world. I hate both of them. Hadoop集群上搭建Ranger 在搭建Ranger工程之前,需要完 ...
随机推荐
- dubbo的ExtensionLoader
了解4个概念:接口,实现类,wrapper,adaptive. 扩展是接口实现类被wrap之后的对象,adaptive扩展是动态生成的类(例如Dubbo$Adaptive类). dubbo框架为接口指 ...
- oracle增加表空间
select tablespace_name, sum(bytes)/1024/1024 from dba_data_files group by tablespace_name; select ta ...
- git 系统找不到 指定的路径
git 系统找不到 指定的路径 %HOMEDRIVE%%HOMEPATH% Home 问题解决
- != 比 & 的优先级高
#define ACQU_OPTION_WEIXIN 8 int options = 7; int a = options & ACQU_OPTION_WEIXIN ; 则a 的结果应该是 ...
- mysql日常运维
一.Linux内核和发行版本 uname -a cat /etc/issue 二.glibc的版本 /lib/libc.so.6 ---没有man函数据的动态链接库 三.MySQL的版 ...
- bzoj1619
题解: 简单灌水 从最高的开始 代码: #include<bits/stdc++.h> ; typedef long long ll; using namespace std; ]={,, ...
- bzoj1086
题解: 树分块 每一次当个数大于B的时候分成一块 省会城市为当前子树根 然后最后剩下的节点和前一个分为一块 代码: #include<bits/stdc++.h> using namesp ...
- mysql 删除表中记录
一.清除mysql表中数据 delete from 表名;truncate table 表名;不带where参数的delete语句可以删除mysql表中所有内容,使用truncate table也可以 ...
- 结合P2P软件使用Ansible分发大文件
一 应用场景描述 现在我需要向50+数量的服务器分发Logstash新版本的rpm包,大概220MB左右,直接使用Ansible的copy命令进行传输,命令如下: 1 ansible all -m ...
- Python+Requests接口测试教程(2):requests
开讲前,告诉大家requests有他自己的官方文档:http://cn.python-requests.org/zh_CN/latest/ 2.1 发get请求 前言requests模块,也就是老污龟 ...