WeakReference 学习和使用
本文转自:http://qifuguang.me/2015/09/02/[Java%E5%B9%B6%E5%8F%91%E5%8C%85%E5%AD%A6%E4%B9%A0%E4%B8%83]%E8%A7%A3%E5%AF%86ThreadLocal/
这里也留着以后自己方便再看。
相信读者在网上也看了很多关于ThreadLocal的资料,很多博客都这样说:ThreadLocal为解决多线程程序的并发问题提供了一种新的思路,ThreadLocal的目的是为了解决多线程访问资源时的共享问题,balabala的。错,大错特错!
ThreadLocal的源码注释,翻译过来大概是这样的:
ThreadLocal类用来提供线程内部的局部变量。这种变量在多线程环境下访问(通过get或set方法访问)时能保证各个线程里的变量相对独立于其他线程内的变量。ThreadLocal实例通常来说都是private
static类型的,用于关联线程和线程的上下文。
可以总结为一句话:ThreadLocal的作用是提供线程内的局部变量,这种变量在线程的生命周期内起作用,减少同一个线程内多个函数或者组件之间一些公共变量的传递的复杂度。
举个栗子,我出门需要先坐公交再做地铁,这里的坐公交和坐地铁就好比是同一个线程内的两个函数,我就是一个线程,我要完成这两个函数都需要同一个东西:公交卡(北京公交和地铁都使用公交卡),那么我为了不向这两个函数都传递公交卡这个变量(相当于不是一直带着公交卡上路),我可以这么做:将公交卡事先交给一个机构,当我需要刷卡的时候再向这个机构要公交卡(当然每次拿的都是同一张公交卡)。这样就能达到只要是我(同一个线程)需要公交卡,何时何地都能向这个机构要的目的。
有人要说了:你可以将公交卡设置为全局变量啊,这样不是也能何时何地都能取公交卡吗?但是如果有很多个人(很多个线程)呢?大家可不能都使用同一张公交卡吧(我们假设公交卡是实名认证的),这样不就乱套了嘛。现在明白了吧?这就是ThreadLocal设计的初衷:提供线程内部的局部变量,在本线程内随时随地可取,隔离其他线程,为了方便!
接下来我们看看ThreadLocal内部的实现原理,如果给你,你会怎么设计。相信大部分人会有这样的想法:
每个ThreadLocal类创建一个Map,然后用线程的ID作为Map的key,实例对象作为Map的value,这样就能达到各个线程的值隔离的效果。
没错,这是最简单的设计方案,JDK最早期的ThreadLocal就是这样设计的。JDK1.3(不确定是否是1.3)之后ThreadLocal的设计换了一种方式。
我们先看看JDK8的ThreadLocal的get方法的源码:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
其中getMap的源码:
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}- 1
- 2
- 3
setInitialValue函数的源码:
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
createMap函数的源码:
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}- 1
- 2
- 3
简单解析一下,get方法的流程是这样的:
1、首先获取当前线程;
2、根据当前线程获取一个Map;
3、如果获取的Map不为空,则在Map中以ThreadLocal的引用作为key来在Map中获取对应的value e,否则转到5;
4、如果e不为null,则返回e.value,否则转到5;
5、Map为空或者e为空,则通过initialValue函数获取初始值value,然后用ThreadLocal的引用和value作为firstKey和firstValue创建一个新的Map。
然后需要注意的是Thread类中包含一个成员变量:
ThreadLocal.ThreadLocalMap threadLocals = null;- 1
所以,可以总结一下ThreadLocal的设计思路:
每个Thread维护一个ThreadLocalMap映射表,这个映射表的key是ThreadLocal实例本身,value是真正需要存储的Object。
这个方案刚好与我们开始说的简单的设计方案相反。查阅了一下资料,这样设计的主要有以下几点优势:
1、这样设计之后每个Map的Entry数量变小了:之前是Thread的数量,现在是ThreadLocal的数量,能提高性能,据说性能的提升不是一点两点(没有亲测)。
2、当Thread销毁之后对应的ThreadLocalMap也就随之销毁了,能减少内存使用量。
再深入一点
先交代一个事实:ThreadLocalMap是使用ThreadLocal的弱引用作为Key的:
static class ThreadLocalMap {
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
...
...
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
下图是本文介绍到的一些对象之间的引用关系图,实线表示强引用,虚线表示弱引用:
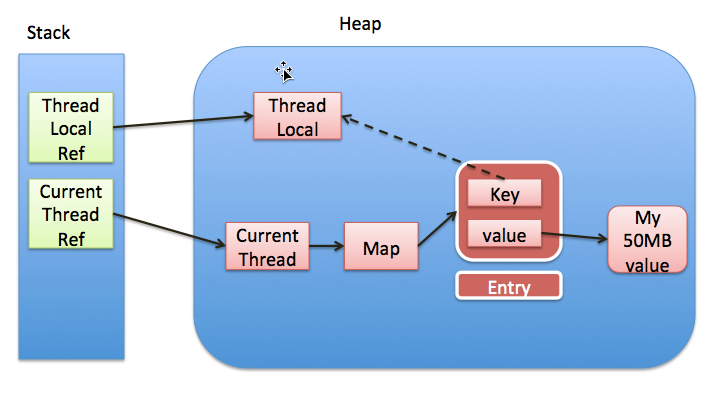
然后网上就传言,ThreadLocal会引发内存泄露,他们的理由是这样的:
如上图,ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用引用他,那么系统gc的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:
Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value
永远无法回收,造成内存泄露。
我们来看看到底会不会出现这种情况。
其实,在JDK的ThreadLocalMap的设计中已经考虑到这种情况,也加上了一些防护措施,下面是ThreadLocalMap的getEntry方法的源码:
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
return getEntryAfterMiss(key, i, e);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
getEntryAfterMiss函数的源码:
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
expungeStaleEntry函数的源码:
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
整理一下ThreadLocalMap的getEntry函数的流程:
首先从ThreadLocal的直接索引位置(通过ThreadLocal.threadLocalHashCode & (len-1)运算得到)获取Entry e,如果e不为null并且key相同则返回e;
如果e为null或者key不一致则向下一个位置查询,如果下一个位置的key和当前需要查询的key相等,则返回对应的Entry,否则,如果key值为null,则擦除该位置的Entry,否则继续向下一个位置查询。
在这个过程中遇到的key为null的Entry都会被擦除,那么Entry内的value也就没有强引用链,自然会被回收。仔细研究代码可以发现,set操作也有类似的思想,将key为null的这些Entry都删除,防止内存泄露。
但是光这样还是不够的,上面的设计思路依赖一个前提条件:要调用ThreadLocalMap的getEntry函数或者set函数。这当然是不可能任何情况都成立的,所以很多情况下需要使用者手动调用ThreadLocal的remove函数,手动删除不再需要的ThreadLocal,防止内存泄露。所以JDK建议将ThreadLocal变量定义成private static的,这样的话ThreadLocal的生命周期就更长,由于一直存在ThreadLocal的强引用,所以ThreadLocal也就不会被回收,也就能保证任何时候都能根据ThreadLocal的弱引用访问到Entry的value值,然后remove它,防止内存泄露。
WeakReference 学习和使用的更多相关文章
- 记录学习WeakReference发现的问题
在学习ThreadLocal时发现ThreadLocalMap里的Entry使用到了WeakReference,所以重新学习WeakReference 查看相关博客例如: https://blog.c ...
- Android学习笔记之SoftReference软引用,弱引用WeakReference
SoftReference可以用于bitmap缓存 WeakReference 可以用于handler 非静态内部类和匿名内部类容易造成内存泄漏 private Handler mRemoteHand ...
- JVM学习(4)——全面总结Java的GC算法和回收机制
俗话说,自己写的代码,6个月后也是别人的代码……复习!复习!复习!涉及到的知识点总结如下: 一些JVM的跟踪参数的设置 Java堆的分配参数 -Xmx 和 –Xms 应该保持一个什么关系,可以让系统的 ...
- 0030 Java学习笔记-面向对象-垃圾回收、(强、软、弱、虚)引用
垃圾回收特点 垃圾:程序运行过程中,会为对象.数组等分配内存,运行过程中或结束后,这些对象可能就没用了,没有变量再指向它们,这时候,它们就成了垃圾,等着垃圾回收程序的回收再利用 Java的垃圾回收机制 ...
- Android学习系列(36)--App调试内存泄露之Context篇(上)
Context作为最基本的上下文,承载着Activity,Service等最基本组件.当有对象引用到Activity,并不能被回收释放,必将造成大范围的对象无法被回收释放,进而造成内存泄漏. 下面针对 ...
- Android学习笔记之SoftReference软引用...
PS:其实这一篇和上一篇很类似,都是为了解决内存不足(OOM)这种情况的发生... 学习内容: 1.对象的引用类.... 最近也是通过项目中知道了一些东西,涉及到了对象的引用类,对象的引用类分为多 ...
- Java I/O NIO学习
给出一个学习的链接讲的很全.. http://ifeve.com/java-nio-all/ 上边的是中文翻译的这里是原地址:http://tutorials.jenkov.com/java-nio/ ...
- (转)Android之ListView原理学习与优化总结
转自: http://jishu.zol.com.cn/12893.html 在整理前几篇文章的时候有朋友提出写一下ListView的性能优化方面的东西,这个问题也是小马在面试过程中被别人问到的….. ...
- 转:Java学习路线图
作者: nuanyangyang 标 题: Java学习路线图(整理中,欢迎纠正) 发信站: 北邮人论坛 (Mon Aug 11 19:28:16 2014), 站内 [以下肯定是不完整的列表, ...
随机推荐
- 轻量级桌面 openbox + tint2 + conky + stalonetray + pcmanfm + xcompmgr
openbox+tint2+pnmixer+conky=轻量级archlinux桌面环境设置备忘 缘起 机器上的Ubuntu 12.04有一段时间没有使用了,最近在用的时候发现频繁死机的情况,开始以为 ...
- @Transient注解的使用
转自:https://blog.csdn.net/sinat_29581293/article/details/51810805 java 的transient关键字的作用是需要实现Serilizab ...
- 有关memcached企业面试案例讲解
有关memcached企业面试案例讲解 1.Memcached是什么,有什么作用? a. memcached是一个开源的.高性能的内存的缓存软件,从名称上看Mem就是内存的意思,而Cache就是 ...
- 什么是EPEL 及 Centos上安装EPEL
RHEL以及他的衍生发行版如CentOS为了稳定,官方的rpm repository提供的rpm包为了服务器安全稳定更新往往是很滞后的,很多时候需要自己编译那太辛苦了,而EPEL恰恰可以解决这两方面的 ...
- 获取android手机基本信息
/** * 获取android当前可用内存大小 */ private String getAvailMemory() {// 获取android当前可用内存大小 ActivityManager am ...
- 【struts2】值栈(后篇)
在值栈(前篇)我们学习了值栈的基本知识,接下来,来看看在程序中具体如何使用值栈. 1 ActionContext的基本使用 1.1 如何获取? 要获取ActionContext有两个基本的方法,如果在 ...
- React Native工程修改Android包名
默认初始化的React Native工程,生成Android工程的时候,包名默认是React Native工程的名字,跟一般Android工程com.company.xxx不一样. 这时候就需要手动修 ...
- mysql-binlog_cache_size
二进制日志缓冲区吗,默认是32k.该参数是基于会话的,不要设置过大. 当事务的记录大于设定的binlog_cache_size时,mysql会把缓冲区中的日志信息写入一个临时文件中,所以该值也不能设置 ...
- Fix SharePoint 2013 Site in Read only mode after an interrupted backup
Problem When I was backing up SharePoint Site Collection Automatically with PowerShell and Windows T ...
- C#基础第四天-作业答案-Hashtable-list<KeyValuePair>泛型实现名片
.Hashtable 实现 Hashtable table = new Hashtable(); while (true) { Console.WriteLine("------------ ...