常用模块:os模块,logging模块等
一 os模块
那么作为一个常用模块,os模块是与操作系统交互的一个模块。
那么os模块中我们常用的一般有以下几种:
os.listdir('dirname') 以列表的形式列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
还有一些不常用的:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
那么我们引用os模块,主要就是方便我们对不同的文件,通过路径来找到他们
os路径处理
#方式一:推荐使用
import os
#具体应用
import os,sys
possible_topdir = os.path.normpath(os.path.join(
os.path.abspath(__file__),
os.pardir, #上一级
os.pardir,
os.pardir
))
sys.path.insert(,possible_topdir) #方式二:不推荐使用
os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
二 json与pickle模块
这个模块主要对文件进行序列化与反序列化
那么什么叫序列化与反序列化:
序列化:我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling。
序列化的用途:
使用json进行序列化操作:
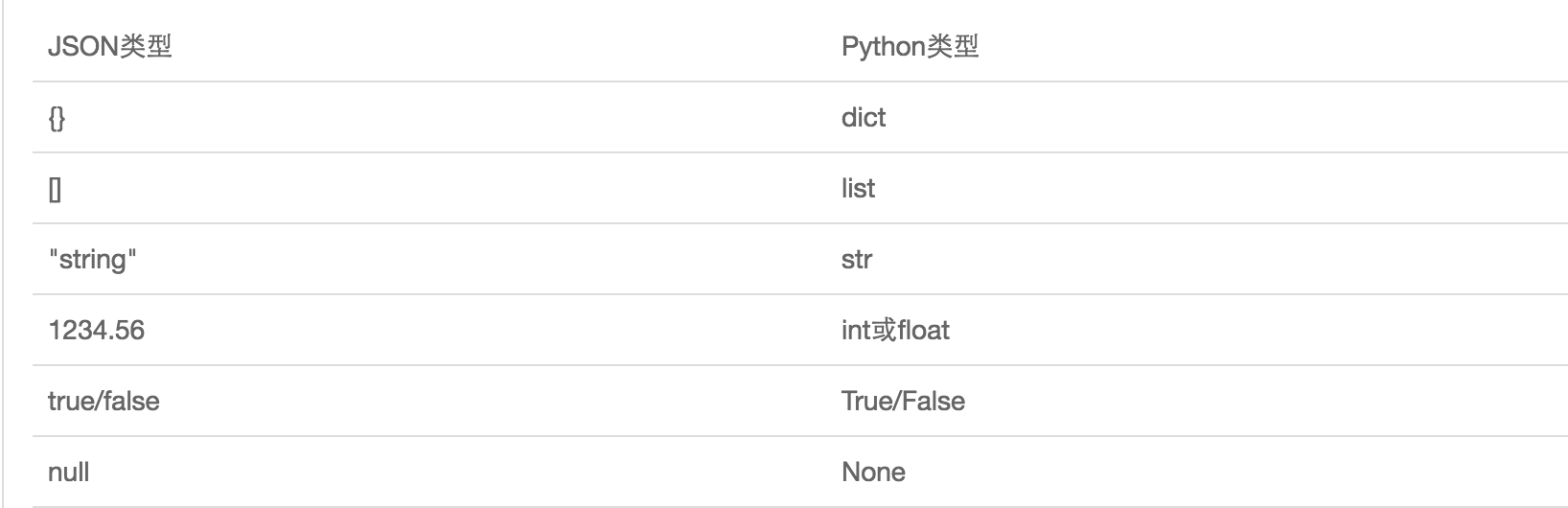
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
import json
dic={'name':'alvin','age':,'sex':'male'}
print(type(dic))#<class 'dict'>
j=json.dumps(dic)
print(type(j))#<class 'str'>
f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open('序列化对象')
data=json.loads(f.read())# 等价于data=json.load(f)
复制代码
复制代码
import json
#dct="{'1':111}"#json 不认单引号
#dct=str({"":})#报错,因为生成的数据还是单引号:{'one': }
dct='{"1":"111"}'
print(json.loads(dct))
#conclusion:
# 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
json使用以及注意事项

使用pickle进行序列化:
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。

那么从上面两个图我们可以看出,json在进行序列化与反序列化操作时与pickle的区别:
在将内存中的结构化的数据保存到文件的时候,他们所转化的形式是不同的,json转化成str,而pickl转化成bytes。同时json的跨平台性更好,pickl只适用于python自己使用。但是json并不能将所有的格式都进行序列化存储。
三 logging模块
1 logging模块分为五个日志级别:
CRITICAL = #FATAL = CRITICAL
ERROR =
WARNING = # 默认级别为worning,打印到终端
INFO =
DEBUG =
NOTSET = #不设置
2 为logging模块指定全局配置,针对所有logger有效,控制打印到文件中:
可在logging.basicConfig()函数中通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 #格式
%(name)s:Logger的名字,并非用户名,详细查看 %(levelno)s:数字形式的日志级别 %(levelname)s:文本形式的日志级别 %(pathname)s:调用日志输出函数的模块的完整路径名,可能没有 %(filename)s:调用日志输出函数的模块的文件名 %(module)s:调用日志输出函数的模块名 %(funcName)s:调用日志输出函数的函数名 %(lineno)d:调用日志输出函数的语句所在的代码行 %(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s:字符串形式的当前时间。默认格式是 “-- ::,”。逗号后面的是毫秒 %(thread)d:线程ID。可能没有 %(threadName)s:线程名。可能没有 %(process)d:进程ID。可能没有 %(message)s:用户输出的消息 复制代码 复制代码
#======介绍
可在logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “-- ::,”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息 #========使用
import logging
logging.basicConfig(filename='access.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=) logging.debug('调试debug')
logging.info('消息info')
logging.warning('警告warn')
logging.error('错误error')
logging.critical('严重critical') #========结果
access.log内容:
-- :: PM - root - DEBUG -test: 调试debug
-- :: PM - root - INFO -test: 消息info
-- :: PM - root - WARNING -test: 警告warn
-- :: PM - root - ERROR -test: 错误error
-- :: PM - root - CRITICAL -test: 严重critical part2: 可以为logging模块指定模块级的配置,即所有logger的配置
3 logger的应用:
"""
logging配置
""" import os
import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' # 定义日志输出格式 结束 logfile_dir = os.path.dirname(os.path.abspath(__file__)) # log文件的目录 logfile_name = 'all2.log' # log文件名 # 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir) # log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典
LOGGING_DIC = {
'version': ,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': **, # 日志大小 5M
'backupCount': ,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
},
},
} def load_my_logging_cfg():
logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置
logger = logging.getLogger(__name__) # 生成一个log实例
logger.info('It works!') # 记录该文件的运行状态 if __name__ == '__main__':
load_my_logging_cfg() logging配置文件
常用模块:os模块,logging模块等的更多相关文章
- Python常用模块os & sys & shutil模块
OS模块 import os ''' os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") 改变当前脚本工作目录: ...
- 模块和包,logging模块
模块和包,logging日志 1.模块和包 什么是包? 只要文件夹下含有__init__.py文件就是一个包. 假设文件夹下有如下结构 bake ├── test.py ├── __init__.py ...
- Python模块:日志输出—logging模块
1. logging介绍 Python的logging模块提供了通用的日志系统,可以方便第三方模块或者是应用使用.这个模块提供不同的日志级别,并可以采用不同的方式记录日志,比如文件,HTTP GET/ ...
- Day5模块-os和sys模块
os模块:操作系统调用的接口 ------------------------------------------------------------------------------------- ...
- python3之xml&ConfigParser&hashlib&Subprocess&logging模块
1.xml模块 XML 指可扩展标记语言(eXtensible Markup Language),标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言. XML 被设计用来传输和存储 ...
- 第二十三篇 logging模块(******)
日志非常重要,而且非常常用,可以通过logging模块实现. 热身运动 import logging logging.debug("debug message") logging. ...
- Python logging 模块学习
logging example Level When it's used Numeric value DEBUG Detailed information, typically of interest ...
- Python入门之logging模块
本章目录: 一.logging模块简介 二.logging模块的使用 三.通过JSON或者YMAL文件配置logging模块 ===================================== ...
- 0x01 Python logging模块
目录 Python logging 模块 前言 logging模块提供的特性 logging模块的设计过程 logger的继承 logger在逻辑上的继承结构 logging.basicConfig( ...
- 第十章、logging模块
目录 第十章.logging模块 一.logging模块及日志框架 第十章.logging模块 一.logging模块及日志框架 导入方式 import logging 作用 写日志 模块功能 # V ...
随机推荐
- 【opencv基础】linux系统opencv以及opencv_contrib的安装与使用
前言 本文主要介绍如何在linux系统安装使用opencv. 具体步骤可参考opencv官网here. 步骤 编译源码之前需要安装相关依赖库: 1.下载源码: 2.解压源码: 3.配置cmake: 注 ...
- 一定要记住这20种PS技术,让你的照片美的不行! - imsoft.cnblogs
照片名称:调出照片柔和的蓝黄色-简单方法, 1.打开原图素材,按Ctrl + J把背景图层复制一层,点通道面板,选择蓝色通道,图像 > 应用图像,图层为背景,混合为正片叠底,不透明度50%,反相 ...
- java正则表达式——Greedy、Reluctant和Possessive
测试1: package jichu; import java.util.regex.Matcher; import java.util.regex.Pattern; public class Mai ...
- 关于self和super在oc中的疑惑与分析 (self= [super init])
这个问题貌似很初级,但很容易让人忽略,me too .直到在一次面试时被问到,稀里糊涂的回答了下.实在惭愧, 面试一定都是很注重 基础的,不管高级还是初级. 虽然基础好跟基础不好都可以写代码,网上那么 ...
- 大家一起做训练 第二场 E Cottage Village
题目来源:CodeForce #15 A 现在有 n 间正方形的房子,其中心点分布在 X轴 上,现在我需要新建一间边长为 t 的房子,要求新房子至少和一间房子相邻,但是不能和其他房子重合.请输出我有多 ...
- CTF-练习平台-Misc之 Linux??????
八.Linux?????? 下载文件,解压后只得到一个没有后缀名的文件,添加后缀名为txt,打开搜索,关键词为“flag”,没有找到:改关键词为“key”得到答案
- arduino 配置 esp8266
在连接之前,先把程序下载到arduino中,很简单,就是定义了软口.如果中间要改动程序,要把rx和tx的连线去掉,不然下载程序可能失败. ; ; void setup() { pinMode(rx,I ...
- 【java规则引擎】《Drools7.0.0.Final规则引擎教程》第3章 3.2 KIE API解析
转载至:https://blog.csdn.net/wo541075754/article/details/75004575 3.2.4 KieServices 该接口提供了很多方法,可以通过这些方法 ...
- day40 python MySQL【四】 之 【索引】【视图】【触发器】【存储过程】【函数】
MySQL[四] 之 [索引][视图][触发器][存储过程][函数] 1.索引 索引相当于图书的目录,可以帮助用户快速的找到需要的内容. 数据库利用各种各样的快速定位技术,能够大大提高查询效率.特 ...
- ZH奶酪:【Python】random模块
Python中的random模块用于随机数生成,对几个random模块中的函数进行简单介绍.如下:random.random() 用于生成一个0到1的随机浮点数.如: import random ra ...