OpenACC 绘制曼德勃罗集
▶ 书上第四章,用一系列步骤优化曼德勃罗集的计算过程。
● 代码
// constants.h
const unsigned int WIDTH=;
const unsigned int HEIGHT=;
const unsigned int MAX_ITERS=;
const unsigned int MAX_COLOR=;
const double xmin=-1.7;
const double xmax=.;
const double ymin=-1.2;
const double ymax=1.2;
const double dx = (xmax - xmin) / WIDTH;
const double dy = (ymax - ymin) / HEIGHT;
// mandelbrot.h
#pragma acc routine seq
unsigned char mandelbrot(int Px, int Py);
// mandelbrot.cpp
#include <cstdio>
#include <cstdlib>
#include <fstream>
#include "mandelbrot.h"
#include "constants.h" using namespace std; unsigned char mandelbrot(int Px, int Py)
{
const double x0 = xmin + Px * dx, y0 = ymin + Py * dy;
double x = 0.0, y = 0.0;
int i;
for(i=; x * x + y * y < 4.0 && i < MAX_ITERS; i++)
{
double xtemp = x * x - y * y + x0;
y = * x * y + y0;
x = xtemp;
}
return (double)MAX_COLOR * i / MAX_ITERS;
}
// main.cpp
#include <cstdio>
#include <cstdlib>
#include <fstream>
#include <cstring>
#include <omp.h>
#include <openacc.h> #include "mandelbrot.h"
#include "constants.h" using namespace std; int main()
{
unsigned char *image = (unsigned char*)malloc(sizeof(unsigned int) * WIDTH * HEIGHT);
FILE *fp=fopen("image.pgm","wb");
fprintf(fp,"P5\n\"#comment\"\n%d %d\n%d\n",WIDTH, HEIGHT, MAX_COLOR); acc_init(acc_device_nvidia);
#pragma acc parallel num_gangs(1)
{
image[] = ;
}
double st = omp_get_wtime();
#pragma acc parallel loop
for(int y = ; y < HEIGHT; y++)
{
for(int x = ; x < WIDTH; x++)
image[y * WIDTH + x] = mandelbrot(x, y);
}
double et = omp_get_wtime();
printf("Time: %lf seconds.\n", (et-st));
fwrite(image,sizeof(unsigned char),WIDTH * HEIGHT, fp);
fclose(fp);
free(image);
return ;
}
● 输出结果
// Ubuntu:
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp$ pgc++ -std=c++ -acc -mp -fast -Minfo -c mandelbrot.cpp
mandelbrot(int, int):
, Generating acc routine seq
Generating Tesla code
, FMA (fused multiply-add) instruction(s) generated
, Loop not vectorized/parallelized: potential early exits
, FMA (fused multiply-add) instruction(s) generated
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp$ pgc++ -std=c++ -acc -mp -fast -Minfo main.cpp mandelbrot.o -o acc1.exe
main.cpp:
main:
, Accelerator kernel generated
Generating Tesla code
Generating implicit copyout(image[])
, Accelerator kernel generated
Generating Tesla code
, #pragma acc loop gang /* blockIdx.x */
, #pragma acc loop vector(128) /* threadIdx.x */
, Generating implicit copy(image[:])
, Loop is parallelizable
Loop not vectorized/parallelized: contains call
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp$ ./acc1.exe
Time: 0.646578 seconds.
● 优化 03,变化仅在 main.cpp 中
// main.cpp
#include <cstdio>
#include <cstdlib>
#include <fstream>
#include <cstring>
#include <omp.h>
#include <openacc.h>
#include "mandelbrot.h"
#include "constants.h" using namespace std; int main()
{
const int num_blocks = , block_size = HEIGHT / num_blocks * WIDTH;
unsigned char *image=(unsigned char*)malloc(sizeof(unsigned int) * WIDTH * HEIGHT);
FILE *fp=fopen("image.pgm","wb");
fprintf(fp,"P5\n\"#comment\"\n%d %d\n%d\n",WIDTH, HEIGHT, MAX_COLOR); acc_init(acc_device_nvidia);
#pragma acc parallel num_gangs(1)
{
image[] = ;
}
double st = omp_get_wtime();
#pragma acc data create(image[WIDTH*HEIGHT])
{
for(int block = ; block < num_blocks; block++)
{
const int start = block * (HEIGHT/num_blocks), end = start + (HEIGHT/num_blocks);
#pragma acc parallel loop async(block)
for(int y=start;y<end;y++)
{
for(int x=;x<WIDTH;x++)
image[y*WIDTH+x]=mandelbrot(x,y);
}
#pragma acc update self(image[block*block_size:block_size]) async(block)
}
}
#pragma acc wait double et = omp_get_wtime();
printf("Time: %lf seconds.\n", (et-st));
fwrite(image,sizeof(unsigned char), WIDTH * HEIGHT, fp);
fclose(fp);
free(image);
return ;
}
● 输出结果
// Ubuntu:
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task3$ pgc++ -std=c++ -acc -mp -fast -Minfo -c mandelbrot.cpp
mandelbrot(int, int):
, Generating acc routine seq
Generating Tesla code
, FMA (fused multiply-add) instruction(s) generated
, Loop not vectorized/parallelized: potential early exits
, FMA (fused multiply-add) instruction(s) generated
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task3$ pgc++ -std=c++ -acc -mp -fast -Minfo main.cpp mandelbrot.o -o acc2.exe
main.cpp:
main:
, Accelerator kernel generated
Generating Tesla code
Generating implicit copyout(image[])
, Generating create(image[:])
, Accelerator kernel generated
Generating Tesla code
, #pragma acc loop gang /* blockIdx.x */
, #pragma acc loop vector(128) /* threadIdx.x */
, Loop is parallelizable
Loop not vectorized/parallelized: contains call
, Generating update self(image[block*:])
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task3$ ./acc2.exe
Time: 0.577263 seconds.
● 优化 05,添加异步计算
// main.cpp
#include <cstdio>
#include <cstdlib>
#include <fstream>
#include <cstring>
#include <omp.h>
#include <openacc.h>
#include "mandelbrot.h"
#include "constants.h" using namespace std; int main()
{
const int num_blocks=, block_size = HEIGHT / num_blocks * WIDTH;
unsigned char *image=(unsigned char*)malloc(sizeof(unsigned int) * WIDTH * HEIGHT);
FILE *fp = fopen("image.pgm", "wb");
fprintf(fp,"P5\n\"#comment\"\n%d %d\n%d\n",WIDTH, HEIGHT, MAX_COLOR); const int num_gpus = acc_get_num_devices(acc_device_nvidia); #pragma omp parallel num_threads(num_gpus)
{
acc_init(acc_device_nvidia);
acc_set_device_num(omp_get_thread_num(),acc_device_nvidia);
}
printf("Found %d NVIDIA GPUs.\n", num_gpus); double st = omp_get_wtime();
#pragma omp parallel num_threads(num_gpus)
{
int queue = ;
int my_gpu = omp_get_thread_num();
acc_set_device_num(my_gpu,acc_device_nvidia);
printf("Thread %d is using GPU %d\n", my_gpu, acc_get_device_num(acc_device_nvidia));
#pragma acc data create(image[WIDTH*HEIGHT])
{
#pragma omp for schedule(static, 1)
for(int block = ; block < num_blocks; block++)
{
const int start = block * (HEIGHT/num_blocks), end = start + (HEIGHT/num_blocks);
#pragma acc parallel loop async(queue)
for(int y=start;y<end;y++)
{
for(int x=;x<WIDTH;x++)
image[y*WIDTH+x]=mandelbrot(x,y);
} #pragma acc update self(image[block*block_size:block_size]) async(queue)
queue = (queue + ) % ;
}
}
#pragma acc wait
} double et = omp_get_wtime();
printf("Time: %lf seconds.\n", (et-st));
fwrite(image,sizeof(unsigned char), WIDTH * HEIGHT, fp);
fclose(fp);
free(image);
return ;
}
● 输出结果
// Ubuntu:
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task5.multithread$ pgc++ -std=c++ -acc -mp -fast -Minfo -c mandelbrot.cpp
mandelbrot(int, int):
, Generating acc routine seq
Generating Tesla code
, FMA (fused multiply-add) instruction(s) generated
, Loop not vectorized/parallelized: potential early exits
, FMA (fused multiply-add) instruction(s) generated
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task5.multithread$ pgc++ -std=c++ -acc -mp -fast -Minfo main.cpp mandelbrot.o -o acc3.exe
main.cpp:
main:
, Parallel region activated
, Parallel region terminated
, Parallel region activated
, Generating create(image[:])
, Parallel loop activated with static cyclic schedule
, Accelerator kernel generated
Generating Tesla code
, #pragma acc loop gang /* blockIdx.x */
, #pragma acc loop vector(128) /* threadIdx.x */
, Loop is parallelizable
Loop not vectorized/parallelized: contains call
, Generating update self(image[block*:])
, Barrier
, Parallel region terminated
cuan@CUAN:/media/cuan/02FCDA52FCDA4019/Code/ParallelProgrammingWithOpenACC-master/Chapter04/cpp/task5.multithread$ ./acc3.exe
Found NVIDIA GPUs.
Thread is using GPU
Time: 0.497450 seconds.
● nvprof 的结果汇总,三张图分别为 “并行和数据优化”,“优化 03(分块分流)” 和 “优化 05(分块调度)”
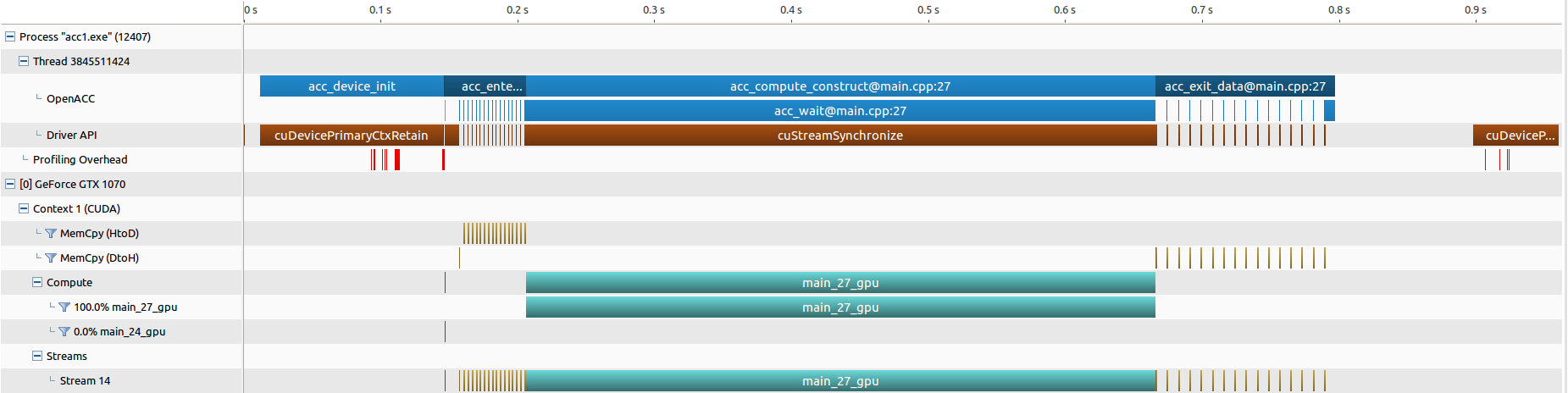
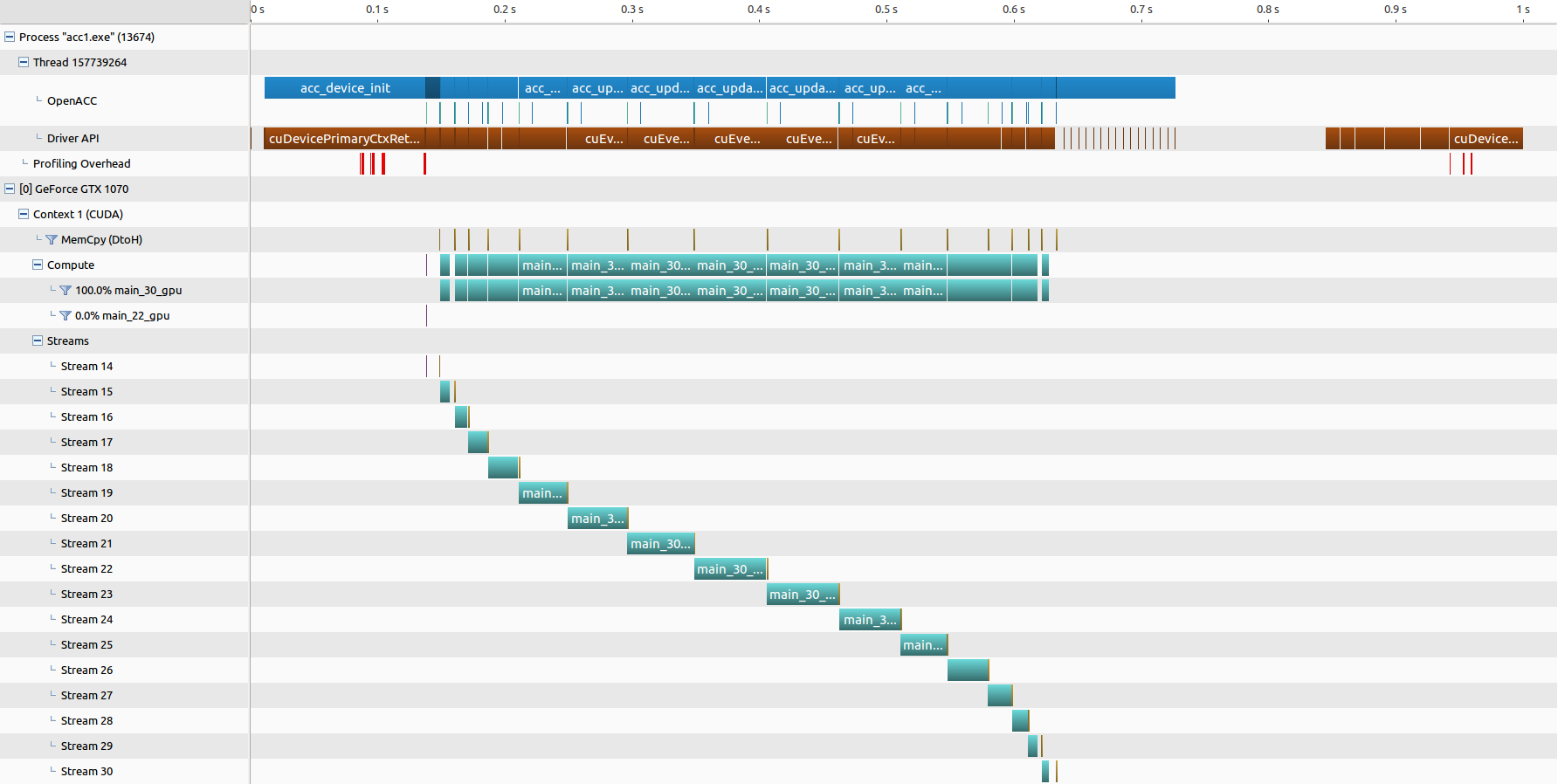
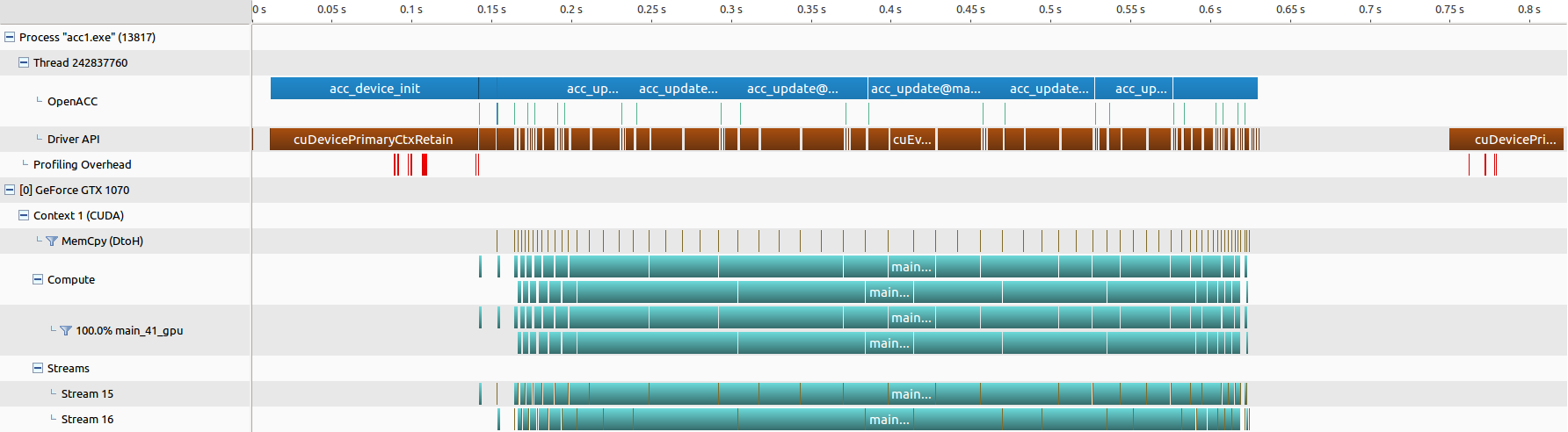
OpenACC 绘制曼德勃罗集的更多相关文章
- 曼德勃罗(Mandelbrot)集合与其编程实现
一.从科赫雪花谈起 设想一个边长为1的等边三角形(例如以下图所看到的).取每边中间的三分之中的一个,接上去一个形状全然类似的但边长为其三分之中的一个的三角形,结果是一个六角形.如今取六角形的每个边做相 ...
- 【C++】Mandelbrot集绘制(生成ppm文件)
曼德勃罗特集是人类有史以来做出的最奇异,最瑰丽的几何图形.曾被称为"上帝的指纹". 这个点集均出自公式:Zn+1=(Zn)^2+C.(此处Z.C均为复数)所有使得该公式无限迭代后的 ...
- python图片和分形树
链接: 这10个Python项目很有趣! Python 绘制分形图(曼德勃罗集.分形树叶.科赫曲线.分形龙.谢尔宾斯基三角等)附代码 使用Python生成树形图案 神奇的代码:用 Python 生成分 ...
- Pollard Rho 算法简介
\(\text{update 2019.8.18}\) 由于本人将大部分精力花在了cnblogs上,而不是洛谷博客,评论区提出的一些问题直到今天才解决. 下面给出的Pollard Rho函数已给出散点 ...
- Miller-Rabin and Pollard-Rho
实话实说,我自学(肝)了两天才学会这两个随机算法 记录: Miller-Rabin 她是一个素数判定的算法. 首先需要知道费马小定理 \[a^{p-1}\equiv1\pmod{p}\quad p\i ...
- 使用OpenGL进行Mandelbrot集的可视化
Mandelbrot集是哪一集?? Mandelbrot集不是哪一集!! 啊不对-- Mandelbrot集是哪一集!! 好像也不对-- Mandelbrot集是数集!! 所以--他不是一集而是数集? ...
- 混沌分形之朱利亚集(JuliaSet)
朱利亚集合是一个在复平面上形成分形的点的集合.以法国数学家加斯顿·朱利亚(Gaston Julia)的名字命名.我想任何一个有关分形的资料都不会放过曼德勃罗集和朱利亚集.这里将以点集的方式生成出朱利亚 ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
随机推荐
- BZOJ4710: [Jsoi2011]分特产【组合数学+容斥】
Description JYY 带队参加了若干场ACM/ICPC 比赛,带回了许多土特产,要分给实验室的同学们. JYY 想知道,把这些特产分给N 个同学,一共有多少种不同的分法?当然,JYY 不希望 ...
- WIN 10系统下,在DOS窗口输入Java或者javac出现乱码的解决方法
昨天在WIN10系统下完成了Java环境的安装配置,配置完成后验证环境的时候出了一个小插曲—输入java后窗口内中文字符出现乱码,如下图. 在经过一番google之后,发现,原来是我cmd窗口的代码页 ...
- Spring学习--静态工厂方法、实例工厂方法创建 Bean
通过调用静态工厂方法创建 bean: 调用静态工厂方法创建 bean 是将对象创建的过程封装到静态方法中 , 当客户端需要对象时 , 只需要简单地调用静态方法 , 而不需要关心创建对象的细节. 要声明 ...
- JQ和JS获取span标签的内容(有的情况下JQ达不到预期的目的就用JS)
https://www.cnblogs.com/anniey/p/6439021.html <span id="content">‘我是span标签的内容’</s ...
- 使用slot编写弹窗组件
具体slot用法详见http://www.cnblogs.com/keepfool/p/5637834.html html: <!--测试弹窗--> <dialog-test v-i ...
- day25 python学习 继承,钻石继承 多态
---恢复内容开始--- 通过一个列子认识父类和子类中,子类的如何实现对父类默认属性调用,同时拥有自己的属性,如何在子类中调用父类的方法,class Ainmal: country='afdas' d ...
- Ribbon Status Bar
https://documentation.devexpress.com/#WindowsForms/CustomDocument2498 官方文档说明 A Ribbon Status Bar (Ri ...
- TweenMax.allTo
需要多个MC进行相同的缓动.比如下面这个游戏菜单.三个按钮的缓动是相同的,都缓动到同一个x坐标位置.然后同时有缓动出舞台. 如果有TweenLite实现的话,需要 if (is ...
- centos6 ext4修复
输入root密码后: fsck -y /dev/mapper/vg_logserv-lv_root 修复完后重启 reboot 若忘记了root密码,可用系统ISO盘引导进入Rescue救援模式 在这 ...
- Java awt组件间的继承关系
Container的继承关系: Window是可独立存在的容器,其他则不行.