storm集群的安装
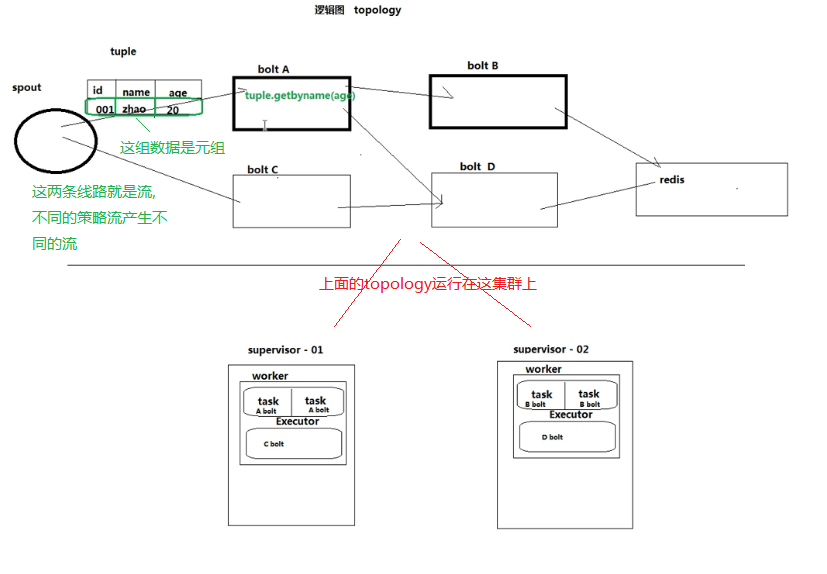
storm图解

storm的基本概念
Topologies:拓扑,也俗称一个任务
Spoults:拓扑的消息源
Bolts:拓扑的处理逻辑单元
tuple:消息元组,在Spoults和Bolts传递数据报的一种格式
Streams:流
Streams groupings:流的分组策略
Tasks:任务处理单元
Executor:工作线程
Workers:工作进程
Configuration:topology的配置
官网:http://storm.apache.org/
storm:
实时在线运算,用于流式计算,就是数据像水一样源源不断的来,storm此时就得把这些数据处理完
storm一般不单独使用,因为它不存储,一般数据从消息队列进来处理完可以存储到mysql或其他数据库中去
Apache Storm是一个免费的开源分布式实时计算系统。Apache Storm可以轻松可靠地处理无限数据流,实现Hadoop为批处理所做的实时处理。Apache Storm很简单,可以与任何编程语言一起使用,并且使用起来很有趣!
Apache Storm有许多用例:实时分析,在线机器学习,连续计算,分布式RPC,ETL等。Apache Storm很快:一个基准测试时钟表示每个节点每秒处理超过一百万个元组。它具有可扩展性,容错性,可确保您的数据得到处理,并且易于设置和操作。
Apache Storm与您已经使用的消息队列和数据库技术集成。Apache Storm拓扑消耗数据流并以任意复杂的方式处理这些流,然后在计算的每个阶段之间重新划分流。
Storm与Hadoop的对比
Topology与Mapreduce
一个关键的区别是:一个MapReduce job最终会结束,而一个Topology永远会存在(除非手动kill掉)
Nimbus与JobTracker
在Storm的集群里面有两种节点:控制节点(master node)和工作槽位节点(worker node,默认每台机器最多4个slots槽位).控制节点上面运行一个叫nimbus后台程序,它的作用类似于haddop里面的JobTracker。nimbus负责在集群里面分发代码,分配计算任务给机器,并且监控状态.。
Supervisor与TaskTracker
每一个工作节点上面运行一个叫做Supervisor的节点,Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程.每一个工作进程执行一个topology的一个子集;一个运行的topology由运行在很多机器上的很多工作进程组成。
安装步骤:
1.安装一个zookeeper集群
2.下载storm的安装包,解压
3.修改配置文件storm.yaml
#所使用的zookeeper集群主机
- hadoop01
- hadoop02
- hadoop03
#nimbus所在的主机名
nimbus.host: "hadoop01"
#默认4个槽位,可以根据机器性能配置大于4个
supervisor.slots.ports
-6701
-6702
-6703
-6704
-6705
#启动storm
#在nimbus主机上
nohup ./storm nimbus 1 > /dev/bull 2>&1 &
nohup ./storm ui 1 > /dev/null 2>&1 &
在supervisor主机上
nohup ./storm supervisor 1 > /dev/null 2>&1 &
1.zookeeper集群前面已经安装过
2.下载storm的安装包,解压
[linyouyi@hadoop01 software]$ wget https://mirrors.aliyun.com/apache/storm/apache-storm-2.0.0/apache-storm-2.0.0.tar.gz
[linyouyi@hadoop01 software]$ ll
total
-rw-rw-r-- linyouyi linyouyi Apr : apache-storm-2.0..tar.gz
-rw-r--r-- linyouyi linyouyi Aug : hadoop-2.7..tar.gz
-rw-rw-r-- linyouyi linyouyi Mar : hbase-2.0.-bin.tar.gz
-rw-r--r-- linyouyi linyouyi Aug : server-jre-8u144-linux-x64.tar.gz
-rw-r--r-- linyouyi linyouyi Aug : zookeeper-3.4..tar.gz
[linyouyi@hadoop01 software]$ tar -zxvf apache-storm-2.0..tar.gz -C /hadoop/module/
[linyouyi@hadoop01 software]$ cd /hadoop/module/apache-storm-2.0.
[linyouyi@hadoop01 apache-storm-2.0.]$ ll
total
drwxrwxr-x linyouyi linyouyi Aug : bin
drwxrwxr-x linyouyi linyouyi Aug : conf
-rw-r--r-- linyouyi linyouyi Apr : DEPENDENCY-LICENSES
drwxr-xr-x linyouyi linyouyi Apr : examples
drwxrwxr-x linyouyi linyouyi Aug : external
drwxr-xr-x linyouyi linyouyi Apr : extlib
drwxr-xr-x linyouyi linyouyi Apr : extlib-daemon
drwxrwxr-x linyouyi linyouyi Aug : lib
drwxrwxr-x linyouyi linyouyi Aug : lib-tools
drwxr-xr-x linyouyi linyouyi Apr : lib-webapp
drwxr-xr-x linyouyi linyouyi Apr : lib-worker
-rw-r--r-- linyouyi linyouyi Apr : LICENSE
drwxr-xr-x linyouyi linyouyi Apr : licenses
drwxrwxr-x linyouyi linyouyi Aug : log4j2
-rw-r--r-- linyouyi linyouyi Apr : NOTICE
drwxrwxr-x linyouyi linyouyi Aug : public
-rw-r--r-- linyouyi linyouyi Apr : README.markdown
-rw-r--r-- linyouyi linyouyi Apr : RELEASE
-rw-r--r-- linyouyi linyouyi Apr : SECURITY.md
3.修改配置文件storm.yaml
[linyouyi@hadoop01 apache-storm-2.0.]$ vim conf/storm.yaml
#zookeeper地址
storm.zookeeper.servers:
- "hadoop01"
- "hadoop02"
- "hadoop03"
nimbus.seeds: ["hadoop01"]
#nimbus.seeds: ["host1", "host2", "host3"] [linyouyi@hadoop01 apache-storm-2.0.]$ cd ../
[linyouyi@hadoop01 module]$ scp -r apache-storm-2.0. linyouyi@hadoop02:/hadoop/module/
[linyouyi@hadoop01 module]$ scp -r apache-storm-2.0. linyouyi@hadoop03:/hadoop/module/
4.启动服务
[linyouyi@hadoop01 module]$ cd apache-storm-2.0.
//如果报找不到java_home则需要配置conf/strom-env.sh文件
[linyouyi@hadoop01 apache-storm-2.0.]$ bin/storm nimbus &
[linyouyi@hadoop01 apache-storm-2.0.]$ jps
Nimbus
QuorumPeerMain
Jps
[linyouyi@hadoop01 apache-storm-2.0.]$ netstat -tnpl | grep
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 ::: :::* LISTEN /java
[linyouyi@hadoop01 apache-storm-2.0.]$ bin/storm ui &
[linyouyi@hadoop01 apache-storm-2.0.]$ jps
UIServer
QuorumPeerMain
Nimbus
Jps
[linyouyi@hadoop01 apache-storm-2.0.]$ netstat -tnpl | grep
tcp6 ::: :::* LISTEN /java
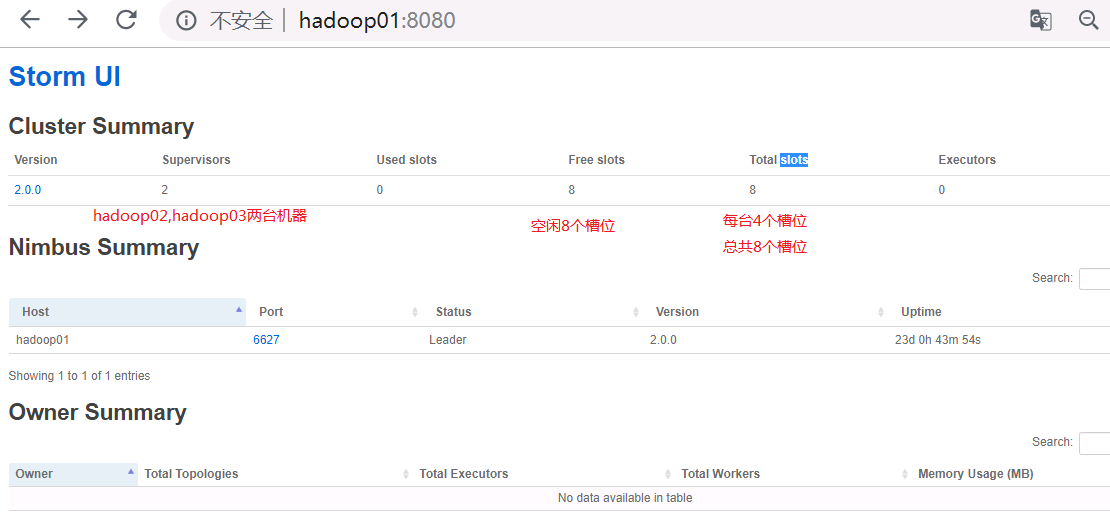
//浏览器查看http://hadoop01:8080发现很多工作槽都是0,下面我们在hadoop02,hadoop03启动supervisor,工作槽就不再是0了
[linyouyi@hadoop02 apache-storm-2.0.]$ bin/storm supervisor
[linyouyi@hadoop02 apache-storm-2.0.]$ jps
Jps
Supervisor
QuorumPeerMain
[linyouyi@hadoop03 apache-storm-2.0.]$ bin/storm supervisor
[linyouyi@hadoop03 apache-storm-2.0.]$ jps
QuorumPeerMain
Jps
Supervisor
storm提交Topologies常用命令
//命令格式: storm jar [jar路径] [拓扑包名.拓扑类名] [stormIP地址] [storm端口] [拓扑名称] [参数]
[linyouyi@hadoop01 apache-storm-2.0.]$ bin/storm jar --help
usage: storm jar [-h] [--jars JARS] [--artifacts ARTIFACTS]
[--artifactRepositories ARTIFACTREPOSITORIES]
[--mavenLocalRepositoryDirectory MAVENLOCALREPOSITORYDIRECTORY]
[--proxyUrl PROXYURL] [--proxyUsername PROXYUSERNAME]
[--proxyPassword PROXYPASSWORD] [--storm-server-classpath]
[--config CONFIG] [-storm_config_opts STORM_CONFIG_OPTS]
topology-jar-path topology-main-class
[topology_main_args [topology_main_args ...]] positional arguments:
topology-jar-path will upload the jar at topology-jar-path when the
topology is submitted.
topology-main-class main class of the topology jar being submitted
topology_main_args Runs the main method with the specified arguments. optional arguments:
--artifactRepositories ARTIFACTREPOSITORIES
When you need to pull the artifacts from other than
Maven Central, you can pass remote repositories to
--artifactRepositories option with a comma-separated
string. Repository format is "<name>^<url>". '^' is
taken as separator because URL allows various
characters. For example, --artifactRepositories
"jboss-repository^http://repository.jboss.com/maven2,H
DPRepo^http://repo.hortonworks.com/content/groups/publ
ic/" will add JBoss and HDP repositories for
dependency resolver.
--artifacts ARTIFACTS
When you want to ship maven artifacts and its
transitive dependencies, you can pass them to
--artifacts with comma-separated string. You can also
exclude some dependencies like what you're doing in
maven pom. Please add exclusion artifacts with '^'
separated string after the artifact. For example,
-artifacts "redis.clients:jedis:2.9.0,org.apache.kafka
:kafka-clients:1.0.^org.slf4j:slf4j-api" will load
jedis and kafka-clients artifact and all of transitive
dependencies but exclude slf4j-api from kafka.
--config CONFIG Override default storm conf file
--jars JARS When you want to ship other jars which are not
included to application jar, you can pass them to
--jars option with comma-separated string. For
example, --jars "your-local-jar.jar,your-local-
jar2.jar" will load your-local-jar.jar and your-local-
jar2.jar.
--mavenLocalRepositoryDirectory MAVENLOCALREPOSITORYDIRECTORY
You can provide local maven repository directory via
--mavenLocalRepositoryDirectory if you would like to
use specific directory. It might help when you don't
have '.m2/repository' directory in home directory,
because CWD is sometimes non-deterministic (fragile).
--proxyPassword PROXYPASSWORD
password of proxy if it requires basic auth
--proxyUrl PROXYURL You can also provide proxy information to let
dependency resolver utilizing proxy if needed. URL
representation of proxy ('http://host:port')
--proxyUsername PROXYUSERNAME
username of proxy if it requires basic auth
--storm-server-classpath
If for some reason you need to have the full storm
classpath, not just the one for the worker you may
include the command line option `--storm-server-
classpath`. Please be careful because this will add
things to the classpath that will not be on the worker
classpath and could result in the worker not running.
-h, --help show this help message and exit
-storm_config_opts STORM_CONFIG_OPTS, -c STORM_CONFIG_OPTS
Override storm conf properties , e.g.
nimbus.ui.port= [linyouyi@hadoop01 apache-storm-2.0.]$ storm jar /home/storm/storm-starter.jar storm.start.WordCountTopology.wordcountTop
提交storm-starter.jar到远程集群,并启动wordcountTop拓扑
storm集群的安装的更多相关文章
- Storm集群的安装配置
Storm集群的安装分为以下几步: 1.首先保证Zookeeper集群服务的正常运行以及必要组件的正确安装 2.释放压缩包 3.修改storm.yaml添加集群配置信息 4.使用storm脚本启动相应 ...
- Storm集群的安装与测试
首先安装zookeeper集群,然后安装storm集群. 我使用的是centos 32bit的三台虚拟机. MachineName ip namenode 192.168.99.110 datanod ...
- Storm 集群安装配置
本文详细介绍了 Storm 集群的安装配置方法.如果需要在 AWS 上安装 Storm,你应该看一下 storm-deploy 项目.storm-deploy 可以自动完成 E2 上 Storm 集群 ...
- storm集群配置以及java编写拓扑例子
storm集群配置 安装 修改配置文件 使用java编写拓扑 storm集群配置 storm配置相当简单 安装 tar -zxvf apache-storm-1.2.2.tar.gz rm apach ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
- Storm集群安装详解
storm有两种操作模式: 本地模式和远程模式. 本地模式:你可以在你的本地机器上开发测试你的topology, 一切都在你的本地机器上模拟出来; 远端模式:你提交的topology会在一个集群的机器 ...
- Storm入门教程 第三章Storm集群安装部署步骤、storm开发环境
一. Storm集群组件 Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node).其分别对应的角色如下: 主控节点(Master Node)上运行一个被称为N ...
- Storm系列(一)集群的安装配置
安装前说明: 必须先安装zookeeper集群 该Storm集群由三台机器构成,主机名分别为chenx01,chenx02,chenx03,对应的IP分别为192.168.1.110,192.168. ...
- Storm集群安装部署步骤
本文以Twitter Storm官方Wiki为基础,详细描述如何快速搭建一个Storm集群,其中,项目实践中遇到的问题及经验总结,在相应章节以"注意事项"的形式给出. 1. Sto ...
随机推荐
- vue 数字输入组件
index.html <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> &l ...
- selenium基本元素定位-findElement(By.*)
selenium基本元素的定位和操作 一. 查找元素 1.1 findElement(By.id) // by——>定位器——>以某种方式去找元素 driver.findElement(b ...
- Shiro学习(3)授权
授权,也叫访问控制,即在应用中控制谁能访问哪些资源(如访问页面/编辑数据/页面操作等).在授权中需了解的几个关键对象:主体(Subject).资源(Resource).权限(Permission).角 ...
- 基于mybatis-plus的代码生成
基于mybatis-plus的代码生成 前言 随着敏捷开发模式的推广,伴着日益增长的需求,日常工作中我们越来越注重效率和便捷性.今天我们就来探讨下如何自动生成代码,准确地说是如何依赖数据库生成我们的e ...
- Hbase表类型的设计
HBase表类型的设计 1.短宽 这种设计一般适用于: * 有大量的列 * 有很少的行 2.高瘦 这种设计一般适用于: * 有很少的列 * 有大量的行 3.短宽-高瘦的对比 短宽 * 使用列名进行查询 ...
- App应用推广
Android应用推广渠道: 360手机助手: http://dev.360.cn/ 应用宝: http://open.qq.com/ 百度手机助手: http://shouji.baidu.com/ ...
- MakeDown渲染出错
MakeDown渲染出错 makedown作为程序员不可或缺的编辑工具,平时的使用技巧也是非常多的. 今天给新电脑装了一个,发现出现了错误(win10环境下),如图: 错误的表现形式即:不能实时预览M ...
- linux:lrzsz安装
Linux中的lrzsc是linux里可代替ftp上传和下载的程序. yum install lrzsc 没有可用软件包 lrzsc. 这时使用 -y即可安装 centos安装:yum -y inst ...
- UVA 1525 Falling Leaves
题目链接:https://vjudge.net/problem/UVA-1525 题目链接:https://vjudge.net/problem/POJ-1577 题目大意 略. 分析 建树,然后先序 ...
- 解决 html5 input type='number' 类型可以输入e
当给 input 设置类型为 number 时,比如,我想限制,只能输入 0-9 的正整数,正则表达式如下: /^[-]?$/ // 匹配 0-9 的整数且只匹配 0 次或 1 次 用正则测试,小数点 ...