IK分词器 原理分析 源码解析
IK分词器在是一款 基于词典和规则 的中文分词器。本文讲解的IK分词器是独立于elasticsearch、Lucene、solr,可以直接用在java代码中的部分。关于如何开发es分词插件,后续会有文章介绍。
IK分词器的源码:Google Code,直接下载请点击这里。
一、两种分词模式
IK提供两种分词模式:智能模式和细粒度模式(智能:对应es的IK插件的ik_smart,细粒度:对应es的IK插件的ik_max_word)。
先看两种分词模式的demo和效果
|
输出如下:
非智能分词结果:ik analyzer 是 一个 一 个 结合 词典 分词 和文 文法 分词 的 中文 分词 开源 工具包 工具 包 它 使用 用了 全新 的 正向 迭代 最 细粒度 细粒 粒度 切分 切 分 算法
----------------------------分割线------------------------------
智能分词结果:ik analyzer 是 一个 结合 词典 分词 和 文法 分词 的 中文 分词 开源 工具包 它 使 用了 全新 的 正向 迭代 最 细粒度 切分 算法
可以看到:细粒度分词,包含每一种切分可能,而智能模式,只包含各种切分路径中最可能的一种。
二、源码概览
根据文章开头提供的链接下载源码在idea中打开后,目录结构如下
我们只需要关注cfg,core,dic三个包。
把lucene,query,sample,solr四个包下的代码注释掉,这几个包的代码是封装IKSegmenter,适配其他类库分词器的接口(lucene,solr),我们在此无需关注。
cfg包括IK的配置接口以及默认配置类,
core包括了IK的分词器接口ISegmenter,分词器核心类IKSegmenter,语义单元类Lexeme,上下文AnalyzeContext,以及子分词器LetterSegementer(英文字符子分词器),CN_QuantifierSegmenter(中文量词子分词器),CJKSegmenter(中日韩字符分词器),
dic包括了词典类Dictionary,词典树分段类DictSegmenter,用来记录词典匹配命中记录的类Hit,以及主词典main2012.dic和中文量词词典quantifier.dic
三、词典
目前,IK分词器自带主词典拥有27万左右的汉语单词量。此外,对于分词组件应用场景所涉及的领域不同,需要各类专业词库的支持,为此IK提供了对扩展词典的支持。同时,IK还提供了对用户自定义的停止词(过滤词)的扩展支持。
1.词典的初始化
在分词器IKSegmenter首次实例化时,默认会根据DefaultConfig找到主词典和中文量词词典路径,同时DefaultConfig会根据classpath下配置文件IKAnalyzer.cfg.xml,找到扩展词典和停止词典路径,用户可以在该配置文件中配置自己的扩展词典和停止词典。
找到个词典路径后,初始化Dictionary.java,Dictionary是单例的。在Dictionary的构造函数中加载词典。Dictionary是IK的词典管理类,真正的词典数据是存放在DictSegment中,该类实现了一种树结构,如下图。
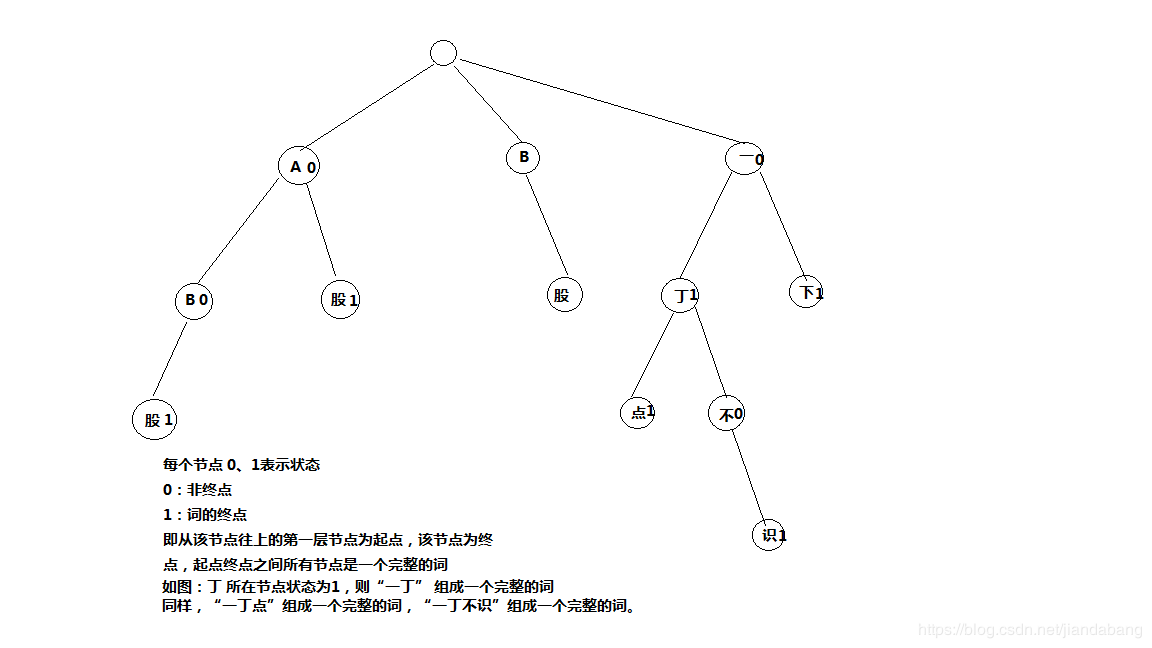
举个例子,要对字符串“A股市场”进行分词,首先拿到字符串的第一个字符'A',在上面的tree中可以匹配到A节点,然后拿到字符串第二个字符'股',首先从前一个节点A往下找,我们找到了股节点,股是一个终点节点。所以,“A股“是一个词。
Dictionary加载主词典,以,将主词典保存到它的_MainDict字段中,加载完主词典后,立即加载扩展词典,扩展词典同样保存在_MainDict中。
|
fillSegment方法是DictSegment加载单个词的核心方法,charArray是词的字符数组,先是从存储节点搜索词的第一个字符,如果不存在则创建一个节点用于存储第一个字符,后面递归存储,直到最后一个字符。
|
停止词和数量词同样的加载方法。参考Dictionary中loadStopWordDict()和loadQuantifierDict()方法。
tips,热词更新:
当词典初始化完毕后,可以调用Dictionary的addWords(Collection<String> words)方法往主词典_MainDict添加热词。
|
四、基于词典的切分
上面提到,主词典加载在Dictionary的_MainDict字段(DictSegment类型)中,
创建IKSegmenter时,需要传进来一个Reader实例,IK分词时,采用流式处理方式。
在IKSegmenter的next()方法中,首先调用AnalyzeContext.fillBuffer(this.input)从Reader读取8K数据到到segmentBuff的char数组中,然后调用子分词器CJKSegmenter(中日韩文分词器),CN_QuantifierSegmenter(中文数量词分词器),LetterSegmenter(英文分词器)的analyze方法依次从头处理segmentBuff中的每一个字符。
LetterSegmenter.analyze():英文分词器逻辑很简单,从segmentBuff中遇到第一个英文字符往后,直到碰到第一个非英文字符,这中间的所有字符则切分为一个英文单词。
CN_QuantifierSegmenter.analyze():中文量词分词器处理逻辑也很简单,在segmentBuff中遇到每一个中文数量词,然后检查该数量词后一个字符是否未中文量词(根据是否包含在中文量词词典中为判断依据),如是,则分成一个词,如否,则不是一个词。
|
CJKSegmenter.analyze则比较复杂一些,拿到第一个字符,调用Dictionary.matchInMainDict()方法,实际就是调用_MainDict.match()方法,在主词典的match方法中去匹配,首先判断该字能否单独成词(即判断_MainDict中该词所在第一个层的节点状态是否为1),如果能则加入上下文中保存起来。然后再判断该词是否可能为其他词的前缀(即判断_MainDict中该词所在第一层节点是否还有子节点),如果是则保存在分词器的临时字段tmpHits中。
再往后拿到segmentBuff中第二个字符,首先判断该词是否存在上一轮保存在temHits中的字符所在节点的子节点中,如果存在则判断这两个字符能否组成完整的词(同样,依据字符节点的状态是否为1来判断),如果成词,保存到上下文中,并且继续判断是否可能为其他词的前缀(还是判断该字符节点是否还有子节点),如果有,继续保存到tmpHits中,如果没有,则抛弃。然后再讲该字符重复与第一个字符一样的操作即可。
|
当子分词器处理完segmentBuff中所有字符后,字符的所有成词情况都已保存到上下文的orgLexemes字段中。
调用分词歧义裁决器IKArbitrator,如果分词器使用细粒度模式(useSmart=false),则裁决器不做不做歧义处理,将上下文orgLexemes字段中所有成词情况全部保存到上下文pathMap中。
然后调用context.outputToResult()方法根据pathMap中的成词情况,将最终分词结果保存到上下文的result字段中。
至此,segmentBuff中所有字符的分词结果全部保存在result中了,通过IKSegmenter.next()方法一个一个返回给调用者。
当next方法返回result所有分词后,分词器再从Reader中读取下一个8K数据到segmentBuff中,重复上述所有步骤,直至Reader全部读取完毕。
五、基于规则的歧义判断
分词裁决器IKArbitrator只有在Smart模式才会生效。
judge是IKArbitrator处理分词歧义的方法。
裁决器从上下文orgLexemes读取所有的成词,判断有交叉(有交叉即表示分词有歧义)的成词,然后,遍历每一种不交叉的情况,用LexemePath对象表示,然后保存到自定义有序链表TreeSet中,最后first()取出链表第一个元素,即为最佳分词结果。
|
然后我们看一下LexemePath对象的比较规则,即为IK的歧义判断规则,LexemePath实现了Comparable接口。
从compareTo方法可以得出,IK歧义判断规则如下,优先级从上到下一致降低:
1.分词文本长度越长越好
2.分词个数越少越好
3.分词路径跨度越大越好
4.分词位置越靠后的优先
5.词长越平均越好
6.词元位置权重越大越好(这个我也没明白,先这样,后面有需要再弄明白具体细节)
|
六、总结
总的来说,IK分词是一个基于词典的分词器,只有包含在词典的词才能被正确切分,IK解决分词歧义只是根据几条可能是最佳的分词实践规则,并没有用到任何概率模型,也不具有新词发现的功能。
原文地址:https://blog.csdn.net/jiandabang/article/details/83539783
IK分词器 原理分析 源码解析的更多相关文章
- IK分词器原理与源码分析
原文:http://3dobe.com/archives/44/ 引言 做搜索技术的不可能不接触分词器.个人认为为什么搜索引擎无法被数据库所替代的原因主要有两点,一个是在数据量比较大的时候,搜索引擎的 ...
- Spring-Session实现Session共享实现原理以及源码解析
知其然,还要知其所以然 ! 本篇介绍Spring-Session的整个实现的原理.以及对核心的源码进行简单的介绍! 实现原理介绍 实现原理这里简单说明描述: 就是当Web服务器接收到http请求后,当 ...
- Spring MVC工作原理及源码解析(三) HandlerMapping和HandlerAdapter实现原理及源码解析
1.HandlerMapping实现原理及源码解析 在前面讲解Spring MVC工作流程的时候我们说过,前端控制器收到请求后会调⽤处理器映射器(HandlerMapping),处理器映射器根据请求U ...
- 机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理、源码解析及测试
机器学习实战(Machine Learning in Action)学习笔记————03.决策树原理.源码解析及测试 关键字:决策树.python.源码解析.测试作者:米仓山下时间:2018-10-2 ...
- tensorflow运行原理分析(源码)
tensorflow运行原理分析(源码) https://pan.baidu.com/s/1GJzQg0QgS93rfsqtIMURSA
- Spring核心框架 - AOP的原理及源码解析
一.AOP的体系结构 如下图所示:(引自AOP联盟) 层次3语言和开发环境:基础是指待增加对象或者目标对象:切面通常包括对于基础的增加应用:配置是指AOP体系中提供的配置环境或者编织配置,通过该配置A ...
- lucene原理及源码解析--核心类
马云说:大家还没搞清PC时代的时候,移动互联网来了,还没搞清移动互联网的时候,大数据时代来了. 然而,我看到的是:在PC时代搞PC的,移动互联网时代搞移动互联网的,大数据时代搞大数据的,都是同一伙儿人 ...
- Redux异步解决方案之Redux-Thunk原理及源码解析
前段时间,我们写了一篇Redux源码分析的文章,也分析了跟React连接的库React-Redux的源码实现.但是在Redux的生态中还有一个很重要的部分没有涉及到,那就是Redux的异步解决方案.本 ...
- LinkedList原理及源码解析
简介 LinkedList是一个双向线性链表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer).由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度, ...
随机推荐
- Mina(一)
配置log4j注意事项: Log4J 1.2 users: slf4j-api.jar, slf4j-log4j12.jar, and Log4J 1.2.x slf4j-log4j*.jar要对应 ...
- Spring Boot跨域问题解决方案
@Configurationpublic class CorsConfig { @Bean public FilterRegistrationBean corsFilter() { UrlBasedC ...
- cm 安装cdh 后添加hive服务
cm 安装cdh 后添加hive服务,出现错误提示 添加服务时候hive 配置如下: 错误信息提示: 错误日志: xec /opt/cloudera/parcels/CDH-5.4.7-1.cdh5. ...
- html5语义化标签大全
常见的语义化标签有 <article>.<section>.<nav>.<aside>.<header>.<footer> 详细 ...
- P3224 [HNOI2012]永无乡(平衡树合并)
题目描述 永无乡包含 nn 座岛,编号从 11 到 nn ,每座岛都有自己的独一无二的重要度,按照重要度可以将这 nn 座岛排名,名次用 11 到 nn 来表示.某些岛之间由巨大的桥连接,通过桥可以从 ...
- vacuumdb - 收集垃圾并且分析一个PostgreSQL 数据库
SYNOPSIS vacuumdb [ connection-option...] [ --full | -f ] [ --verbose | -v ] [ --analyze | -z ] [ -- ...
- 浏览器http跳转至https问题
Chrome 浏览器 地址栏中输入 chrome://net-internals/#hsts 在 Delete domain security policies 中输入项目的域名,并 Delete 删 ...
- 安装监控MongoDB的Python安装包时候报错:HTTP Error 403: SSL is required
安装pymongo-2.3.tar.gz,执行命令python setup.py install报错: HTTP Error 403: SSL is required 分析原因:安装需要下载这个dis ...
- leetcode-12周双周赛-5090-抛掷硬币
题目描述: 二维dp: class Solution: def probabilityOfHeads(self, prob: List[float], target: int) -> float ...
- 使用Thread创建线程
#_author:来童星#date:2019/12/17#使用Thread创建线程import threadingimport timeclass Sunthread(threading.Thread ...