2019-08-22 纪中NOIP模拟A&B组
T1 [JZOJ3229] 回文子序列
题目描述
回文序列是指左右对称的序列。我们会给定一个N×M的矩阵,你需要从这个矩阵中找出一个P×P的子矩阵,使得这个子矩阵的每一列和每一行都是回文序列。
数据范围
对于 $20\%$ 的数据,$1 \leq N,M \leq 10$
对于 $100\%$ 的数据,$1 \leq N,M \leq 300$
分析
$O(n^5)$ 暴力跑起来真实快

#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <algorithm>
#include <vector>
#include <queue>
using namespace std;
#define ll long long
#define inf 0x3f3f3f3f
#define N 305 int n, m, flag;
int g[N][N]; int main() {
scanf("%d%d", &n, &m);
for (int i = ; i <= n; i++)
for (int j = ; j <= m; j++)
scanf("%d", &g[i][j]);
for (int k = min(n, m); k; k--)
for (int x = ; x + k - <= n; x++)
for (int y = ; y + k - <= m; y++) {
flag = ;
for (int i = ; i < k; i++) {
for (int j = ; j <= k / ; j++)
if (g[x + i][y + j - ] != g[x + i][y + k - j] ||
g[x + j - ][y + i] != g[x + k - j][y + i]) {
flag = ; break;
}
if (!flag) break;
}
if (flag) {printf("%d", k); return ;}
} return ;
}
T2 [JZOJ3230] 树环转换
题目描述
给定一棵N个节点的树,去掉这棵树的一条边需要消耗值1,为这个图的两个点加上一条边也需要消耗值1。树的节点编号从1开始。在这个问题中,你需要使用最小的消耗值(加边和删边操作)将这棵树转化为环,不允许有重边。
环的定义:(1)该图有N个点,N条边。(2)每个顶点的度数为2。(3)任意两点是可达的。
树的定义:(1)该图有N个点,N-1条边。(2)任意两点是可达的。
数据范围
对于 $20\%$ 的数据,$1 \leq N \leq 10$
对于 $100\%$ 的数据,$1 \leq N \leq 10^6$
分析
看到这种树状的题,很容易能想到树形 $dp$
我们发现当环删去一条边时,就变成了一棵特殊的树——链
所以考虑找出将树转化为一条链的最小代价,最后答案加一
设 $f[x][0]$ 表示 $x$ 的子树转化为链且一个端点为 $x$ 时的最小代价,$f[x][1]$ 表示 $x$ 的子树转化为链(不考虑 $x$ 在链上的位置)的最小代价
对于 $f[x][1]$,有两种转移方式
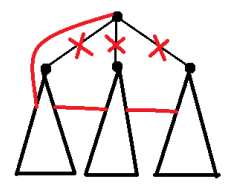
令 $Sum$ 为 $\sum_{son} f[son][1]$,$Cnt$ 为 $x$ 的子节点数,则有 $$f[x][0]=min(Sum+2Cnt,Sum-(f[u][1]-f[u][0])+2(Cnt-1))$$
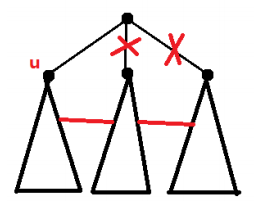
对于 $f[x][0]$,$f[x][1]$ 当然属于其一种情况,此外还一种情况

此时状态转移方程为 $$f[x][1]=min(f[x][0],Sum-(f[p][1]-f[p][0])-(f[q][1]-f[q][0])+2(Cnt-2))$$
为了得到点 $x$ 的 $u,p,q$,只需要记录其子节点中 $f[son][1]-f[son][0]$ 的最大值与次大值
由于数据对 $dfs$ 不是很友好,最后一个点会爆栈,所以我选择手写栈
当然也可以选择 $bfs$ 或者贪心
说到贪心,就是不停找两端点的度都大于 $2$ 的边删去,AC代码里跑得最快的是这么写的,感觉有点道理(然而这个贪心不存在完全正确性,结果会因遍历顺序产生不同)
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <algorithm>
#include <vector>
#include <queue>
using namespace std;
#define ll long long
#define inf 0x3f3f3f3f
#define N 1000005 int n, uu, vv, tot, top;
int f[N][], stack[N], cur[N];
int to[N << ], nxt[N << ], head[N]; inline void add(int u, int v) {
to[++tot] = v; nxt[tot] = head[u]; head[u] = tot;
} void dfs() {
memcpy(cur, head, sizeof cur);
while (top) {
int x = stack[top], go = ;
for (int i = cur[x]; i; i = nxt[i])
if (to[i] != stack[top - ]) {
cur[x] = nxt[i]; stack[++top] = to[i];
go = ; break;
}
if (go) continue;
int m1 = -inf, m2 = -inf, sum = , cnt = ;
for (int i = head[x]; i; i = nxt[i]) {
if (to[i] == stack[top - ]) continue;
int now = f[to[i]][] - f[to[i]][];
if (now > m1) m2 = m1, m1 = now;
else if (now > m2) m2 = now;
sum += f[to[i]][]; cnt++;
}
if (cnt) {
f[x][] = min(sum + * cnt, sum - m1 + * (cnt - ));
f[x][] = min(f[x][], sum - m1 - m2 + * (cnt - ));
}
top--;
}
} int main() {
scanf("%d", &n);
for (int i = ; i < n; i++) {
scanf("%d%d", &uu, &vv);
add(uu, vv); add(vv, uu);
}
stack[++top] = ; dfs();
printf("%d", f[][] + ); return ;
}
T3 [JZOJ3231] 海明距离
题目描述
对于二进制串a,b,他们之间的海明距离是指两个串异或之后串中1的个数。
计算两个串之间的海明距离的时候,他们的长度必须相同。现在我们给出N个不同的二进制串,请计算出这些串两两之间的最短海明距离。
(输入时每个二进制串用一个长度为5的16进制串表示)
数据范围
对于 $30\%$ 的数据,$1 \leq N \leq 100$
对于 $100\%$ 的数据,$1 \leq N \leq 10^5$
分析
我们可以从小到大枚举海明距离,与该海明距离下的所有可能的异或结果
对于一个异或结果,我们可以枚举给定的二进制串,如果该异或结果与该串异或后得到的二进制数也是一个给定的串,那么当前的海明距离是存在的,就可以直接得出答案
这样做的理论时间复杂度为 $O(20 \times 2^{20}n)$,但实际上不可能同时达到 $ans=20$,$n=10^5$,因为这些二进制串两两之间互不相同,当 $ans=20$ 时,$n$ 一定为 $2$,以此类推,这个时间复杂度是远远跑不满的
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <vector>
#include <queue>
using namespace std;
#define ll long long
#define inf 0x3f3f3f3f
#define N 100005
#define M (1 << 20) + 5 int t, n, ans;
int a[N], book[M], cnt[M];
char c; int main() {
scanf("%d", &t);
for (int i = , j = i; i < ( << ); j = ++i)
while (j) j &= (j - ), cnt[i]++;
while (t--) {
scanf("%d", &n);
memset(a, , sizeof a);
memset(book , , sizeof book);
for (int i = ; i <= n; i++) {
for (int j = ; j <= ; j++) {
scanf(" %c", &c);
if (isdigit(c)) a[i] = a[i] * + c - '';
else a[i] = a[i] * + + c - 'A';
}
book[a[i]] = ;
}
int flag = ;
for (ans = ; ans <= ; ans++) {
for (int s = ; s < ( << ); s++)
if (cnt[s] == ans) {
for (int i = ; i <= n; i++)
if (book[s ^ a[i]]) {
flag = ; break;
}
if (flag) break;
}
if (flag) break;
}
printf("%d\n", ans);
} return ;
}
T4 [JZOJ3232] 排列
题目描述
一个关于n个元素的排列是指一个从{1, 2, …, n}到{1, 2, …, n}的一一映射的函数。这个排列p的秩是指最小的k,使得对于所有的i = 1, 2, …, n,都有p(p(…p(i)…)) = i(其中,p一共出现了k次)。
例如,对于一个三个元素的排列p(1) = 3, p(2) = 2, p(3) = 1,它的秩是2,因为p(p(1)) = 1, p(p(2)) = 2, p(p(3)) = 3。
给定一个n,我们希望从n!个排列中,找出一个拥有最大秩的排列。例如,对于n=5,它能达到最大秩为6,这个排列是p(1) = 4, p(2) = 5, p(3) = 2, p(4) = 1, p(5) = 3。
当我们有多个排列能得到这个最大的秩的时候,我们希望你求出字典序最小的那个排列。对于n个元素的排列,排列p的字典序比排列r小的意思是:存在一个整数i,使得对于所有j < i,都有p(j) = r(j),同时p(i) < r(i)。对于5来说,秩最大而且字典序最小的排列为:p(1) = 2, p(2) = 1, p(3) = 4, p(4) = 5, p(5) = 3。
数据范围
对于 $40\%$ 的数据,$1 \leq N \leq 100$
对于 $100\%$ 的数据,$1 \leq N \leq 10^4$
分析
这题很像 2019 - 08 - 09 - T3
这里是要求将 $n$ 分为若干数之和,使得这些数的最小公倍数最大
然后就是做质数幂之积最大的多重背包了
但这里的 $f$ 会很大,远超 $long \; long$ 的范围,所以可以将 $f$ 中的元素用自然对数表示
最后显然就是把小的循环节放在前面,并且每个循环节中把第一个数放到节末输出
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <cmath>
#include <vector>
#include <queue>
using namespace std;
#define ll long long
#define inf 0x3f3f3f3f
#define N 10005 int T, n, m, last;
int vis[N], p[N], t[N];
pair<int, int> pre[][N];
double f[][N], Log[N]; int main() {
scanf("%d", &T);
for (int i = ; i <= N; i++) {
if (!vis[i]) p[++p[]] = i;
for (int j = ; j <= p[]; j++) {
if (i * p[j] > N) break;
vis[i * p[j]] = ;
}
}
for (int i = ; i <= N; i++) Log[i] = log(i);
while (T--) {
scanf("%d", &n);
if (n == ) {printf("1\n"); continue;}
for (int i = ; i <= n; i++) f[][i] = ;
for (int i = ; i <= p[] && p[i] <= n; m = i, i++)
for (int j = n; j >= p[i]; j--) {
f[i & ][j] = f[(i & ) ^ ][j];
pre[i][j] = pre[i - ][j];
for (int k = p[i]; k <= j; k *= p[i])
if (f[i & ][j] < f[(i & ) ^ ][j - k] + Log[k]) {
f[i & ][j] = f[(i & ) ^ ][j - k] + Log[k];
pre[i][j] = make_pair(i - , j - k);
}
}
t[] = last = ;
while (m && n) {
int x = pre[m][n].first;
int y = pre[m][n].second;
t[++t[]] = n - y;
m = x; n = y;
}
while (n--) t[++t[]] = ;
sort(t + , t + t[] + );
for (int i = ; i <= t[]; i++) {
for (int j = ; j <= t[i]; j++)
printf("%d ", last + j);
printf("%d ", last + );
last += t[i];
}
printf("\n");
} return ;
}
2019-08-22 纪中NOIP模拟A&B组的更多相关文章
- 2019-08-21 纪中NOIP模拟A组
T1 [JZOJ6315] 数字 题目描述
- 2019-08-15 纪中NOIP模拟B组
T1 [JZOJ3455] 库特的向量 题目描述 从前在一个美好的校园里,有一只(棵)可爱的弯枝理树.她内敛而羞涩,一副弱气的样子让人一看就想好好疼爱她.仅仅在她身边,就有许多女孩子想和她BH,比如铃 ...
- 2019-08-01 纪中NOIP模拟B组
T1 [JZOJ2642] 游戏 题目描述 Alice和Bob在玩一个游戏,游戏是在一个N*N的矩阵上进行的,每个格子上都有一个正整数.当轮到Alice/Bob时,他/她可以选择最后一列或最后一行,并 ...
- 2019-08-25 纪中NOIP模拟A组
T1 [JZOJ6314] Balancing Inversions 题目描述 Bessie 和 Elsie 在一个长为 2N 的布尔数组 A 上玩游戏. Bessie 的分数为 A 的前一半的逆序对 ...
- 2019-08-23 纪中NOIP模拟A组
T1 [JZOJ2908] 矩阵乘法 题目描述 给你一个 N*N 的矩阵,不用算矩阵乘法,但是每次询问一个子矩形的第 K 小数. 数据范围 对于 $20\%$ 的数据,$N \leq 100$,$Q ...
- 2019-08-20 纪中NOIP模拟B组
T1 [JZOJ3490] 旅游(travel) 题目描述 ztxz16如愿成为码农之后,整天的生活除了写程序还是写程序,十分苦逼.终于有一天,他意识到自己的生活太过平淡,于是决定外出旅游丰富阅历. ...
- 2019-08-20 纪中NOIP模拟A组
T1 [JZOJ6310] Global warming 题目描述 给定整数 n 和 x,以及一个大小为 n 的序列 a. 你可以选择一个区间 [l,r],然后令 a[i]+=d(l<=i< ...
- 2019-08-18 纪中NOIP模拟A组
T1 [JZOJ6309] 完全背包 题目描述
- 2019-08-09 纪中NOIP模拟B组
T1 [JZOJ1035] 粉刷匠 题目描述 windy有N条木板需要被粉刷. 每条木板被分为M个格子. 每个格子要被刷成红色或蓝色. windy每次粉刷,只能选择一条木板上一段连续的格子,然后涂上一 ...
随机推荐
- 5分钟看懂系列:HTTP缓存机制详解
原创文章首发于公众号:「码农富哥」,欢迎收藏和关注,如转载请注明出处! 什么是HTTP缓存 HTTP 缓存可以说是HTTP性能优化中简单高效的一种优化方式了,缓存是一种保存资源副本并在下次请求时直接使 ...
- 使用Java, AppleScript对晓黑板进行自动打卡
使用Java, AppleScript对晓黑板进行自动打卡 由于我们学校要求每天7点起床打卡,但是实在做不到,遂写了这个脚本. 绪论 由于晓黑板不支持网页版,只能使用App进行打卡,所以我使用网易的安 ...
- C#建立自己的测试用例系统
引言 很多时候,需要对类中的方法进行一些测试,来判断是否能按要求输出预期的结果. C#提供了快速创建单元测试的方法,但单元测试不仅速度慢不方便,大量的单元测试还会拖慢项目的启动速度. 所以决定自己搞个 ...
- java 入门如何设计类
2019/12/24 | 在校大二上学期 | 太原科技大学 初学java后,我们会发现java难点不在于Java语法难学,而是把我们挂在了如何设计类的“吊绳”上了.这恰恰也是小白 ...
- SAP Basis DEBUG改表数据权限角色设计
SAP Basis DEBUG改表数据权限角色设计 项目实践中,因种种原因不得不要通过debug才能解决一些特定的问题,所以就涉及到了debug权限角色的定义了. DEBUG的权限,无非就是: 1)数 ...
- 如何利用Azure DevOps快速实现自动化构建、测试、打包及部署
前两天有朋友问我,微软的Azure好用吗,适不适合国人的使用习惯,我就跟他讲了下,Azue很好用,这也是为什么微软云营收一直涨涨涨的原因,基本可以再1个小时内实现自动化构建.打包以及部署到Azure服 ...
- C#实现Excel操作——添加页签Sheet
C#实现对Excel操作,根据数据的类型不同或者来源不同会放在不同的页签中,C#实现添加页签代码如下:(path为文档保存的地址,dt为要处理的源数据) public void addSheet(st ...
- CommonJs模块化(nodejs模块规范)
1.概述: Node应用由模块组成,采用CommonJS模块规范. 根据这个规范,每个文件就是一个模块,有自己的作用域.在一个文件里面定义的变量.函数.类,都是私有的,对其他文件不可见. 如果想在多个 ...
- Vue(八)---组件(Component)
组件(Component)是 Vue.js 最强大的功能之一.组件可以扩展 HTML 元素,封装可重用的代码. 注册一个全局组件语法格式如下: Vue.component(tagName, optio ...
- Nginx简单的负载均衡(一)
Nginx是一个高性能的http和反向代理服务器,官方测试nginx能够支支撑5万并发链接,并且cpu.内存等资源消耗却非常低,运行非常稳定. 1.应用场景 1.http服务器.Nginx是一个htt ...