python爬取淘宝排名
import time
import json
import requests
import xlrd
import random
import os
from xlutils.copy import copy #导入模块
excel = r'C:\Users\Administrator\Desktop\查排名.xls'
try:
rdx = xlrd.open_workbook(excel, formatting_info=True) #打开Excel,并保留原格式
except:
print( "no excel in %s " % excel )
newb = copy(rdx) #复制一份做输出
#sh = rdx.sheet_by_index(name)
print('\033[31;1m已录入型号 :\033[0m',(rdx.sheet_names())) #所有sheets.name
#sh=rdx.sheet_names()
for sheet_n in rdx.sheet_names(): #循环整个工作簿
sh1=rdx.sheet_by_name(sheet_n) #工作表对象
w_sheet=newb.get_sheet(sheet_n) #获取sheet名称查
id=str(int(sh1.cell_value(0,1))) #int浮点转整数 str转字符串
print('id' ,sh1.cell_value(0,1), id ,type(id))
print('\033[31;1m查询型号 :\033[0m'+ sheet_n)
tplt = "{:3}\t{:23}" #这里控制输出 行数
for i in range(sh1.nrows): #非空行行数 整个型号的词循环
i1=str(sh1.cell_value(i, 0))
if i1=="": #空行退出
break
time.sleep(random.uniform(1.5,3.6)) #随机浮点数
url='https://s.m.taobao.com/search?q='+i1+'&sst=1&n=20&buying=buyitnow&m=api4h5&token4h5=&abtest=3&wlsort=3&page=name'
#url获取地址
1.淘宝手机端链接地址登录s.m.taobao.com
2.输入查询的关键字 审查元素 这里记得刷新一次
3.network 右侧name 一个个打开 需要的信息就在preview里面
4.恭喜找到自己需要的信息
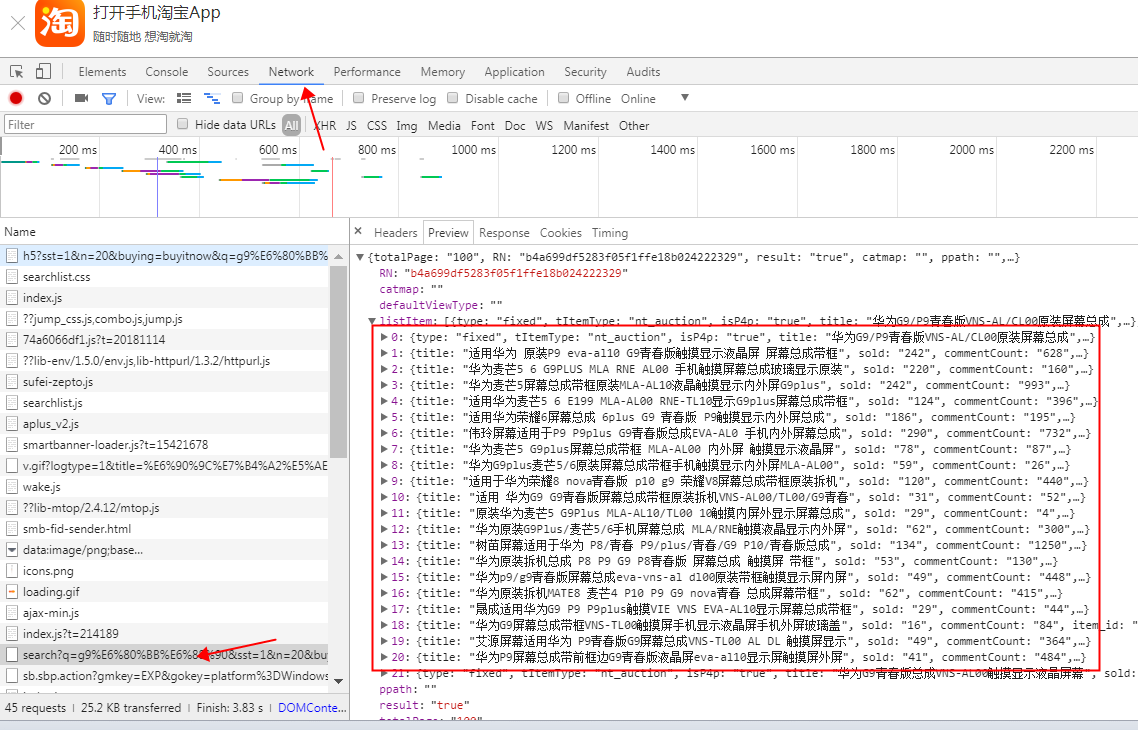
# url='https://s.m.taobao.com/search?q='+i1+'&sst=2&n=40&buying=buyitnow&m=api4h5&abtest=22&wlsort=22&page=name'
#这里是找到目标真正的地址
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.name; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
comments = requests.get(url,headers=headers)
#这里有问题临时处理办法
try:
js = json.loads(comments.text)
except json.decoder.JSONDecodeError:
continue
count=0
for j in js['listItem']: #所有店铺信息
count+=1
if j['item_id']==id: #如果id相同
print('j]',j['item_id']==id)
w_sheet.write(i,2,count)
break
else :
# print(tplt.format('没找到',i1))
w_sheet.write(i,2,'没找到')
w_sheet.write(i+1,2,time.strftime('%m-%d ',time.gmtime()))
print(" 任务完成!")
os.remove(r'C:\Users\Administrator\Desktop\查排名.xls')
newb.save(r'C:\Users\Administrator\Desktop\查排名.xls')
print('\033[32;1m查询完成!\033[0m','\n','warning:以上是查询无线两页45位结果!')
ps:记得Excel 不要有多于空白工作表 不然会报错
python爬取淘宝排名的更多相关文章
- Python 爬取淘宝商品数据挖掘分析实战
Python 爬取淘宝商品数据挖掘分析实战 项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 爬取淘宝商品 ...
- 使用Python爬取淘宝两千款套套
各位同学们,好久没写原创技术文章了,最近有些忙,所以进度很慢,给大家道个歉. 警告:本教程仅用作学习交流,请勿用作商业盈利,违者后果自负!如本文有侵犯任何组织集团公司的隐私或利益,请告知联系猪哥删除! ...
- 甜咸粽子党大战,Python爬取淘宝上的粽子数据并进行分析
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 爬虫 爬取淘宝数据,本次采用的方法是:Selenium控制Chrome浏览 ...
- Python爬取淘宝店铺和评论
1 安装开发需要的一些库 (1) 安装mysql 的驱动:在Windows上按win+r输入cmd打开命令行,输入命令pip install pymysql,回车即可. (2) 安装自动化测试的驱动s ...
- 【Python爬虫案例学习】Python爬取淘宝店铺和评论
安装开发需要的一些库 (1) 安装mysql 的驱动:在Windows上按win+r输入cmd打开命令行,输入命令pip install pymysql,回车即可. (2) 安装自动化测试的驱动sel ...
- 一篇文章教会你用Python爬取淘宝评论数据(写在记事本)
[一.项目简介] 本文主要目标是采集淘宝的评价,找出客户所需要的功能.统计客户评价上面夸哪个功能多,比如防水,容量大,好看等等. 很多人学习python,不知道从何学起.很多人学习python,掌握了 ...
- 【Python爬虫案例学习】python爬取淘宝里的手机报价并以价格排序
第一步: 先分析这个url,"?"后面的都是它的关键字,requests中get函数的关键字的参数是params,post函数的关键字参数是data, 关键字用字典的形式传进去,这 ...
- python 爬取淘宝的模特照片
前段时间花了一部分时间学习下正则表达式,总觉得利用正则要做点什么事情,所以想通过爬取页面的方式把一些美女的照片保存下来,其实过程很简单. 1.首先读取页面信息: 2.过滤出来照片的url地址: 3.通 ...
- Python 爬取淘宝商品信息和相应价格
!只用于学习用途! plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) :获得商品价格和view_pri ...
随机推荐
- Maria数据库
项目上要进行数据库选型,业务上来讲,数据是非常结构化的数据,使用传统关系数据库更适合:另外项目采用微服务框架,每个服务的数据库应该尽可能轻量级, 最后考虑Maria数据库. MariaDB简介: Ma ...
- XModem协议
XModem协议介绍: XModem是一种在串口通信中广泛使用的异步文件传输协议,分为XModem和1k-XModem协议两种,前者使用128字节的数据块,后者使用1024字节即1k字节的数据块. 一 ...
- python's ninth day for me
函数 函数的定义与调用: #def 关键字 定义一个函数. # my_len 函数名, 函数名的书写规则与变量的命名一致. # def 与函数名中间一个空格. # 函数名() : 加上冒号. ...
- sourceTree免密码校验
1.ssh请求:参考:http://www.ithao123.cn/content-1584888.html 步骤1:检查你的电脑上是否已经生成了SSH Key 在git bash下执行如下命令 cd ...
- 服务器发送邮件出现Could not connect to SMTP host错误 解决办法
服务器发送邮件出现Could not connect to SMTP host错误 解决办法 功夫不负有心人,最后了解到,除了google的smtp服务器收到请求“smtp”会接受,其他服务器比如qq ...
- selenium2 断言失败自动截图 (四)
一般web应用程序出错过后,会抛出异常.这个时候能截个图下来,当然是极好的. selenium自带了截图功能. //获取截图file File scrFile= ((TakesScreenshot)d ...
- PHP程序员求职经验总结
这次来深圳找工作,是我人生中第一次正式的求职,也是第一份正式的工作.这几天收获不少,总结一下,"供后人参考"; 从7月23来深圳到今天刚好一个星期,这7天内我发了18封求职邮件,在 ...
- 696. Count Binary Substrings统计配对的01个数
[抄题]: Give a string s, count the number of non-empty (contiguous) substrings that have the same numb ...
- 【转】浏览器中F5和CTRL F5的行为区别
原文地址:http://www.cnblogs.com/jiji262/p/3410518.html 前言 在印象中,浏览器中的F5和刷新按钮是一样的效果,都是对当前页面进行刷新:Ctrl-F5的行为 ...
- Web服务器父与子 Apache和Tomcat区别(转)
From http://developer.51cto.com/art/201007/210894.htm 熟悉三国的朋友都知道曹操,曹操有二十五个儿子,其中最得曹操宠爱的是曹丕.曹植.曹彰三个,曹丕 ...