简易推荐引擎的python实现
主要思路
使用协同过滤的思路,从当前指定的用户过去的行为和其他用户的过去行为的相似度进行相似度评分,然后使用这个相似度的评分,来构建其他用户过去的行为列表,去除当前指定用户与其他用户重复的内容,形成一份推荐列表,将其中的内容推荐给当前指定用户。
准备工作
- numpy库的安装,安装过程可以自行问度娘。一个比较简单的安装就是直接通过pip安装。
pip install numpy
或者下载numpy的whl离线包,在该文件的路径中使用pip命令安装
pip install numpy文件名.whl
- 数据集的下载,这个实例使用到了movielens的公开的数据集,可以在点这里下载,里面有100k,1m,10m,20m多个版本,这里的100k不是指文件大小100k,是指有100k(100000)条数据的意思。我这里使用了100k的那个数据集作为我的演示数据集
解压后的数据有这么多
下载后的数据是长这个样子的
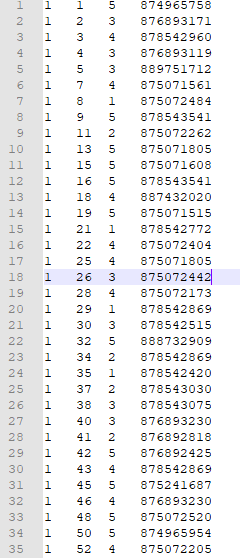
这个数据文件的第一列是用户名,因为这是一份公开数据,用户名被使用了数字代替,第二列是电影名称,因为还有另外一份表是显示完整的电影名称,这个只是显示了电影的ID,需要自己做数据整理形成比较完整的显示内容。
- 数据整理,上面图片中的这份数据,只需要用到前3列的数据,所以需要对数据集进行整理,这里我用最懒的方式
# 数据预处理
filename = 'u1.base'
dataset = []
with open(filename, 'r') as f:
datas = f.readlines()
for data in datas:
dataline = data.split('\t')[:-1]
dataset.append(dataline)
# 将数据组合成一个数据字典,大致的格式为{用户名:{电影名:评分,电影名:评分},用户名:{电影名:评分,电影名:评分}}
# 方便后面处理数据,取值、计算
data_dict = {}
for name, movie, rating in dataset:
if name not in data_dict:
data_dict[name] = {}
data_dict[name][movie] = int(rating) # 读过来的数据,这里是字符串,需要转成int,因为后面要计算值
将数据集读取后放到一个dict里面,但是建议可以做持久化,不用这样每次执行脚本都需要做一次数据整理。
项目结构图
整体的项目结构其实很简单,这也是Python的魅力——代码量少。就长下图的样子,一个脚本文件,两个数据文件,但是实际上只用了一个数据文件。

实现过程的部分代码展示
- 通过皮尔逊相关系数计算出两个用户之间的相似度
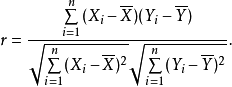
在python中实现,利用numpy库做运算计算
部分代码如下:
- 指定用户的相同评分电影值的和
user_a_sum = np.sum([dataset[user_a][item] for item in rated_by_both])
user_b_sum = np.sum([dataset[user_b] [item] for item in rated_by_both])
- 相同评分电影值的平方和
user_a_square_sum = np.sum([np.square(dataset[user_a][item]) for item in rated_by_both])
user_b_square_sum = np.sum([np.square(dataset[user_b][item]) for item in rated_by_both])
- 数据集的乘积的和
product_sum = np.sum([dataset[user_a][item] * dataset[user_b][item] for item in rated_by_both])
- 计算相似度
sxy = product_sum - (user_a_sum * user_b_sum / num_ratings)
sxx = user_a_square_sum - np.square(user_a_sum) / num_ratings
syy = user_b_square_sum - np.square(user_b_sum) / num_ratings
sxy / np.sqrt(sxx * syy)
需要注意,分母如果为零需要做一个抛异常处理。
- 遍历用户,查找相似度高的用户,形成推荐列表
similarity_score = pearson_score(dataset, user, u)
if similarity_score <= 0.9:
# 用户量大,有近千用户,如果取相似度大于0的,可能将全部的电影内容都推荐出来。这样的推荐就没有意义。
# 如果用户的相似度低于0.9的推荐不要,要找相似度高的用户的共同数据推荐才有意义
continue
for item in [x for x in dataset[u] if x not in dataset[user] or dataset[user][x] == 0]:
total_scores.update({item: dataset[u][item] * similarity_score})
similarity_sums.update({item: similarity_score})
需要考虑一个例外情况,就是如果数据集中的电影,当前指定的用户都评论过的话,这时的推荐列表长度是0
if len(total_scores) == 0
此时应该有一个例外的处理,避免最后输出的结果为空
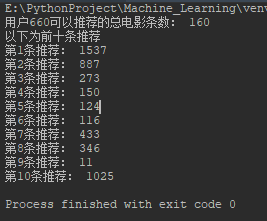
运行效果截图
user = '660'
movies = generate_recommendations(data_dict, user)
print('用户'+user+'可以推荐的总电影条数:', len(movies))
print('以下为前十条推荐')
for i, movie in enumerate(movies[:10]): # [:10]只取排名前十的推荐
print('第'+str(i + 1)+'条推荐:', movie)
最终的运行效果,因为我没有添加电影的名称到数据集中,所以推荐的内容也是显示ID。
其他补充
这只是一个简单的演示,实际上在很多真实应用的运用场景中,需要计算相似度的内容比这个演示中涉及的条件更多、更复杂。下载下来的数据集中还有对于电影的分类、用户的分类,可以在这个系统的基础上深入研究,分析用户评价过的电影,对这些电影的分类进行评分,形成用户喜欢的电影类型的列表,在根据这个列表约束推荐列表,剔除指定用户不喜欢的类型电影等等。
简易推荐引擎的python实现
注:本文著作权归作者,由demo大师代发,拒绝转载,转载需要作者授权
简易推荐引擎的python实现的更多相关文章
- 基于Azure构建PredictionIO和Spark的推荐引擎服务
基于Azure构建PredictionIO和Spark的推荐引擎服务 1. 在Azure构建Ubuntu 16.04虚拟机 假设前提条件您已有 Azure 帐号,登陆 Azure https://po ...
- Azure构建PredictionIO和Spark的推荐引擎服务
Azure构建PredictionIO和Spark的推荐引擎服务 1. 在Azure构建Ubuntu 16.04虚拟机 假设前提条件您已有 Azure 帐号,登陆 Azure https://port ...
- 用Crontab打造简易工作流引擎
1. 引言 众所周知,Oozie(1, 2)是基于时间条件与数据生成来做工作流调度的,但是Oozie的数据触发条件只支持HDFS路径,故而面临着这样的问题: 无法判断Hive partition是否已 ...
- 从源代码剖析Mahout推荐引擎
转载自:http://blog.fens.me/mahout-recommend-engine/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pi ...
- [转] 基于 Apache Mahout 构建社会化推荐引擎
来源:http://www.ibm.com/developerworks/cn/java/j-lo-mahout/index.html 推荐引擎简介 推荐引擎利用特殊的信息过滤(IF,Informat ...
- 基于Spark ALS构建商品推荐引擎
基于Spark ALS构建商品推荐引擎 一般来讲,推荐引擎试图对用户与某类物品之间的联系建模,其想法是预测人们可能喜好的物品并通过探索物品之间的联系来辅助这个过程,让用户能更快速.更准确的获得所需 ...
- JVM调优(这里主要是针对优化基于分布式Mahout的推荐引擎)
优化推荐系统的JVM关键参数 -Xmx 设定Java允许使用的最大堆空间.例如-Xmx512m表示堆空间上限为512MB -server 现代JVM有两个重要标志:-client和-server,分别 ...
- 基于lucene实现自己的推荐引擎
基于lucene实现自己的推荐引擎 推荐常用算法之-基于内容的推荐 推荐算法
- 转】从源代码剖析Mahout推荐引擎
原博文出自于: http://blog.fens.me/mahout-recommend-engine/ 感谢! 从源代码剖析Mahout推荐引擎 Hadoop家族系列文章,主要介绍Hadoop家族产 ...
随机推荐
- IOC(控制反转)的理解
1.IOC的理论背景 我们知道在面向对象设计的软件系统中,它的底层都是由N个对象构成的,各个对象之间通过相互合作,最终实现系统地业务逻辑[1]. 图1 软件系统中耦合的对象 如果我们打开机械式手表的后 ...
- 51nod 1240 莫比乌斯函数【数论+莫比乌斯函数】
1240 莫比乌斯函数 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 收藏 关注 莫比乌斯函数,由德国数学家和天文学家莫比乌斯提出.梅滕斯(Mertens)首先使用 ...
- HDU 2045 LELE的RPG难题(递推)
不容易系列之(3)—— LELE的RPG难题 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/O ...
- java应用高cpu占用
一个应用占用CPU很高,除了确实是计算密集型应用之外,通常原因都是出现了死循环 排查故障如下: 1.根据top命令,发现PID为28555的Java进程占用CPU高达200%,出现故障 2.通过ps ...
- [BZOJ4530]大融合
LCT维护子树信息 维护两个子树信息,$vinf_x$表示节点$x$的所有轻儿子子树信息,$inf_x$表示以$x$为根的LCT子树(包含虚边)的信息 对$vinf$: access时,断开$x$的原 ...
- 【分类讨论】Codeforces Round #395 (Div. 2) D. Timofey and rectangles
D题: 题目思路:给你n个不想交的矩形并别边长为奇数(很有用)问你可以可以只用四种颜色给n个矩形染色使得相接触的 矩形的颜色不相同,我们首先考虑可不可能,我们分析下最多有几个矩形互相接触,两个时可以都 ...
- 【堆】bzoj1293 [SCOI2009]生日礼物
考虑poj3320尺取法的做法,与此题基本一样,但是此题的 位置 的范围到2^31 尺取法不可. 将每种珠子所在的位置排序. 每种珠子要维护一个指针,指到已经用到这个种类的哪个珠子. 所以尺取法用堆优 ...
- IntelliJ IDEA导入Maven之后强制刷新项目解决无法识别为Maven项目的问题
先点击左下角按钮以显示Maven Project 再点击右侧Maven Project 点击刷新按钮,当然也可以点击加号选择pom.xml文件. 最后是等待项目的更新.
- 开源的库RestSharp轻松消费Restful Service
现在互联网上的服务接口都是Restful的,SOAP的Service已经不是主流..NET/Mono下如何消费Restful Service呢,再也没有了方便的Visual Studio的方便生产代理 ...
- WebStorm中部署网页到Tomcat
1. 新建一个Deployment 在上面过程中Add Server弹窗下如下输入 2. 配置Deployment的Connection选项卡 3. 配置Deployment的Mappings选项卡 ...