How to 充分利用你的服务器
服务器高性能计算指南


本文处于preview阶段,内容并不完全严谨,如有错误敬请原谅,适当参考。
什么样的计算适合当前服务器?
从CPU架构入手
本文立足于PR4768GW服务器,由于服务器购买年限比较久远,无法查看到其对应的架构图,IO扩展的详细描述,本文只能保守估计,待有时间进行详细性能测试验证。
双路CPU常见于服务器主板上,双路CPU带来的是超多的PCIE插槽,更多的IO扩展性能。
PR4768GW 的主板支持性能如下:
最大支持两颗Intel Xeon processor E5-2600 v3/v4 family (up to 160W TDP ),Dual Socket R3 (LGA 2011);
组内使用的正是两颗E5-2620 V4
单颗的规格如下:

单颗包含了8颗物理核心,最通过超线程技术可同时运行16个线程。也就是说8个厨师可以同时做16个菜。
那么我们通过系统可以看到CPU的信息如下:
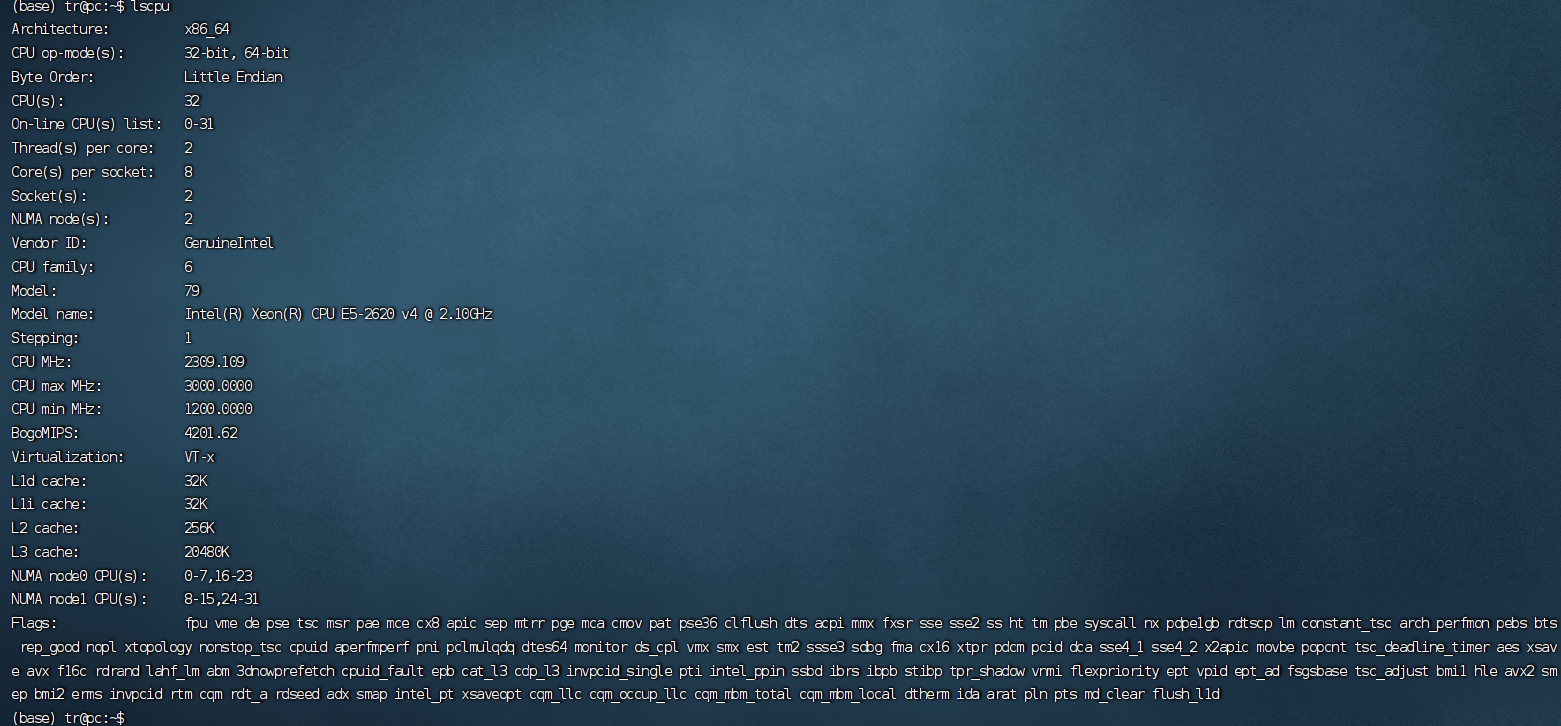
这里显示CPUS,也就是逻辑CPU有32个?
这是为什么呢?
首先,CPUS = 系统最大支持的CPU线程数量。(线程和进程的概念在这里被模糊)。
本文单个CPU支持16个线程,存在2个CPU 所以 : 16 x 2 =32。
那么在系统层级上你实际是感受不出来的,到底有多少个CPU。
但为什么要强调使用的是双CPU呢?对我们有什么影响呢?
两个CPU带来的影响
两个CPU虽然在系统层级上是完全感受不到的,但实际上是有很大区别的,可以简单画一个架构图来展示一下:
RAM1 <-->ACPU
ACPU <--CHIPSET--> BCPU
BCPU <-->RAM2
双CPU架构的计算机系统中PCIe显卡的调用过程涉及操作系统、设备驱动程序、NUMA、I/O亲和性和多CPU核心之间的协同工作。但是对于ACPU要想访问RAM2的东西或者BCPU想要访问RAM1,你就会意识到他们不仅在物理位置上相隔较远,且并没有直接链接在一起,这意味着什么呢?
即所有内存对于用户来说是透明的,即ACPU可以放访问RAM1也可以访问RAM2,但在物理意义上ACPU访问RAM2延迟往往大于RAM1,这就会造成主观感受上的很慢,并且我们再考虑一个极端情况,就是当ACPU和BCPU同时要访问一个RAM1里面的数据,这样二者就造成的抢占,CHIPSET就会介入来让A先访问,B后访问,等等措施,即二者或有先后顺序,但这个过程就或造成等待的问题,在系统层级上感受就是代码运行很慢。
那么有办法控制代码的运行,和架构来匹配吗?
讲完上述内容你会意识到一个问题,在多线程并发运行的时候,是CPU 线程越多越好吗?
并不见得,对于的服务器我们需要合理的,线程数量分配,才能发挥服务器的性能。
基于上述内容,我简单列举四种测试条件,及其收益效果:
存储在同区RAM,多CPU参与运算
有如下程序,在庞大的数据中找到对应的数据并提取出来,此处利用了Pytorch的多线程支持,即index_ select是支持多线程操作的:
import time
import numpy as np
import torch
INDEX = 10000
NELE = 1000
device = torch.device("cpu")
a = torch.rand(INDEX, NELE).to(device)
index = np.random.randint(INDEX - 1, size=INDEX * 8)
b = torch.from_numpy(index).to(device)
for threads in range(1, torch.get_num_threads() * 2):
torch.set_num_threads(threads)
start = time.time()
for _ in range(100):
res = a.index_select(0, b)
print("the number of cpu threads:{} , time {}".format(torch.get_num_threads(), time.time() - start))
数据量相对较小运行的时候 即数据为:INDEX = 10000 NELE = 1000的时候
我们让代码运行看一看在不同线程运行下运行的时间:
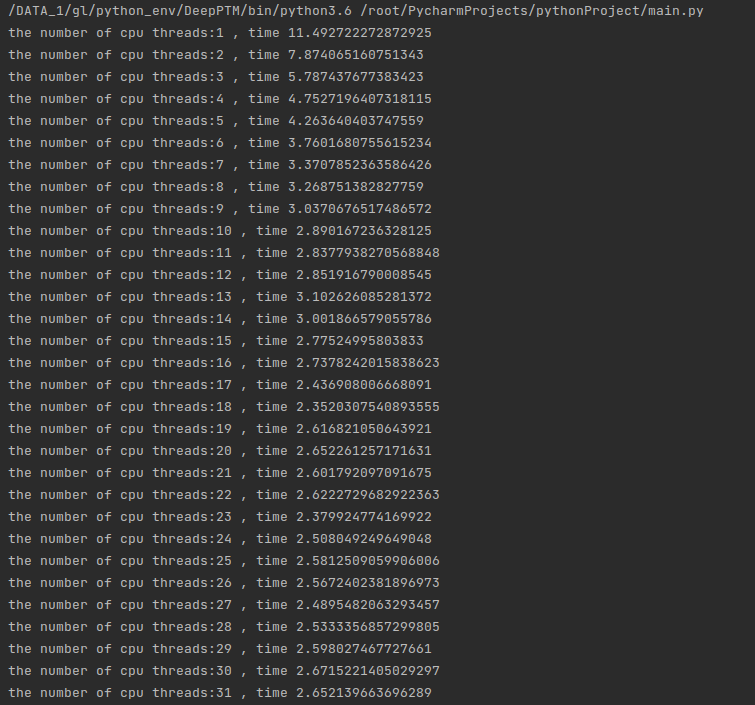
可以看到随着线程增加时间在快速下降,但是需要注意的是,当线程从8-16的时候:
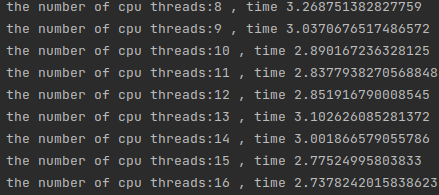
时间下降并不是很明显,是因为在这里启用了超线程技术,即同一个cpu的超线程技术,8个厨师做16道菜,当我们来到16-32线程的时候,时间有了明显的下降:
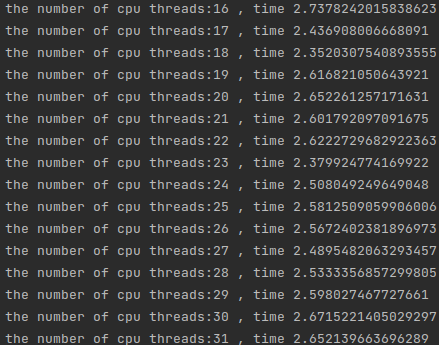
这因为CPU2来参与了运算。同理后边的运算随着线程的增多,多线程的开销反而占了大头,运算反而变慢了,当然这里也有因为双CPU抢占内存读取的问题,也就是说上文的抢占RAM1的情况,当然具体情况不会这么简单,这里想要讨论的是这种情况下甜点在于16线程。
这里的讨论结果具有一次性,并不能作为参考,所以我翻倍增加了内层循环的运行时间,运行结果如下:
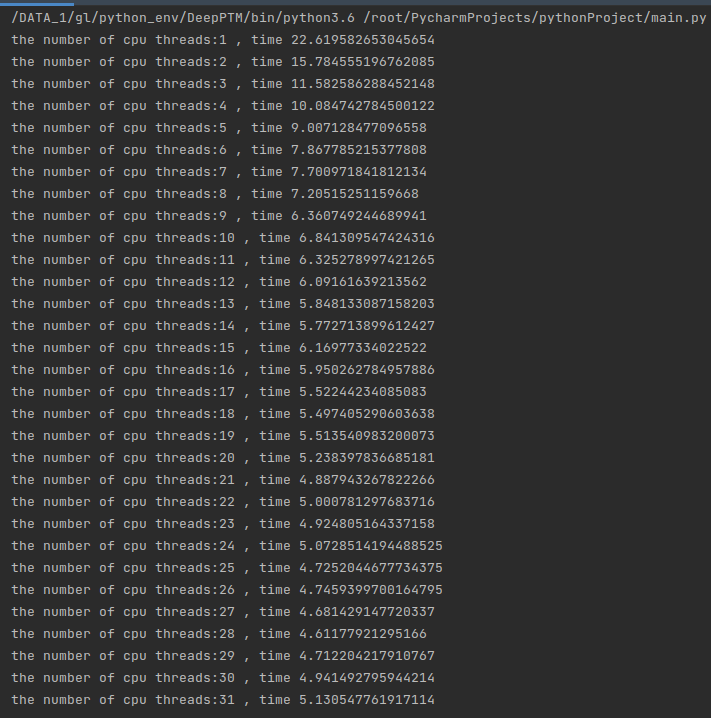
可以看到规律几乎一致。
下图展示了确实调用了很多CPU来运行:

存储在不同区RAM,多CPU参与运算
上文的结果可能令人沮丧,我的双CPU是否废了?
当然不是,也存在一种结果:当申请的内存足够多,如下所示:
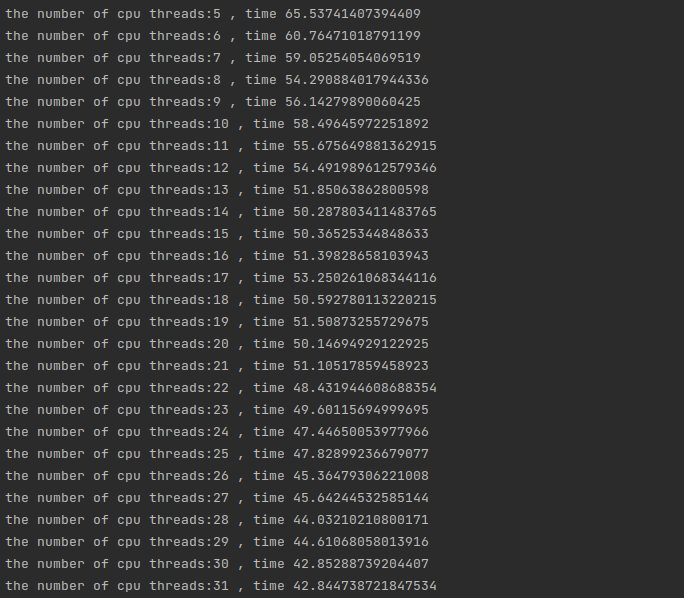
数据量相对较小运行的时候 即数据为:INDEX = 1000000 NELE = 1000的时候
运算的结果会不会像上文一样?当然不是,此时内存峰值已经到到了如下:

远远超过了一半。
那么性能还会保持下降的趋势吗?如果没有保持效果是什么样呢?
由于参数量过大,这里就不使用1到两个线程来实现了可以看到在前8个线程中都保持了比较好的运行性能下降的趋势,此时处于单线程单核心的阶段,性能会保持一个线性的下降:

可看到随着核心数量的变化,CPU运行处于不同的阶段,在跨阶段的时候运行时间会明显增加,这是因为内存访问和CPU抢占、多线程之间的开销三者的互相关系所造成的。所以线程数量往往设定为跨阶段的最终状态是最合适的。
当然这里的结论依赖于内存的高负载使用条件。
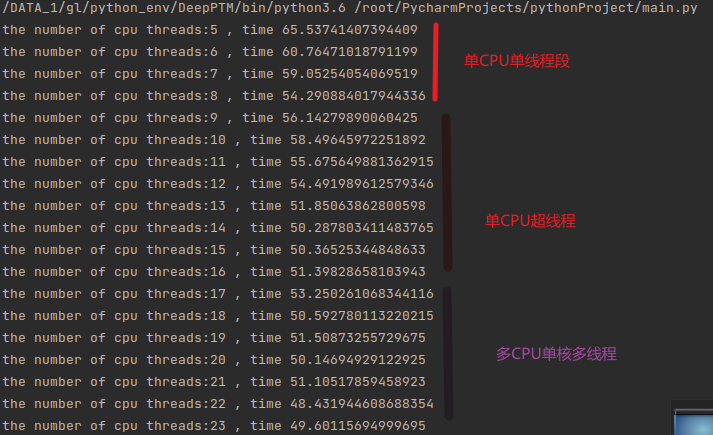
可以看到最终结果呈现出完整的阶段下降趋势:
上述测试方法一定是对的吗?
回到开始,上述的结果一定是对的吗?
我换一套环境来试一下,这一套测试环境为标准的商用PC。
硬件条件如下:

软件条件如下:

在代码相同的情况下,pytorch版本不同,会有什么效果呢?
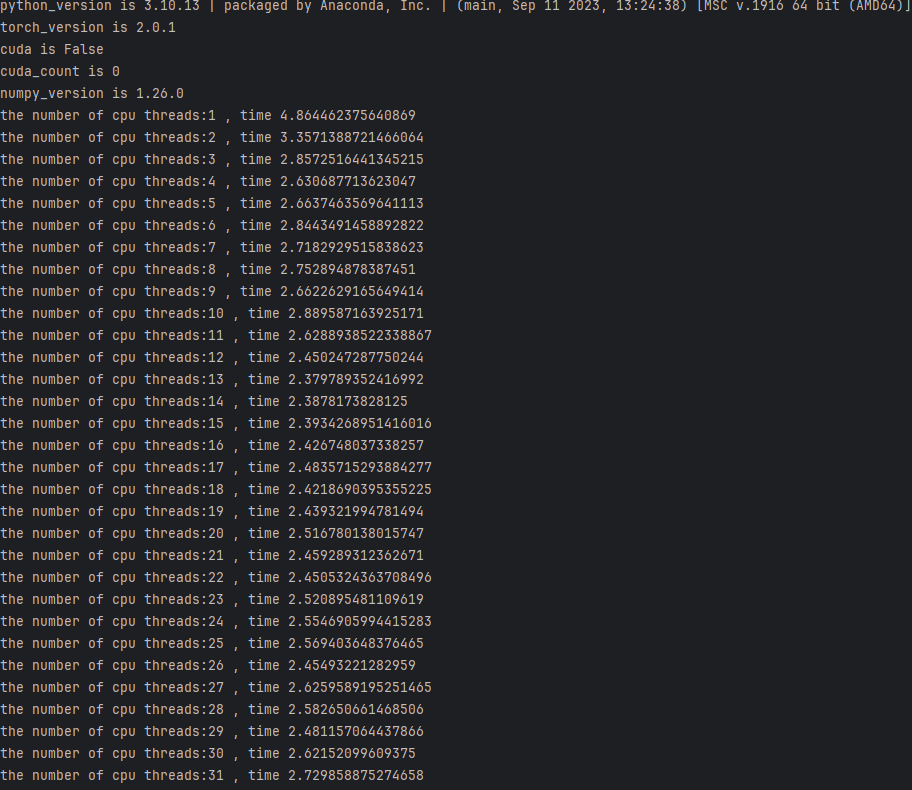
可以看到性能没有任何的增长!这是为什么呢?
我们尝试追踪一下CPU的使用情况,看一看是什么效果:
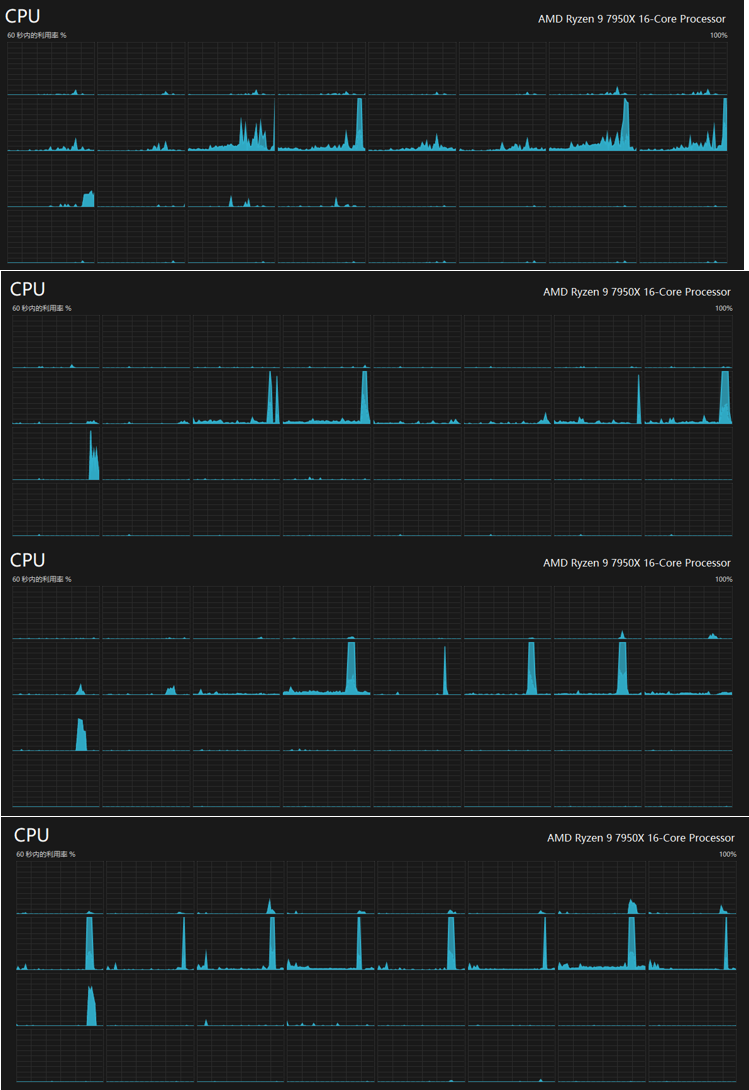
从上到下一共1-4个线程所运行的效果,可以发现1线程的时候也并不是只用一个线程来运行,实际上在Pytorch这种高度封装的框架下,你根本无法详细了解其运行规律和运行方法(除非你联系作者),当然这里并没有解释为什么线程数量增加,性能反而下降了?
以下参考以下回答:
每次模型进行inference的时候,pytorch的核心会fork出多个线程进行Inter-op的并行计算,在每个op计算的内部(Intra-op)又会使用ATen,MKL,MKL-DNN等矩阵加速库进行加速,并使用OpenMP(默认)或TBB进行多线程计算。
这里使用MKL和OpenMP进行多线程计算时默认使用CPU物理线程的一半,具体使用几个线程可以使用torch.get_num_threads()得到,在默认情况下(intel处理器使用MKL和OpenMP)其对应的是两个环境变量:“MKL_NUM_THREADS”和“OMP_NUM_THREADS”。
因此使用multiprocessing实现多个模型并行计算时,默认情况下是每个进程都有物理计算资源一半的使用权限,从而之间存在资源竞争,对应问题中的实验结果就是随着进程数的增多,进程内平均前馈时间是非线性增长,并且进程间前馈时间的方差也会变大,宏观的讲这是资源竞争造成的损失。
如果需要模型在multiprocessing中使用(数据并行计算,或RL中多个actor生成样本等),则最好根据实际需要限定每个进程可以使用的物理线程数量,保证进程间不存在计算资源竞争,也就不会造成资源的浪费了。
我们找到官方文档:
CPU threading and TorchScript inference — PyTorch 2.1 documentation
里面详细解释了关于内部操作和操作之间的多线程的关系:
pytorch的核心会fork出多个线程进行Inter-op的并行计算,在每个op计算的内部(Intra-op)又会使用ATen,MKL,MKL-DNN等矩阵加速库进行加速
当设置torch.set_num_threads(threads),实际上设置的是外部操作之间的多线程,在核心数量足够的时候,宏观上程序调用了1+N个线程来实现操作,这是为什么上文并不是一个线程在跑。
torch.set_num_threads(threads)为数量过多什么会导致性能下降?
原因很简单,内部线程和外部线程之间发生了抢占关系,性能不升反降。
总结一下:
面对多核心CPUS、高度封装的pytorch框架,我们该如何优化程序呢?
铁定律只有一条
实践才是检验真理的唯一标准!
尝试手动设置线程来调优最佳线程数量,小轮次迭代来避免陷入多线程陷阱。(小轮次迭代的同时也要考虑IO吞吐量对程序运行时间的影响,读数据都要20s,迭代1一轮s,你就要循环20s来让运行时间占据优势再进行比较,代码计算时间的位置也要避免开IO读取时间,下图证明了7950XC平台并不是因为IO性能造成的影响):
结论
在内存使用不明显的情况下推荐使用16线程,当然最保险的情况是实验一下,哪个线程比较合适。
在内存使用需要跨俩个CPU的时候,以阶段最多的CPU核心数量为优点,8,16,24不要直接32,系统会卡死!
尝试手动设置线程来调优最佳线程数量,小轮次迭代来避免陷入多线程陷阱。
上文中的各种情况由于硬件平台条件限制,文章篇幅限制,并没有做到非常详尽的讲解和分析,文章的主要目的在于希望大家不要一个劲的多线程数量上升,要明白,实践才是检验真理的唯一标准。
参考文献
CPU threading and TorchScript inference — PyTorch 2.1 documentation
Set the Number of Threads to Use in PyTorch - jdhao's digital space
pytorch模型在multiprocessing下前馈速度明显降低的原因是什么? - 知乎 (zhihu.com)
How to 充分利用你的服务器的更多相关文章
- Pycharm远程连接服务器,并在本地调试服务器代码
问题描述 其实有很多教程了,我只是想记录一下设置得记录,这样就能充分利用阿里云服务器为我跑代码了... 步骤一:配置deployment 步骤二:选择远程python解释器 步骤三:将本地文件上传至远 ...
- 基于GPS北斗卫星授时系统和NTP网络授时服务器的设计与开发
基于GPS北斗卫星授时系统和NTP网络授时服务器的设计与开发 安徽京准科技提供@请勿转载@@ 更多资料请参考——ahjzsz.com 天文观测设备对于控制系统的时间准确度有严格要求.为此,采用搭建高精 ...
- 架构设计:一种远程调用服务的设计构思(zookeeper的一种应用实践)
在深入学习zookeeper我想先给大家介绍一个和zookeeper相关的应用实例,我把这个实例命名为远程调用服务.通过对这种应用实例的描述,我们会对zookeeper应用场景会有深入的了解. 远程调 ...
- mysql 5.5多实例部署【图解】
mysql5.5数据库多实例部署,我们可以分以下几个步骤来完成. 1. mysql多实例的原理 2. mysql多实例的特点 3. mysql多实例应用场景 4. mysql5.5多实例部署方法 一. ...
- 烂泥:mysql5.5多实例部署
本文由秀依林枫提供友情赞助,首发于烂泥行天下. mysql5.5数据库多实例部署,我们可以分以下几个步骤来完成. 1. mysql多实例的原理 2. mysql多实例的特点 3. mysql多实例应用 ...
- CDN技术
CDN 是构建在数据网络上的一种分布式的内容分发网. CDN 的作用是采用流媒体服务器集群技术,克服单机系统输出带宽及并发能力不足的缺点,可极大提升系统支持的并发流数目,减少或避免单点失效带来的不良影 ...
- [转]Reed Solomon纠删码
[转]Reed Solomon纠删码 http://peterylh.blog.163.com/blog/static/12033201371375050233/ 纠删码是存储领域常用的 ...
- cdn是什么和作用有些
内容分发网络其基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快.更稳定.通过在网络各处放置节点服务器所构 成的在现有的互联网基础之上的一层智能虚拟网络,CDN系 ...
- MySQL入门笔记
MySQL入门笔记 版本选择: 5.x.20 以上版本比较稳定 一.MySQL的三种安装方式: 安装MySQL的方式常见的有三种: · rpm包形式 · 通用二进制 ...
- Dropbox可伸缩性设计最佳实践分享
http://www.infoq.com/cn/news/2012/11/dropbox-scale-bestpractice Dropbox的运维工程师Rajiv,跟大家分享了可伸缩性设计的最佳实践 ...
随机推荐
- 【cJSON】轻量级的C语言JSON解析器
C++ 进阶版:[CJsonObject]C++ JSON 解析器使用教程 1. JSON与cJSON JSON -- 轻量级的数据格式 JSON 全称 JavaScript Object Notat ...
- Codeforces Global Round 12(个人题解)
1450A. Avoid Trygub 挺简单的题,题意是避免字符串中有子串"Trygub" 只要给字符串排序就可以了,这样一定不会出现 void solve() { string ...
- vivo 微服务 API 网关架构实践
一.背景介绍 网关作为微服务生态中的重要一环,由于历史原因,中间件团队没有统一的微服务API网关,为此准备技术预研打造一个功能齐全.可用性高的业务网关. 二.技术选型 常见的开源网关按照语言分类有如下 ...
- Web Components从技术解析到生态应用个人心得指北
Web Components浅析 Web Components 是一种使用封装的.可重用的 HTML 标签.样式和行为来创建自定义元素的 Web 技术. Web Components 自己本身不是一个 ...
- 阿里云张建锋:核心云产品全面 Serverless 化
11月3日,2022 杭州 · 云栖大会上,阿里云智能总裁张建锋表示,以云为核心的新型计算体系正在形成,软件研发范式正在发生新的变革,Serverless 是其中最重要的趋势之一,阿里云将坚定推进核心 ...
- WebGPU光追引擎基础课:使用WebGPU绘制三角形
大家好~我开设了"WebGPU光追引擎基础课"的线上课程,从0开始,在课上带领大家现场写代码,使用WebGPU开发基础的光线追踪引擎 课程重点在于基于GPU并行计算,实现BVH构建 ...
- LaTex · overleaf | 使用技巧存档
如何使用 bibtex:http://www.taodudu.cc/news/show-5832925.html?action=onClick bibtex 格式:https://blog.csdn. ...
- mybatis plus 中增删改查及Wrapper的使用
本文为博主原创,未经允许不得转载: mybatis plus 通过封装 baseMapper 以及 ServiceImpl ,实现对数据库的增删改查操作,baseMapper 是我们通常所说的 da ...
- C语言中的操作符:了解与实践
欢迎大家来到贝蒂大讲堂 养成好习惯,先赞后看哦~ 所属专栏:C语言学习 贝蒂的主页:Betty's blog 1. 操作符的分类 操作符又叫运算符,它在C语言中起着非常大的作用,以下是 ...
- [转帖]git常用命令
https://www.cnblogs.com/xingmuxin/p/11416870.html GitHub可以托管各种git库,并提供一个web界面,但与其它像 SourceForge或Goog ...