mysql 索引优化 explain,复合索引,联合索引,优化 user_base 和 log_login 实战


本节是关于MySQL的复合索引相关的知识,两个或更多个列上的索引被称作复合索引,本文主要介绍了mysql 联合索引生效的条件及失效的条件
对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c)。 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找;
复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。如果您知道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。所以说创建复合索引时,应该仔细考虑列的顺序。对索引中的所有列执行搜索或仅对前几列执行搜索时,复合索引非常有用;仅对后面的任意列执行搜索时,复合索引则没有用处。
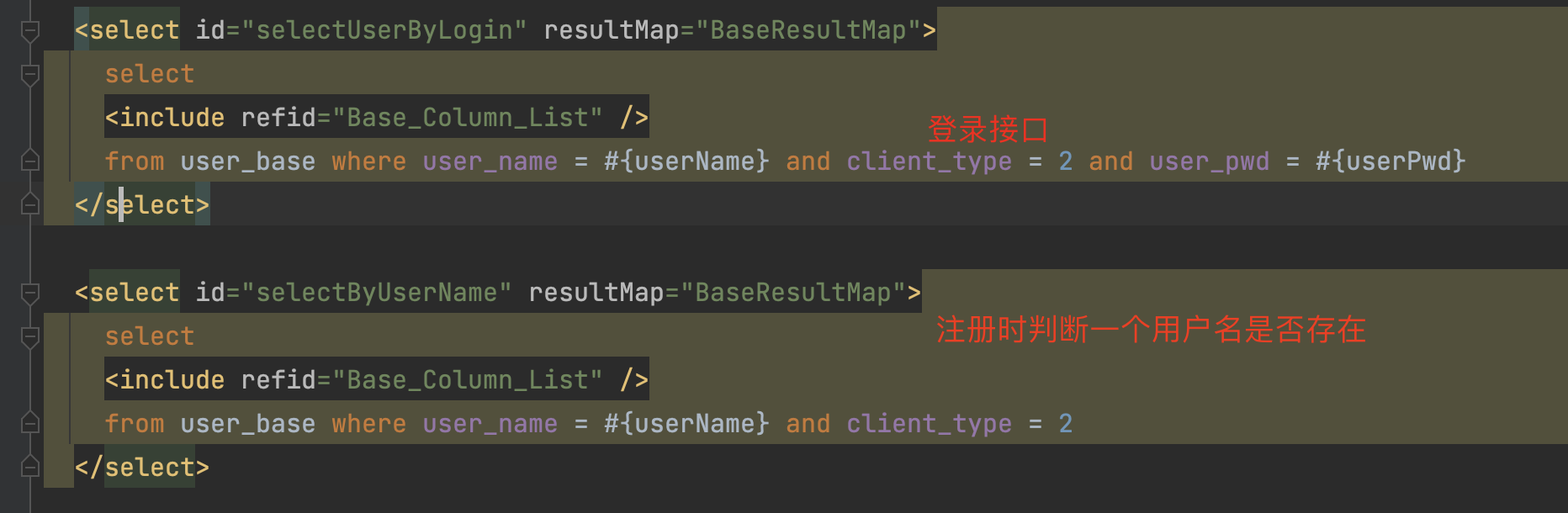
可见 登录和注册时判断一个用户名是否存在都使用了 user_name + client_type 这2列,且要求用户名 + 终端类型 必须唯一,若只单独给这2列加一个唯一索引,则登录时 又查询了 user_pwd 所以,最好这3列一并组成一个唯一索引,才能发挥最佳效率,以下我们测试一下:
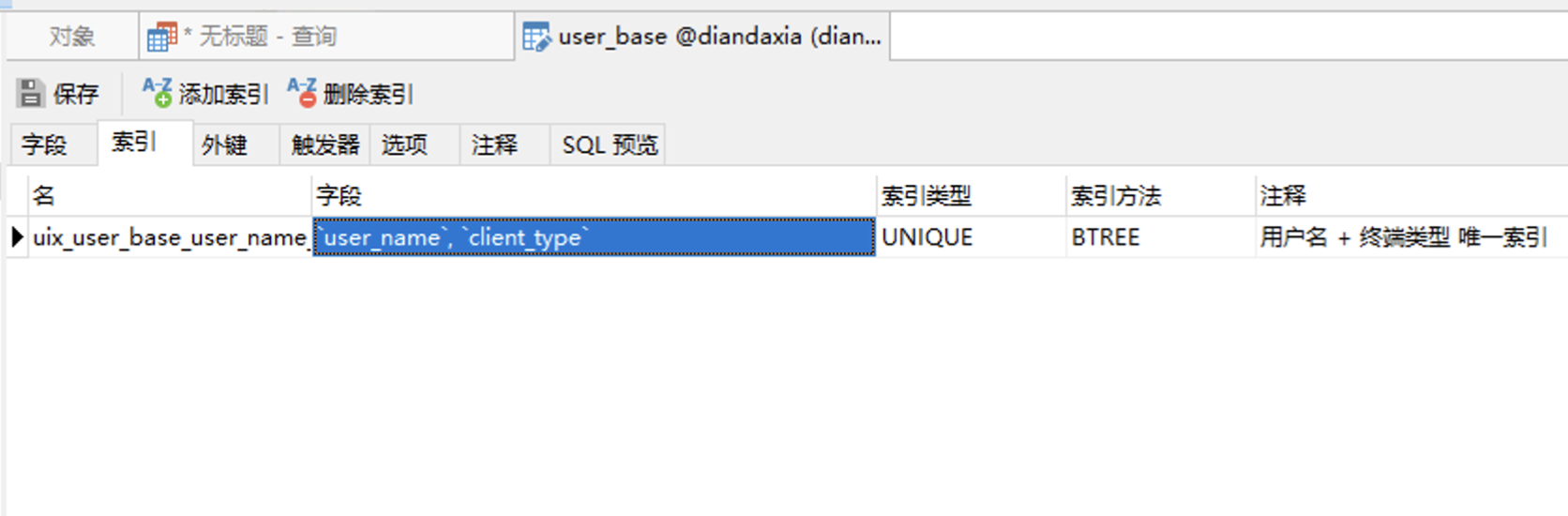
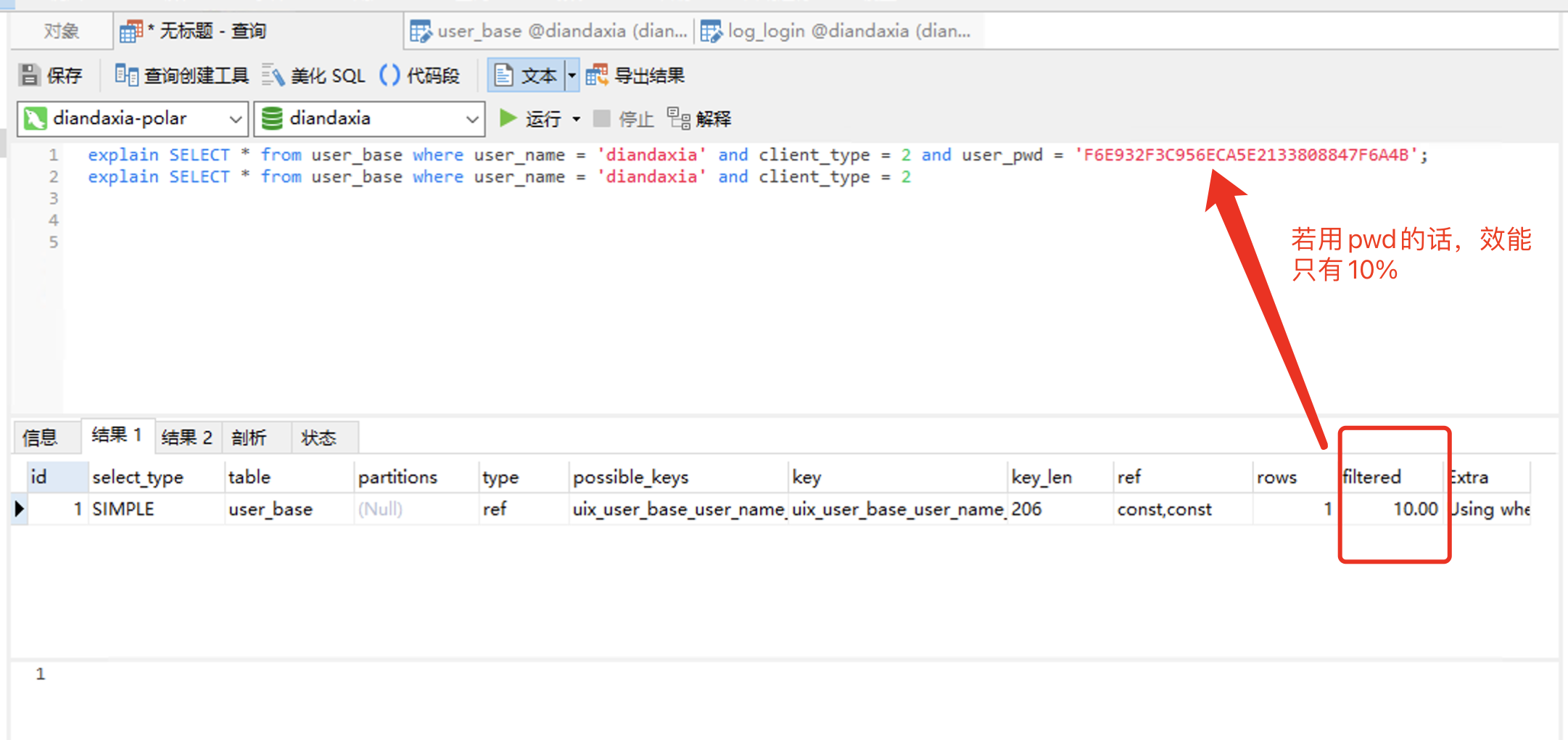
1. 首先只user_name + client_type 组成唯一索引,若登录的话看下查询效能:
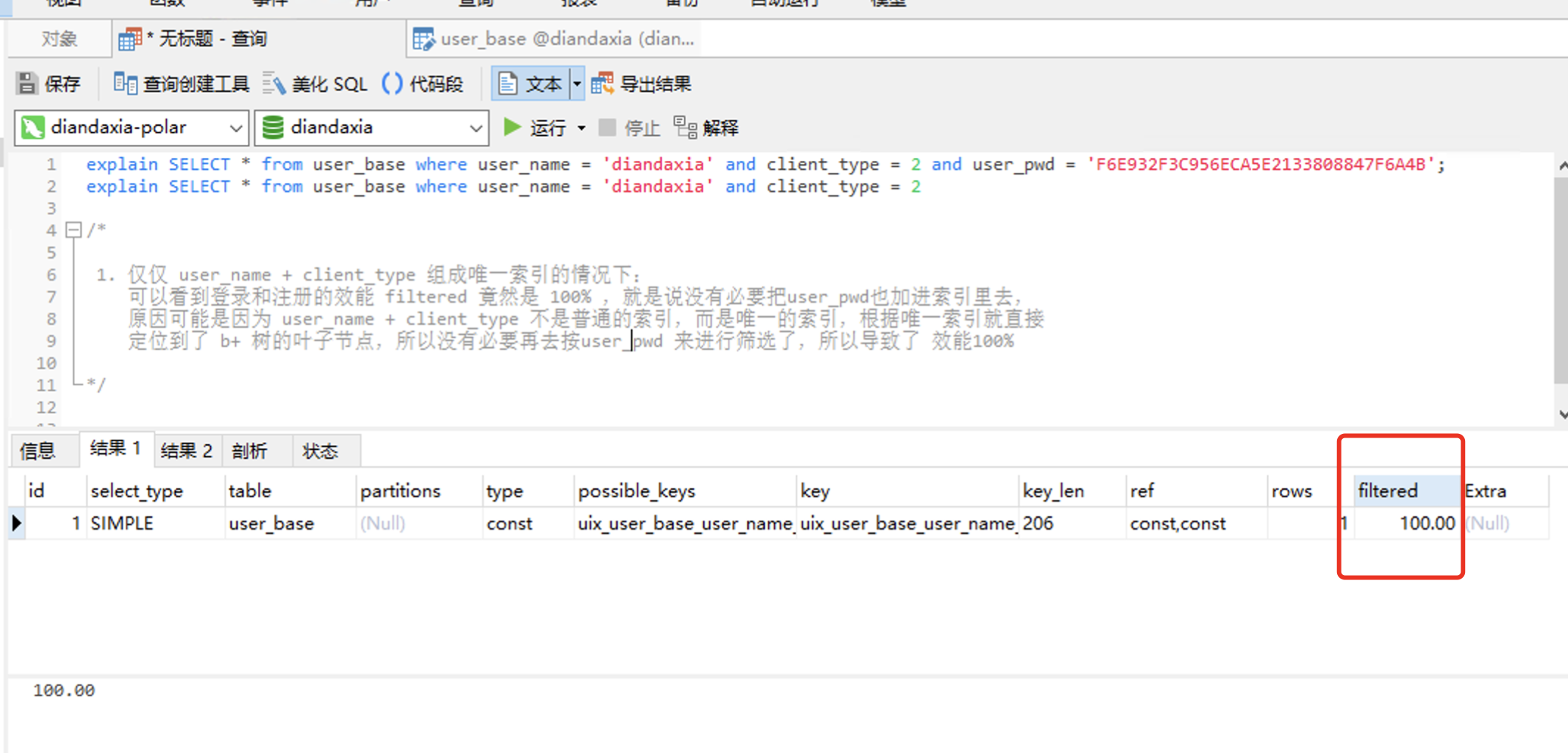
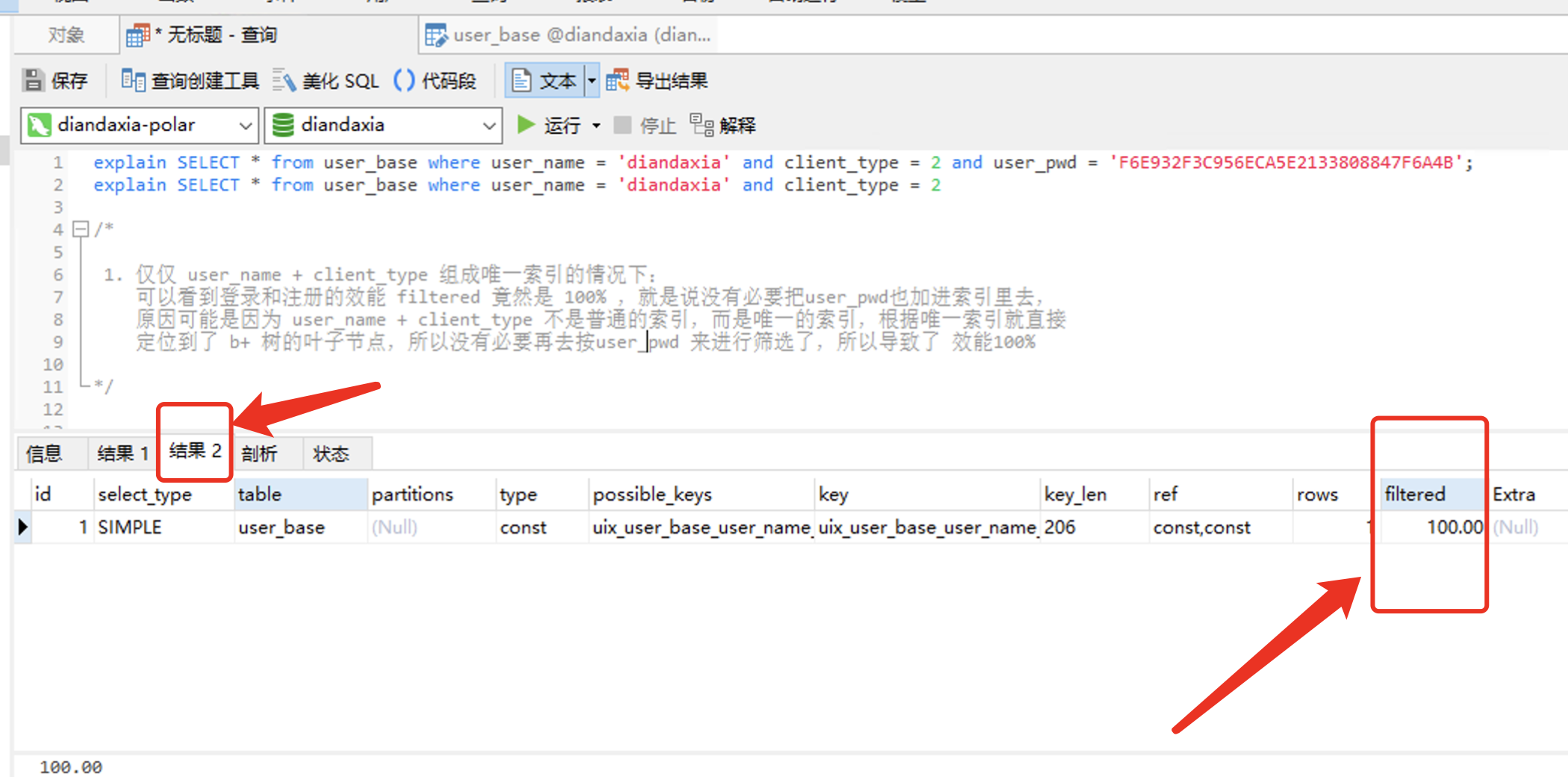
explain SELECT * from user_base where user_name = 'diandaxia' and client_type = 2 and user_pwd = 'F6E932F3C956ECA5E2133808847F6A4B';
explain SELECT * from user_base where user_name = 'diandaxia' and client_type = 2 /* 1. 仅仅 user_name + client_type 组成唯一索引的情况下:
可以看到登录和注册的效能 filtered 竟然是 100% ,就是说没有必要把user_pwd也加进索引里去,
原因可能是因为 user_name + client_type 不是普通的索引,而是唯一的索引,根据唯一索引就直接
定位到了 b+ 树的叶子节点,所以没有必要再去按user_pwd 来进行筛选了,所以导致了 效能100% */
2. 根据上面的分析,接下来这样搞下,把user_name + client_type 搞成 非 唯一索引。再来测试一下效能:
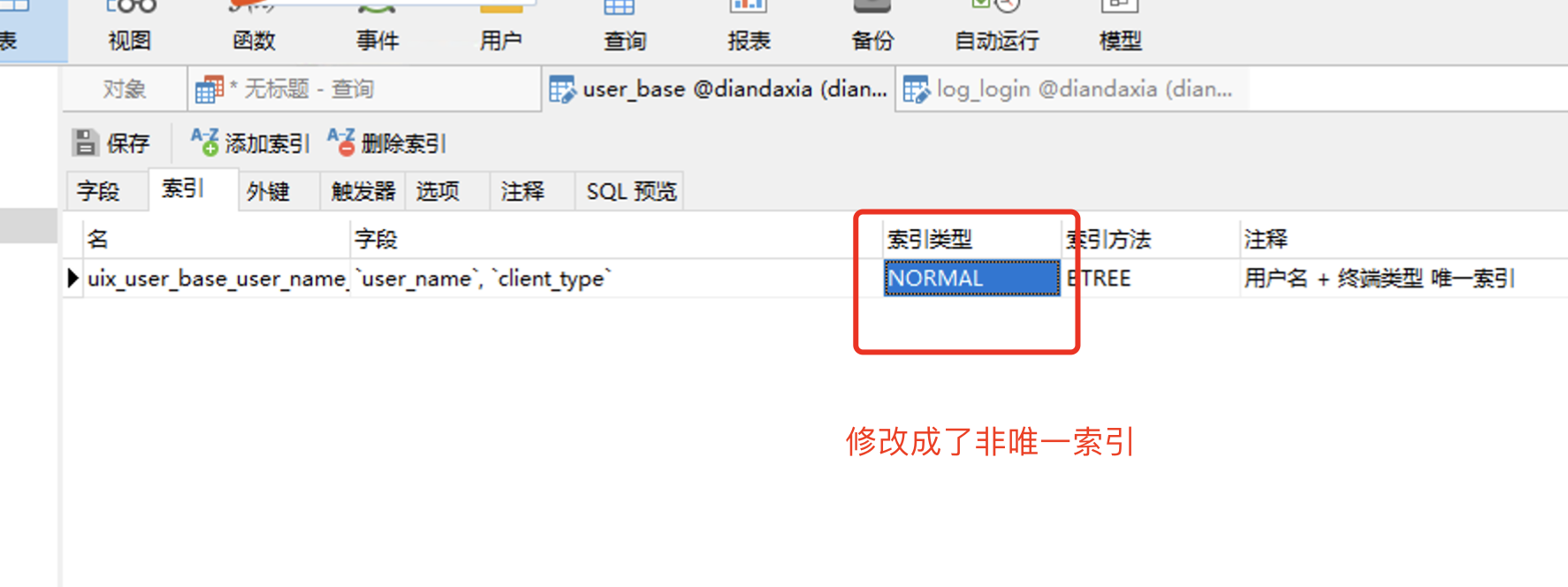
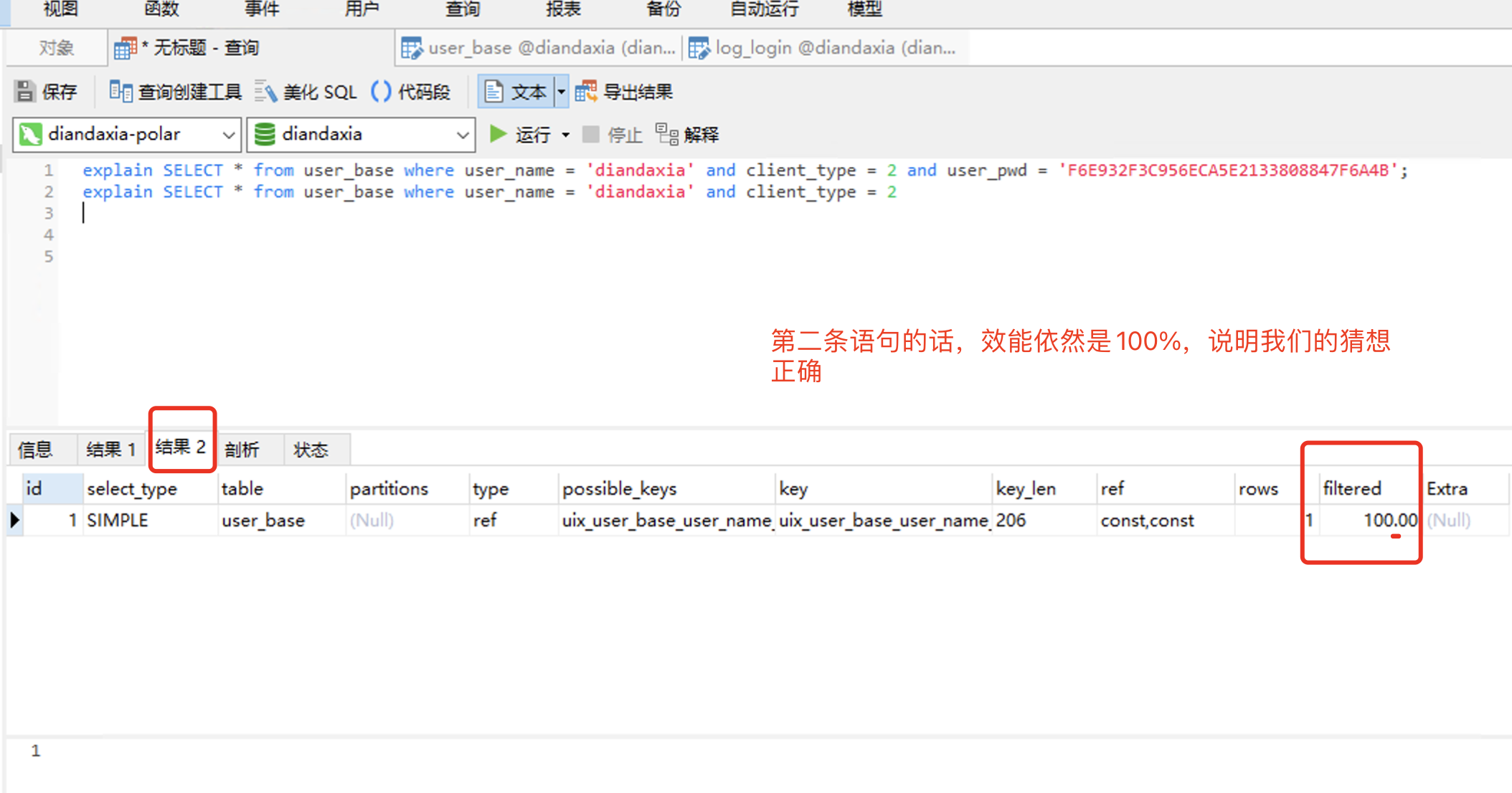
所以,user_base 表中,只需要 user_name + client_type 组成唯一索引就行了,没有必要把 user_pwd 也加进索引中,浪费索引空间。这点对我以后用户表的开发设计,非常重要的思想,即只要是用户表 通常就是
1. 若没有client_type项的话,user_id 主键 、user_name 唯一索引;
2. 若有 client_type 字段的话,则是 user_id 主键、user_name + client_type 唯一索引就可 保证登录 + 注册时判断用户是否存在 最优化。
好了,接下来 开始优化一下 log_login 表的索引,因为这个表也是常用的表;
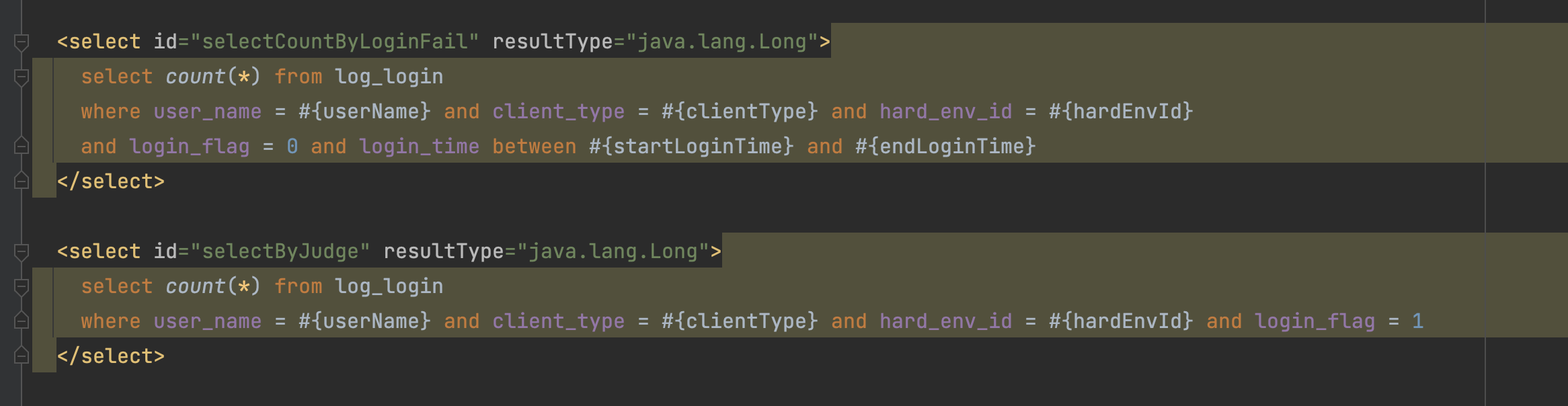
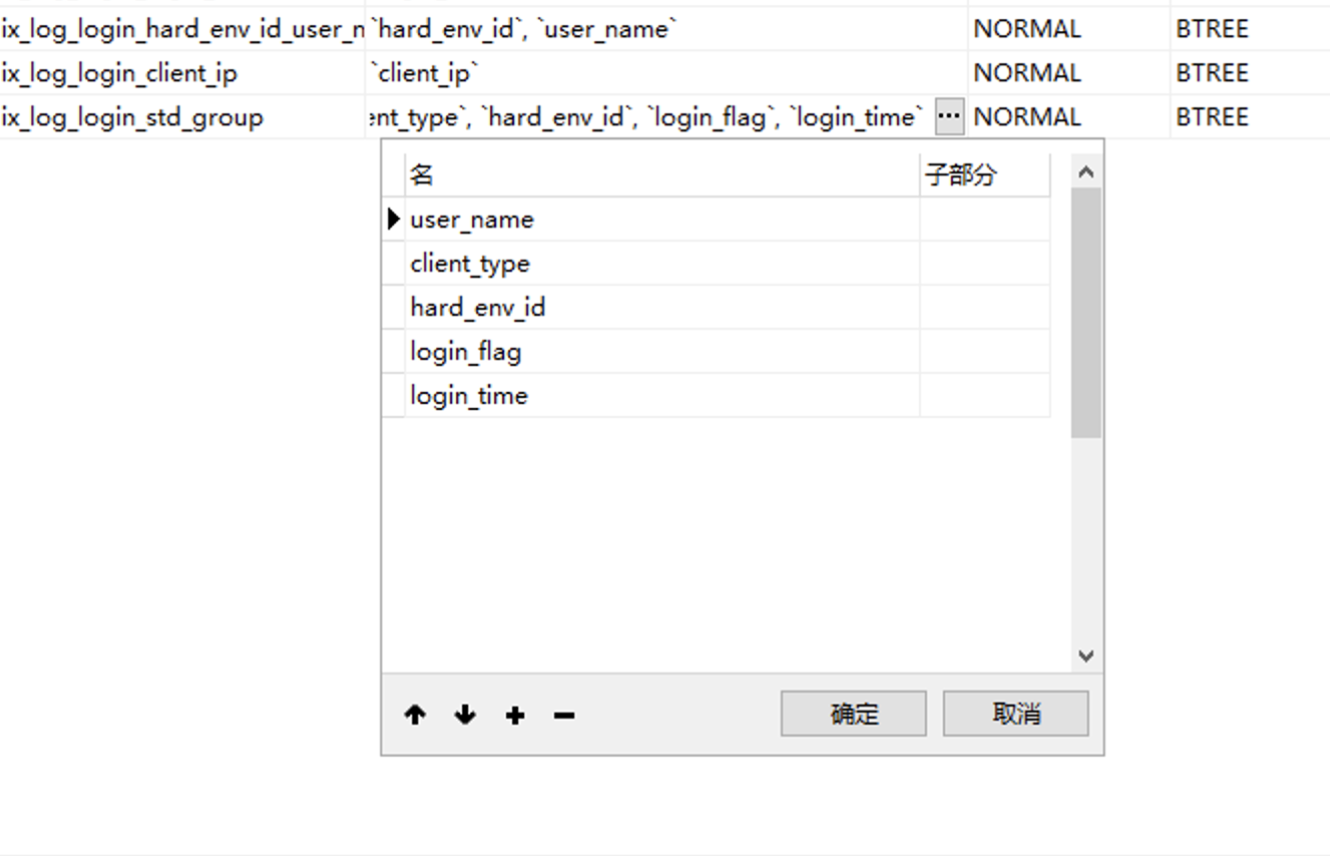
可以看到,这2个查询 都用到了 user_name + client_type + hard_env_id + login_flag 所以 这 4列 应该是可以确定的需要组成一个索引,没有必要是唯一索引,因为业务上 这个不唯一。
那么 login_time 呢,这个需要也加索引吗,接下来就用 explain 来测试 对比下 效能
1. 仅那4列 有索引
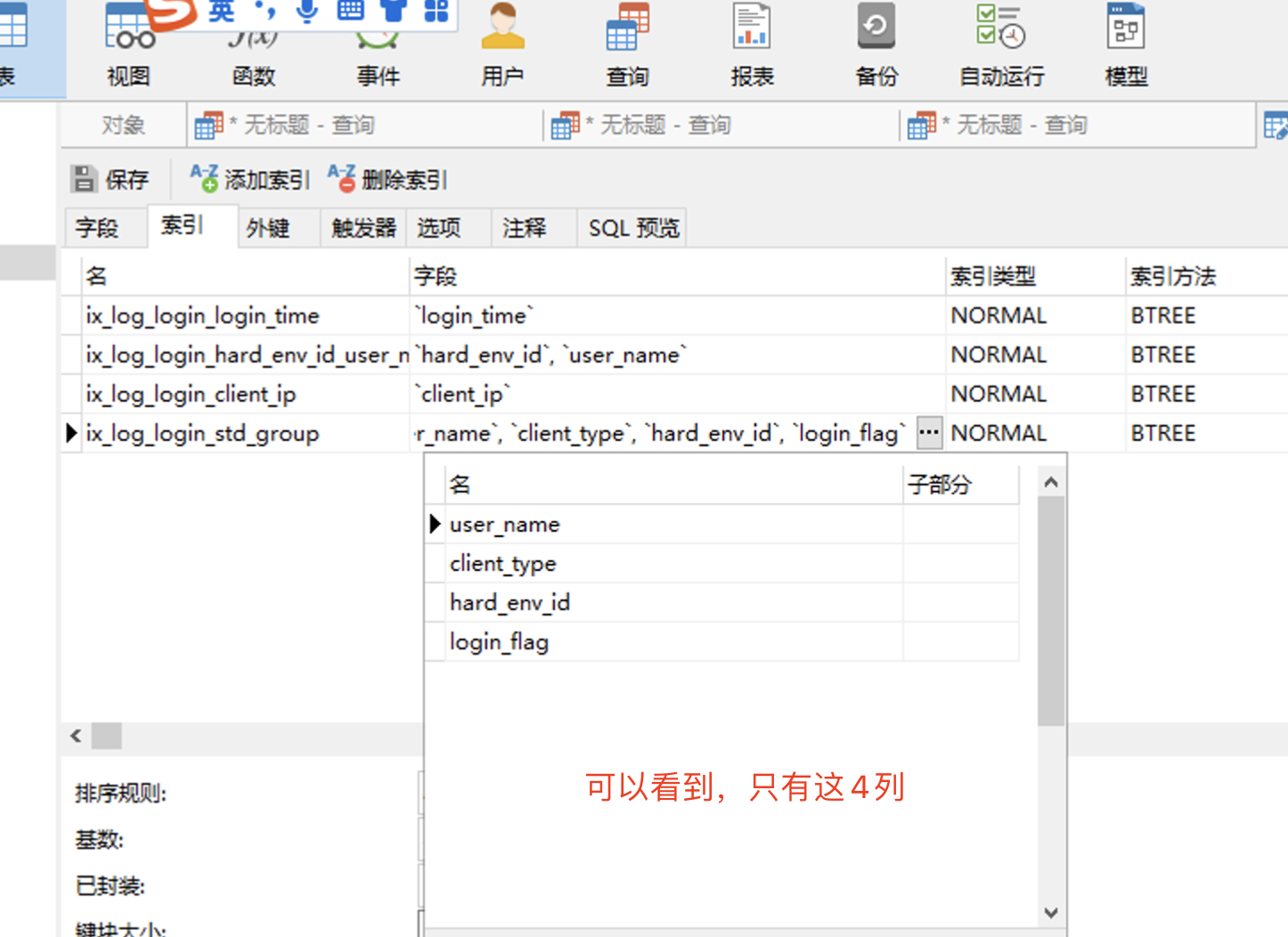
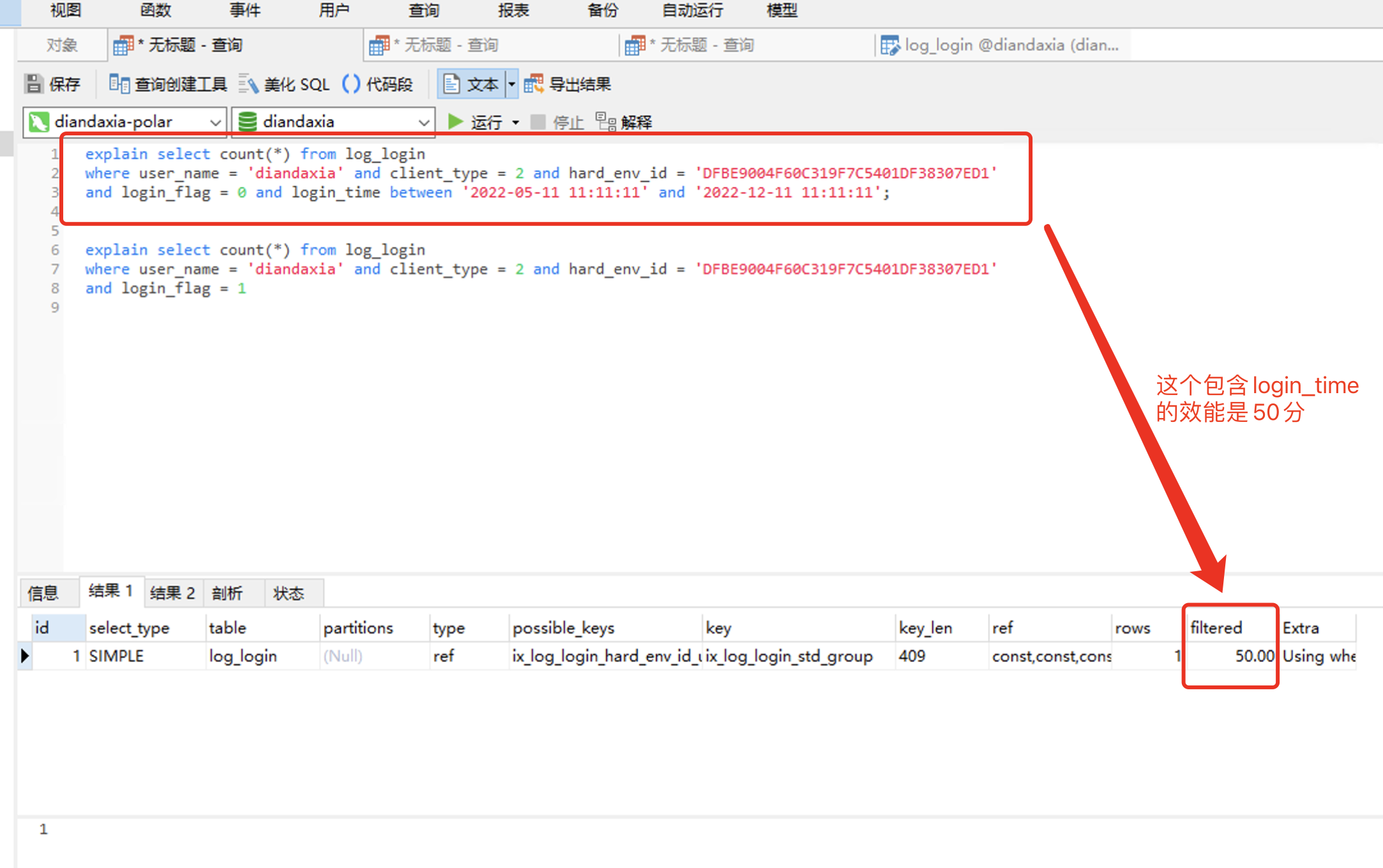
2. 接下来就是给把login_time 也加进组合索引中去:
explain select count(*) from log_login
where user_name = 'diandaxia' and client_type = 2 and hard_env_id = 'DFBE9004F60C319F7C5401DF38307ED1'
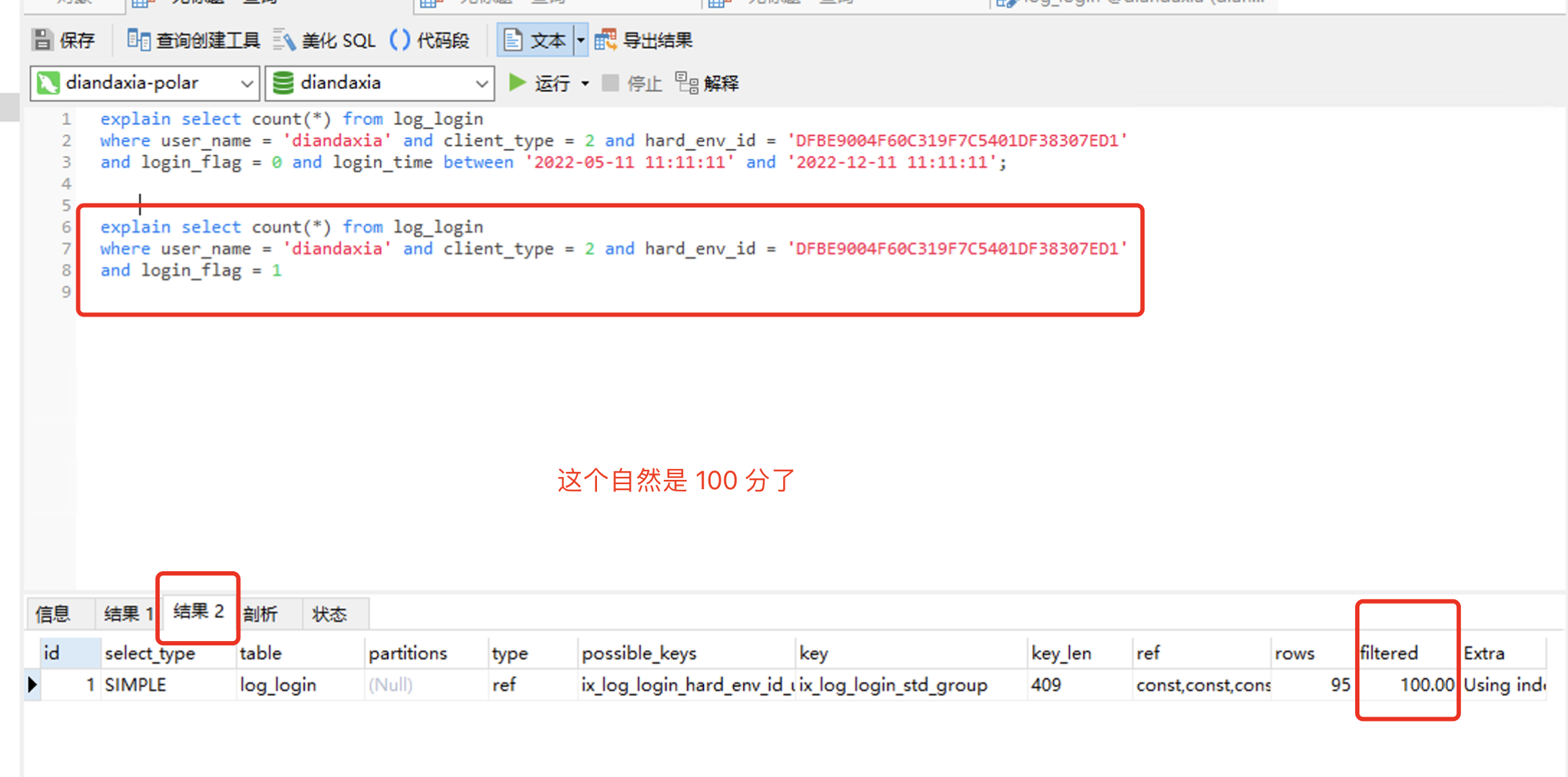
and login_flag = 0 and login_time between '2022-05-11 11:11:11' and '2022-12-11 11:11:11'; explain select count(*) from log_login
where user_name = 'diandaxia' and client_type = 2 and hard_env_id = 'DFBE9004F60C319F7C5401DF38307ED1'
and login_flag = 1
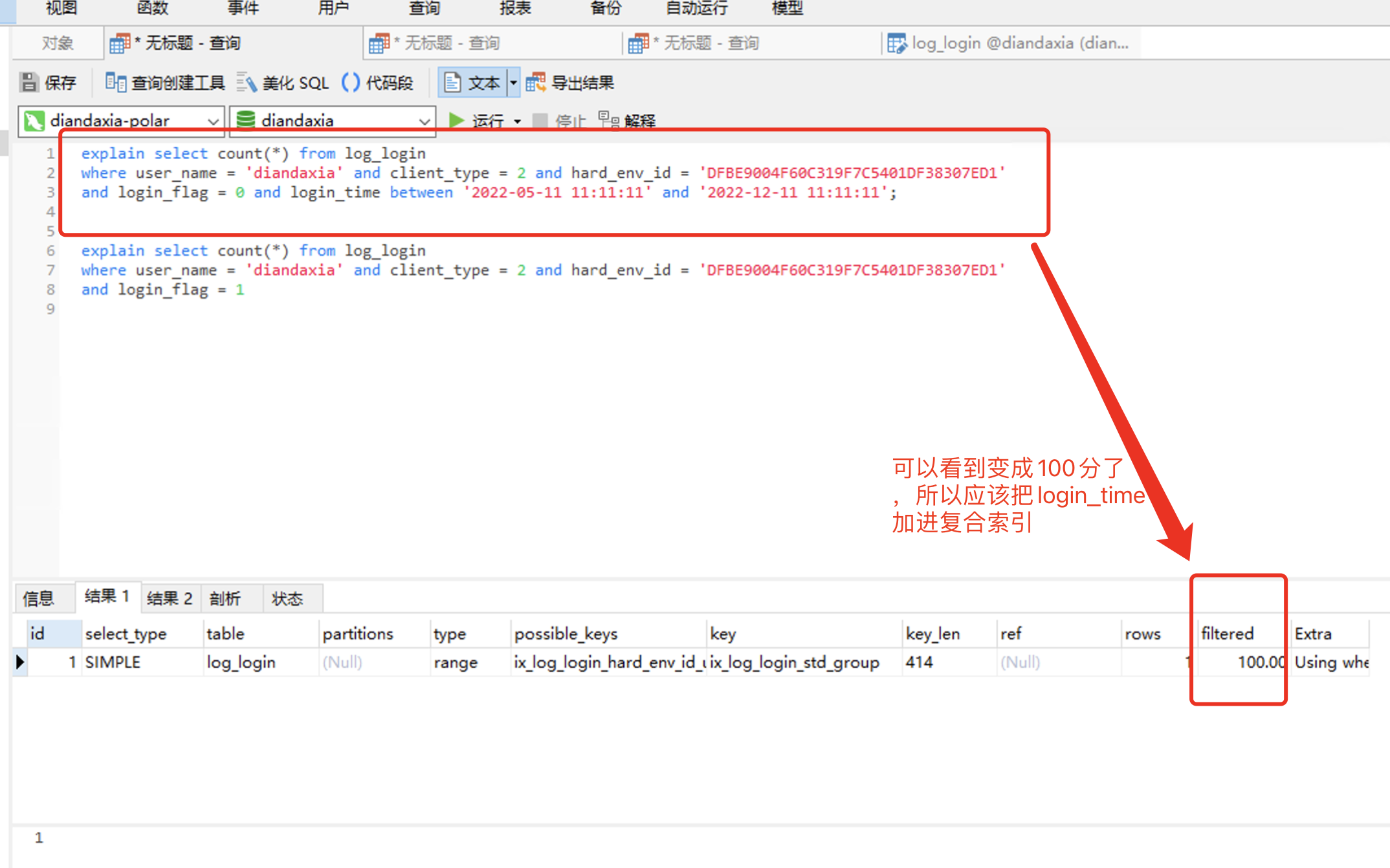
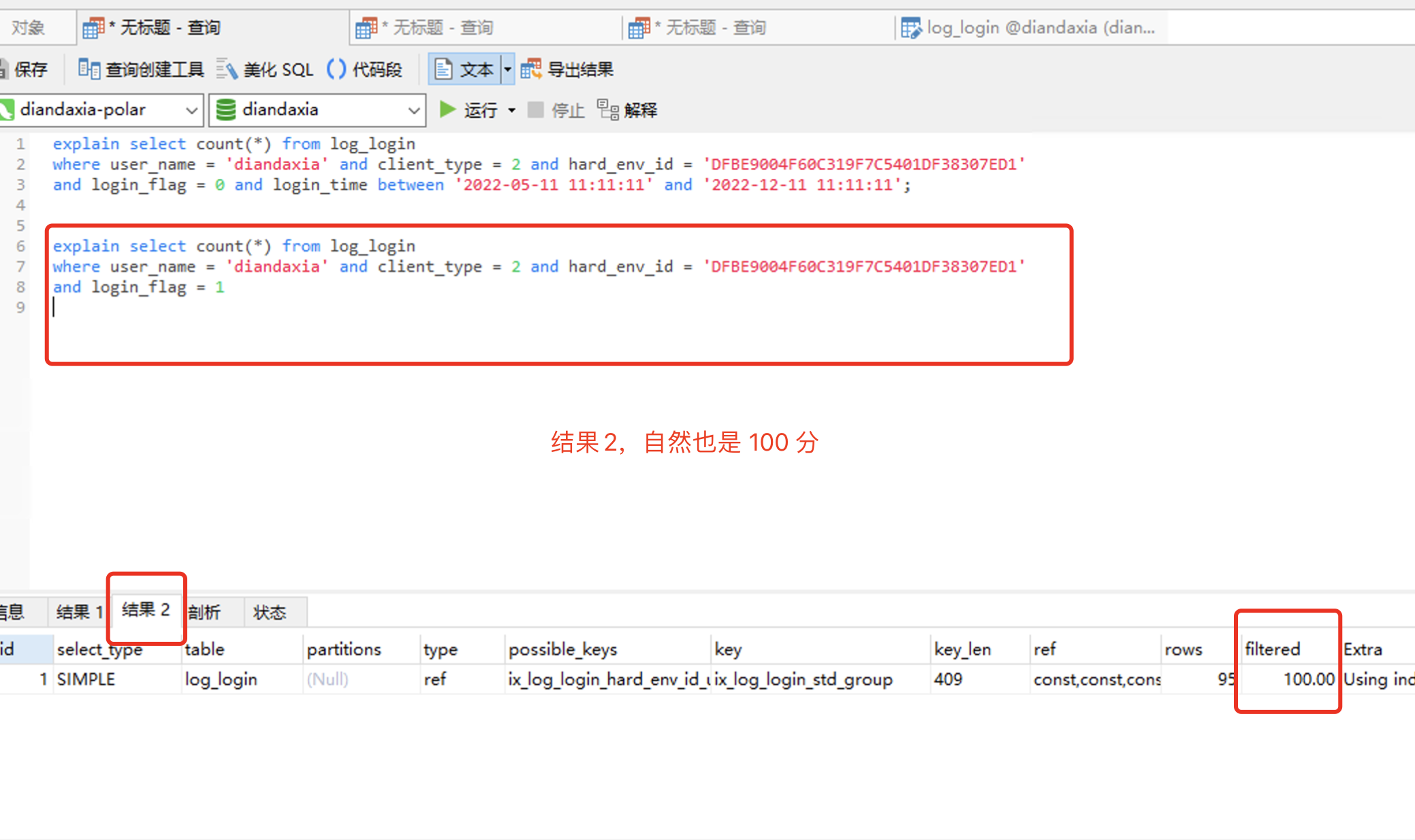
====================================================================
这里我又有个疑问,就是 联合索引里,若有范围查询的怎么办,比如上面的这个login_time ,这个需要 大于 或 小于 这种的 范围查询

接下来我们测试一下,把login_time 放到 中间,看看,是否会向他说的那样,后阻碍后面的索引;
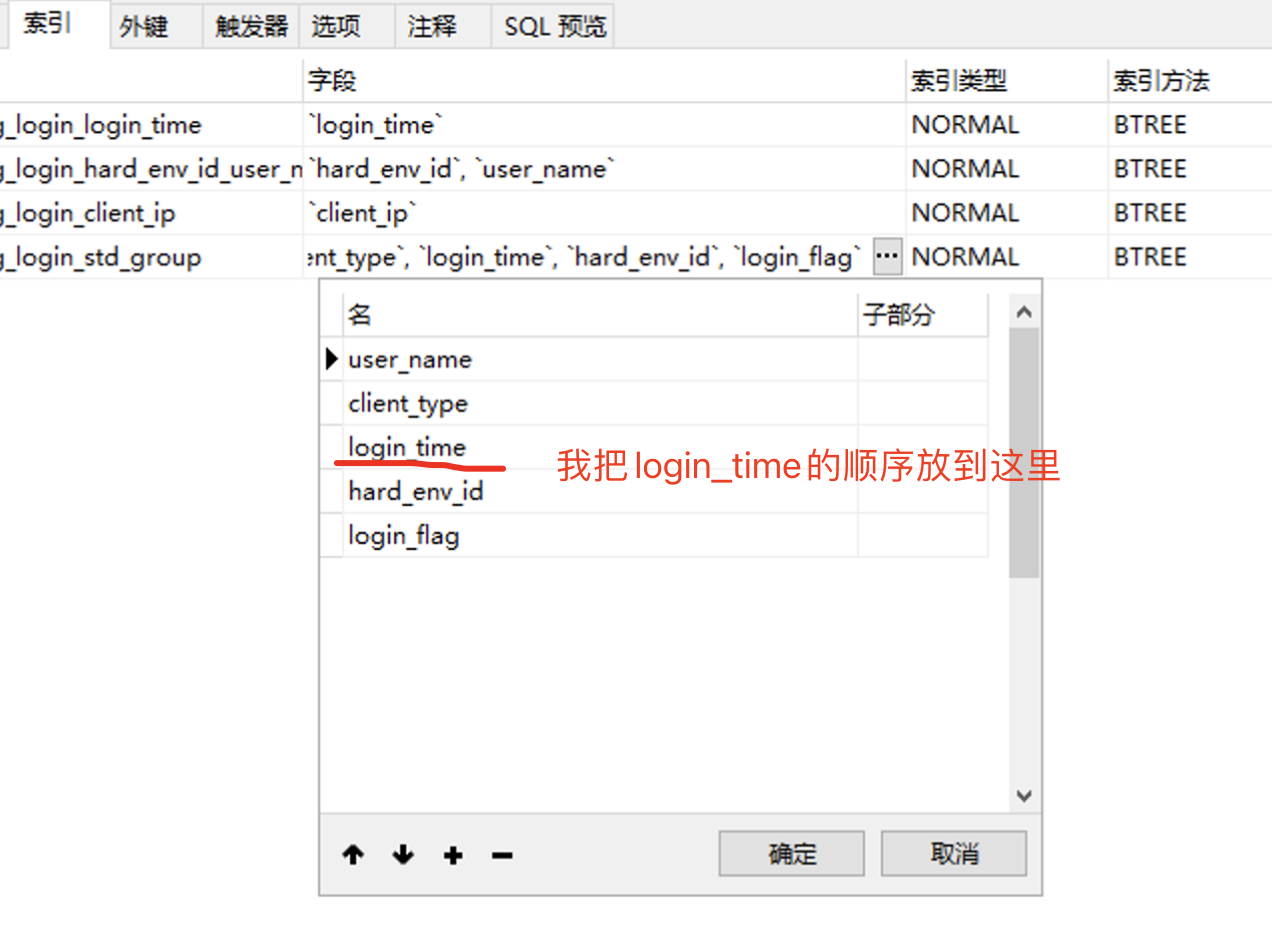
然后sql语句修改下:
explain select count(*) from log_login
where user_name = 'diandaxia' and client_type = 2 and login_time between '2022-05-11 11:11:11' and '2022-12-11 11:11:11'
and hard_env_id = 'DFBE9004F60C319F7C5401DF38307ED1' and login_flag = 0;
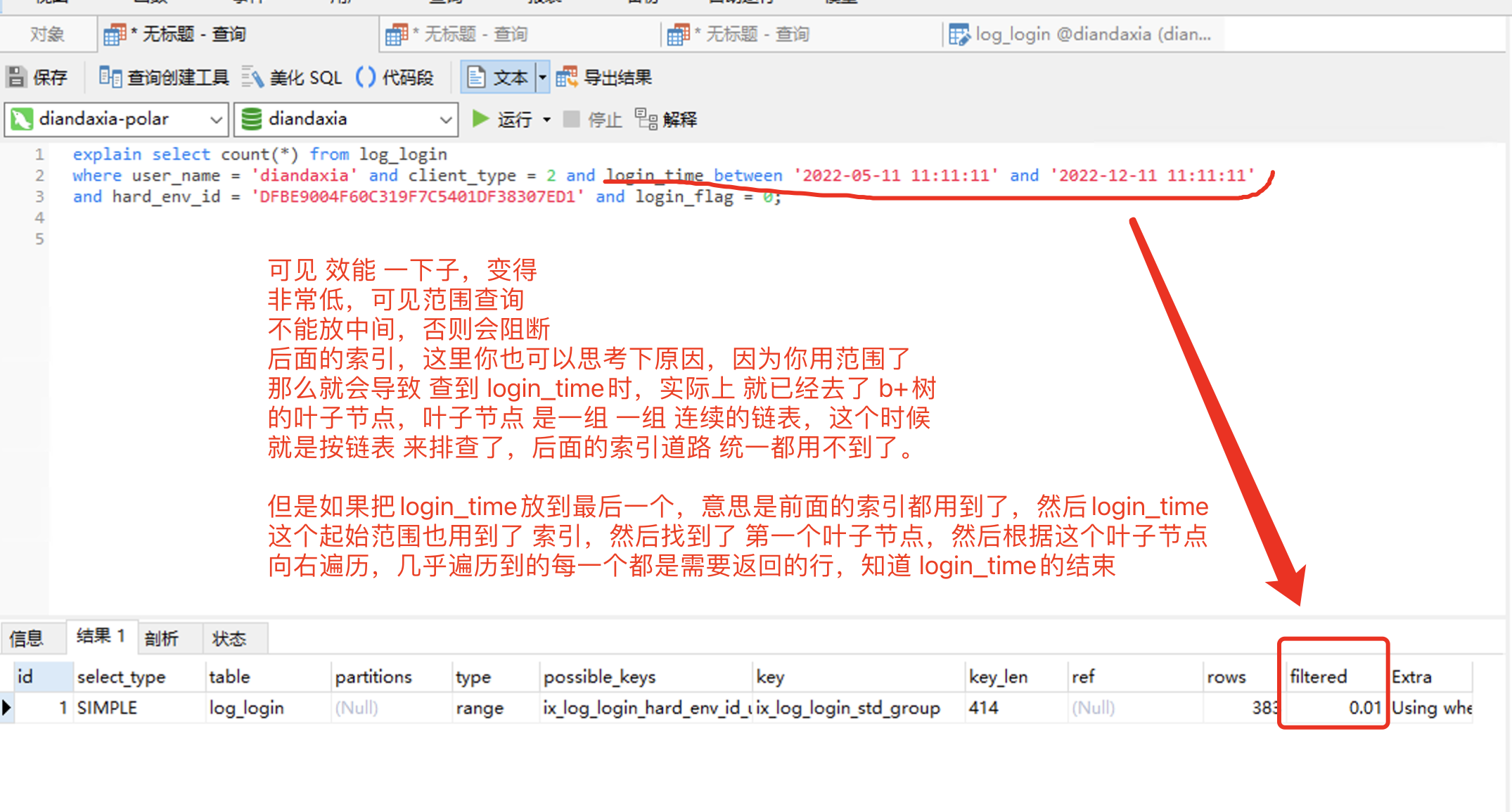
最后 B+ 树的原理:
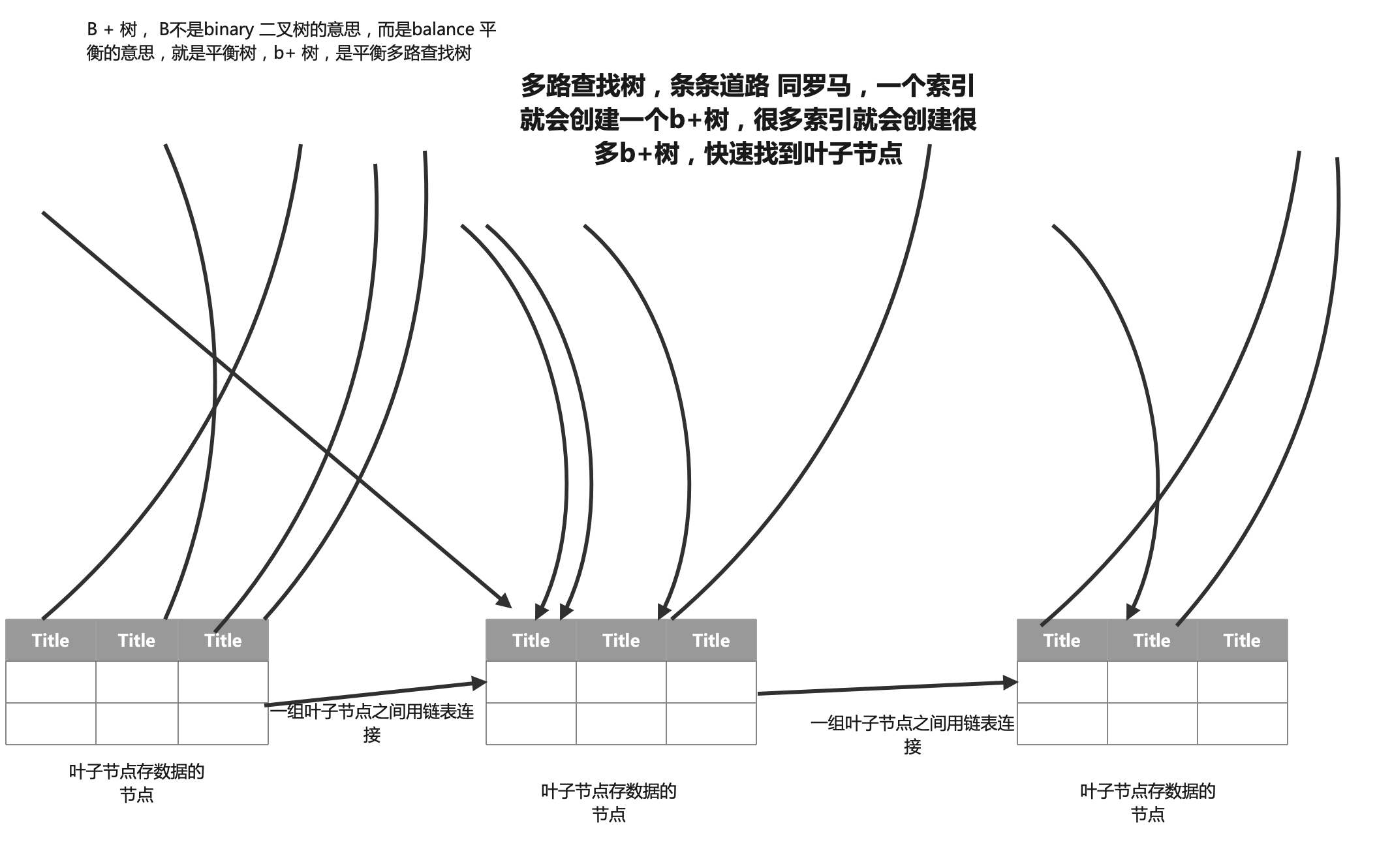
mysql 索引优化 explain,复合索引,联合索引,优化 user_base 和 log_login 实战的更多相关文章
- MYSQL 什么时候用单列索引?什么使用用联合索引?(收集)
我一个表 students 表,有3个字段 ,id,name,age 我要查询 通过 name 和age,在这两个字段 是创建 联合索引?还是分别在name和age上创建 单列索引呢? 多个字段查询什 ...
- MYSQL 什么时候用单列索引?什么使用用联合索引?
我一个表 students 表,有3个字段 ,id,name,age 我要查询 通过 name 和age,在这两个字段 是创建 联合索引?还是分别在name和age上创建 单列索引呢? 多个字段查询什 ...
- [MySQL] mysql索引的长度计算和联合索引
1.所有的索引字段,如果没有设置not null,则需要加一个字节.2.定长字段,int占4个字节.date占3个字节.char(n)占n个字符.3.变长字段,varchar(n),则有n个字符+两个 ...
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(十二)数据层优化-explain关键字及慢sql优化
本文提要 从编码角度来优化数据层的话,我首先会去查一下项目中运行的sql语句,定位到瓶颈是否出现在这里,首先去优化sql语句,而慢sql就是其中的主要优化对象,对于慢sql,顾名思义就是花费较多执行时 ...
- mysql索引之四:复合索引之最左前缀原理,索引选择性,索引优化策略之前缀索引
高效使用索引的首要条件是知道什么样的查询会使用到索引,这个问题和B+Tree中的“最左前缀原理”有关,下面通过例子说明最左前缀原理. 一.最左前缀索引 这里先说一下联合索引的概念.MySQL中的索引可 ...
- mysql索引 多个单列索引和联合索引的区别详解
背景: 为了提高数据库效率,建索引是家常便饭:那么当查询条件为2个及以上时,我们是创建多个单列索引还是创建一个联合索引好呢?他们之间的区别是什么?哪个效率高呢?我在这里详细测试分析下. 一.联合索引测 ...
- mySql单列索引与联合索引的区别
引自https://my.oschina.net/857359351/blog/658668 第一张表gift和索引为联合索引,如图: 第二张表gift2为单列索引,如图: 下面开始进行测试: 相同的 ...
- mysql 索引学习--多条件等值查询,顺序不同也能应用联合索引啦
以前学习这一块的时候,是说:假设建立了联合索引a+b,那么查询语句也一定要是这个顺序才能应用该索引. 那么实际是怎样呢,经过mysql这么多次版本升级,相信mysql已经给我们做了某些优化. 下面是我 ...
- MySQL单列索引和组合索引(联合索引)的区别详解
发现index merge局限性,优化器会自动判断是否使用 index merge 优化技术,查询还是需要组合索引[推荐阅读:对mysql使用索引的误解] MySQL单列索引和组合索引(联合索引)的区 ...
- MySQL索引 索引分类 最左前缀原则 覆盖索引 索引下推 联合索引顺序
MySQL索引 索引分类 最左前缀原则 覆盖索引 索引下推 联合索引顺序 What's Index ? 索引就是帮助RDBMS高效获取数据的数据结构. 索引可以让我们避免一行一行进行全表扫描.它的 ...
随机推荐
- C语言哈希表uthash的使用方法详解(附下载链接)
uthash简介 由于C语言本身不存在哈希,但是当需要使用哈希表的时候自己构建哈希会异常复杂.因此,我们可以调用开源的第三方头文件,这只是一个头文件:uthash.h.我们需要做的就是将头文件复制 ...
- C# 排序算法5:归并排序
归并排序,是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个有序的子序列,再把有序的子序列合并为整体有序序列.该算法是采用分治法. 原理: 1.申请空间,使其大小为两个已经排序 ...
- 理解 docker volume
1. docker volume 简介 文章 介绍了 docker image,它由一系列只读层构成,通过 docker image 可以提高镜像构建,存储和分发的效率,节省时间和存储空间.然而 do ...
- NLP复习之神经网络
NLP复习之神经网络 前言 tips: 设计神经网络时,输入层与输出层节点数往往固定,中间层可以自由指定: 神经网络中的拓扑与箭头代表预测过程数据流向,与训练的数据流有一定区别: 我们不妨重点关注连接 ...
- 如何取消VSCODE文件夹折叠
1.问题 如图所示,文件夹折叠在一起,导致我无法在父文件夹中新建一个文件夹,而是只能在子文件夹中新建文件夹 2.解决 原因:文件夹以紧凑方式呈现,取消即可 1. 打开设置,在里面搜索Explorer: ...
- Linux-文件用户及组管理-chown-chgrp
- [转帖]linux shell 中数组的定义和for循环遍历的方法
https://www.cnblogs.com/ysk123/p/11510718.html linux 中定义一个数据的语法为: variable=(arg1 arg2 arg3 ....) 中间用 ...
- [转帖]Kafka关键参数设置
https://www.cnblogs.com/wwcom123/p/11181680.html 生产环境中使用Kafka,参数调优非常重要,而Kafka参数众多,我们的java的Configurat ...
- [转帖]军备芯片14nm对比5nm,在战场上差距在哪里?
https://www.eet-china.com/mp/a207185.html 现在全球已经打响科技之战,每个国家都在力求让自己做到足够拔尖.美国商务部长就曾自曝家底说,美国制定两套战略应对在芯片 ...
- [转帖]iptables的四表五链与NAT工作原理
本文主要介绍了iptables的基本工作原理和四表五链等基本概念以及NAT的工作原理. 1.iptables简介 我们先来看一下netfilter官网对iptables的描述: iptables is ...