Hive执行计划之一文读懂Hive执行计划
概述
Hive的执行计划描述了一个hiveSQL语句的具体执行步骤,通过执行计划解读可以了解hiveSQL语句被解析器转换为相应程序语言的执行逻辑。通过执行逻辑可以知晓HiveSQL运行流程,进而对流程进行优化,实现更优的数据查询处理。
同样,通过执行计划,还可以了解到哪些不一样的SQL逻辑其实是等价的,哪些看似一样的逻辑其实是执行代价完全不一样。
如果说Hive优化是一堵技术路上的高墙,那么关于Hive执行计划,就是爬上这堵高墙的一架梯子。
不同版本的Hive会采用不同的方式生成的执行计划。主要区别就是基于规则生成hive执行计划,和基于成本代价来生成执行计划。而hive早期版本是基于规则生成执行计划,在Hive0.14及之后的版本都是基于成本代价来生成执行计划,这主要是集成了Apache Calcite。Apache Calcite具体可以查看官网介绍。
两种方式的优劣显而易见,基于规则生成执行计划,作为使用方来说,集群的环境,数据量的大小完全不一样,同样的规则逻辑,执行起来差异巨大,因此会对开发者有更高的优化要求。Hive基于成本代价来生成执行计划,这种方式能够结合Hive元数据信息和Hive运行过程收集到的各类存储统计信息推测出一个更合理的执行计划。也就是说Hive本身已经为我们的SQL语句做了一轮优化了,可以预见的将来,Hive还会具备更多的优化能力。
Hive执行计划是一个预估的执行计划,只有在SQL实际执行后才会获取到真正的执行计划,而一些关系型数据库中,会提供真实的SQL执行计划。如SQLserver和Oracle等。
1.hive执行计划的查看
Hive提供的执行计划使用语法如下:
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
- EXPLAIN:查看执行计划的基本信息;
- EXTENDED:加上 extended 可以输出有关计划的额外扩展信息。这些通常是物理信息,例如文件名等;
- CBO:可以选择使用Calcite优化器不同成本模型生成计划。CBO 从 hive 4.0.0 版本开始支持;
- AST:输出查询的抽象语法树。AST 在hive 2.1.0 版本删除了,存在bug,转储AST可能会导致OOM错误,将在4.0.0版本修复;
- DEPENDENCY:dependency在EXPLAIN语句中使用会产生有关计划中输入的依赖信息。包含表和分区信息等;
- AUTHORIZATION:显示SQL操作相关权限的信息;
- LOCKS:这对于了解系统将获得哪些锁以运行指定的查询很有用。LOCKS 从 hive 3.2.0 开始支持;
- VECTORIZATION:查看SQL的矢量化描述信息;
- ANALYZE:用实际的行数注释计划。从 Hive 2.2.0 开始支持;
以上内容重点关注explain,explain extend,explain dependency,explain authorization,explain vectorization。
2.学会查看Hive执行计划的基本信息
一个HIVE查询被转换为一个由一个或多个stage组成的序列(有向无环图DAG)。这些stage可以是MapReduce stage,也可以是负责元数据存储的stage,也可以是负责文件系统的操作(比如移动和重命名)的stage。
在查询SQL语句前加上关键字explain用来查看执行计划的基本信息。
可以看如下实例的执行计划结果解析:
实例SQL
-- 本文默认使用mr计算引擎
explain
-- 统计年龄小于30岁各个年龄里,昵称里带“小”的人数
select age,count(0) as num from temp.user_info_all where ymd = '20230505'
and age < 30 and nick like '%小%'
group by age;
执行计划:
# 描述任务之间stage的依赖关系
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
# 每个stage详细信息
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: user_info_all
Statistics: Num rows: 32634295 Data size: 783223080 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((age < 30) and (nick like '%小%')) (type: boolean)
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: age (type: bigint)
outputColumnNames: age
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: count(0)
keys: age (type: bigint)
mode: hash
outputColumnNames: _col0, _col1
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: bigint)
sort order: +
Map-reduce partition columns: _col0 (type: bigint)
Statistics: Num rows: 5439049 Data size: 130537176 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: bigint)
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0)
keys: KEY._col0 (type: bigint)
mode: mergepartial
outputColumnNames: _col0, _col1
Statistics: Num rows: 2719524 Data size: 65268576 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: true
Statistics: Num rows: 2719524 Data size: 65268576 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
我们将上述结果拆分看,先从最外层开始,包含两个大的部分:
stage dependencies: 各个stage之间的依赖性
stage plan: 各个stage的执行计划
先看第一部分 stage dependencies ,包含两个 stage,Stage-1 是根stage,说明这是开始的stage,Stage-0 依赖 Stage-1,Stage-1执行完成后执行Stage-0。
一些Hive执行逻辑的可视化工具页面就是利用该语句信息绘画出Hive执行流程图以及相关进度信息。
再看第二部分 stage plan,里面有一个 Map Reduce,一个MR的执行计划分为两个部分:
- Map Operator Tree: MAP端的执行计划树
- Reduce Operator Tree: Reduce端的执行计划树
这两个执行计划树里面包含这条sql语句的 operator:
map端Map Operator Tree信息解读:
TableScan 对关键字alias声明的结果集进行表扫描操作。
alias: 表名称
Statistics: 表统计信息,包含表中数据条数,数据大小等
Filter Operator:过滤操作,表示在之前的表扫描结果集上进行数据过滤。
predicate:过滤数据时使用的谓词(过滤条件),如sql语句中的and age < 30,则此处显示(age < 30),什么是谓词,以及优化点,可以详细看之前一篇文章谓词下推。
Statistics:过滤后数据条数和大小。
Select Operator: 对列进行投影,即筛选列,选取操作。
expressions:筛选的列名称及列类型
outputColumnNames:输出的列名称
Statistics:筛选列后表统计信息,包含表中数据条数,数据大小等。
Group By Operator:分组聚合操作。
aggregations:显示聚合函数信息,这里使用
count(0)。keys:表示分组的列,如果没有分组,则没有此字段。
mode:聚合模式,值有 hash:随机聚合;mergepartial:合并部分聚合结果;final:最终聚合
outputColumnNames:聚合之后输出列名,_col0对应的是age列, _col1对应的是count(0)列。
Statistics: 表统计信息,包含分组聚合之后的数据条数,数据大小。
Reduce Output Operator:输出到reduce操作结果集信息。
key expressions:MR计算引擎,在map和reduce阶段的输出都是key-value形式,这里描述的是map端输出的键使用的是哪个数据列。_col0对应的是age列。
sort order:值为空不排序;值为 + 正序排序,值为 - 倒序排序;值为 +- 排序的列为两列,第一列为正序,第二列为倒序,以此类推多值排序。
Map-reduce partition columns:表示Map阶段输出到Reduce阶段的分区列,在HiveSQL中,可以用distribute by指定分区的列。这里默认为_col0对应的是age列。
Statistics:输出结果集的统计信息。
value expressions:对应key expressions,这里是value值字段。_col1对应的是count(0)列。
接下来是reduce阶段Reduce Operator Tree,出现和map阶段关键词一样的,其含义是一致的,罗列一下map阶段未出现的关键词。
File Output Operator:文件输出操作。
compressed:表示输出结果是否进行压缩,true压缩,false不压缩。
table:表示当前操作表的信息。
input format:输入文件类型。
output format:输出文件类型。
serde:读取表数据的序列化和反序列化方式。
Stage-0的操作信息。
Fetch Operator:客户端获取数据操作。
limit:值为-1标识不限制条数,其他值为限制的条数。
Processor Tree:处理器树
ListSink:数据展示。
3.执行计划步骤操作过程
可以根据上述执行计划通过流程图来描述一下hiveSQL的执行逻辑过程。
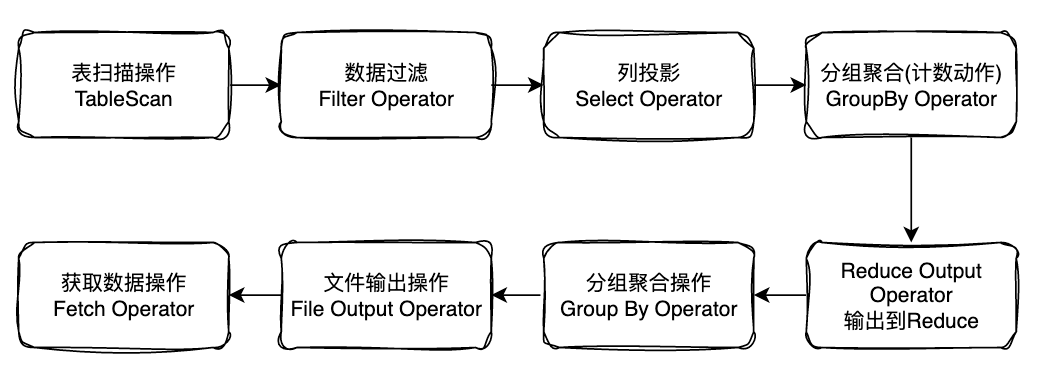
通过上图可以很清晰的了解一个hiveSQL的执行逻辑过程,便于理解hive数据流转过程。
4.explain extended
explain extended可以查看explain的扩展信息,主要包含三个部分内容:
- 抽象语法树(Abstract Syntax Tree,AST):是SQL转换成MR或其他计算引擎的任务中的一个重要过程。AST 在HIVE-13533中从 explain extended 中删除 ,并在HIVE-15932 中恢复为单独的命令 。
- 作业的依赖关系图,同explain展现内容。
- 每个作业的详细信息,即Stage Plans,相比explain多了表配置信息,表文件存储路径等。具体可以通过以下命令进行查看比对。不作列举了。
explain extended
-- 统计年龄小于30岁各个年龄里,昵称里带“小”的人数
select age,count(0) as num from temp.user_info_all where ymd = '20230505'
and age < 30 and nick like '%小%'
group by age;
下一期:Hive执行计划之hive依赖及权限查询和常见使用场景
按例,欢迎点击此处关注我的个人公众号,交流更多知识。
后台回复关键字 hive,随机赠送一本鲁边备注版珍藏大数据书籍。
Hive执行计划之一文读懂Hive执行计划的更多相关文章
- 大数据篇:一文读懂@数据仓库(PPT文字版)
大数据篇:一文读懂@数据仓库 1 网络词汇总结 1.1 数据中台 数据中台是聚合和治理跨域数据,将数据抽象封装成服务,提供给前台以业务价值的逻辑概念. 数据中台是一套可持续"让企业的数据用起 ...
- 一文读懂AI简史:当年各国烧钱许下的愿,有些至今仍未实现
一文读懂AI简史:当年各国烧钱许下的愿,有些至今仍未实现 导读:近日,马云.马化腾.李彦宏等互联网大佬纷纷亮相2018世界人工智能大会,并登台演讲.关于人工智能的现状与未来,他们提出了各自的观点,也引 ...
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 即时通讯新手入门:一文读懂什么是Nginx?它能否实现IM的负载均衡?
本文引用了“蔷薇Nina”的“Nginx 相关介绍(Nginx是什么?能干嘛?)”一文部分内容,感谢作者的无私分享. 1.引言 Nginx(及其衍生产品)是目前被大量使用的服务端反向代理和负载均衡 ...
- kubernetes基础——一文读懂k8s
容器 容器与虚拟机对比图(左边为容器.右边为虚拟机) 容器技术是虚拟化技术的一种,以Docker为例,Docker利用Linux的LXC(LinuX Containers)技术.CGroup(Co ...
- 一文读懂MySQL的事务隔离级别及MVCC机制
回顾前文: 一文学会MySQL的explain工具 一文读懂MySQL的索引结构及查询优化 (同时再次强调,这几篇关于MySQL的探究都是基于5.7版本,相关总结与结论不一定适用于其他版本) 就软件开 ...
- 一文读懂clickhouse集群监控
更多精彩内容,请关注微信公众号:后端技术小屋 一文读懂clickhouse集群监控 常言道,兵马未至,粮草先行,在clickhouse上生产环境之前,我们就得制定好相关的监控方案,包括metric采集 ...
- 一文读懂Java动态代理
作者 :潘潘 日期 :2020-11-22 事实上,对于很多Java编程人员来说,可能只需要达到从入门到上手的编程水准,就能很好的完成大部分研发工作.除非自己强主动获取,或者工作倒逼你学习,否则我们好 ...
- 一文读懂数仓中的pg_stat
摘要:GaussDB(DWS)在SQL执行过程中,会记录表增删改查相关的运行时统计信息,并在事务提交或回滚后记录到共享的内存中.这些信息可以通过 "pg_stat_all_tables视图& ...
- Java8 函数式【1】:一文读懂逆变
Java8 函数式[1]:一文读懂逆变 禁止转载 pure function 协变 逆变 Java8 引入了函数式接口,从此方法传参可以传递函数了,有人说: 不就是传一个方法吗,语法糖! lambda ...
随机推荐
- vue之写发表评论思路
后端接口 var express = require('express'); const sql = require('../sql') const Comment = require('../sql ...
- Java中的命名规范
Java中的命名规范 一. 常规约定 类一般采用大驼峰命名,方法和局部变量使用小驼峰命名,而大写下划线命名通常是常量和枚举中使用. 类型 约束 例 项目名 全部小写,多个单词用中划线分隔'-' spr ...
- 细节拉满,80 张图带你一步一步推演 slab 内存池的设计与实现
1. 前文回顾 在之前的几篇内存管理系列文章中,笔者带大家从宏观角度完整地梳理了一遍 Linux 内存分配的整个链路,本文的主题依然是内存分配,这一次我们会从微观的角度来探秘一下 Linux 内核中用 ...
- [GIT]辨析/区别: git add -u | git add -A | git add . [转载]
参考文献 git add -u与-A .三者的区别 - CSDN
- [Linux]CPU架构/指令集:RISC / CISC | arm | amd | X86/i386 | aarch64
1 前言 本文是解决在软件开发.软件交付过程中,常常需要找寻与服务器硬件的CPU架构适配的软件包时,开发者和交付者又时常摸不着头脑.[迷迷糊糊]地就下载了某个所谓"适配".&quo ...
- Go语言入门实战: 猜谜游戏+在线词典
包含基础语法和入门Go语言的3个案例 速览基础语法 对于耳熟能详的顺序结构.分支结构(if else-if else.switch).循环结构(for)不作赘述. 数组: 长度固定的元素序列 pack ...
- Docker 配置阿里云或腾讯云镜像加速
1.新建 /etc/docker/daemon.json 文件,并写入以下内容: 阿里云按下面配置 sudo tee /etc/docker/daemon.json <<-'EOF' { ...
- 从热爱到深耕,全国Top10开源软件出品人手把手教你如何做开源
摘要:DTT直播邀请到管雷鸣与广大开发者分享"如何在开源领域找到适合自己的路". "想象一下,你写的代码被越来越多的人使用,并极大地帮助他们提高了开发效率和稳定性.&qu ...
- TENGSHE-OS-渗透测试系统-win11版
下载ISO文件 创建新的虚拟机 VM17 已支持直接创建 win11 x64 稍后安装系统 选中win11 修改路径 win11需要设置8位加密密码 勾选安全引导 根据自身情况选择 默认即可 150G ...
- react中子组件给父组件传值
组件间通信: React中,数据是从上向下流动的,也就是一个父组件可以把它的 state/props通过props传递给它的子组件,但是子组件,不能修改props,如果组件需要修改父组件中的数据,则 ...