youtobe深度学习推荐系统-学习笔记
简介
前言
本文是Deep Neural Networks for YouTube Recommendations 论文的学习笔记。淘宝的召回模型曾经使用过这篇论文里面的方案,后续淘宝召回模型升级到了MGDSPR:多粒度深度语义商品检索。
转向深度学习
和谷歌的其他产品一样,you2b也经历了向深度学习转变的过程。矩阵分解技术在推荐系统中使用广泛研究多,而深度学习当时在推荐系统中应用并不多。y2b有超过10亿用户,应用DL的挑战
由于用户规模、语料库规模的庞大,很多在小问题上应用效果不错的模型算法,在y2b上面效果却一般。
用户偏好新的内容,每秒钟有大量新的视频内容产生,这些新的数据如何于现有系统的数据协同好
用户的历史行为非常稀疏,视频元数据缺乏良好的结构定义
系统概览
1 系统架构图
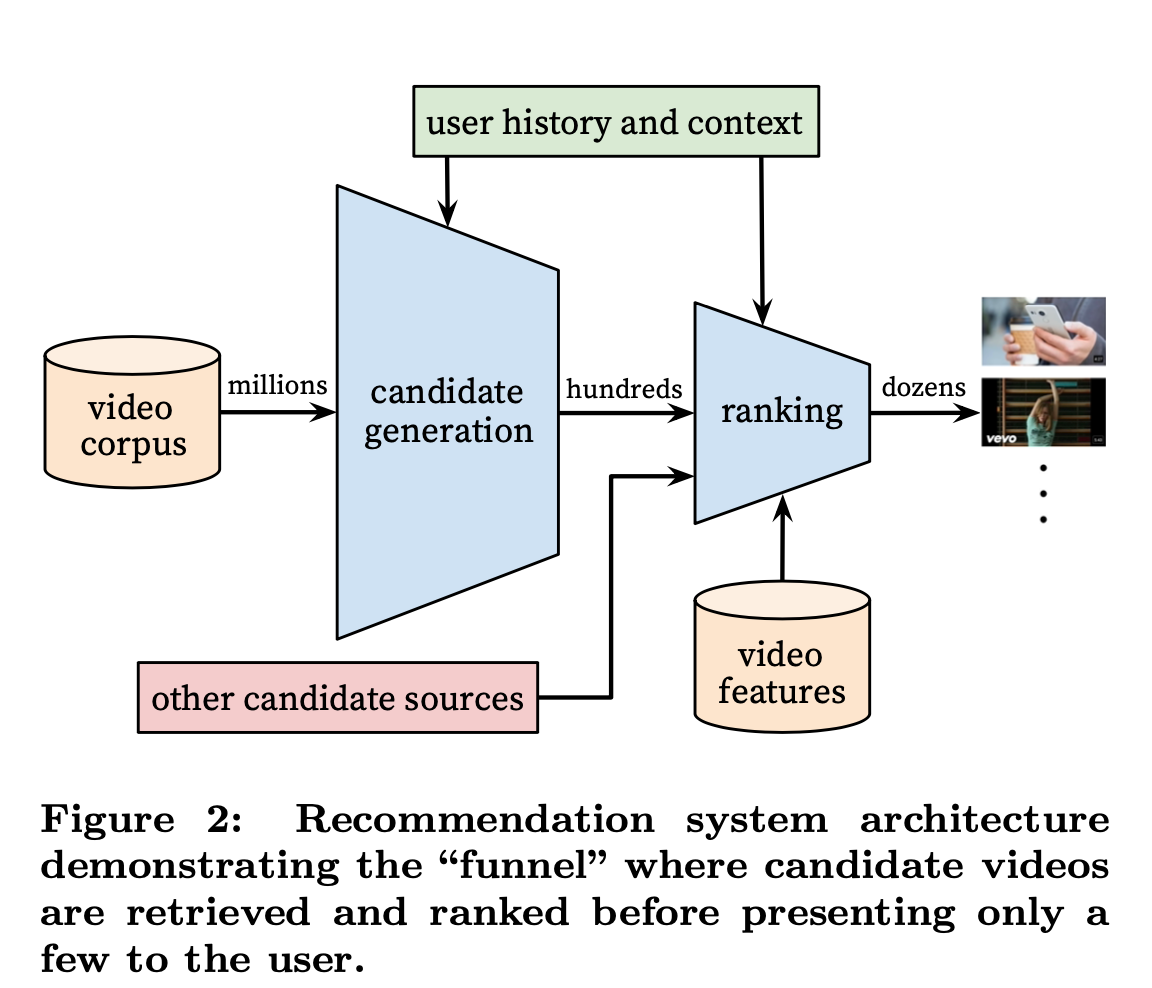
如图所示系统架构图非常简单,先试召回,然后排序。最经典、最古老的召回是倒排召回,近年来基于神经网络兴起的向量召回也逐渐流行并应用起来。比如facebook构建了基于倒排的ANN检索;淘宝构建了基于倒排、协同过滤、ANN检索的多路检索系统。召回阶段至关重要,召回的质量决定了下一个阶段排序能达到的上限,因为召回能看到语料库中的全部数据,而排序则基于召回的少量数据LIST.
2 召回
以用户的历史行为作为输入,产出小批量相关的视频给用户,并通过协同过滤提供宽泛的个性化。用观看过的视频ID、搜索的query以及统计出的特征来衡量用户之间的相似度
3 排序
在召回大相关视频之间,应该细粒度地区分它们之间的重要性,这个就是排序阶段要做的事情。排序阶段会给每一个召回的视频赋予一个打分,打分越高,就排到越前面。这个打分是基于我们期望的目标函数,以用户特征、视频特征为输入训练出来的
迭代评估
基于离线训练的评估指标迭代模型,但是在线的表现并不完全跟离线训练的行为一致,且在线可以通过多种无法在离线评估中使用的指标来评价模型效果,因此在线A/B测试
召回
问题定义
y2b推荐系统从大规模语料库里面检索出数百个相关的结果给用户。论文里把推荐系统看作一个极端多分类问题: 将预测问题转化为在用户U+上下文C的情况下,从大规模语料库准确地分类出用户在时间t观看的视频\(w_t\)
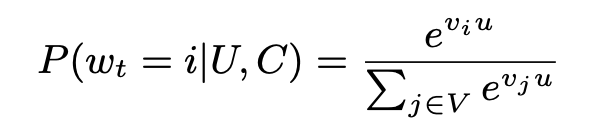
\(u\) 代表用户和上下文经过embedding后的低维稠密向量
\(v\) 代表视频item的向量表示
\(V\) 是语料库,或者索引库
为了叙述的方便,此处忽略指数,这个表达式的分母是语料库\(V\)中每一个视频和当前用户大向量乘积,分子是特定某个视频和用户之间的乘积。衡量的是某个视频应该被推荐给用户的概率,显然这些概率的和是1,这个其实就是softmax操作。
极端多分类
为了训练规模高达数百万类别的模型,从候选集中挑选抽样负样本,并通过加权修正的方式来进行调整。训练的过程最小化\(true\) 标签和抽样负样本之间的交叉熵的值。通过抽样的方式softmax训练效率相对于传统softmax提高了100倍。层次softmax也是一种高效的方案,然而经常在不相关的节点之间游走遍历,使得分类问题非常困难,性能也恶化。
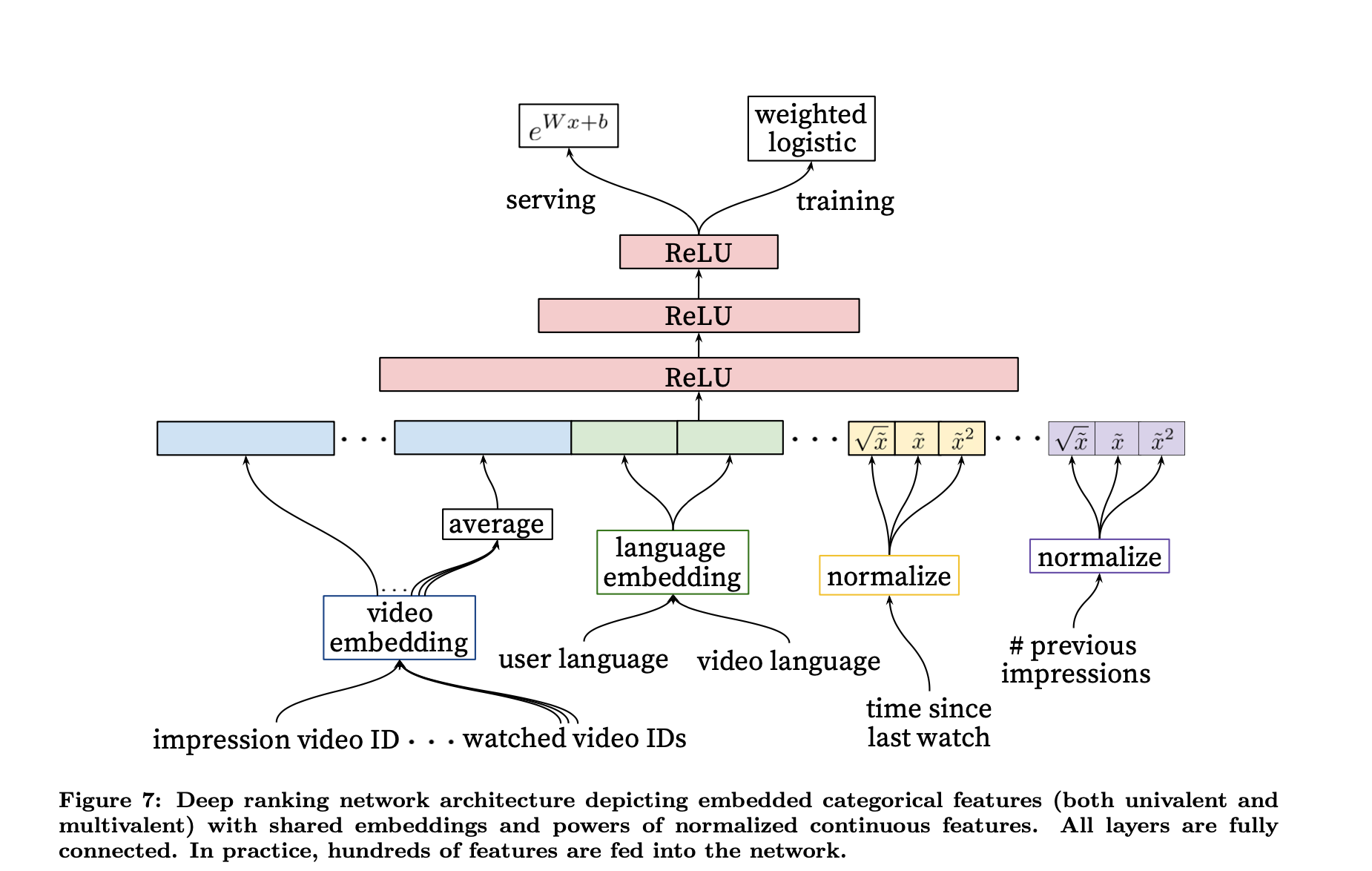
模型架构
用户的历史行为由一系列视频ID组成,这些视频ID已经编码为稠密向量,最后这些向量进行平均操作作为历史行为的表示。
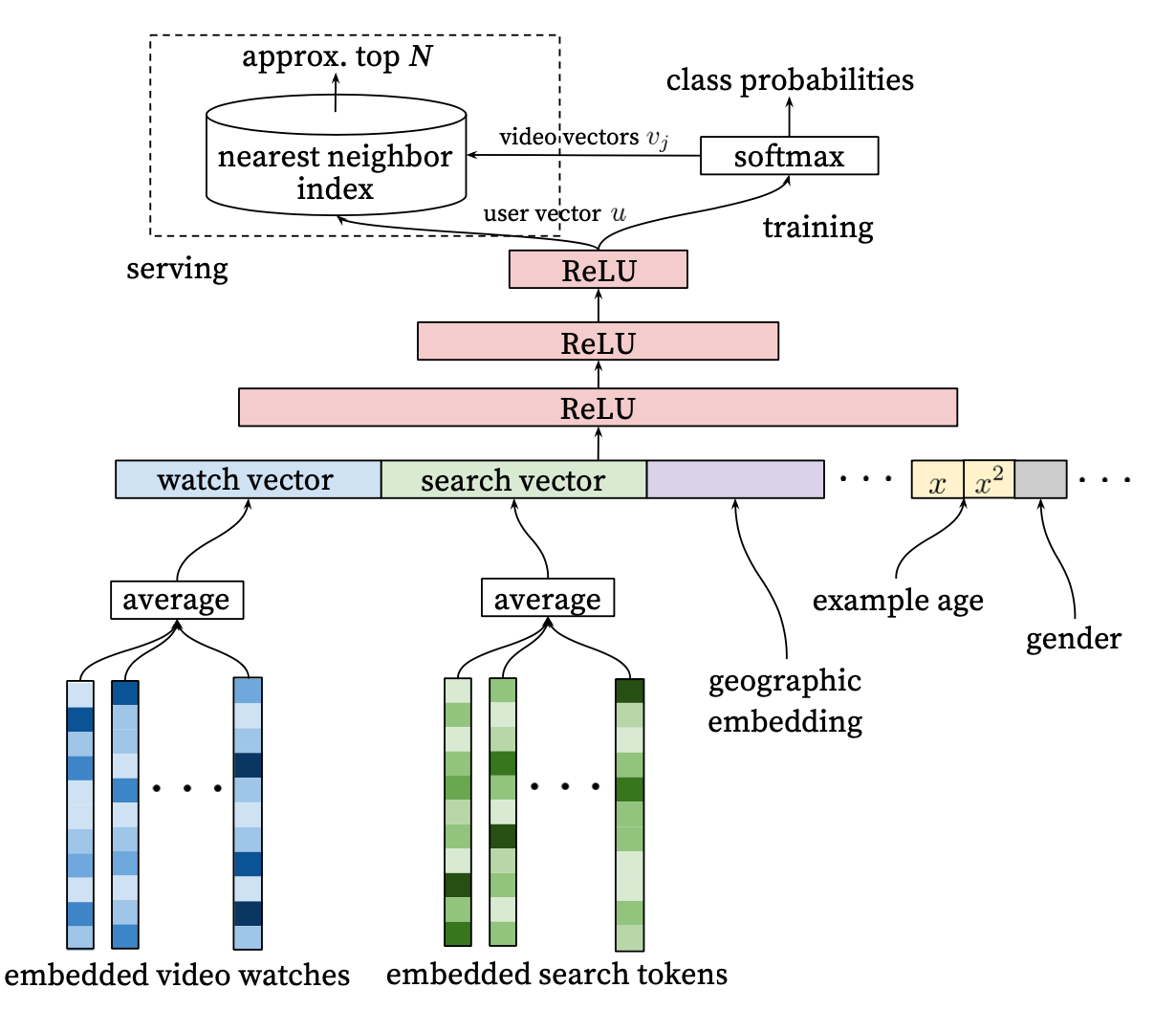
异构信号
深度学习的优点是可以很容易地将任意特征引入到模型中。论文中用户的搜索query、观看历史被同等对待,query基于1-gram、2-gram语言模型进行分词,分词后的token编码为向量,它们经过平均后代表用户的历史行为。另外地理位置、设备也会embedding为向量输入模型。一些简单的特征如性别、登陆状态等归一化到\([0,1]\) 直接输入到模型。
age特征
每秒钟都有很多小时的视频被上传到y2b,这些新的内容如何快速地推荐给用户是非常重要的,因为在不损失相关性的前提下,用户偏好新的内容。由于模型基于过去的老数据训练,容易偏向推荐老的内容给用户。
为了解决这个问题将age 作为样本的一个特征,参与模型训练。在线服务的时候将age设置为\(0\) 或者稍微负数一点,已表明模型预测最近的一个时间窗口。
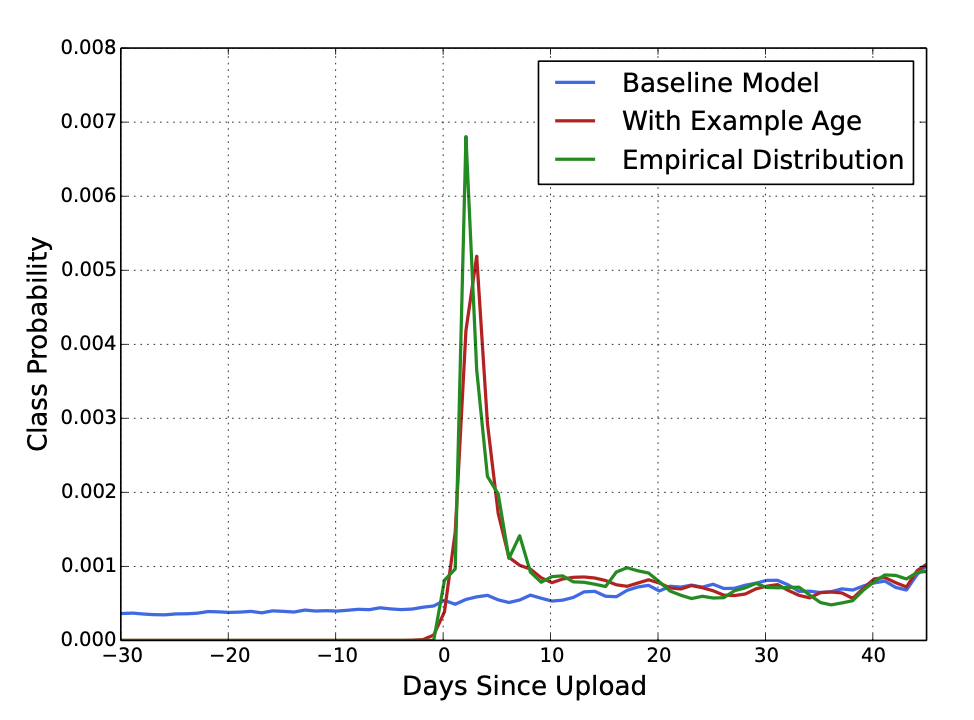
如图是随着时间的流逝,模型输出的视频分类概率,\(Empirical\) 这条线是根据经验判断一个内容流行度随着视频流逝而变化的曲线图:刚开始出现时有新鲜感比较受欢迎,越来越多的人看过后,新鲜感消失,流行度下降。可以看出\(baseline\) 接近一条直线,没有考虑实效性的影响。而带上\(Age\)特征后,曲线比较接近经验上的走势
标签和上下文的选择
样本来源
训练样本来自y2b全部的观看数据,而不仅仅是y2b的推荐系统,否则容易产生一个偏差:新的内容很难展现出来。因此如果用户通过推荐系统以外的方式进行探索,那么可以通过协同过滤传播给其他用户。
笔者注 在谷歌的一片关于冷启动的论文里,使用推荐系统的数据辅助搜索的模型训练,以解决那些新的没有点击过的但是实际上又是相关的用户感兴趣的文档不在训练数据中的冷启动问题。而本文用推荐系统以外的观看行为来\(enhance\) 推荐系统,正好形成一个回路。
活跃用户
一些极度活跃的用户会导致模型训练时,他们的数据会影响目标函数导致产生训练偏差。解决办法是对每个用户产生固定数目的训练样本。
反直觉
有一个反直觉的发现模型会利用网站的结构等信息导致过拟合问题,例如用户搜索了\(泰勒斯威夫特\),那么在这个背景下,推荐系统会将对应的搜索结果页作为内容推荐给用户,但是表现非常差。通过丢弃用户历史搜索行为的顺序、乱序词包,可以解决这个问题。
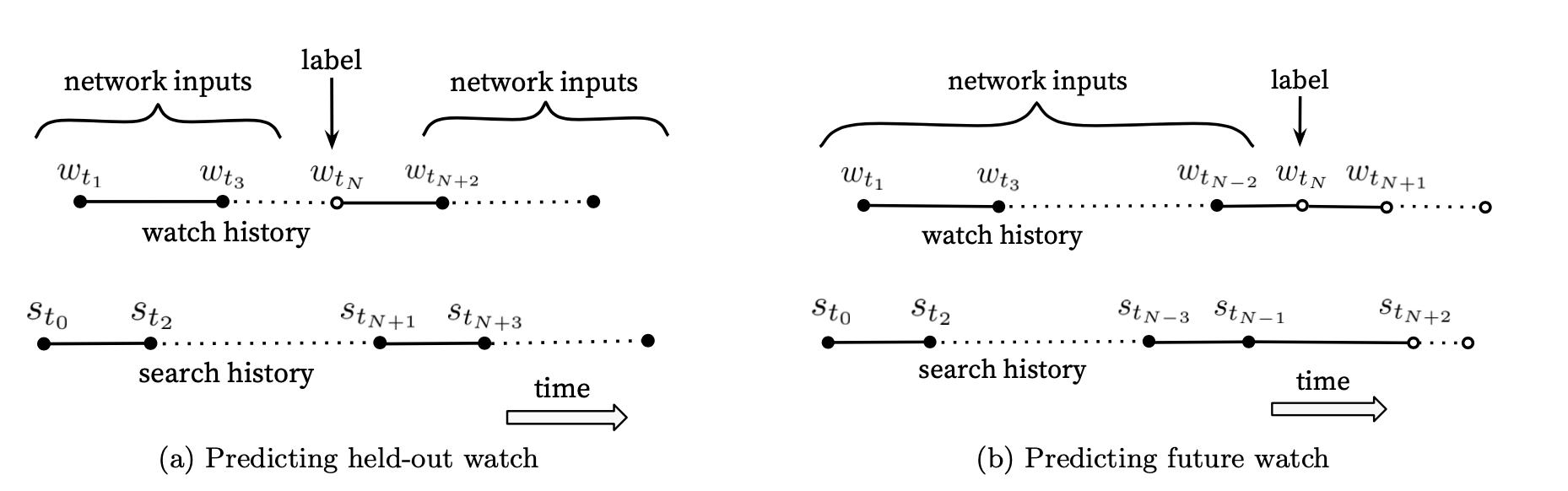
Future Leak
许多协同过滤系统从观看序列移除一个事件,用前后的上下文信息来预测被移除的事件。但是这样会泄漏future information,而y2b的做法是将被预测的那个事件及时间序列之后的都移除,如下图所示。验证来看用b 训练出的模型表现好于a。
排序
排序阶段使用类似召回阶段的模型结构,给每一个召回的候选数据赋予一个分数,然后按照这个分数对结果List进行排序。点击率具有欺骗性,用户可能点击了某个视频,但是并没有完成观看,因此观看时间更能代表用户对结果的认可度。
特征表达
1 特征工程
深度学习的兴起能够减轻特征工程的负担,然而y2b的原始数据不适合直接输入模型,因此仍然花费了大量的资源进行特征标注。难点在于如何表达用户活动的时序序列,以及和他们相关的视频item如何打分。
在特征工程中观察到2个重点:
用户之前和某个item(以及和这个item相似的其他item)的交互
将召回阶段的特征传递到排序阶段比较重要
2 Embeding类目特征
类似召回阶段稀疏多类目特征会转为稠密向量以适合神经网络模型的输入。每一个独立的ID空间独立学习embedding表示,空间会进行裁剪,此处的空间即词汇表,例如所有用户搜索过的所有query分词后产出一个词汇表,这个表会进行裁剪,只有出现次数达到一定阈值的TOP-N才会被选中。除了共享的特征(例如视频ID),其他的特征都会单独输入神经网络,以学习到这个特征特有的表示。
3 归一化连续特征
与决策树不同的是,神经网络对数据的规模后分布比较敏感。归一化特征数据有利于模型的快速收敛。对于一个符合\(f\) 分布的连续特征\(x\) ,通过按比例缩放归一化到区间\([0,1)\) 得到归一化后的特征值\(\hat{x}\) .经过指数操作后得到的形如 \(\hat{x}^2\) \(\sqrt{{\hat{x}}}\) 也作为模型的输入,可以提高模型的精度。
4 预期观看时间的建模
模型的目标是预测视频的观看时长,正样本根据标注的观看时长进行加权,负样本不加权,通过逻辑回归和交叉熵损失进行训练。学习到到概率是\(\frac{{\sum{T_i}}}{N - k}\) \(N\)是训练样本的数目,\(k\)是正样本的数目,\(T_i\)是第\(i\) 个样本的观看时长。假设正例的样本少到可以忽略, 点击的概率是P, 学习到的观看时长的可能性是\(E[T ](1 + P )\) ,由于\(P\)比较小,那么预测的结果接近\(E[T]\) .
在线推理阶段,最后一层使用指数函数,来预测几率。
youtobe深度学习推荐系统-学习笔记的更多相关文章
- Deep Learning(深度学习)学习笔记整理系列之(五)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(八)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(七)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(六)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(四)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(三)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(二)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- Deep Learning(深度学习)学习笔记整理系列之(一)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-0 ...
- Deep Learning(深度学习)学习笔记整理系列之(一)(转)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-0 ...
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
随机推荐
- git的Rebase和Merge之间的区别
有人会说Merge更好,因为它保留了最完整的工作历史.其他人则认为,Rebase变得更整洁,这使审阅者的生活更轻松,更高效.本文将解释合并和重新设置之间的区别是什么,使用它们之一有什么好处. 从根本上 ...
- 逍遥自在学C语言 | 算数运算符
前言 一.人物简介 第一位闪亮登场,有请今后会一直教我们C语言的老师 -- 自在. 第二位上场的是和我们一起学习的小白程序猿 -- 逍遥. 二.算数运算符简介 C语言的算数运算符,是用来完成基本的算术 ...
- blender资源库 【自用】
1 https://www.threedscans.com A Website with a lot of photo-scanned sculptures which are free to use ...
- 图与网络分析—R实现(一)
图与网络 一个网络G,也可以称为图(graph)或网络图,是一种包含了节点V(即网络参与者,也称顶点)与边E(即节点之间的连接关系)的数学结构,记作G={V,E}.可以使用一个矩阵来存放节点之间的连接 ...
- w11默认调用ie浏览器方法
作为公司的一个it人员,最近发现w11不能不能调用ie,导致公司的系统不能正常使用,因为后台插件室默认调用ie,如果重新写插件太麻烦,所以百度了下,亲测可用,目前,公司电脑已经可以正常使用,具体方法如 ...
- [Linux]Linux发展历程
古人云,知其然知其所以然.马哲思想指导着我们,任何事物.问题,离不开:为什么(Why,事物从哪里来?).是什么(What,事物的定位?).怎么做(How,到哪里去?)的哲学3问. 继上个月算是相对彻底 ...
- Redis读书笔记(二)
Redis对象系统 Redis对象 字符串(String)的底层实现方式 直接保存整数值:字符串对象保存的是整数值,且可以用long类型来表示. embstr编码的SDS:字符串对象保存的是一个长度小 ...
- 深入理解 python 虚拟机:字节码教程(3)——深入剖析循环实现原理
深入理解 python 虚拟机:字节码教程(3)--深入剖析循环实现原理 在本篇文章当中主要给大家介绍 cpython 当中跟循环相关的字节码,这部分字节码相比起其他字节码来说相对复杂一点,通过分析这 ...
- 微信小程序隐藏页面滚动条
开发小程序时,经常会碰到页面长度超过屏幕高度,然后下拉时会出现滚动条,对于一些有强迫症的人来说是不可忍受的. 网上看了好多,写的.都评论有起作用或者不起作用的. 我在这分享一个全局隐藏滚动条的方式. ...
- 图文介绍 Windows 系统下打包上传 IOS APP 流程
现在很多伙伴跨平台开发应用,有些童鞋没有苹果机,本文将介绍,如何在 Windows 系统环境下直接上架 APP ,不用去搞虚拟机之类的了, Windows 下照样轻松打包上架 iOS APP . 下面 ...