Mind2Web: Towards a Generalist Agent for the Web 论文解读
概要
本文介绍了一个名为MIND2WEB的数据集,用于开发和评估Web通用代理,可以使用自然语言输入指令,使之可以在任何复杂的网站上执行操作。
对比
前人缺陷:
现有的用于Web代理的数据集要么使用模拟网站,要么仅涵盖有限的网站和任务集,因此不适用于通用的Web代理。
本文优势:
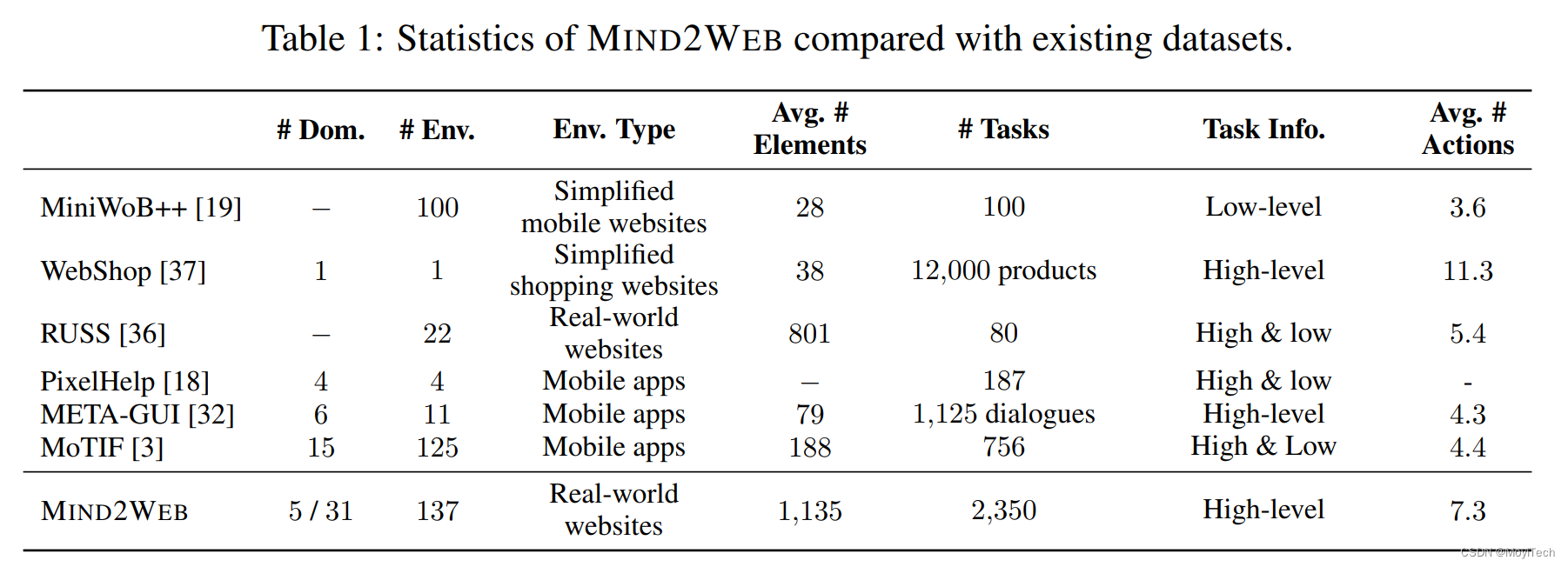
MIND2WEB数据集包含来自137个网站、跨足31个领域的超过2,000个开放式任务,以及为这些任务收集的众包行动序列。MIND2WEB为构建通用Web代理提供了三个必要的要素:
- 多样化的领域、网站和任务
- 使用真实世界的网站而不是模拟和简化的网站
- 广泛的用户交互模式。
基于MIND2WEB,作者进行了首次尝试使用大型语言模型(LLMs)构建通用Web代理。
由于真实世界网站的原始HTML通常元素过多无法直接输入LLM,本文的方案为:先通过小型LM进行筛选,再输入到LLM中,可以显著提升模型的效果和效率。
MIND2WEB 数据集介绍
- 来自于真实网站的捕捉
- 涵盖领域广
- 网站的快照和交互捕获完全
任务定义
该数据集旨在使代理通过一系列操作完成特定任务
- 任务描述:是高级的,而不是避免了低级的、一步一步的指令。
- 操作序列:(目标元素,操作)->(目标元素,操作)-> ... ->(目标元素,操作)
- 三种常见操作:点击(包括悬停和按回车)、输入、选择
- 操作序列通常跨越一个站点的多个网页。
- 网页快照:HTML、DOM、HAR等过程信息
执行方式:逐步预测、执行,
input:当前网页、历史操作,output:接下来的操作 (有RNN的意思)
数据收集
数据通过亚马逊众包平台(Amazon Mechanical Turk)收集,主要分为三个阶段:
- 第一阶段-任务提出:首先要求工作者提出可以在给定网站上执行的任务。作者会仔细审核提出的任务,并选择在第二阶段进行注释的可行且有趣的任务。
- 第二阶段-任务演示:要求工作者演示如何在网站上执行任务。使用 Playwright 开发了一个注释工具,记录交互跟踪并在每个步骤中对网页进行快照。如图 2 所示,用红色标记的操作将导致转换到新网页。
- 第三阶段-任务验证:作者验证所有任务,以确保所有操作都是正确的,任务描述正确地反映了注释的操作。
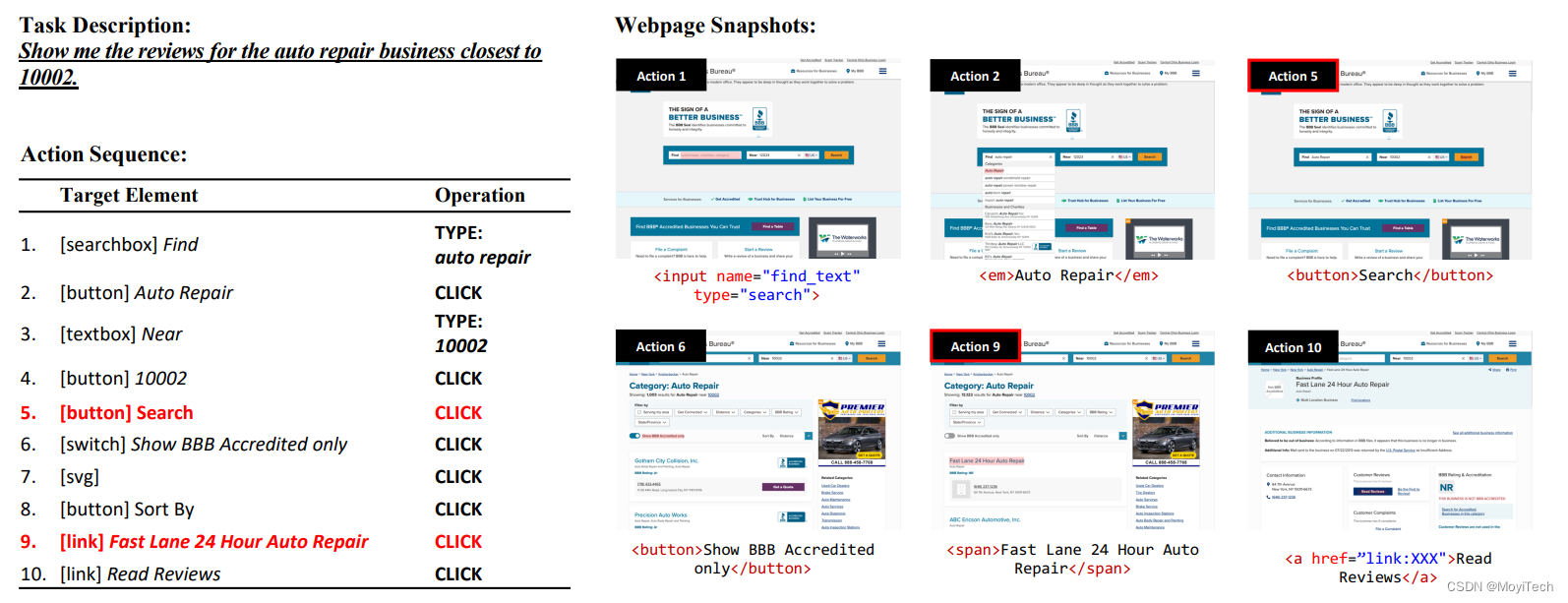
与前人的比较 及 研究挑战
- 采用真实的网页,更符合实际
- 网页元素多、复杂度高,未进行人工简化
- 任务等级高,更接近日常使用
- 先前的研究通常提供逐步的指令,并主要关注测试代理将低级指令转化为操作的能力,例如,“在位置字段中输入纽约,单击搜索按钮并选择明天标签”
- 本文数据集只提供高级目标,例如,“纽约明天的天气如何?”
故这种数据集(Mind2Web)对于代理模型的训练及应用来说提出了很大的挑战。
MindAct 框架
为了使用Mind2Web数据集,引入了MindAct框架
由于原始HTML过大,直接输入到LLM中消耗资源过大,MindAct将此分为二阶段过程(如图三)
- 第一阶段:如图四,使用一个Small LM,从HTML中元素中筛选出几个候选元素
- 第二阶段:将候选元素合并成HTML片段传入到LLM进行最后预测(元素 + 操作)
Small LM 用于筛选;LLM用于预测

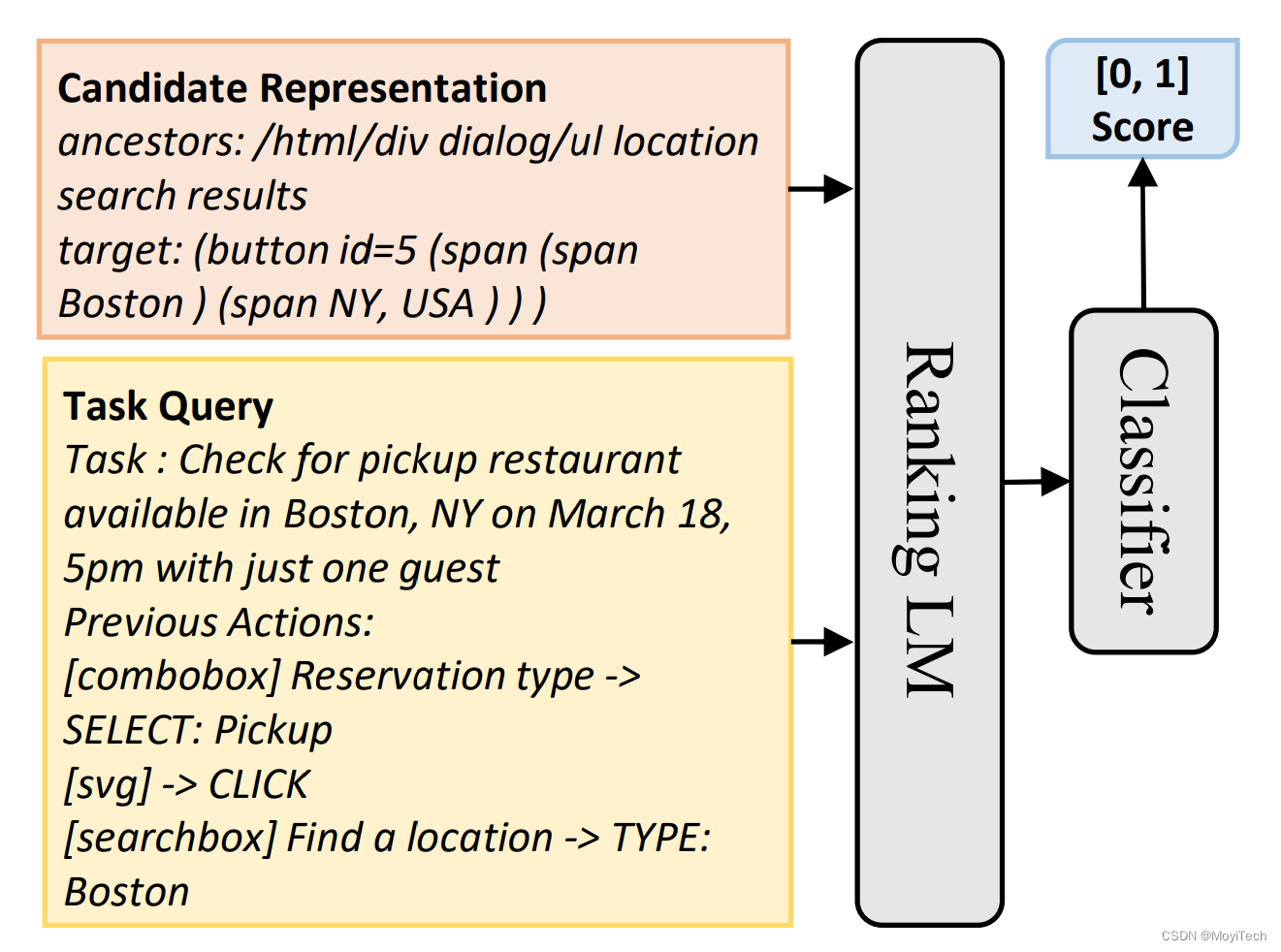
通过Small LM生成小模型
feature: Task Description + Previous Actions
target: Top-k Elements
通过LLM预测操作
LLM用于判别 比 生成更有效率
故LM被训练为从一系列选项中进行选择,而不是生成完整的目标元素
Divide the top-k candidates into multiple clusters of five options.
If more than one option is selected after a round,
Form new groups with the selected ones.
This process repeats until a single element is selected, or all
options are rejected by the model
test result:
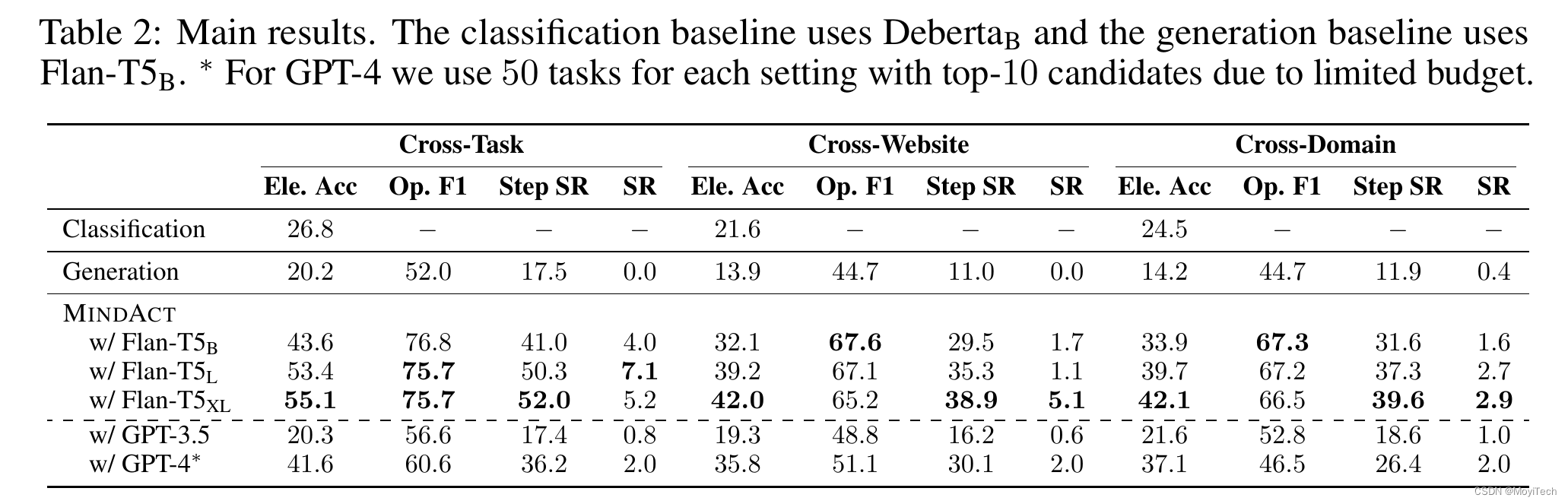
- 为什么MindAct和两个baseline不使用相同的LLM以控制变量?
baseline1: Classfication,仅使用Debertab进行 元素 预测
baseline2: Generation,使用Flan-T5直接进行 元素+操作 的预测
实验
实验步骤
Test-Cross-Domain:使用不同的域名进行预测
Test-Cross-Website:使用同域的网站预测
TestCross-Task:使用相同的网站预测
数据预处理和评估
分别使用Element Accuracy、Operation F1、Step Success Rate、Success Rate对数据进行评估
实验结果
第一步候选生成
使用了微调的DeBERTa 作为Small LM,用于第一步的候选生成(For efficiency, use the base version DeBERTaB with 86M parameters.)
分别获得了88.9% / 85.3% / 85.7% 的recall
取k=50,即top-50用于下一步预测。
第二步操作预测
使用Flan-T5作为生成模型
尽管是大模型(220M for Flan-T5),但在元素选择方面表现先不佳
使用上述MindAct中使用的multi-choice QA formulation方法很有效
The best model achieves 52.0% step success rate under Cross-Task setting, and 38.9% / 39.6% when generalizing to unseen websites(Cross-Website) and domains(Cross-Domain).
However, the overall task success rate remains low for all models, as the agent often commits at least one error step in most cases.
Three Levels of Generalization
- 模型均在Cross-Task表现最佳、但在Cross-Website、Cross-Domain中低于Cross-Task 10%以上。由此可见,对于未见过的环境进行预测是目前最大的问题。
- 在图6中可见,Cross-Website、Cross-Domain中的表现很相近。就此可推断,首要问题在于网站的设计和交互逻辑、而不是域名特性。
- 对于网站之间的一些共同的操作,预训练语言模型已经有了可以解析复杂任务的能力。在具体环境中,将这些知识转化为可操作的步骤仍然是一个相当大的挑战。
In-context Learning with LLM
分别使用MINDACT的方法在GPT-3.5和GPT-4进行了测试,结果如下:
GPT-3.5表现不好,在元素选择正确率上仅有20%
GPT-4要稍好一些,与微调过的Flan-T5不相上下,表明用大语言模型在此有很大的潜力
但GPT-4运行成本很高,使用较小规模的模型是一个很好的发展方向
Mind2Web: Towards a Generalist Agent for the Web 论文解读的更多相关文章
- Jenkins 2.16.3默认没有Launch agent via Java Web Start,如何配置使用
问题:Jenkins 2.16.3默认没有Launch agent via Java Web Start,如下图所示,而这种启动方式在Windows上是最方便的. 如何设置才能让出来呢? 打开&quo ...
- Jenkins的配置从节点中默认没有Launch agent via Java Web Start选项问题
Jenkins的配置从节点中默认没有Launch agent via Java Web Start,如下图所示,而这种启动方式在Windows上是最方便的. 如何设置才能让出来呢? 1:打开" ...
- Jenkins的配置从节点中默认没有Launch agent via Java Web Start,该如何配置使用
Jenkins的配置从节点中默认没有Launch agent via Java Web Start,如下图所示,而这种启动方式在Windows上是最方便的. 如何设置才能让出来呢? 1:打开" ...
- 识别User Agent屏蔽一些Web爬虫防采集
识别User Agent屏蔽一些Web爬虫防采集 from:https://jamesqi.com/%E5%8D%9A%E5%AE%A2/%E8%AF%86%E5%88%ABUser_Agent%E5 ...
- Jenkins节点配置页面,启动方法没有"Launch agent via Java Web Start"解决方法?
Jenkins的配置从节点中默认没有Launch agent via JavaWeb Start,解决办法: 步骤: 1:打开"系统管理"——"Configure Glo ...
- Jenkins 节点配置中没有Launch agent via Java Web Start 选项
Jenkins节点配置的启动方式中没有Launch agent via Java Web Start,如下图 怎样能设置出来呢? 1:打开"系统管理"——"Configu ...
- Jenkins 默认没有Launch agent via Java Web Start,该如何配置
打开"系统管理"——"Configure Global Security" TCP port JNLP agents 配置成"随机",点击& ...
- Searching the Web论文阅读
Searching the Web (Arvind Arasu etc.) 1. 概述 2000年,23%网页每天更新,.com域内网页40%每天更新.网页生存半衰期是10天.描述方法可用Pois ...
- 论文学习——《Learning to Compose with Professional Photographs on the Web》 (ACM MM 2017)
总结 1.这篇论文的思路基于一个简单的假设:专业摄影师拍出来的图片一般具备比较好的构图,而如果从他们的图片中随机抠出一块,那抠出的图片大概率就毁了.也就是说,原图在构图方面的分数应该高于抠出来的图片. ...
- 部署WEB应用程序
部署WEB应用程序: 1.在模板机上新建IIS站点 2.安装WebDeploy后在IIS控制台中导出站点为应用程序包 其站点在新虚机上必须存在,否则会报错,如下: 应用程序(C:\ProgramDat ...
随机推荐
- 倒排Tree树
倒排Tree树 需求说明为: 树节点存在(标识)或者叶子节点存在标识 都需要展示出来 存在※的节点及其上级节点需要返回 其余节点需要剔除 A() ----------------------- ...
- java.lang.Error: Unresolved compilation problems
一般有两种常见的情况: 1.当一个 jar 文件的 MANIFEST.MF 中已经标记了 Sealed: true 时,这个 jar 内所有的 java package 中的类必须来自这个 jar 包 ...
- Google Colab:云端的Python编程神器
Google Colab,全名Google Colaboratory,是Google Research团队开发的一款云端编程工具,它允许任何人通过浏览器编写和执行Python代码.Colab尤其适合机 ...
- 【WALT】update_task_demand() 代码详解
目录 [WALT]update_task_demand() 代码详解 代码展示 代码逻辑 用于判断是否进入新窗口的标志位 ⑴ 不累加任务运行时间的条件判断 ⑵ 仍在旧窗口中 ⑶ 进入新窗口 ⑷ 返回值 ...
- 国标GB28181协议客户端开发(四)实时视频数据传输
国标GB28181协议客户端开发(四)实时视频数据传输 本文是<国标GB28181协议设备端开发>系列的第四篇,介绍了实时视频数据传输的过程.通过解读INVITE报文中的SDP信息,读取和 ...
- 手写call&apply&bind
在这里对call,apply,bind函数进行简单的封装 封装主要思想:给对象一个临时函数来调用,调用完毕后删除该临时函数对应的属性 call函数封装 function pliCall(fn, obj ...
- 普通用户启动 supervisor 报 HTTP 错误(strace)
公司的开发对生产环境都有普通用户 www 的权限,采用堡垒机登录到生产环境的机器. 默认 supervisor 使用 root 用户启动,开发没有权限直接修改配置和操作 supervisor 管理的进 ...
- Java 调用gdal API(二)——栅格裁剪
gdal可以说是GIS数据处理比较好的工具之一,虽然也提供了Java API,但是官方文档确实太过简单,用起来确实太难受,每次都需要去参考对应的C++api,然后在对应使用. 因此小编决定从这篇文章开 ...
- Kernel panic 堆栈信息怎么看
Kernel panic 是指 Linux 内核遇到了无法继续执行的致命错误,此时会在屏幕上输出一些错误信息,其中就包括堆栈信息.堆栈信息是指发生错误时 CPU 执行的代码路径,可以通过堆栈信息来定位 ...
- virt-install 使用 qcow2格式虚拟机镜 、macvtap网卡
安装虚拟机 这里使用 amazn2 虚拟机镜像安装,根据官网文档,需要预先配置一个 seed.iso 文件 参考文档:https://docs.aws.amazon.com/zh_cn/AWSEC2/ ...