drf(分页、IP限制用户频率、自动生成文档、RBAC、django缓存)
一 分页
settings.py
REST_FRAMEWORK = {'PAGE_SIZE': 2,
}
views.py
# 分页
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination # 第一种分页方式: 通过指定page获取页数, 通过size获取每页显示的条目
class CoustomPageNumberPagination(PageNumberPagination):
"""
url地址栏目支持的查询格式:
http://127.0.0.1:8000/api/books1/?page=2
http://127.0.0.1:8000/api/books1/?page=1&size=4
"""
page_size = 2 # 页面大小. 表示显示每页数据条数. 可配置全局('PAGE_SIZE': None)
page_query_param = 'page' # 页面查询参数. 表示查询第几页的key. (可自定义名称)
page_size_query_param = 'size' # 页面大小查询参数. 表示每一页显示的条数 (可自定义名称)
max_page_size = 5 # 最大页面大小. 表示每页最大显示条数 # 第二种分页方式: 通过指定offset找到指定位置, 通过limit往后获取条目数
class CustomLimitOffsetPagination(LimitOffsetPagination):
"""
url地址栏目支持的查询格式:
http://127.0.0.1:8000/api/books1/?limit=100
http://127.0.0.1:8000/api/books1/?offset=400&limit=100
"""
default_limit = 3 # 每页条数. 可配置全局('PAGE_SIZE': None,)
limit_query_param = 'limit' # 从offset标杆的位置, 往后获取的条目数 (可自定义名称)
offset_query_param = 'offset' # 标杆. 可以理解为旗帜, 插在这里, 后去旗帜后面的内容条目 (可自定义名称)
max_limit = 5 # 每页显示的最大条目数. 默认为None, 不做任何限制. # 第三种分页方式: 光标分页
class CustomCursorPagination(CursorPagination):
"""
提示: 这种方式实现的方式很复杂, 因此带来的好处就是查询效率极高, 不过也有它的缺陷, 就是通过这种方式制作的分页只有上一页下一页,
如果数据库数据非常大那么使用它将会是非常好的选择.
url地址栏目支持的查询格式:
直接浏览器输入访问即可, 因为不能指定位置.
"""
cursor_query_param = 'cursor' # 每一页查询的key (可自定义名称)
page_size = 3 # 每页显示的条数. 可配置全局('PAGE_SIZE': None,)
ordering = '-id' # 排序字段. 如果不指定默认使用'-created'进行分页, 如果你的数据库中没有这个字段, 那么就会抛出异常 from rest_framework.generics import ListAPIView class BookListAPIView(ListAPIView):
queryset = models.Book.objects.all()
serializer_class = ser.BookModelSerializer
# pagination_class = PageNumberPagination
# 第一种分页方式,继承PageNumberPagination自定义的分页
pagination_class = CoustomPageNumberPagination
# 第二种分页方式
# pagination_class = CustomLimitOffsetPagination
# 第三种分页方式
# pagination_class = CustomCursorPagination
总结
'''
from rest_framework.pagination import PageNumberPagination
通过page分页, 通过site获取分页条目数
from rest_framework.pagination import LimitOffsetPagination
通过offset找到分页位置, 通过limit获取当前数据之后的条目数
from rest_framework.pagination import CursorPagination
没有参数, 默认只有上一页, 下一页. 通过ordering排序进行分页
优点: 查询速度快. 缺点: 无法选择起始位置
提示: 以上都可以限制最大显示条目数 和 默认获取条目数. 以及筛选的key都可以重定义.
'''
继承APIView的分页
# 继承APIView的分页
class BookAPIView1(APIView):
def get(self, request, *args, **kwargs):
book_queryset = models.Book.objects.all()
# 调用分页器, 实例化出分页器对象
page_obj = CoustomPageNumberPagination()
instance = page_obj.paginate_queryset(book_queryset, request=request, view=self)
# 通过分页器对象. 获取下一条的url链接
next_url = page_obj.get_next_link()
# 通过分页器对象. 获取上一条的url链接
previous_url = page_obj.get_previous_link()
# print('next_url:', next_url)
# print('previous_url:', previous_url)
book_ser = ser.BookModelSerializer(instance, many=True)
return CommonResponse(results=book_ser.data, next=next_url, previous_url=previous_url)
二 根据IP限制用户频率
setting.py
REST_FRAMEWORK = {
'DEFAULT_THROTTLE_RATES': {
'custom': '3/m' # key要跟类中的scope对应
},
'PAGE_SIZE': 2,
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
}
throttle.py
from rest_framework.throttling import SimpleRateThrottle class CustomSimpleRateThrottle(SimpleRateThrottle):
scope = 'custom' def get_cache_key(self, request, view):
# 'REMOTE_ADDR': '127.0.0.1',
# print(request.META.get('REMOTE_ADDR'))
return request.META.get('REMOTE_ADDR')
view.py
# 频率限制
from utils.throttl import CustomSimpleRateThrottle class BookAPIView1(APIView):
throttle_classes = [CustomSimpleRateThrottle,] def get(self, request, *args, **kwargs):
book_queryset = models.Book.objects.all()
# 调用分页器, 实例化出分页器对象
page_obj = CoustomPageNumberPagination()
instance = page_obj.paginate_queryset(book_queryset, request=request, view=self)
# 通过分页器对象. 获取下一条的url链接
next_url = page_obj.get_next_link()
# 通过分页器对象. 获取上一条的url链接
previous_url = page_obj.get_previous_link()
# print('next_url:', next_url)
# print('previous_url:', previous_url)
book_ser = ser.BookModelSerializer(instance, many=True)
return CommonResponse(results=book_ser.data, next=next_url, previous_url=previous_url)
三 自动生成接口文档
1. 自动生成接口文档配置
1. 安装:pip3 install coreapi
2. 一般在总路由中配置
from rest_framework.documentation import include_docs_urls
urlpatterns = [
path('docs/', include_docs_urls(title='站点页面标题'))
]
3. settings.py中到 REST_FRAMEWORK 中声明
REST_FRAMEWORK = {
"DEFAULT_SCHEMA_CLASS": "rest_framework.schemas.AutoSchema",
# 下面的这个默认的配置不知道为什么不能使用????
# 'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.openapi.AutoSchema',
}
4. 浏览器url地址栏输入: http://127.0.0.1:8010/docs/
抛出异常: 则表示没有在settings.py中声明 DEFAULT_SCHEMA_CLASS
AttributeError at /docs/
'AutoSchema' object has no attribute 'get_link'
2. 文档描述说明的定义位置
1) 单一方法的视图,可直接使用类视图的文档字符串,如
class BookListView(generics.ListAPIView):
"""
返回所有图书信息.
""" 2)包含多个方法的视图,在类视图的文档字符串中,分开方法定义,如
class BookListCreateView(generics.ListCreateAPIView):
"""
get:
返回所有图书信息. post:
新建图书.
""" 3)对于视图集ViewSet,仍在类视图的文档字符串中封开定义,但是应使用action名称区分,如
class BookInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet):
"""
list:
返回图书列表数据 retrieve:
返回图书详情数据 latest:
返回最新的图书数据 read:
修改图书的阅读量
"""
3. 访问接口文档网页
浏览器访问 127.0.0.1:8000/docs/,即可看到自动生成的接口文档。
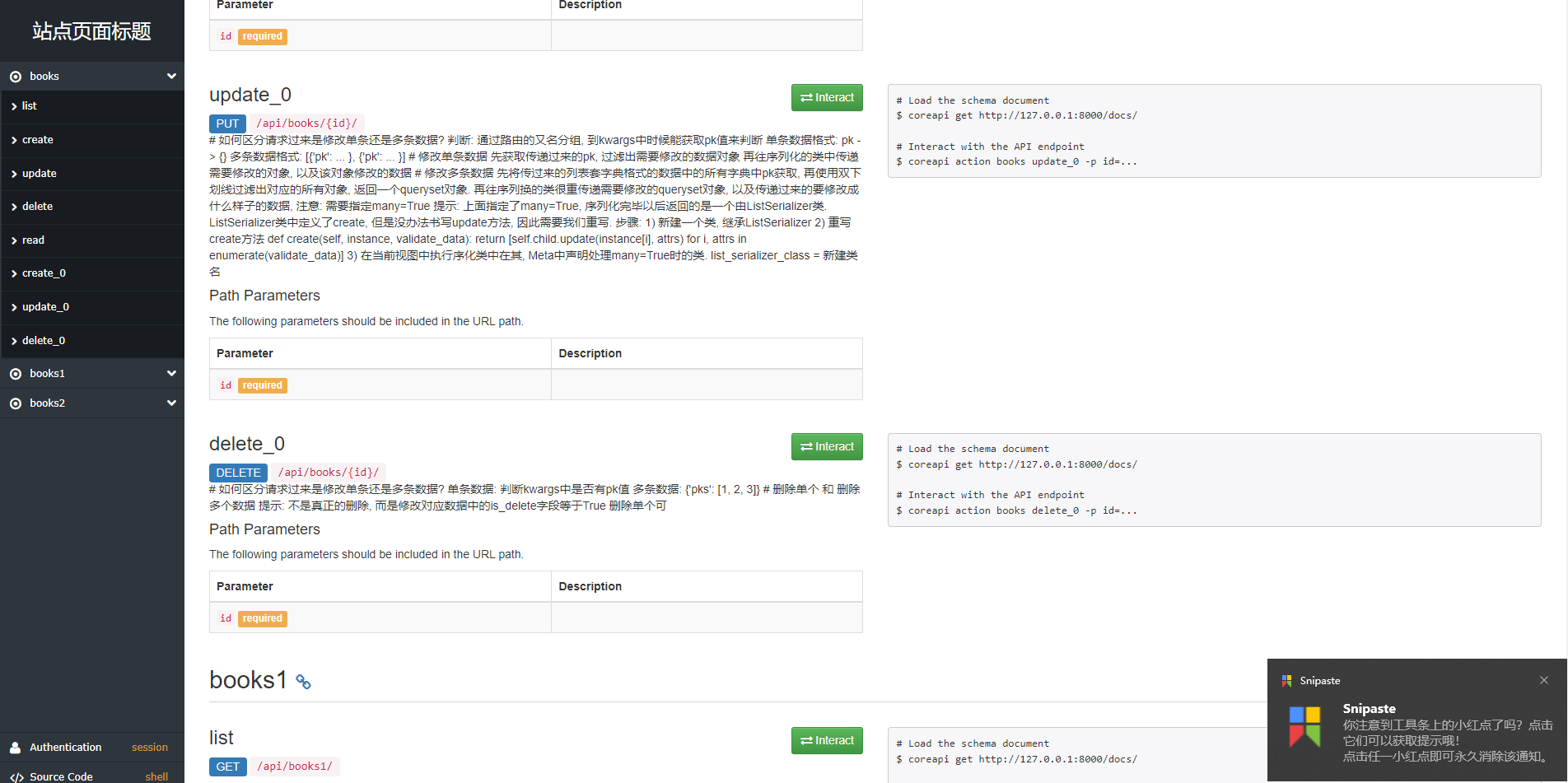
两点说明
1) 视图集ViewSet中的retrieve名称,在接口文档网站中叫做read
2)参数的Description需要在模型类或序列化器类的字段中以help_text选项定义,如:
class Student(models.Model):
...
age = models.IntegerField(default=0, verbose_name='年龄', help_text='年龄')
...
或
class StudentSerializer(serializers.ModelSerializer):
class Meta:
model = Student
fields = "__all__"
extra_kwargs = {
'age': {
'required': True,
'help_text': '年龄'
}
}
四 RBAC基于角色的访问控制
1. 什么是RBAC
1.1. 概念
RBAC(Role-Based Access Control)权限模型的概念,即:基于角色的权限控制。通过角色关联用户,角色关联权限的方式间接赋予用户权限。
1.2. 应用
RBAC - Role-Based Access Control
Django的 Auth组件 采用的认证规则就是RBAC 1)像专门做人员权限管理的系统(CRM系统)都是公司内部使用,所以数据量都在10w一下,一般效率要求也不是很高
2)用户量极大的常规项目,会分两种用户:前台用户(三大认证) 和 后台用户(BRAC来管理)
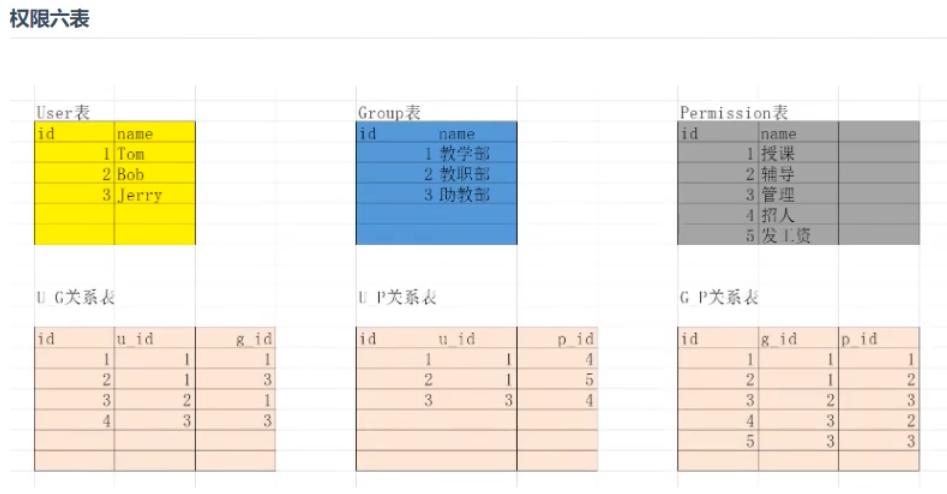
结论:没有特殊要求的Django项目可以直接采用Auth组件的权限六表,不需要自定义六个表,也不需要断开表关系,单可能需要自定义User表
1.3. 前后台权限控制
1)后台: 用户对各表操作,是后台项目完成的,我们可以直接借助admin后台项目(Django自带的)
后期也可以用xadmin框架来做后台用户权限管理. 如django的后台管理权限
auth_user 用户
auth_group 用户组
auth_permission 用户权限
auth_user_groups 用户属于的用户组, 用户组包含的用户
auth_group_permissions 用户组赋予的权限
auth_user_user_permissions 用户属于用户组, 因此用户也含有该组的权限 2)前台: 用户的权限管理如何处理
定义了一堆数据接口的视图类,不同的登录用户是否能访问这些视图类,能就代表有权限,不能就代表无权限
前台用户权限用drf框架的 三大认证: 认证, 权限, 频率
2. Django的内置RBAC(六表)

3. 实操
3.1. models.py
from django.db import models from django.contrib.auth.models import AbstractUser
class User(AbstractUser):
mobile = models.CharField(max_length=11, unique=True) def __str__(self):
return self.username class Book(models.Model):
name = models.CharField(max_length=64) def __str__(self):
return self.name class Car(models.Model):
name = models.CharField(max_length=64) def __str__(self):
return self.name
3.2. admin.py
from . import models from django.contrib.auth.admin import UserAdmin as DjangoUserAdmin # 自定义User表后,admin界面管理User类
class UserAdmin(DjangoUserAdmin):
# 添加用户课操作字段
add_fieldsets = (
(None, {
'classes': ('wide',),
'fields': ('username', 'password1', 'password2', 'is_staff', 'mobile', 'groups', 'user_permissions'),
}),
)
# 展示用户呈现的字段
list_display = ('username', 'mobile', 'is_staff', 'is_active', 'is_superuser') admin.site.register(models.User, UserAdmin)
admin.site.register(models.Book)
admin.site.register(models.Car)
3.3. 流程分析
先创建超级用户, 再通过超级用户创建普通用户, 为普通用户添加用户组,
为用户组设置A权限. 在为用户设置B权限. 最后将用户加入该用户组中,
于是用户在有B权限的基础之上, 又有了A权限.
五 django缓存机制
1. 缓存介绍
在动态网站中,用户所有的请求,服务器都会去数据库中进行相应的增,删,查,改,渲染模板,执行业务逻辑,最后生成用户看到的页面. 当一个网站的用户访问量很大的时候,每一次的的后台操作,都会消耗很多的服务端资源,所以必须使用缓存来减轻后端服务器的压力. 缓存是将一些常用的数据保存内存或者memcache中,在一定的时间内有人来访问这些数据时,则不再去执行数据库及渲染等操作,而是直接从内存或memcache的缓存中去取得数据,然后返回给用户.
2. Django中的6种缓存方式
1. 开发调试缓存
2. 内存缓存
3. 文件缓存
4. 数据库缓存
5. Memcache缓存(使用python-memcached模块)
6. Memcache缓存(使用pylibmc模块)
注: 经常使用的有文件缓存和Mencache缓存
3. Django6种缓存的配置
3.1. 开发调试(此模式为开发调试使用,实际上不执行任何操作)
settings.py文件配置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.dummy.DummyCache', # 缓存后台使用的引擎
'TIMEOUT': 300, # 缓存超时时间(默认300秒,None表示永不过期,0表示立即过期)
'OPTIONS':{
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
},
}
}
3.2. 内存缓存(将缓存内容保存至内存区域中)
settings.py文件配置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache', # 指定缓存使用的引擎
'LOCATION': 'unique-snowflake', # 写在内存中的变量的唯一值
'TIMEOUT':300, # 缓存超时时间(默认为300秒,None表示永不过期)
'OPTIONS':{
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
}
}
}
3.3. 文件缓存(把缓存数据存储在文件中)
settings.py文件配置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache', #指定缓存使用的引擎
'LOCATION': '/var/tmp/django_cache', #指定缓存的路径
'TIMEOUT':300, #缓存超时时间(默认为300秒,None表示永不过期)
'OPTIONS':{
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
}
}
}
3.4. 数据库缓存(把缓存数据存储在数据库中)
settings.py文件配置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache', # 指定缓存使用的引擎
'LOCATION': 'cache_table', # 数据库表
'OPTIONS':{
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
}
}
}
注意,创建缓存的数据库表使用的语句:
python manage.py createcachetable
3.5. Memcache缓存(使用python-memcached模块连接memcache)
Memcached是Django原生支持的缓存系统.要使用Memcached,需要下载Memcached的支持库python-memcached或pylibmc.
settings.py文件配置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', # 指定缓存使用的引擎
'LOCATION': '192.168.10.100:11211', # 指定Memcache缓存服务器的IP地址和端口
'OPTIONS':{
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
}
}
}
LOCATION也可以配置成如下:
'LOCATION': 'unix:/tmp/memcached.sock', # 指定局域网内的主机名加socket套接字为Memcache缓存服务器
'LOCATION': [ # 指定一台或多台其他主机ip地址加端口为Memcache缓存服务器
'192.168.10.100:11211',
'192.168.10.101:11211',
'192.168.10.102:11211',
]
3.6. Memcache缓存(使用pylibmc模块连接memcache)
settings.py文件配置
settings.py文件配置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', # 指定缓存使用的引擎
'LOCATION':'192.168.10.100:11211', # 指定本机的11211端口为Memcache缓存服务器
'OPTIONS':{
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
},
}
}
LOCATION也可以配置成如下:
'LOCATION': '/tmp/memcached.sock', # 指定某个路径为缓存目录
'LOCATION': [ # 分布式缓存,在多台服务器上运行Memcached进程,程序会把多台服务器当作一个单独的缓存,而不会在每台服务器上复制缓存值
'192.168.10.100:11211',
'192.168.10.101:11211',
'192.168.10.102:11211',
]
注: Memcached是基于内存的缓存,数据存储在内存中.所以如果服务器死机的话,数据就会丢失,所以Memcached一般与其他缓存配合使用
4. 前端混合开发Django中的缓存应用
4.1. 视图函数使用缓存
1) 视图
from django.shortcuts import render
from django.views.decorators.cache import cache_page # 单页面缓存
@cache_page(5) # 缓存5s钟
def single_page_cache(request):
import time
ctime = time.time()
return render(request, 'single_page_cache.html', locals())
2) 模板
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{{ ctime }}
</body>
</html>
3) 更改settings.py的配置
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache', # 指定缓存使用的引擎
'LOCATION': 'E:\django_cache', # 指定缓存的路径
'TIMEOUT': 300, # 缓存超时时间(默认为300秒,None表示永不过期)
'OPTIONS': {
'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300)
'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3)
}
}
}
然后再次刷新浏览器,可以看到在刚才配置的目录下生成的缓存文件
通过实验可以知道,Django会以自己的形式把缓存文件保存在配置文件中指定的目录中.
4.2. 全站使用缓存
既然是全站缓存,当然要使用Django中的中间件.
用户的请求通过中间件,经过一系列的认证等操作,如果请求的内容在缓存中存在,则使用FetchFromCacheMiddleware获取内容并返回给用户
当返回给用户之前,判断缓存中是否已经存在,如果不存在,则UpdateCacheMiddleware会将缓存保存至Django的缓存之中,以实现全站缓存
缓存整个站点,是最简单的缓存方法 在 MIDDLEWARE_CLASSES 中加入 “update” 和 “fetch” 中间件
MIDDLEWARE_CLASSES = (
‘django.middleware.cache.UpdateCacheMiddleware’, #第一
'django.middleware.common.CommonMiddleware',
‘django.middleware.cache.FetchFromCacheMiddleware’, #最后
)
“update” 必须配置在第一个
“fetch” 必须配置在最后一个
注: “update” 必须配置在第一个
1) 修改settings.py配置文件
MIDDLEWARE_CLASSES = (
'django.middleware.cache.UpdateCacheMiddleware', # 响应HttpResponse中设置几个headers
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.auth.middleware.SessionAuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'django.middleware.security.SecurityMiddleware',
'django.middleware.cache.FetchFromCacheMiddleware', # 用来缓存通过GET和HEAD方法获取的状态码为200的响应 ) CACHE_MIDDLEWARE_SECONDS=10
2) 视图函数
from django.views.decorators.cache import cache_page
import time
from .models import * def index(request):
t=time.time() # 获取当前时间
bookList=Book.objects.all()
return render(request,"index.html",locals()) def foo(request):
t=time.time() # 获取当前时间
return HttpResponse("HELLO:"+str(t))
3) 模板
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h3 style="color: green">当前时间:-----{{ t }}</h3> <ul>
{% for book in bookList %}
<li>{{ book.name }}--------->{{ book.price }}$</li>
{% endfor %}
</ul> </body>
</html>
4.3. 局部视图缓存
例子,刷新页面时,整个网页有一部分实现缓存
1) 视图
def page_local_cache(request):
import time
ctime = time.time()
return render(request, 'page_local_cache.html', locals())
2) 模板
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h2>没有缓存的时间: {{ ctime }}</h2> <hr>
{% load cache %}
{# cache标签第一个参数是时间, 第二个参数是存取的key值 #}
{% cache 5 'key' %}
<h2>局部缓存的时间:{{ ctime }}</h2>
{% endcache %}
</body>
</html>
5. 前后端分离Django中的缓存应用
使用:
from django.core.cache import cache
cache.set('key',value可以是任意数据类型)
cache.get('key')
应用场景:
第一次查询所有图书,你通过多表联查序列化之后的数据,直接缓存起来
后续,直接先去缓存查,如果有直接返回,没有,再去连表查,返回之前再缓存
实例:
from django.core.cache import cache class Person:
def __init__(self, name, age):
self.name = name
self.age = age def test_cache(request):
p = Person('lqz', 18)
cache.set('name', p)
import time
ctime = time.time()
return render(request, 'index.html', context={'ctime': ctime}) def test_cache2(request):
p = cache.get('name')
print(type(p))
print(p.name)
import time
ctime = time.time()
return render(request, 'index.html', context={'ctime': ctime})
drf(分页、IP限制用户频率、自动生成文档、RBAC、django缓存)的更多相关文章
- 使用 Swagger 自动生成 ASP.NET Core Web API 的文档、在线帮助测试文档(ASP.NET Core Web API 自动生成文档)
对于开发人员来说,构建一个消费应用程序时去了解各种各样的 API 是一个巨大的挑战.在你的 Web API 项目中使用 Swagger 的 .NET Core 封装 Swashbuckle 可以帮助你 ...
- eoLinker 新功能发布,增加了识别代码注释自动生成文档功能
产品地址:https://www.eolinker.com开源代码:https://www.eolinker.com/#/os/download在线生成代码注释工具:http://tool.eolin ...
- SpringBoot 集成Swagger2自动生成文档和导出成静态文件
目录 1. 简介 2. 集成Swagger2 2.1 导入Swagger库 2.2 配置Swagger基本信息 2.3 使用Swagger注解 2.4 文档效果图 3. 常用注解介绍 4. Swagg ...
- MVC WEB api 自动生成文档
最近在一直在用webapi做接口给移动端用.但是让我纠结的时候每次新加接口或者改动接口的时候,就需要重新修改文档这让我很是苦恼.无意中发现.webapi居然有自动生成文档的功能....真是看见了救星啊 ...
- 使用swagger在netcorewebapi项目中自动生成文档
一.背景 随着前后端分离模式大行其道,我们需要将后端接口撰写成文档提供给前端,前端可以查看我们的接口,并测试,提高我们的开发效率,减少无效的沟通.在此情况下,通过代码自动生成文档,这种需求应运而生,s ...
- 【Sphinx】 为Python自动生成文档
sphinx 前言 Sphinx是一个可以用于Python的自动文档生成工具,可以自动的把docstring转换为文档,并支持多种输出格式包括html,latex,pdf等 开始 建一个存放文档的do ...
- 使用doctest代码测试和Sphinx自动生成文档
python代码测试并自动生成文档 Tips:两大工具:doctest--单元测试.Sphinx--自动生成文档 1.doctest doctest是python自带的一个模块.doctest有两种使 ...
- 用doxygen自动生成文档
1. 添加符合doxygen解析规则的注释 (比如函数说明,函数参数/返回值说明) 用qt-creator可以在函数上方一行键入“/**”,然后直接回车,就可以自动生成默认的格式. 2. 安装doxy ...
- 使用Sphinx为你的python模块自动生成文档
Sphinx是一个可以用于Python的自动文档生成工具,可以自动的把docstring转换为文档,并支持多种输出格式包括html,latex,pdf等. 安装 创建一个sphinx项目 下面的命令会 ...
- linux c/c++ 代码使用 doxygen 自动生成文档
www.doxygen.org 的使用非常方便,下面分成2步介绍一下 1. 注释风格,需要在c/c++代码中按照下面的风格添加注释,基本上还是很顺手的 C++的注释风格 主要使用下面这种样式:即在注释 ...
随机推荐
- 小知识:TFA收集日志报错空间不足
今天在某客户环境下分析某节点驱逐的故障,发现有安装TFA,所以使用一键收集包含故障时刻的日志 tfactl diagcollect -from "2020-08-14 03:00:00&qu ...
- 基于OpenTelemetry实现Java微服务调用链跟踪
本文分享自华为云社区<基于OpenTelemetry实现Java微服务调用链跟踪>,作者: 可以交个朋友. 一 背景 随着业务的发展,所有的系统都会走向微服务化体系,微服务进行拆分后,服务 ...
- NC51216 花店橱窗
题目链接 题目 题目描述 小q和他的老婆小z最近开了一家花店,他们准备把店里最好看的花都摆在橱窗里. 但是他们有很多花瓶,每个花瓶都具有各自的特点,因此,当各个花瓶中放入不同的花束时,会产生不同的美学 ...
- cmp命令
cmp命令 cmp命令用来比较两个文件是否有差异,当相互比较的两个文件完全一样时,则该指令不会输出任何信息,若发现有差异,预设会标示出第一个不同之处的字符和列数编号,若不指定任何文件名称或是所给予的文 ...
- 微信小程序引入iconfont实现添加自定义颜色图标
说明 最近搞微信小程序,需要添加一些图标,发现引入iconfont还是有几个步骤,就记录下来分享以下. 以下配置方法支持自定义颜色的. 操作步骤 1. 在iconfont网站挑选自己需要的图标,添加到 ...
- Nginx开启gzip提升访问效率
说明 最近网站考虑开启gzip压缩试试效果,gzip是nginx服务器的ngx_http_gzip_module模块提供的在线实时数据压缩功能. 通过开启gzip功能,可对服务器响应的数据进行压缩处理 ...
- 责任链模式与spring容器的搭配应用
背景 有个需求,原先只涉及到一种A情况设备的筛选,每次筛选会经过多个流程,比如先a功能,a功能通过再筛选b功能,然后再筛选c功能,以此类推.现在新增了另外一种B情况的筛选,B情况同样需要A情况的筛选流 ...
- String--cannot convert from 'const char *' to 'LPTSTR'错误
这种错误,很多情况下是类型不匹配 LPTSTR表示为指向常量TCHAR字符串的长指针 TCHAR可以是wchar_t或char,基于项目是多字节还是宽字节版本. 看下面的代码,代码来源:Example ...
- 负载均衡load balancing和算法分类概要介绍
一.负载均衡介绍 1.1 什么是负载均衡 负载均衡(load balancing) 它是计算机的一种技术,用来在计算机集群.网络连接.CPU.磁盘驱动器或其他资源中分配负载,以达到优化资源使用.最大化 ...
- leetcode 平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树. 本题中,一棵高度平衡二叉树定义为: 一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 . 示例 1: 输入:root = [3,9,20,n ...