LinkedHashMap原理详解—从LRU缓存机制说起
写在前面
从一道Leetcode题目说起
首先,来看一下Leetcode里面的一道经典题目:146.LRU缓存机制,题目描述如下:
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现
LRUCache类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。函数
get和put必须以O(1)的平均时间复杂度运行。
LRU 的全称是 Least Recently Used,也就是说我们认为最近使用过的数据应该是是「有用的」,很久都没用过的数据应该是无用的,内存满了就优先删那些很久没用过的数据。
分析
要让 LRU 的 put 和 get 方法的时间复杂度为 O(1),可以总结出 LRU 这个数据结构必要的条件:
- 显然 LRU 中的元素必须有时序,以区分最近使用的和久未使用的数据,当容量满了之后要删除最久未使用的那个元素腾位置。
- 要在 LRU 中快速找某个
key是否已存在并得到对应的val; - 每次访问 LRU 中的某个
key,需要将这个元素变为最近使用的,也就是说 LRU 要支持在任意位置快速插入和删除元素。
那么,什么数据结构同时符合上述条件呢?哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表 LinkedHashMap。
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样:
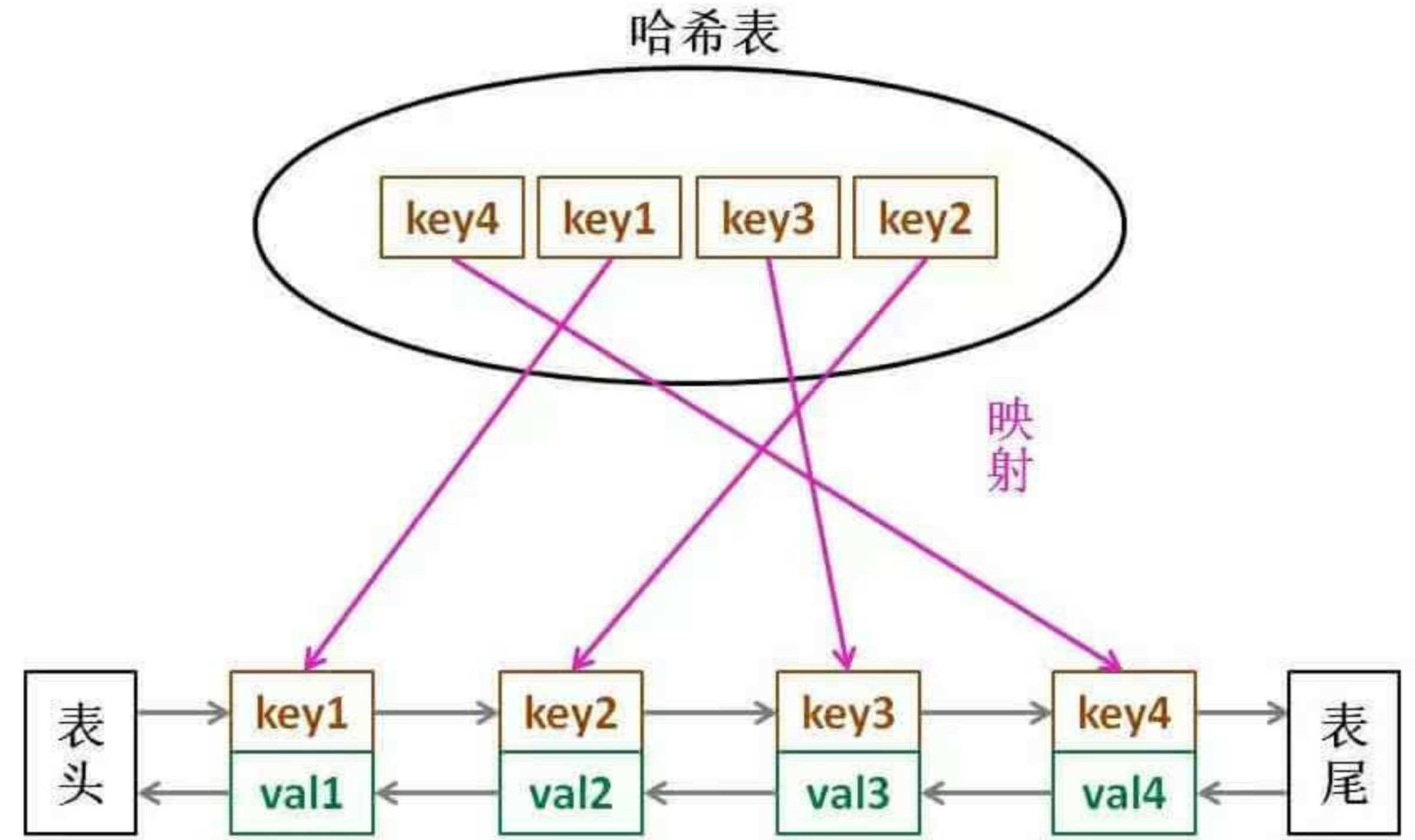
借助这个结构,逐一分析上面的 3 个条件:
- 如果我们每次默认从链表尾部添加元素,那么显然越靠尾部的元素就是最近使用的,越靠头部的元素就是最久未使用的。
- 对于某一个
key,我们可以通过哈希表快速定位到链表中的节点,从而取得对应val。 - 链表显然是支持在任意位置快速插入和删除的,改改指针就行。只不过传统的链表无法按照索引快速访问某一个位置的元素,而这里借助哈希表,可以通过
key快速映射到任意一个链表节点,然后进行插入和删除。
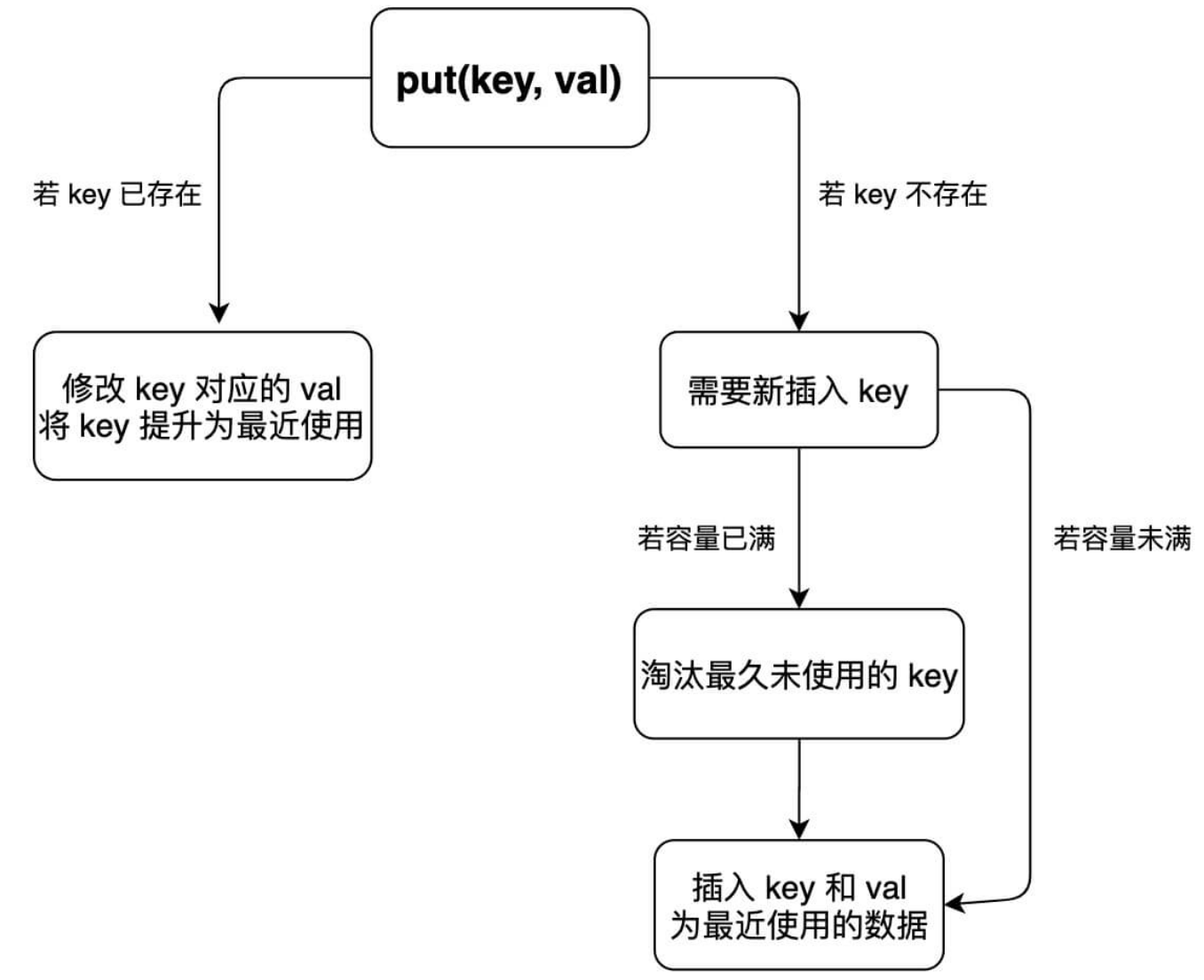
put方法流程图:
LinkedHashMap介绍
LinkedHashSet和LinkedHashMap其实也是一回事。LinkedHashSet和LinkedHashMap在Java里也有着相同的实现,前者仅仅是对后者做了一层包装,也就是说LinkedHashSet里面有一个LinkedHashMap(适配器模式)。
LinkedHashMap实现了Map接口,即允许放入key为null的元素,也允许插入value为null的元素。从名字上可以看出该容器是linked list和HashMap的混合体,也就是说它同时满足HashMap和linked list的某些特性。可将LinkedHashMap看作采用linked list增强的HashMap。

事实上LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样的好处:
可以保证元素的迭代顺序跟插入顺序相同。跟HashMap相比,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。
迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关。
有两个参数可以影响LinkedHashMap的性能:初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。这点与HashMap是一样的
方法剖析
get()
get(Object key)方法根据指定的key值返回对应的value。该方法跟HashMap.get()方法的流程几乎完全一样
put()
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于get()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry。
注意,这里的插入有两重含义:
- 从table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。
- 从header的角度看,新的entry需要插入到双向链表的尾部。

addEntry()代码如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}
上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。addBefore()的代码如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
remove()
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。
注意,这里的删除也有两重含义:
从table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。
从header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。
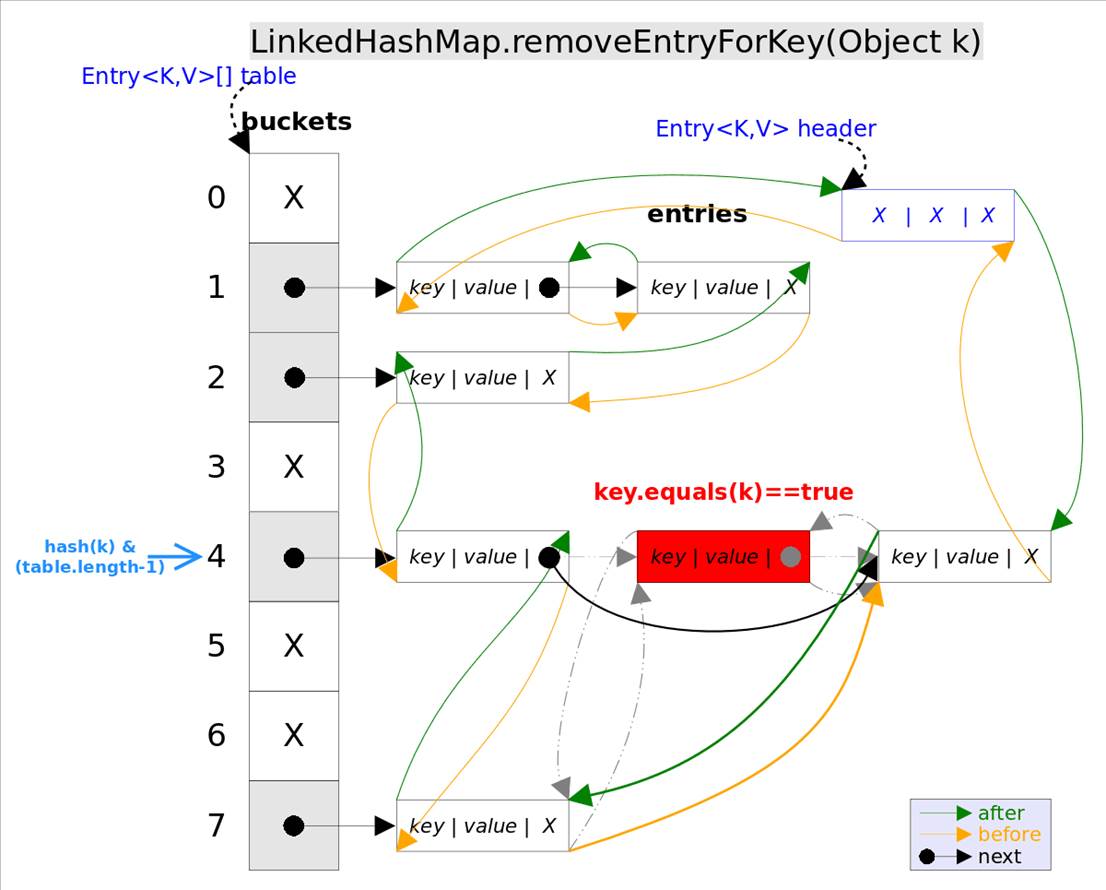
removeEntryForKey()对应的代码如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}
LinkedHashSet
LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法,因此LinkedHashSet的实现非常简单
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
......
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}
关于作者
来自一线程序员Seven的探索与实践,持续学习迭代中~
本文已收录于我的个人博客:https://www.seven97.top
公众号:seven97,欢迎关注~
LinkedHashMap原理详解—从LRU缓存机制说起的更多相关文章
- 详解ASP.NET缓存机制
文中对ASP.NET的缓存机制进行了简述,ASP.NET中的缓存极大的简化了开发人员的使用,如果使用得当,程序性能会有客观的提升.缓存是在内存存储数据的一项技术,也是ASP.NET中提供的重要特性之一 ...
- Non-local Neural Networks 原理详解及自注意力机制思考
Paper:https://arxiv.org/abs/1711.07971v1 Author:Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming ...
- 【转】VLAN原理详解
1.为什么需要VLAN 1.1 什么是VLAN? VLAN(Virtual LAN),翻译成中文是“虚拟局域网”.LAN可以是由少数几台家用计算机构成的网络,也可以是数以百计的计算机构成的企业网络.V ...
- VLAN原理详解[转载] 网桥--交换机---路由器
来自:http://blog.csdn.net/phunxm/article/details/9498829 一.什么是桥接 桥接工作在OSI网络参考模型的第二层数据链路层,是一种以 ...
- 通过 JFR 与日志深入探索 JVM - TLAB 原理详解
全系列目录:通过 JFR 与日志深入探索 JVM - 总览篇 什么是 TLAB? TLAB(Thread Local Allocation Buffer)线程本地分配缓存区,这是一个线程专用的内存分配 ...
- epoll原理详解及epoll反应堆模型
本文转载自epoll原理详解及epoll反应堆模型 导语 设想一个场景:有100万用户同时与一个进程保持着TCP连接,而每一时刻只有几十个或几百个TCP连接是活跃的(接收TCP包),也就是说在每一时刻 ...
- Spring框架系列(7) - Spring IOC实现原理详解之IOC初始化流程
上文,我们看了IOC设计要点和设计结构:紧接着这篇,我们可以看下源码的实现了:Spring如何实现将资源配置(以xml配置为例)通过加载,解析,生成BeanDefination并注册到IoC容器中的. ...
- SSL/TLS 原理详解
本文大部分整理自网络,相关文章请见文后参考. SSL/TLS作为一种互联网安全加密技术,原理较为复杂,枯燥而无味,我也是试图理解之后重新整理,尽量做到层次清晰.正文开始. 1. SSL/TLS概览 1 ...
- 锁之“轻量级锁”原理详解(Lightweight Locking)
大家知道,Java的多线程安全是基于Lock机制实现的,而Lock的性能往往不如人意. 原因是,monitorenter与monitorexit这两个控制多线程同步的bytecode原语,是JVM依赖 ...
- 节点地址的函数list_entry()原理详解
本节中,我们继续讲解,在linux2.4内核下,如果通过一些列函数从路径名找到目标节点. 3.3.1)接下来查看chached_lookup()的代码(namei.c) [path_walk()> ...
随机推荐
- [oeasy]python001_先跑起来_python_三大系统选择_windows_mac_linux
先跑起来 Python 什么是 Python? Python [ˈpaɪθɑ:n] 是 一门 适合初学者 的编程语言 添加图片注释,不超过 140 字(可选) 类库 众多 几行代码 就 ...
- [翻译]欢迎使用C#9.0
本文由公众号[开发者精选资讯](微信号:yuantoutiao)翻译首发,转载请注明来源 C# 9.0 is taking shape, and I'd like to share our think ...
- Java 根据XPATH批量替换XML节点中的值
根据XPATH批量替换XML节点中的值 by: 授客 QQ:1033553122 测试环境 JDK 1.8.0_25 代码实操 message.xml文件 <Request service=&q ...
- vue 拖拉改变盒子高度(mousedown、mousemove、mouseup)流畅不卡顿
需求:上下两个盒子之间添加可拖拽按钮,实现高度变化 html: <textarea :id="'mycode'+(index*1+1)" :ref="'mycode ...
- 前缀函数及 Knuth–Morris–Pratt 算法学习笔记
\(\text{1 引言 Preface}\) 对于形如以下的问题: 给予一个模式串 \(T\) 和主串 \(S\),在主串中寻找 \(T\). 我们称之为字符串匹配. 很显然朴素算法时间复杂度是 \ ...
- appium+python自动化-文本(name)定位
前言 appium1.5以下老的版本是可以通过name定位的,新版本从1.5以后都不支持name定位了 name定位报错 1.最新版appium V1.7用name定位,报错: selenium.co ...
- nats 简介和使用
nats 简介和使用 nats 有 3 个产品 core-nats: 不做持久化的及时信息传输系统 nats-streaming: 基于 nats 的持久化消息队列(已弃用) nats-jetstre ...
- [rCore学习笔记 019]在main中测试本章实现
写在前面 本随笔是非常菜的菜鸡写的.如有问题请及时提出. 可以联系:1160712160@qq.com GitHhub:https://github.com/WindDevil (目前啥也没有 批处理 ...
- 【转载】 图解协程调度模型-GMP模型
原文地址: https://www.cnblogs.com/codexiaoyi/p/14975236.html =========================================== ...
- 分布式深度学习计算框架依赖环境——NCCL的安装
分布式深度学习计算框架(MindSpore, PyTorch)依赖环境--NCCL, NCCL提供多显卡之间直接进行数据交互的功能(可以跨主机进行). 注意: 本文环境为 Ubuntu18.04 以 ...