[转帖]数据库篇-MySql架构介绍
https://zhuanlan.zhihu.com/p/147161770
公众号-坚持原创,码字不易。加微信 : touzinv 关注分享,手有余香~
本篇咱们也来聊聊mysql物理和逻辑架构,还有其组件。MySQL的架构具备灵活性,因为它把不同的存储引擎作为插件。
因此,MySQL的架构和行为也会随着存储引擎的改变而改变。
我们重点讨论InnoDB,因为它是MySQL的默认存储引擎。文章最后我们再来对比主流的MySql引擎,从与其他引擎对比中,看看为什么InnoDB会被选为默认存储引擎。
01 先来看 物理 架构

02 配置文件
auto.cnf: 包含server_uuidmy.cnf: MySQL配置文件
03 其他文件

04 MySQL 逻辑 架构
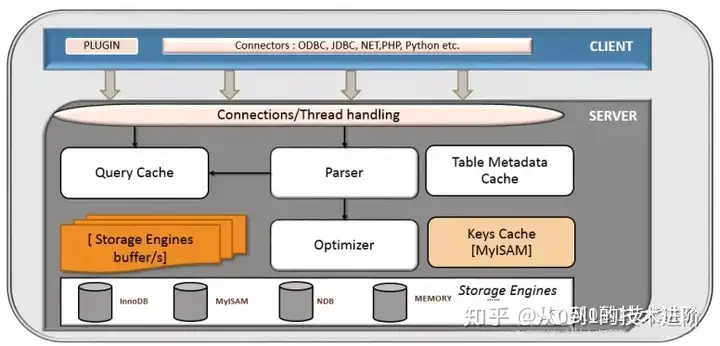
- Client :
提供连接MySQL服务器功能的常用工具集 - Server :
MySQL实例,真正提供数据存储和数据处理功能的MySQL服务器进程 - mysqld:
MySQL服务器守护程序,在后台运行。它管理着客户端请求。mysqld是一个多线程的进程,允许多个会话连接,端口监听连接,管理MySQL实例 - MySQL memory allocation:
MySQL的要求的内存空间是动态的,比如innodb_buffer_pool_size (from 5.7.5), key_buffer_size。每个会话都有独一无二的执行计划,我们只能共享同一会话域内的数据集。 - SESSION
为每个客户端连接分配一个会话,动态分配和回收。用于查询处理,每个会话同时具备一个缓冲区。每个会话是作为一个线程执行的 - Parser
检测SQL语句语法,为每条SQL语句生成SQL_ID,用户认证也发生在这个阶段 - Optimizer
创造一个有效率的执行计划(根据具体的存储引擎)。它将会重写查询语句。比如:InnoDB有共享缓冲区,所以,优化器会首先从预先缓存的数据中提取。使用 table statistics optimizer将会为SQL查询生成一个执行计划。用户权限检查也发生在这个阶段。 - Metadata cache
缓存对象元信息和统计信息 - Query cache
共享在内存中的完全一样的查询语句。如果完全相同的查询在缓存命中,MySQL服务器会直接从缓存中去检索结果。缓存是会话间共享的,所以为一个客户生成的结果集也能为另一个客户所用。查询缓存基于SQL_ID。将SELECT语句写入视图就是查询缓存最好的例子。 - key cache
缓存表索引。MySQL keys是索引。如果索引数据量小,它将缓存索引结构和叶子节点(存储索引数据)。如果索引很大,它只会缓存索引结构,通常供MyISAM存储引擎使用
05 SQL执行
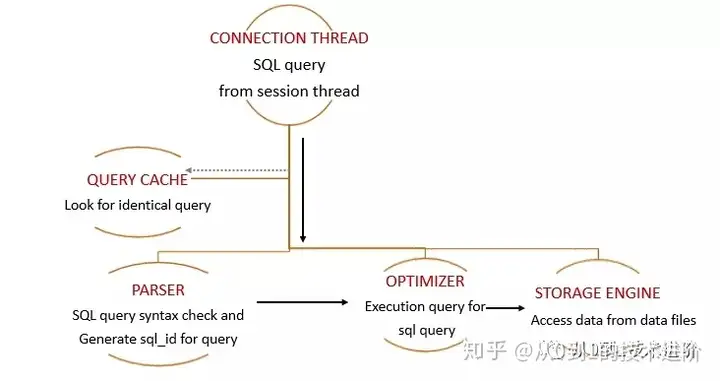
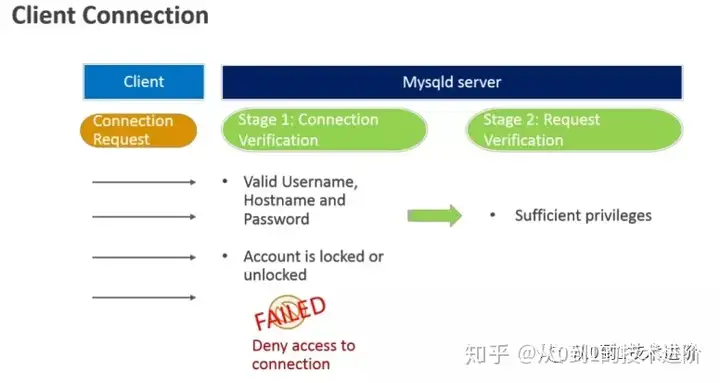
06 MySQL连接
07 InnoDB存储引擎架构

08 TABLESPACE
InnoDB存储空间被切分成tablespace,tablespace是一个与多个数据文件相关联的逻辑结构。
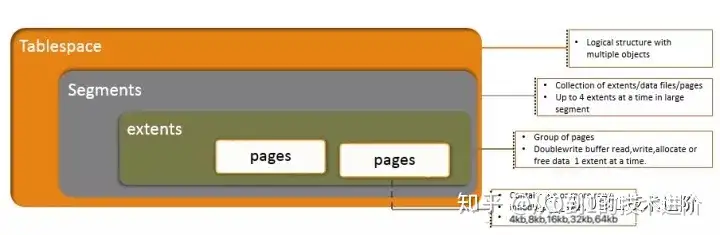
- Pages
InnoDB最小的数据存储单元被也称作块。默认的页框是16KB,一个页包含多行。
可用页大小: 4kb,8kb,16kb,32kb,64kb
配置变量名 :innodb_page_size,在初始化mysqld时配置 - Extents
一组页组成一个区,InnoDB为了更好的I/O吞吐率,每次读写都是按照区为单位。
一组16KB的页,一个区可以1MB,双写缓冲区(Doublewrite buffer )每次分配/读/写都是以区为单位。 - Segments
4个区构成一个Segments
09 InnoDB存储引擎
- ACID事务支持
- 行锁模式
- 事务REDO&UNDO支持
- 多数据文件
- 逻辑对象结构(InnoDB数据和日志缓冲区)
- InnoDB数据是百分百的具备逻辑结构,数据物理存储。
- InnoDB读取物理数据,创建逻辑结构[Blocks and Rows]
- 逻辑存储称为
TABLESPACE
10 InnoDB 内存中组件
- InnoDB buffer pool
InnoDB存储引擎的核心缓冲区。在这个缓冲区之中,加载表和索引数据 - InnoDB缓存表数据和索引数据的主要区域
- 占据80%以上的物理内存,在专用数据库服务器中
- 所有会话的共享缓冲区
- InnoDB使用LRU页面置换算法
Redo log buffer,redo logs缓冲区,保存写到redo log(重放日志)的数据。周期性的将缓冲区内的数据写入redo日志中。将内存中的数据写入磁盘的行为由innodb_log_at_trx_commit 和 innodb_log_at_timeout 调节。较大的redo日志缓冲区允许大型事务在事务提交前不进行写磁盘操作。
变量:innodb_log_buffer_size (default 16M)
11 在磁盘上的组件
- 系统表空间(tablespace)
除了存储表数据之外,InnoDB也支持查找表元信息,存储和检索MVCC信息以兑现服从ACID和事务隔离性等原则。它包含几种类型的InnoDB对象信息。 - 其包含的文件:
- Table Data Pages
- Table Index Pages
- Data Dictionary
- MVCC Control Data
- Undo Space
- Rollback Segments
- Double Write Buffer (Pages Written in the Background to avoid OS
caching) Insert Buffer (Changes to Secondary Indexes) - 变量:innodb_data_file_path = /ibdata/ibdata1:10M:autoextend
- 激活:
innodb_file_per_table选项,你可以将每个新创建的表存储到不同的tablespace中。这种做法的优点是减少磁盘上数据文件中的碎片 - 通用tablespace
Shared tablespace to store multiple table data. Introduce in MySQL 5.7.6. A user has to create this using CREATE TABLESPACE syntax. TABLESPACE option can be used with CREATE TABLE to create a table and ALTER TABLE to move a table in general table.
共享的tablespace存储多个表信息,在MySQL 5.7.6时引入。用户只能使用CREATE TABLESPACE创建一个这样的表空间。TABLESPACE选项可以在使用CREATE TABLE命令创建一个表然后 ALTER TABLE 将表移入通用空间时发挥作用。
- InnoDB数据字典
在系统tablespace中的存储区域,由系统内部表(供mysql服务器使用的表)和对象元数据(表,索引,列信息)组成 - 双写缓冲区(Double write buffer)
系统tablespace的存储区域,InnoDB在写入物理文件之前先将页从InnoDB buffer pool写入此空间。mysqld进程突然崩溃会导致部分写问题。InnoDB可以从这个区域拿到一个备份。Variable: inndb_doublewrite (default enable) - REDO logs
用于灾难恢复。mysqld启动的时候,InnoDB会尝试执行自动恢复,将不完整的事务更改矫正。还未完成更新数据文件的事务会在mysqld启动时会根据此日志记录中的信息被重放。它使用LSN(Log Sequence Number)值来重放信息,因为mySQL会为每个事务赋予一个ID。因为大量数据更改不可能及时写道磁盘,所以得先记录到redo日志,然后再写入磁盘。
再redo日志,所有更改都会带有 row_id, 旧的列值,新的列值, session_id 和时间。

- UNDO日志和UNDO表空间
UNDO tablespace包含一个或多个undo日志文件。UNDO通过为事务(MVCC)保存被更改还未提交的值保持读一致性。未提交值从这个存储区域读取。UNDO日志也被叫做回滚数据段。
默认地,UNDO日志是系统表空间的一部分。但MySQL允许UNDO日志置于一个单独的表空间中 [Introduce in MySQL 5.6]。这需要在初始化mysqld之前进行更改才起作用。
当我们配置单独UNDO表空间时,系统表空间的UNDO日志就被抑制了,但是一旦配置成单独的,我们只能删除UNDO日志的一部分,比如过期日志,而不能删除它。 - 临时表空间
为临时表和相关对象提供存储功能,存储包括临时表未提交的数据。在MySQL 5.7.2引入,用于对临时表修改的回滚。ibtmp1每次系统启动被重新创建,避免REDO日志对临时表的I/O操作。

12 MySQL存储引擎对比
虽然InnoDB是默认引擎,但是了解其他存储引擎的适用场景,可以更利于我们建表时合理作出选择。MySQL的存储引擎是表级别的概念,我们无法创建database时指定存储引擎,而是只能在创建表的时候可以明确指定使用哪种存储引擎。因此存储引擎也通常被称作“表类型”。也就是说,存储引擎是负责跟文件系统真正数据打交道的工具,它却决定了表中是如何存储数据的,不同存储引擎的工作特性是各不相同的。
1>.查看MySQL支持的所有存储引擎
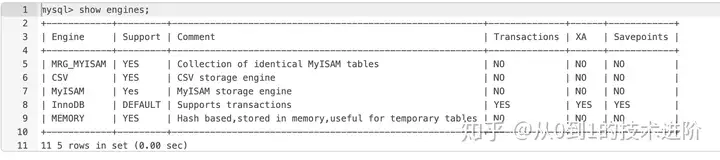

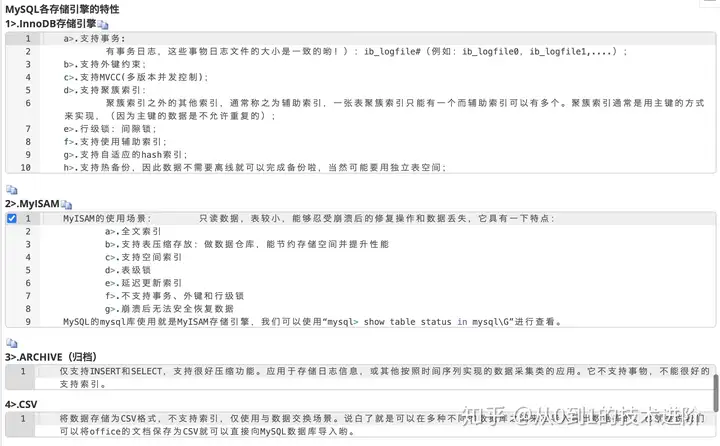
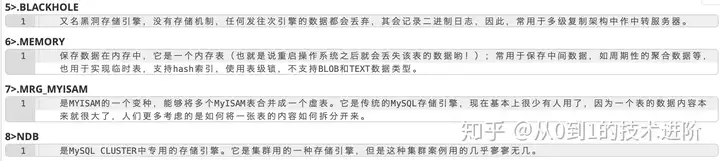
小结:Innodb强调多功能性,支持的拓展功能比较多,myisam主要侧重于性能
区别:
1、InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
2、InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
3、InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
4、Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高;
如何选择
1、是否要支持事务,如果要请选择innodb,如果不需要可以考虑MyISAM;
2、如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读写也挺频繁,请使用InnoDB。
3、系统奔溃后,MyISAM恢复起来更困难,能否接受;
4、MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的,如果你不知道用什么,那就用InnoDB,至少不会差。
[转帖]数据库篇-MySql架构介绍的更多相关文章
- iOS开发数据库篇—SQLite简单介绍
iOS开发数据库篇—SQLite简单介绍 一.离线缓存 在项目开发中,通常都需要对数据进行离线缓存的处理,如新闻数据的离线缓存等. 说明:离线缓存一般都是把数据保存到项目的沙盒中.有以下几种方式 (1 ...
- 【转】 iOS开发数据库篇—SQLite简单介绍
开始学SQLite啦, 原文: http://www.cnblogs.com/wendingding/p/3868893.html iOS开发数据库篇—SQLite简单介绍 一.离线缓存 在项目开发中 ...
- 【数据库】MySQL & SQL 介绍
文章目录 MySQL & SQL 介绍 1.MySQL的背景 2.MySQL的优点 3.MySQL的安装 4.MySQL服务的启动和停止 方式一 方式二 5.MySQL服务的登录和退出 方式一 ...
- iOS开发数据库篇—FMDB简单介绍
iOS开发数据库篇—FMDB简单介绍 一.简单说明 1.什么是FMDB FMDB是iOS平台的SQLite数据库框架 FMDB以OC的方式封装了SQLite的C语言API 2.FMDB的优点 使用起来 ...
- 详解MySQL第一篇—MySQL简要介绍及DDL语句
背景:近几年,开源数据库逐渐流行起来.由于具有免费使用.配置简单.稳定性好.性能优良等优点,开源数据库在中低端应用上占据了很大的市场份额,而 MySQL 正是开源数据库中的杰出代表.MySQL 数据库 ...
- 数据库之MySQL的介绍与使用20180703
/*******************************************************************************************/ 一.mysq ...
- [MySQL实战-Mysql基础篇]-mysql架构
1.基本组成 下面是mysql的基本架构示意图 图一 图二 我们可以从图上看出,mysql大体分为两个部分,一个是server层,另一个是引擎层. server层中包含了连接器.查询缓存.分析器.优 ...
- Mysql双主互备+keeplived高可用架构介绍
一.Mysql双主互备+keeplived高可用架构介绍 Mysql主从复制架构可以在很大程度保证Mysql的高可用,在一主多从的架构中还可以利用读写分离将读操作分配到从库中,减轻主库压力.但是在这种 ...
- [转帖]我花了10个小时,写出了这篇K8S架构解析
我花了10个小时,写出了这篇K8S架构解析 https://www.toutiao.com/i6759071724785893891/ 每个微服务通过 Docker 进行发布,随着业务的发展,系统 ...
- MySQL高级知识- MySQL的架构介绍
[TOC] 1.MySQL 简介 概述 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司. MySQL是一种关联数据库管理系统,将数据保存在不同的表中,而 ...
随机推荐
- 神经网络入门篇:详解为什么需要非线性激活函数?(why need a nonlinear activation function?)
为什么需要非线性激活函数? 为什么神经网络需要非线性激活函数?事实证明:要让的神经网络能够计算出有趣的函数,必须使用非线性激活函数,证明如下: 这是神经网络正向传播的方程,现在去掉函数\(g\),然后 ...
- Jenkins Pipeline 流水线 - 声明式 Demo
Jenkins Pipeline 流水线 流水线既能作为任务的本身,也能作为 Jenkinsfile 使用流水线可以让我们的任务从UI手动操作,转换为代码化,像dockerfile 一样.从shell ...
- PlayWright安装及使用
PlayWright是由业界大佬微软(Microsoft)开源的端到端 Web 测试和自动化库,可谓是大厂背书,功能满格,虽然作为无头浏览器,该框架的主要作用是测试 Web 应用,但事实上,无头浏览器 ...
- Python分析大数据,推荐四款加速器
在数据科学计算.机器学习.以及深度学习领域,Python 是最受欢迎的语言.Python 在数据科学领域,有非常丰富的包可以选择,numpy.scipy.pandas.scikit-learn.mat ...
- 【Docker】基础原理
基础原理 基础流程 Docker镜像讲解 Docker容器讲解 创建容器的两种方式 容器创建命令详解
- Codeforces Round #712 (Div. 2) 个人题解
这一场打的又很差(掉分预定),D题想不出来. A. Déjà Vu 这题首先判断字符串是否全由 a 组成,如果是的话输出 NO int main() { ios_base::sync_with_std ...
- 版本升级 | 兼容VSCode及全系IDE,代码风险一键查询
OpenSCA插件上新啦~ Jetbrains IDE插件全新升级,很多朋友提了需求的VSCode咱也支持上啦~ 当然,CEC-IDE也是兼容的(手动狗头). OpenSCA-VSCode-plugi ...
- Serverless 时代开启,云计算进入业务创新主战场
作者 | 于洪涛 "我们希望让用户做得更少而收获更多,通过 Serverless 化,让企业使用云服务像用电一样简单." Serverless 化正在成为全新的软件研发范式,阿里云 ...
- C#读取FX5U线圈(modbusTCP)
第一步:导入所需的类库 第二步:包含命名空间 第三步:实例化modbus类 ModbusTcpNet busTcpClient = null; busTcpClient = new ModbusTcp ...
- 处理uniapp(同理小程序)开发中使用rich-text富文本解析,图片未自适应宽度问题(图片显示不全)
https://www.cnblogs.com/luyaru/p/15538883.html