EasyNLP集成K-BERT算法,借助知识图谱实现更优Finetune
导读
知识图谱(Knowledge Graph)的概念⾸次出现2012年,由Google提出,它作为⼀种⼤规模语义⽹络, 准确地描述了实体以及实体之间的关系。知识图谱最早应⽤于搜索引擎,⽤于准备返回⽤户所需的知识。随着预训练语⾔模型的不断发展,将知识图谱中的知识三元组融⼊预训练模型,对提升模型的效果有重要的作⽤。经典的知识注⼊算法直接将知识图谱中实体的词嵌⼊向量注⼊预训练模型的词嵌⼊向量中;然⽽,知识图谱中实体的词嵌⼊向量和预训练模型的词嵌⼊向量的向量空间不⼀致,⽽且容易引起知识噪⾳(Knowledge Noise)的问题。K-BERT算法提出利⽤Visible Matrix在BERT模型中引⼊外部知识,具有较好的效果。 因此,我们在EasyNLP这⼀算法框架中集成了K-BERT算法,使⽤户在具有知识图谱的情况下,取得更好的模型Finetune效果。
EasyNLP(https://github.com/alibaba/EasyNLP)是阿⾥云机器学习PAI 团队基于 PyTorch 开发的易⽤且丰富的中⽂NLP算法框架,⽀持常⽤的中⽂预训练模型和⼤模型落地技术,并且提供了从训练到部署的⼀站式 NLP 开发体验。EasyNLP 提供了简洁的接⼝供⽤户开发 NLP 模型,包括NLP应⽤ AppZoo 和预训练 ModelZoo,同时提供技术帮助⽤户⾼效的落地超⼤预训练模型到业务。由于跨模态理解需求的不断增加,EasyNLP也⽀持各种跨模态模型,特别是中⽂领域的跨模态模型,推向开源社区,希望能够服务更多的 NLP 和多模态算法开发者和研 究者,也希望和社区⼀起推动 NLP /多模态技术的发展和模型落地。
本⽂简要介绍K-BERT的技术解读,以及如何在EasyNLP框架中使⽤K-BERT模型。
K-BERT模型详解
BERT等预训练语言模型从大规模语料库中捕获文本语言表示,但缺乏领域特定的知识。而领域专家在阅读领域文本时,会利用相关知识进行推理。为了实现这一功能,K-BERT提出了面向知识图谱的知识增强语言模型,将三元组作为领域知识注入到句子中。然而,过多的知识融入会导致知识噪音,使句子偏离其正确的含义。为了克服知识噪音, K-BERT引入了Soft-position和Visibel Matrix来限制知识的影响。由于K-BERT能够从预训练的BERT中加载模型参数,因此通过配备KG,可以很容易地将领域知识注入到模型中,而不需要对模型进行预训练。K-BERT的模型架构和知识注入的应用示例如下所示:
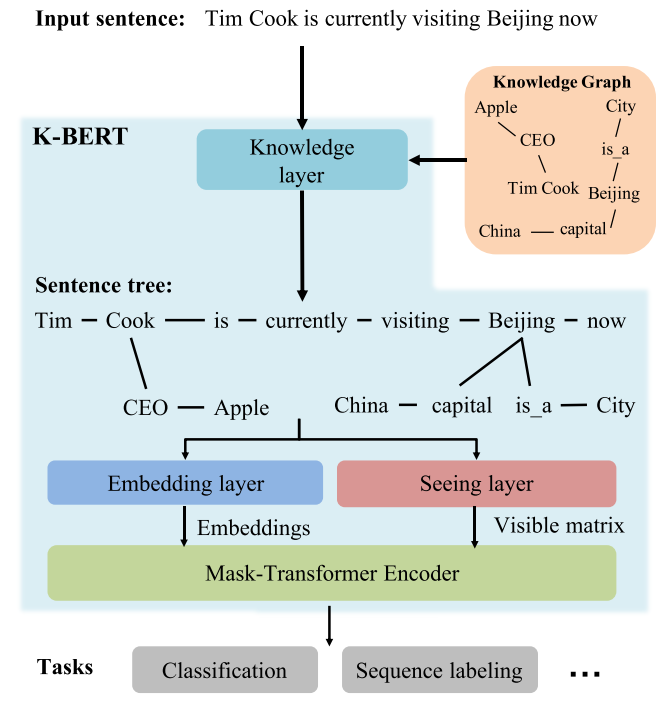
特别地,在模型的输入层,K-BERT表征层通过位置索引将语句树转换为句子,构造三种表征方式:Token表征、Soft-position表征和Segment表征。其中Soft-position表征作为位置嵌入,为重排的序列提供句子结构信息。此外,通过Visible Matrix来覆盖不应该看到的Token,避免了知识噪声问题。如下图所示,以Beijing为例,给定知识三元组(Beijing,capital,China),K-BERT通过Visible Matrix限制只有Beijing能“看到”其相关的关系词和宾语,分别为“capital”和“China”。与之相反,一个知识无关的词now则无法“看到”“capital”和“China”。
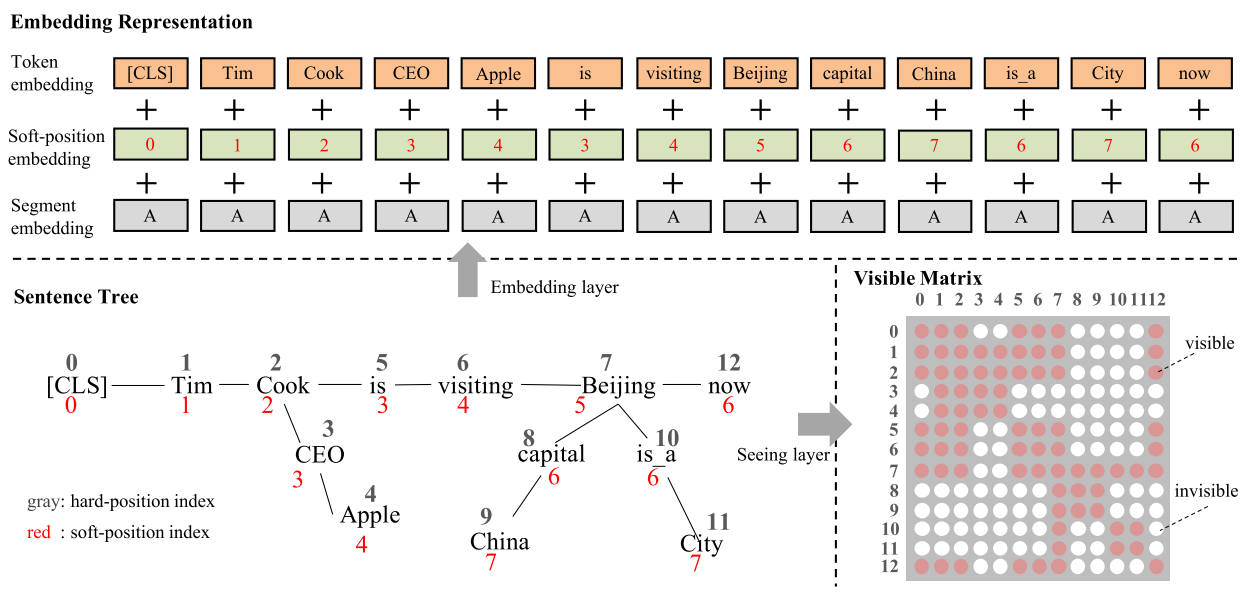
从作者论文中我们也可以看到K-BERT中的Attention Matrix的计算过程:
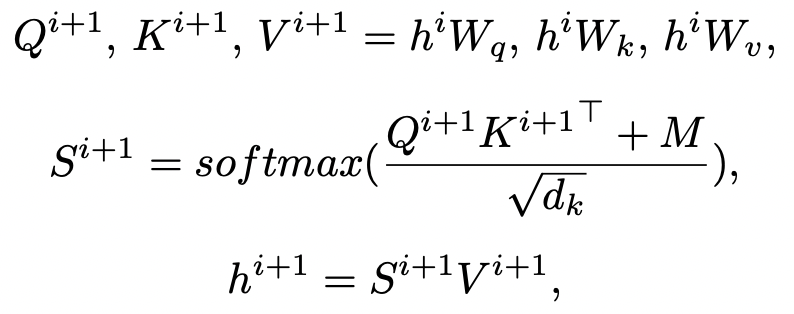
其中,M即为Visible Matrix,为了表示K-BERT输入Token序列能否互相“看见”,定义M如下:
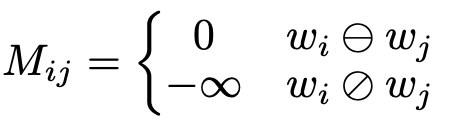
因此,当两个Token互相可以“看见”,M矩阵对应的元素值为0,因此Attention Matrix的计算过程和普通BERT相同。反之,当两个Token不能互相“看见”,M矩阵对应的元素值为负无穷,对应SoftMax函数后的权重则会趋于0,这使得这两个Token在Self-Attention计算过程中互无影响。这就在计算过程中,大大缓解了知识图谱增强过程的知识噪声问题。
K-BERT模型的实现与效果
在EasyNLP框架中,我们在模型层构建了K-BERT模型的Backbone,其核⼼代码如下所示:
self.kbert = KBertModel(config, add_pooling_layer=False)
self.cls = KBertOnlyMLMHead(config) outputs = self.kbert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
) sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
其中,在K-BERT中,模型Backbone的Attention Mask由两个Matrix加和而成,分别为普通的Attention Mask和Visible Matrix,实现核心代码如下:
extended_attention_mask = self.get_extended_attention_mask(attention_mask, input_shape, device) + self.get_extended_attention_mask(visible_matrix, input_shape, device)
在数据预处理过程中,我们需要获得当前样本的输入文本和知识三元组,从而计算出Visible Matrix:
if self.kbert_model_prefix:
encoding['input_ids'], encoding['token_type_ids'], encoding['attention_mask'], encoding['position_ids'], encoding['visible_matrix'] = self.kbert_row_data_process(encoding['input_ids'], encoding['token_type_ids'], encoding['attention_mask'])
为了验证EasyNLP框架中K-BERT模型在各种任务上的精度,我们在多个公开数据集上验证了句子分类和NER任务的效果。我们使用EasyNLP加载了BERT模型,对比复现结果和K-BERT官方论文的结果,如下所示:
|
数据集 |
Dev复现结果 |
Dev论文结果 |
Test复现结果 |
Test论文结果 |
|
Book_review |
88.5 |
88.6 |
87.06 |
87.2 |
|
Chnsenticorp |
94.3 |
94.6 |
95.08 |
95.6 |
|
MSRA-NER |
94.56 |
94.5 |
94.46 |
94.5 |
可以通过上述结果,验证EasyNLP框架中K-BERT算法实现的正确性。
K-BERT模型使⽤教程
以下我们简要介绍如何在EasyNLP框架使⽤K-BERT模型。
安装EasyNLP
⽤户可以直接参考GitHub(https://github.com/alibaba/EasyNLP)上的说明安装EasyNLP算法框架。
数据准备
K-BERT是一个finetune模型,需要用户准备下游任务的训练与验证数据,为tsv文件。对于文本分类任务,这⼀⽂件包含以制表符\t分隔的三列,第一列是标签,第二列是句子序号,第三列是文本句子。样例如下:
0 25 作者肯定是手头有一本年表和名册的,人物事件行动完全扣合正史,人物性格也多有《百家讲坛》为证,人物年龄的bug比红楼梦还少,叙述事件某某年某某月某某伐某某不厌其烦,可是切合历史绝不是说它是好小说的理由啊!我觉得玛丽苏都不是致命伤,关键是情节幼稚看不下去啊!
对于NER任务,同样为一个tsv文件,由\t分隔为文本和label两列,文本字与字之间用空格隔开。样例如下:
猎 豹 移 动 方 面 解 释 称 , 移 动 收 入 和 海 外 收 入 的 增 长 主 要 得 益 于 L i v e . m e 产 品 在 海 外 市 场 的 快 速 增 长 。 B-ORG I-ORG I-ORG I-ORG O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O O
下列⽂件已经完成预处理,可⽤于测试:
https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/K-BERT/kbert_data.zip
K-BERT⽂本分类示例
在文本分类任务中,我们采⽤以下命令对K-BERT模型进⾏finetune,模型在finetune过程中也会自动输出评估结果。其中,用户可以在前述预处理示例文件中找到训练集chnsenticorp/train.tsv、评测集chnsenticorp/dev.tsv以及知识图谱文件kbert_kgs/HowNet.spo。kbert_cls.py位于EasyNLP项目下的examples/kbert/下。相关示例代码如下:
python kbert_cls.py \
--mode train \
--tables tmp/kbert_data/chnsenticorp/train.tsv,tmp/kbert_data/chnsenticorp/dev.tsv \
--input_schema label:str:1,sid1:str:1,sent1:str:1 \
--first_sequence sent1 \
--label_name label\
--label_enumerate_values 0,1 \
--checkpoint_dir ./tmp/kbert_classification_model/ \
--learning_rate 2e-5 \
--epoch_num 2 \
--random_seed 42 \
--save_checkpoint_steps 50 \
--sequence_length 128 \
--micro_batch_size 16 \
--app_name text_classify \
--user_defined_parameters "pretrain_model_name_or_path=kbert-base-chinese kg_file=tmp/kbert_data/kbert_kgs/HowNet.spo"
K-BERT命名实体识别示例
在NER任务中,我们采⽤以下命令对K-BERT模型进⾏finetune,其使用方式与文本分类相同:
python kbert_ner.py \
--mode train \
--tables tmp/kbert_data/financial_ner/train.tsv,tmp/kbert_data/financial_ner/dev.tsv \
--input_schema content:str:1,label:str:1 \
--first_sequence content \
--label_name label\
--label_enumerate_values B-ORG,B-PER,B-POS,I-ORG,I-PER,I-POS,O \
--checkpoint_dir ./tmp/kbert_ner_model/ \
--learning_rate 2e-5 \
--epoch_num 2 \
--random_seed 42 \
--save_checkpoint_steps 50 \
--sequence_length 128 \
--micro_batch_size 16 \
--app_name sequence_labeling \
--user_defined_parameters "pretrain_model_name_or_path=kbert-base-chinese kg_file=tmp/kbert_data/kbert_kgs/HowNet.spo"
未来展望
在未来,我们计划在EasyNLP框架中集成更多中⽂知识模型,覆盖各个常⻅中⽂领域,敬请期待。我们 也将在EasyNLP框架中集成更多SOTA模型(特别是中⽂模型),来⽀持各种NLP和多模态任务。此外, 阿⾥云机器学习PAI团队也在持续推进中⽂多模态模型的⾃研⼯作,欢迎⽤户持续关注我们,也欢迎加⼊ 我们的开源社区,共建中⽂NLP和多模态算法库!
Github地址:https://github.com/alibaba/EasyNLP
Reference
- Chengyu Wang, Minghui Qiu, Taolin Zhang, Tingting Liu, Lei Li, Jianing Wang, Ming Wang, Jun Huang, Wei Lin. EasyNLP: A Comprehensive and Easy-to-use Toolkit for Natural Language Processing. arXiv
- Weijie Liu, Peng Zhou, Zhe Zhao, Zhiruo Wang, Qi Ju, Haotang Deng, and Ping Wang. 2020. K-BERT: Enabling Language Representation with Knowledge Graph. In AAAI. 2901–2908
- K-BERT原作者开源代码:https://github.com/autoliuweijie/K-BERT
阿里灵杰回顾
- 阿里灵杰:阿里云机器学习PAI开源中文NLP算法框架EasyNLP,助力NLP大模型落地
- 阿里灵杰:预训练知识度量比赛夺冠!阿里云PAI发布知识预训练工具
- 阿里灵杰:EasyNLP带你玩转CLIP图文检索
- 阿里灵杰:EasyNLP中文文图生成模型带你秒变艺术家
原文链接:https://click.aliyun.com/m/1000353809/
本文为阿里云原创内容,未经允许不得转载。
EasyNLP集成K-BERT算法,借助知识图谱实现更优Finetune的更多相关文章
- 1. 通俗易懂解释知识图谱(Knowledge Graph)
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 从一开始的Google搜索,到现在的聊天机器人.大数据风控 ...
- 百度大脑UNIT3.0详解之知识图谱与对话
如今,越来越多的企业想要在电商客服.法律顾问等领域做一套包含行业知识的智能对话系统,而行业或领域知识的积累.构建.抽取等工作对于企业来说是个不小的难题,百度大脑UNIT3.0推出「我的知识」版块专门为 ...
- 知识图谱如何运用于RecomSys
将知识图谱作为辅助信息引入到推荐系统中可以有效地解决传统推荐系统存在的稀疏性和冷启动问题,近几年有很多研究人员在做相关的工作.目前,将知识图谱特征学习应用到推荐系统中主要通过三种方式——依次学习.联合 ...
- ISWC 2018概览:知识图谱与机器学习
语义网的愿景活跃且良好,广泛应用于行业 语义网的愿景是「对计算机有意义」的数据网络(正如 Tim Berners Lee.James Hendler 和 Ora Lassila 在<科学美国人& ...
- 知识图谱+Recorder︱中文知识图谱API与工具、科研机构与算法框架
目录 分为两个部分,笔者看到的知识图谱在商业领域的应用,外加看到的一些算法框架与研究机构. 文章目录 @ 一.知识图谱商业应用 01 唯品金融大数据 02 PlantData知识图谱数据智能平台 03 ...
- 知识图谱与Bert结合
论文题目: ERNIE: Enhanced Language Representation with Informative Entities(THU/ACL2019) 本文的工作也是属于对BERT锦 ...
- ERNIE:知识图谱结合BERT才是「有文化」的语言模型
自然语言表征模型最近受到非常多的关注,很多研究者将其视为 NLP 最重要的研究方向之一.例如在大规模语料库上预训练的 BERT,它可以从纯文本中很好地捕捉丰富的语义模式,经过微调后可以持续改善不同 N ...
- 知识图谱顶刊综述 - (2021年4月) A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
知识图谱综述(2021.4) 论文地址:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications 目录 知 ...
- Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation(知识图谱)
知识图谱(Knowledge Graph,KG)可以理解成一个知识库,用来存储实体与实体之间的关系.知识图谱可以为机器学习算法提供更多的信息,帮助模型更好地完成任务. 在推荐算法中融入电影的知识图谱, ...
- 哈工大知识图谱(Knowledge Graph)课程概述
一.什么是知识图谱 知识(Knowledge)可以理解为 精炼的数据,知识图谱(Knowledge Graph)即是对知识的图形化表示,本质上是一种大规模语义网络 (semantic network) ...
随机推荐
- 世界银行使用.NET 7开发的免费电子问卷制作系统Survey Solution
Survey Solution (下文简称SS) 是世界银行数据部开发的一套免费电子问卷制作系统, 官网地址为: https://mysurvey.solutions/, github地址:https ...
- 基于ADS1292芯片的解决方案之芯片简析
基本资料: ADS1292芯片是多通道同步采样 24 位 Δ-Σ 模数转换器 (ADC),它们具有内置的可编程增益放大器 (PGA).内部基准和板载振荡器. ADS1292 包含 便携式 低功耗医疗心 ...
- In-batch negatives Embedding模型介绍与实践
语义索引(可通俗理解为向量索引)技术是搜索引擎.推荐系统.广告系统在召回阶段的核心技术之一.语义索引模型的目标是:给定输入文本,模型可以从海量候选召回库中快速.准确地召回一批语义相关文本.语义索引模型 ...
- 浅谈React与SolidJS对于JSX的应用
React将JSX这一概念深入人心.但,并非只有React利用了JSX,VUE.SolidJS等JS库或者框架都使用了JSX这一概念.网上已经有大量关于JSX的概念与形式的讲述文章,不在本文的讨论范围 ...
- 02.Android之IPC机制问题
目录介绍 2.0.0.1 什么是Binder?为什么要使用Binder?Binder中是如何进行线程管理的?总结binder讲的是什么? 2.0.0.2 Android中进程和线程的关系?什么是IPC ...
- Spring Cloud Alibaba服务的注册与发现之Nacos部署
1.Nacos官网介绍 Nacos 致力于帮助您发现.配置和管理微服务.Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现.服务配置.服务元数据及流量管理.Nacos 帮助您更敏捷和容 ...
- 前端ajax调用后端下载Excel模板流,解决输出乱码等问题
JavaScript方法function importTemplate() { $.ajax({ url: "/importTemplate", type: "get&q ...
- 2 URLEncode和Base64
1. URLEncode和Base64 在我们访问一个url的时候总能看到这样的一种url https://www.sogou.com/web?query=%E5%90%83%E9%A5%AD%E7% ...
- #斯坦纳树#洛谷 4294 [WC2008]游览计划
题目 分析 几乎就是模板题,考虑不同点就是它是点权, 所以在求两个子集的时候要减去这个点的点权, 还有一点恶心的就是要输出方案,令人作呕 代码 #include <cstdio> #inc ...
- Qt 实现涂鸦板二:实现放大功能
在一的基础上改造: .h 文件 #pragma once #include <QtWidgets/QWidget> #include "ui_xuexi.h" #inc ...