华为云GaussDB(for Influx)揭秘第五期:最佳实践之子查询
摘要: GaussDB(for influx)提供灵活的子查询能力,满足海量数据场景下的高性能查询需求。
本文分享自华为云社区《华为云GaussDB(for Influx)揭秘第五期:最佳实践之子查询》,作者: GaussDB 数据库 。
"告警了!告警了!"。
"什么告警了?"正在睡梦中迷糊的小王突然被运维同事的一个电话叫醒,顿时一脸惊愕。
"慢查询!客户报障了!赶紧起来处理啊!"
小王赶紧打开便携,远程连上环境查找问题所在,最终发现该慢查询是一条子查询。"不对啊,相同语句昨天还没报慢查询啊?"
不过小王很快得出了原因。这条慢查询的问题在于:子查询的内部查询本来可以将数据汇聚后再输出到外部查询,但由于没有做汇聚,因此当数据量大的时候,就会很慢!
找到症结所在,小王立马将优化后的sql语句通过运维同事转给客户,该告警终于得以解决。
"看来得好好整理下子查询了!",趁着思路清晰,小王开始整理了起来......
01 什么是子查询?
子查询是嵌套在另一个查询中的查询,在InfluxQL语法中一般放在from语句中,以增强代码的灵活性。子查询主要有以下几大分类:
- 标量子查询(scalarsubquery):返回1行1列一个值
- 行子查询(rowsubquery):返回的结果集是 1 行 N 列
- 列子查询(columnsubquery):返回的结果集是 N 行 1列
- 表子查询(tablesubquery):返回的结果集是 N 行 N 列
例如在查询语句:
select first(sum_f1)/first(sum_f2) from (select sum(f1) as sum_f1 from mst), (select sum(f2) as sum_f2 from mst)
使用了两个子查询,分别是从表mst中求得f1和f2两列之和,并将结果sum_f1和sum_f2作为外部查询的源,供外层查询语句使用。
GaussDB(for Influx)子查询的一般语法为SELECT_clause FROM (SELECT_statement ) [...]。在处理子查询时的逻辑如下图所示。
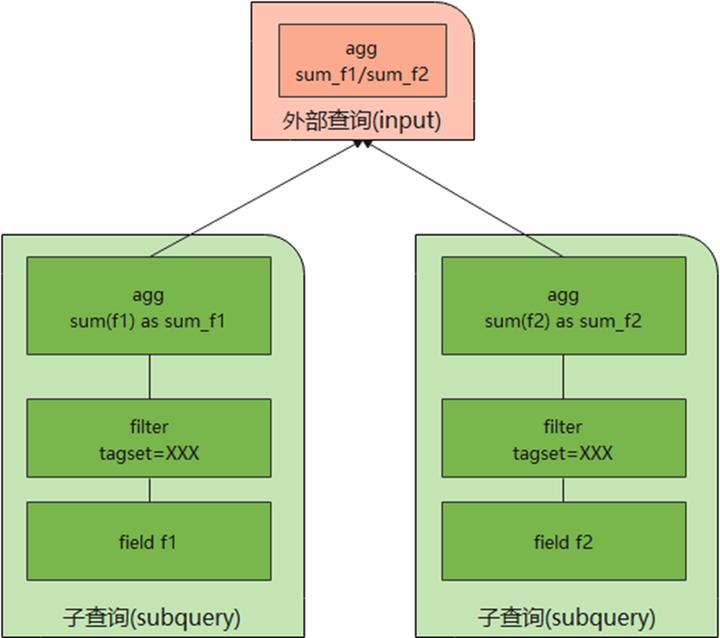
系统会首先处理子查询语句,子查询的结果被缓存起来,作为外查询的数据源,最终由外层查询处理完成后将结果返回给客户。
02 子查询的使用场景
子查询用在一次简单查询无法处理的情况下,或者是基于一个查询的数据做进一步的处理,比如想找出每个分组的最小值中最大的三个:
SELECT top (v,3)
FROM (
SELECT min (value) AS v
FROM mst
GROUP BY tag1
)
子查询为我们带来了很大的灵活性,但是原则上不推荐使用子查询。原因很简单,相比于普通的查询来说,子查询有更深的函数调用和更大的数据量,消耗的资源和时延都会增加。
03 案例剖析
我们在使用GaussDB(for Influx)开发的过程中,常常会面临一些子查询方面的困扰,例如:
1. 什么时候使用子查询?
2. 面对一个复杂场景,如何分解成为子查询来解决?
3. 写好的子查询是最优的么?可不可以再优化?
接下来我们结合一个具体案例来简单分析下如何高效的使用子查询和分析思路。
华为云某用户使用GaussDB(for Influx),每天写入约5.4亿个点,时间线100w+,业务中有时空查询,请求成功率查询,topN查询。
以下面脱敏数据作为sample数据做案例分析和实践:
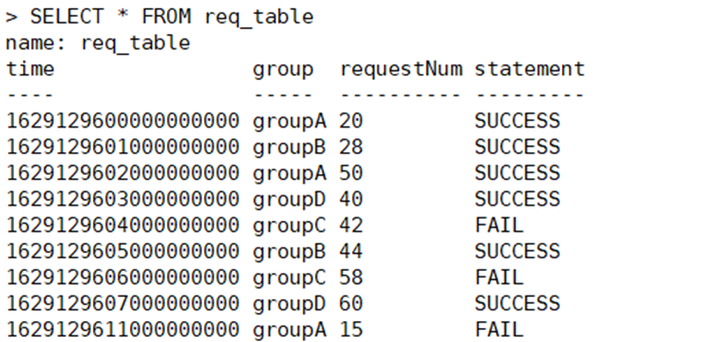
案例1 什么时候使用子查询?
用户使用了子查询做时空分组并且作为外查询的源,外查询将时空分组的结果做聚合。查询语句为:
SELECT SUM(req_nums)
FROM(
SELECT requestNum AS req_nums
FROM req_table
WHERE statement=’SUCCESS’ AND time >= 1629129600000000000
AND time<=1629129611000000000 )
WHERE time>=1629129600000000000 AND time<=1629129611000000000
AND req_nums < 50
GROUP BY time(1s), group
ORDER BY time ASC
产生的问题:
用户的使用场景下,可以发现该查询子查询内部仅仅实现了条件过滤和列名更改,因此内部查询等同于SELECT requestNum AS req_nums + 过滤, 非聚合场景的查询由于需要捞出大量原始数据导致查询速度较慢,因此该查询效率达不到用户的要求。
解决思路:
通过分析查询语句可知,用户的需求是将符合条件(statement=’SUCCESS’ AND requestNum < 50)的数据做一个时空聚合(GROUPBY TAG, time(5m)),明确了查询目标之后能写出更加清晰高效的查询语句:将所有的过滤条件放在一起,直接做时空聚合。
语法改进:
SELECT SUM(requestNum)
FORM req_table
WHERE statement=’SUCCESS’ AND requestNum < 50
AND time>=1629129600000000000 AND time<=1629129611000000000
GROUP BY time(1s), group
ORDER BY time ASC
案例2 使用子查询解决复杂问题
用户的业务场景中需要计算请求成功率,即按照不同的过滤条件对某一列数据进行筛选和计数,最后求出比例。GaussDB(for Influx)不支持case when语句,因此如何根据不同case过滤出同一列的不同数据是一个难点。很多开发者碰到这样的问题时,便没了思路。
解决思路:
第一步:利用子查询+多表特性,根据过滤条件将同一列数据变为两列:
SELECT * FROM
(SELECT requestNum AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT requestNum AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
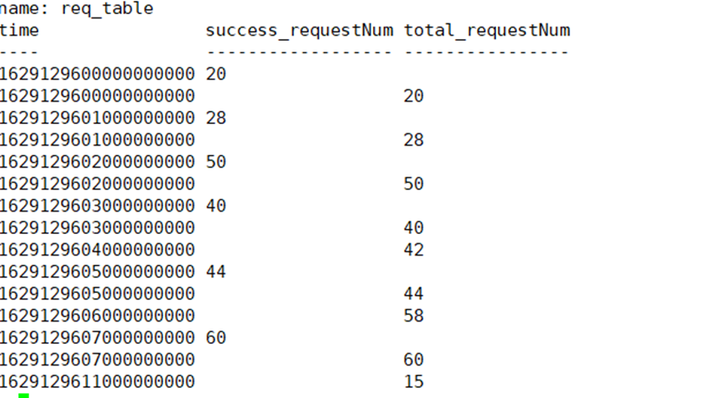
第二步:对查询出来的数据进行计数:
SELECT SUM(success_requestNum) AS total_success_reqNum, SUM(total_requestNum) AS total_requestNum
FROM
(SELECT requestNum AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT requestNum AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
GROUP BY time ASC

第三步:写出最终求成功率的查询语句:
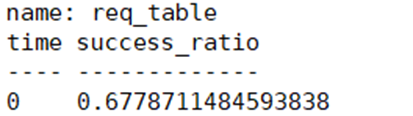
SELECT SUM(success_requestNum)/SUM(total_requestNum) AS success_ratio
FROM
(SELECT requestNum AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT requestNum AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
GROUP BY time ASC
案例3 如何优化子查询语句?
基于案例2,我们得到了求成功率的方法,查询语句如下:
SELECT SUM(success_requestNum)/SUM(total_requestNum) AS success_ratio
FROM
(SELECT requestNum AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT requestNum AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
GROUP BY time ASC
产生的问题:
用户所写查询语句查询时长高于120s不满足业务需求,需要进一步优化。
语法改进:
根据前面所述的子查询原则和解决方法,应当把聚合查询放到子查询内部来减少数据量加快查询速度,优化后的查询语句如下:
SELECT SUM(success_requestNum)/SUM(total_requestNum) AS success_ratio
FROM
(SELECT SUM(requestNum) AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT SUM(requestNum) AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
GROUP BY time ASC
查询结果一致:
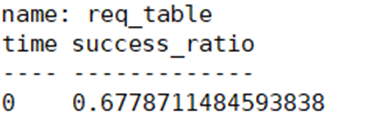
优化效果:
未优化查询耗时126s,优化后查询耗时2.7s,性能提升47倍。
注意
使用SUM(success_requestNum),SUM(total_requestNum)的目的是为了让数据对齐。直接使用SELECTsuccess_requestNum / total_requestNum,会因为相同时间数据无法对齐而出现结果不正确的情况:
SELECT *
FROM
(SELECT SUM(requestNum) AS success_requestNum FROM req_table WHERE statement=’SUCCESS’ AND time>=1629129600000000000 AND time<=1629129611000000000),
(SELECT SUM(requestNum) AS total_requestNum FROM req_table WHERE time>=1629129600000000000 AND time<=1629129611000000000)
GROUP BY time ASC

查询的总数据量与查询速度正相关,越大的数据查询量意味着越慢的查询速度,因此无论是书写子查询还是非子查询的查询语句,第一原则是尽量在查询中减少数据量,也就意味着聚合查询(典型减少数据量的查询)应当尽可能放到子查询内部。
04 灵活的子查询和高性能
GaussDB(for Influx)不但提供灵活的子查询能力,同时还使用了向量化、内存复用等技术不断提升查询的效率,满足了用户海量数据场景下的查询性能需求。
向量化查询:GaussDB(for Influx) 使用了SIMD指令集,提高数据处理的并行化程度。与此同时,采用向量化数据模型,一次迭代可以处理一批次的点,极大减少了计算迭代次数,加快了计算速度。
内存复用:在查询过程中尽可能减少GC对内存的回收和分配,申请的内存单独管理,解决了查询过程中内存膨胀导致GC频繁降低查询速度的问题。
05 总结
GaussDB(for Influx)支持子查询功能给我们处理问题带来了很大的灵活性,同时对使用者也有很高的要求,不合理的子查询往往会导致查询时延高,资源消耗大等问题,因此在使用GaussDB(for Influx)子查询时应该注意以下几点:
1. 理解子查询适用的业务逻辑,子查询适用于对查询出来的数据做二次(多次)处理的场景;
2. 能不使用子查询的场景下尽量避免使用子查询;
3. 必须使用子查询的场景尽量将减少数据量的查询放到子查询内部以减少整体的查询数据量从而加快查询速度。
06 结束
本文作者:华为云数据库创新Lab & 华为云时空数据库团队
欢迎加入我们!
云数据库创新Lab(成都、北京)简历投递邮箱:xiangyu9@huawei.com
华为云时空数据库团队(西安、深圳)简历投递邮箱:yujiandong@huawei.com
华为云GaussDB(for Influx)揭秘第五期:最佳实践之子查询的更多相关文章
- 揭秘华为云GaussDB(for Influx)最佳实践:hint查询
摘要:GaussDB(for Influx)通过提供hint功能,在单时间线的查询场景下,性能有大幅度的提升,能有效满足客户某些特定场景的查询需求. 本文分享自华为云社区<华为云GaussDB( ...
- 揭秘华为云GaussDB(for Influx):数据直方图
摘要:本文带您了解直方图在不同产品中的实现,以及GaussDB(for Influx)中直方图的使用方法. 本文分享自华为云社区<华为云GaussDB(for Influx)揭秘第九期:最佳实践 ...
- 华为云PB级数据库GaussDB(for Redis)揭秘第八期:用高斯 Redis 进行计数
摘要:高斯Redis,计数的最佳选择! 一.背景 当我们打开手机刷微博时,就要开始和各种各样的计数器打交道了.我们注册一个帐号后,微博就会给我们记录一组数据:关注数.粉丝数.动态数-:我们刷帖时,关注 ...
- 华为云PB级数据库GaussDB(for Redis)揭秘第七期:高斯Redis与强一致
摘要:在KV数据库领域,"强一致性"不仅是一个技术名词,它更是业务与运维的重要需求. 清明刚过,五一假期就要来了.大好春光,不如去婺源看油菜花吧!小云迅速打开APP刷出余票2张,赶 ...
- 升级的华为云“GaussDB”还能战否?
摘要:芯片.操作系统.数据库是现代信息技术领域的三大核心基础,做数据库,不仅需要技术和投入,对华为这种做通讯起家的企业,更需要的是一种并非玩票性质的态度. GaussDB,不仅蕴含着华为对数学和科学的 ...
- 华为云GaussDB(DWS)内存知识点,你知道吗?
前言 在日常数据库的使用中,难免会遇到一些内存问题.此次博文主要向大家分享一些华为云数仓GaussDB(DWS)内存的基本框架以及基本视图的使用,以便遇到内存问题后可以有一个基本的判断. 注意,本篇博 ...
- 华为云 MRS 基于 Apache Hudi 极致查询优化的探索实践
背景 湖仓一体(LakeHouse)是一种新的开放式架构,它结合了数据湖和数据仓库的最佳元素,是当下大数据领域的重要发展方向. 华为云早在2020年就开始着手相关技术的预研,并落地在华为云 Fusio ...
- TOP100summit:【分享实录-华为】微服务场景下的性能提升最佳实践
本篇文章内容来自2016年TOP100summit华为架构部资深架构师王启军的案例分享.编辑:Cynthia 王启军:华为架构部资深架构师.负责华为的云化.微服务架构推进落地,前后参与了华为手机祥云4 ...
- 阿里云RDS for SQL Server使用的一些最佳实践
了解RDS的概念 这也是第一条,也是最重要的一条,在使用某项产品和服务之前,首先要了解该产品或服务的功能与限制,就像你买一个冰箱或洗衣机,通常也只有在阅读完说明书之后才能利用起来它们的所以功能,以及使 ...
- 轻量ORM-SqlRepoEx (十五)最佳实践之数据映射(Map)
简介:SqlRepoEx是 .Net平台下兼容.NET Standard 2.0人一个轻型的ORM.解决了Lambda转Sql语句这一难题,SqlRepoEx使用的是Lambda表达式,所以,对c#程 ...
随机推荐
- 调和级数发散率证明|欧拉常数|ln n+gamma+varepsilon_k证明|sigma(1/i)
最近在做一个 练习 ,然后看到了 调和级数 这个东西,说实话这东西谁能在考场上想到,平日还是要多积累. 开门见山 但是我们今天只证这个东西: \[\sum^{n}_{i = 1} \frac{1}{n ...
- Qt 迭代器
目录 (一) java风格迭代器 1. QListIterator类 1. 初始化 2. findNext() 3. findPrevious() 4. hasNext() 5. hasPreviou ...
- Redis常用命令-实战篇
目录 写在前面 连接操作命令 持久化 远程服务控制 对value操作的命令 操作字符串String命令 List Set Hash 写在前面 java 操作 redis 太常见了,基本上有需要的系统, ...
- AirSim 自动驾驶仿真 (6) 设置采集参数和属性
https://cloud.tencent.com/developer/article/2011384 1.配置文件在哪 默认情况下,文件位于用户目录下的AirSim文件夹,比如在Windows下,文 ...
- SNN_STDP
STDP 是一种时间不对称的Hebbian学习形式,由突触前和突触后神经元的脉冲时间的时间相关性引起的.是一种双向Hebbian学习法则. 突触权重变化\(\Delta w\)依赖于突触前脉冲的到达和 ...
- CDQZ DS 题单总结(上)
Preview: 个人认为是一套非常好的题单,能在各个方面练习 DS 水平,并且很多题型也是比赛当中的经典题 题单链接 Challenge 0: 简单的数组,懒得写了. Challenge 1: 考虑 ...
- Welcome to YARP - 5.压缩、缓存
目录 Welcome to YARP - 1.认识YARP并搭建反向代理服务 Welcome to YARP - 2.配置功能 2.1 - 配置文件(Configuration Files) 2.2 ...
- Java 删除PDF页面 (免费工具分享)
对PDF页面的增删通常需要借助专门的工具,而这些工具一般需要付费才能使用.那么我们可以通过Java代码免费实现这一功能吗?答案是肯定的.这篇文章就教大家如何使用一个免费的国产Java库来删除PDF中的 ...
- 4G打猎摄像机拆机分析
前言 收到一台4G打猎相机,官方外观及功能图片如下所示,现对该设备进行拆机及整体技术分析评估,看我们可以从中学习到什么. (一)什么是打猎相机 所谓打猎相机,也叫野外相机,专门用于野外观察和监测野生动 ...
- iNeuOS工业互联网操作系统,高效采集数据配置与应用
1. 概述 2. 通讯原理 3. 参数配置 1. 概述 某生产企业世界500强的集团能源管控平台项目建设,通过专线网络实现异地厂区数据集成,每个终端能源仪表都有IP地址,总共有1000多台能源表 ...