如何运维多集群数据库?58 同城 NebulaGraph Database 运维实践
图计算业务背景介绍
我们为什么选择 NebulaGraph?
在公司各个业务线中,有不少部门都有着关系分析等图探索场景,随着业务发展,相关的需求越来越多。大量需求使用多模数据库来实现,开发成本和管理成本相对较高。
随着图数据库的发展,相关系统应用越来越成熟,于是引入专业图数据库来满足这部分业务需求的事务也提上日程。接下来要考虑的问题就是图数据库选型了。
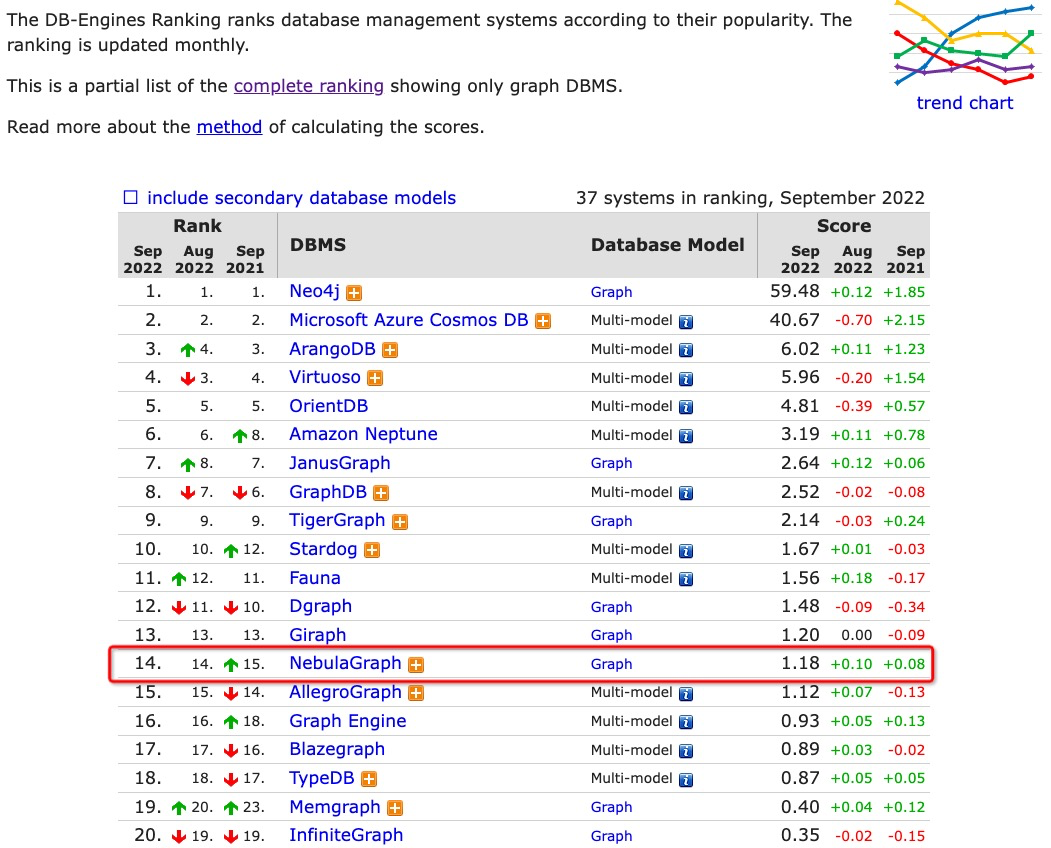
首先,NebulaGraph 有大量互联网大厂应用案例,说明 NebulaGraph 可以应对海量数据的图探索场景。另外,目前 NebulaGraph 在 DB-Engines 在图数据库领域排名 14,而且增长势头强劲。排名靠前的图数据库,部分不开源或者单机版开源,场景受限。
NebulaGraph 实际测试表现如何
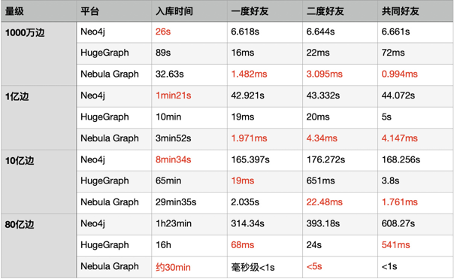
在导入性能上,数据量小的时候 NebulaGraph 的导入效率稍慢于 neo4j,但在大数据量的时候 NebulaGraph 的导入明显优于其他两款图数据库。在 3 种查询场景下,NebulaGraph 的效率都明显高于 neo4j,与 HugeGraph 相比也有一定的优势。
适用场景有哪些
公司有多种线上业务,工程复杂度和架构复杂度都较高,各个业务部门都需要专门的图数据库来实现对实体关系数据的处理和探索。
通过图数据库实现对任务依赖的运行时间进行监控,及时获取延迟任务、销售激励平台任务血缘关系处理、分析应用内部的类/方法级调用关系、业务风险数据分析、记录企业高管、法人、股东关系,用于签单业务等场景。
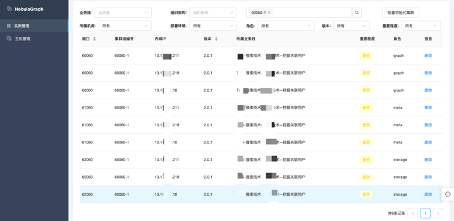
资源申请和集群管理方式
为了更好的管理和维护,图数据库在运维部门集中运维管理。用户按需在工单平台中提交申请即可,工单中填写详细的资源需求数据和性能需求指标,由运维同学统一审核交付集群资源。
公司目前服务器环境是自建机房,采用高配物理机,单机多实例混部数据库服务。为了实现规模化管理和维护,需要提前制定好实例标准和规则。
集群规模
得益于 NebulaGraph 良好的图计算能力,我们已经持续交付集群接近 20 套,目前还有业务部门在持续申请相关集群服务资源。
NebulaGraph 规范和架构设计
由于需要满足大量业务需求,未来会有大量的集群需要交付和维护。为了高效管理和运维规模化的集群,需要提前规划和制定规范。
版本规范
目前使用版本为 2.0.1
路径规范
- 程序路径为
/opt/soft/nebula201,该路径下有 bin、scripts、share 等,作为公共的服务依赖路径,从服务路径中抽离出来
同样,升级为 3.X 版本,只需要将程序路径抽离出来作为公共的服务依赖路径即可。
- 服务路径为
/work/nebulagraph+graph 端口,该路径下有 data、etc、logs、pids
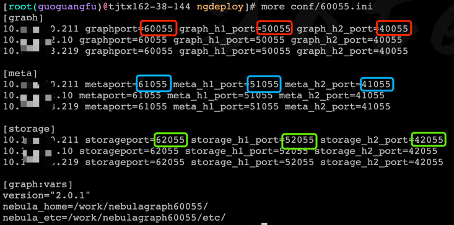
端口规范
- 集群之间端口递增 5,因为 storage 副本需要端口通信,通常是 storage 端口 -1,例如两套集群 graph 端口分别是 60000 和 60005;
- 每种服务端口和 http、http2 端口之间步长为 10000,例如 graph 端口是 60000,ws_http_port 就是 50000,ws_h2_port 就是 40000;
- 三种服务端口之间相差 1000,例如 graph 端口是 60000,meta 端口就是 61000,storage 端口就是 62000;
- 60000 graph 端口;50000 ws_http_port;40000 ws_h2_port
- 61000 meta 端口;51000 ws_http_port;41000 ws_h2_port
- 62000 storage 端口;52000 ws_http_port;42000 ws_h2_port
运维规范
第一,创建 space 需用 ngdb_ 左前缀,分片默认是节点数的 2 倍,副本数默认为 2,参考 CREATE SPACE ngdb_demo (partition_num=6,replica_factor=2,charset=utf8,collate=utf8_bin,vid_type=FIXED_STRING(128),atomic_edge=false) ON default;
第二,授予业务账号 DBA 角色:GRANT ROLE DBA ON ngdb_demo TO demo_wr;
第三,搭建一套 NebulaGraph 集群后,将内置账号 root 的密码重置,之后将 /work/nebulagraph+graph 端口 路径打包生成 rpm,作为标准安装包
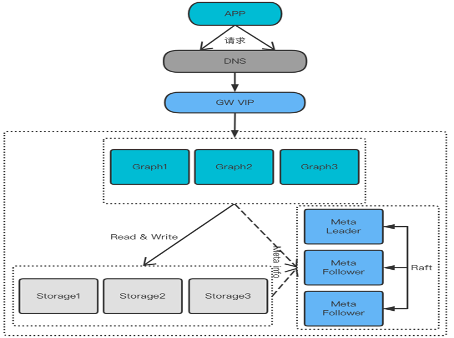
服务请求直接通过 DNS 和网关服务到 Graph,方便计算和存储服务直接交互,由于是通过 DNS 访问,不对外暴露 Meta 节点信息,可以更灵活的运维,较少服务绑定 Meta 节点 ip 带来的运维代价。
这种架构限制了 Java 等驱动的访问,需要用其他驱动替代。
第四,基础集群套餐是 3 个 Graph 节点、3 个 Meta 节点、3 个 Storage 节点,在保证高可用的同时也能保证足够的处理能力。
基础集群分布在 3 台物理机上,存储和计算不需要过多的网络交互。
集群部署自动化实现
为了能够一键部署服务,集中式管理服务,我们需要借助远程管理工具 Ansible,能帮我们做到快速部署。依据三种角色服务的端口规范,生成 Ansible 的配置文件。
- 由于将版本信息写到了配置文件中,在兼容多版本场景下,只需要在
bootstrap.yml文件中增加相应判断即可,主程序兼容多版本成本非常有限。
部署实例时,根据 graph 角色分发文件,也可以每个节点单独分发文件。
- 依据三种角色,分别分发配置文件到目的路径下,并且按照文件命名规则生成最终配置文件。
more bootstrap.yml
- hosts: graph
become: yes
remote_user: root
tasks:
- name: init elasticsearch file on data
command: cp -r /opt/soft/nebulagraph201 {{ nebula_home }}
- hosts: graph
become: yes
remote_user: root
tasks:
- name: init config graphfile on master {{ version }}
template: src=/opt/soft/ngdeploy/conf/templates/201graph dest="{{ nebula_etc }}nggraphd.conf" owner=root group=root mode=0755
- hosts: meta
become: yes
remote_user: root
tasks:
- name: init config metafile on master {{ version }}
template: src=/opt/soft/ngdeploy/conf/templates/201meta dest="{{ nebula_etc }}ngmetad.conf" owner=root group=root mode=0755
- hosts: storage
become: yes
remote_user: root
tasks:
- name: init config storagefile on master {{ version }}
template: src=/opt/soft/ngdeploy/conf/templates/201storage dest="{{ nebula_etc }}ngstoraged.conf" owner=root group=root mode=0755
配置文件的分发最为关键,有较多变量需要处理,这些变量需要提前在 Ansible 的配置文件中定义,nebulagraphd 路径规范和服务端口需要使用 graphport、meta_server_addrs 需要用到 for 循环语法实现。
more templates/201graph
########## basics ##########
--daemonize=true
--pid_file=/work/nebulagraph{{ graphport }}/pids/nebula-graphd.pid
--enable_optimizer=true
########## logging ##########
--log_dir=/work/nebulagraph{{ graphport }}/logs
--minloglevel=0
--v=0
--logbufsecs=0
--redirect_stdout=true
--stdout_log_file=graphd-stdout.log
--stderr_log_file=graphd-stderr.log
--stderrthreshold=2
########## query ##########
--accept_partial_success=false
########## networking ##########
--meta_server_addrs={% for host in groups.graph%}{%if loop.last%}{{ hostvars[host].inventory_hostname }}:{{ hostvars[host].metaport }}{%else%}{{hostvars[host].inventory_hostname }}:{{hostvars[host].metaport}}
,{%endif%}{% endfor %}
--local_ip={{inventory_hostname}}
--listen_netdev=any
--port={{ graphport }}
--reuse_port=false
--listen_backlog=1024
--client_idle_timeout_secs=0
--session_idle_timeout_secs=0
--num_accept_threads=1
--num_netio_threads=0
--num_worker_threads=0
--ws_ip={{inventory_hostname}}
--ws_http_port={{ graph_h1_port }}
--ws_h2_port={{ graph_h2_port }}
--default_charset=utf8
--default_collate=utf8_bin
########## authorization ##########
--enable_authorize=true
########## Authentication ##########
--auth_type=password
同样,nebulametad 服务配置文件路径规范和服务端口需要使用 metahport、meta_server_addrs 需要用到 for 循环语法实现。
more templates/201meta
########## basics ##########
--daemonize=true
--pid_file=/work/nebulagraph{{graphport}}/pids/nebula-metad.pid
########## logging ##########
--log_dir=/work/nebulagraph{{graphport}}/logs
--minloglevel=0
--v=0
--logbufsecs=0
--redirect_stdout=true
--stdout_log_file=metad-stdout.log
--stderr_log_file=metad-stderr.log
--stderrthreshold=2
########## networking ##########
--meta_server_addrs={% for host in groups.graph%}{%if loop.last%}{{ hostvars[host].inventory_hostname }}:{{ hostvars[host].metaport }}{%else%}{{hostvars[host].inventory_hostname }}:{{hostvars[host].metaport}}
,{%endif%}{% endfor %}
--local_ip={{inventory_hostname}}
--port={{metaport}}
--ws_ip={{inventory_hostname}}
--ws_http_port={{meta_h1_port}}
--ws_h2_port={{meta_h2_port}}
########## storage ##########
--data_path=/work/nebulagraph{{graphport}}/data/meta
########## Misc #########
--default_parts_num=100
--default_replica_factor=1
--heartbeat_interval_secs=10
--timezone_name=CST-8
同样,nebulastoraged 服务配置文件路径规范和服务端口需要使用 storageport、meta_server_addrs 需要用到 for 循环语法实现。
more templates/201graph
########## basics ##########
--daemonize=true
--pid_file=/work/nebulagraph{{ graphport }}/pids/nebula-graphd.pid
--enable_optimizer=true
########## logging ##########
--log_dir=/work/nebulagraph{{ graphport }}/logs
--minloglevel=0
--v=0
--logbufsecs=0
--redirect_stdout=true
--stdout_log_file=graphd-stdout.log
--stderr_log_file=graphd-stderr.log
--stderrthreshold=2
########## query ##########
--accept_partial_success=false
########## networking ##########
--meta_server_addrs={% for host in groups.graph%}{%if loop.last%}{{ hostvars[host].inventory_hostname }}:{{ hostvars[host].metaport }}{%else%}{{hostvars[host].inventory_hostname }}:{{hostvars[host].metaport}}
,{%endif%}{% endfor %}
--local_ip={{inventory_hostname}}
--listen_netdev=any
--port={{ graphport }}
--reuse_port=false
--listen_backlog=1024
--client_idle_timeout_secs=0
--session_idle_timeout_secs=0
--num_accept_threads=1
--num_netio_threads=0
--num_worker_threads=0
--ws_ip={{inventory_hostname}}
--ws_http_port={{ graph_h1_port }}
--ws_h2_port={{ graph_h2_port }}
--default_charset=utf8
--default_collate=utf8_bin
########## authorization ##########
--enable_authorize=true
########## Authentication ##########
--auth_type=password
需要部署新集群时,需要按照规则和目的服务器信息生成 Ansible 的配置文件,然后调用 ansible-playbook,按照 bootstrap.yml 定义的行为执行即可。
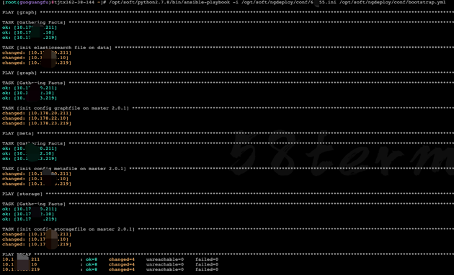
部署完毕之后,需要按照服务角色依次启动 start.yml 的脚本文件提前定义好三种服务的启动命令和配置文件。
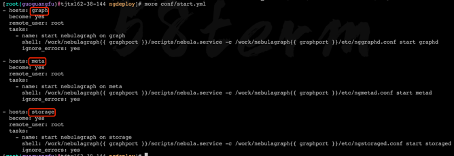
调用 ansible-playbook,根据 start.yml 的脚本文件依次执行三种服务的启动命令即可。

可视化图探索平台
有赖于将目标 host 前置于 Web 平台的设置,我们只需要对多个项目的开发提供一套公共的 Web 平台即可,减少了 NebulaGraph 集群的组件数量,有别于 ELK 的标准架构。
开发可以通过 NebulaGraph Studio 实现可视化管理数据,轻松实现数据导入和导出,便于用户探索数据关系。直接呈现出点边关系,使探索图数据之间的关系更为直观。
以上是我们在规模化管理维护 NebulaGraph 集群过程中的一些经验,希望对大家有些帮助。
交流图数据库技术?加入 NebulaGraph 交流群请先填写下你的 NebulaGraph 名片,NebulaGraph 小助手会拉你进群~~
NebulaGraph 的开源地址:https://github.com/vesoft-inc/nebula 如果你觉得使用体验还不错的话,给我们的 GitHub 点个 ️ 鼓励下开源路上的我们呢~
如何运维多集群数据库?58 同城 NebulaGraph Database 运维实践的更多相关文章
- RAC集群数据库连库代码示例(jdbc thin方式,非oci)
1.RAC集群数据库连库代码示例(jdbc thin方式,非oci):jdbc.driverClassName=oracle.jdbc.driver.OracleDriverjdbc.url=jdbc ...
- nbu还原集群数据库异常问题
集群数据库软件均已安装完毕,现在想从NBU上还原数据库,但在还原控制文件报错 [oracle@oracle-db1 ~]$ rman target / Recovery Manager: Releas ...
- es集群数据库~运维相关
一 数据同步方案 1 ES-JDBC 不能实现删除同步操作.MYSQL如果删除,ES不会删除 2 logstash-input-jdbc 能实现insert update,但是仍然不能实现删除 ...
- Docker集群管理工具 - Kubernetes 部署记录 (运维小结)
一. Kubernetes 介绍 Kubernetes是一个全新的基于容器技术的分布式架构领先方案, 它是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernete ...
- Nginx+PHP负载均衡集群环境中Session共享方案 - 运维笔记
在网站使用nginx+php做负载均衡情况下,同一个IP访问同一个页面会被分配到不同的服务器上,如果session不同步的话,就会出现很多问题,比如说最常见的登录状态. 下面罗列几种nginx负载均衡 ...
- Zookeeper集群的"脑裂"问题处理 - 运维总结
关于集群中的"脑裂"问题,之前已经在这里详细介绍过,下面重点说下Zookeeper脑裂问题的处理办法.ooKeeper是用来协调(同步)分布式进程的服务,提供了一个简单高性能的协调 ...
- 针对多类型数据库,集群数据库的有序GUID
一.背景 常见的一种数据库设计是使用连续的整数为做主键,当新的数据插入到数据库时,由数据库自动生成.但这种设计不一定适合所有场景. 随着越来越多的使用Nhibernate.EntityFramewor ...
- 11g RAC 集群数据库不能跟随集群启动
1.查看集群资源详细情况 [oracle@rac01-+ASM1 ~]$ crsctl stat res -p 2.修改集群资源ora.rac.db的auto_start属性改为always [ora ...
- es集群数据库~基本安装
1 安装java环境 yum -y install java-1.8.0-openjdk*->需要最新的JDK环境1.82 安装 es curl -L -O https://artifa ...
- 使用kubeoperator安装的k8s集群以及采用的containerd容器运行时,关于采用的是cgroup 驱动还是systemd 驱动的说明
使用kubeoperator安装的k8s集群,默认使用的是systemd驱动 # kubectl get cm -n kube-system NAME DATA AGE calico-config 4 ...
随机推荐
- 纯c#运行开源本地大模型Mixtral-8x7B
先看效果图,这是一个比较典型的逻辑推理问题,以下是本地运行的模型和openai gpt3.5的推理对比 本地运行Mixtral-8x7B大模型: chatgpt3.5的回答: 关于Mixtral 8x ...
- 玩一玩 golang 汇编(二)
作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢! cnblogs博客 zhihu Github 公众号:一本正经的瞎扯 上次玩 golang 汇编是使用了一个 python 的 ...
- [西湖论剑 2022]web部分题解(更新中ing
[西湖论剑 2022]Node Magical Login 环境!启动!(ノへ ̄.) 这么一看好像弱口令啊,(不过西湖论剑题目怎么会这么简单,当时真的傻),那就bp抓包试一下(这里就不展示了,因为是展 ...
- rider代码折叠
可折叠元素块 rider那些元素块是可折叠?参考官方文档:Fold Code Elements Code folding works for the keywords if/ while/ else/ ...
- 手撕Vuex-实现共享数据
经过上一篇章介绍,完成了添加全局 $store,接下来就是实现共享数据的功能. 在 Vuex 中,共享数据是通过 state 来实现的,所以我们需要在 Nuex.js 文件中实现 state 的功能. ...
- TienChin 渠道管理-前端展示渠道信息
在编写 Vue 项目的时候我们可以使用 IDEA 当中提供的一个工具叫做 structure,也就是说可以很轻松的列举出当前 Vue 文件的大致结构,点那个就会跳转到对应的地方. 简简单单介绍一个编写 ...
- 【主流技术】实战之 Spring Boot 中集成微信支付(小程序)
前言 微信支付是企业级项目中经常使用到的功能,作为后端开发人员,完整地掌握该技术是十分有必要的. 以下是经过真实商业项目实践的集成步骤,包括注册流程.调用过程.代码demo(经过脱敏)等,希望我的分享 ...
- C/C++ 使用API实现数据压缩与解压缩
在Windows编程中,经常会遇到需要对数据进行压缩和解压缩的情况,数据压缩是一种常见的优化手段,能够减小数据的存储空间并提高传输效率.Windows提供了这些API函数,本文将深入探讨使用Windo ...
- 从嘉手札<2023-11-27>
"我也没做错什么,放它去看海,总比跟着我好" 很多时候,悲伤总是细细的钻进心底 悄悄的生根发芽 待到了时机 它便如同一株参天巨树般郁郁葱葱 郁郁葱葱的令人发疯 人生本就像是做了一场 ...
- RabbitMQ高级知识(消息可靠性,死信交换机,惰性队列,MQ集群)
服务异步通信-高级篇 消息队列在使用过程中,面临着很多实际问题需要思考: 1.消息可靠性 消息从发送,到消费者接收,会经历多个过程: 其中的每一步都可能导致消息丢失,常见的丢失原因包括: 发送时丢失: ...