【论文笔记】SegNet
【深度学习】总目录
SegNet是Cambridge提出旨在解决自动驾驶或者智能机器人的图像语义分割深度网络,开放源码,基于caffe框架。SegNet运用编码-解码结构和最大池化索引进行上采样,最主要的贡献是它在效率上的提升(内存和时间)。文章很长,消融实验写的很详细,了解一下对以后改模型有所帮助。最后与DeepLab-LargeFOV和DeconvNet的对比实验我没有细看,这边先不写了。
原文地址:https://arxiv.org/abs/1511.00561
复现详解:http://mi.eng.cam.ac.uk/projects/segnet/tutorial.html
1 Motivation
最近的一些方法尝试直接采用用于类别预测的深度体系结构来进行像素级标记。结果虽然非常令人鼓舞,但结果看起来还是粗糙的。这主要是因为最大池化和子采样降低了特征图的分辨率。我们设计SegNet的动机来自于将低分辨率特征映射到输入分辨率以实现像素级分类。这种映射必须产生对精确的边界定位有用的特征。
道路场景理解需要对外观(道路、建筑)、形状(汽车、行人)进行建模,并理解不同类别(如道路和人行道)之间的空间关系(上下文)。在典型的道路场景中,大多数像素属于道路、建筑等大类,因此网络必须产生平滑的分割。引擎还必须能够根据物体的形状描绘物体,尽管它们的尺寸很小。因此,在提取的图像表示中保留边界信息是重要的。从计算角度来看,在推理过程中,网络必须在内存和计算时间方面都有效。网络需要有端到端训练的能力,以便使用有效的权重更新技术(如随机梯度)联合优化网络中的所有权重。
2 网络结构
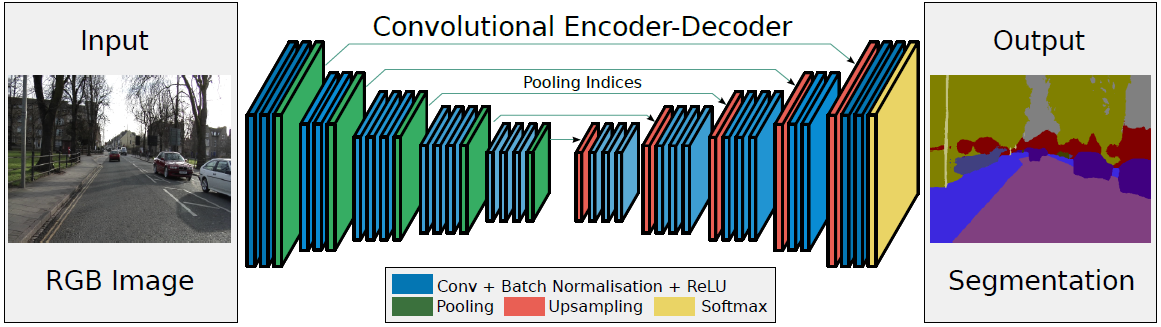
- 左边是Encoder:卷积提取特征,通过pooling增大感受野,同时图片变小。使用的是VGG16的前13层卷积网络,去除全连接层可以保留更高分辨率的特征图,并且能够显著地减小网络的参数(134M->14.7M)
- 右边是Decoder:Upsamping就是Pooling的逆过程,将图片变成两倍大小,再用index信息直接将数据放回对应位置,后面再接Conv训练学习。
- 最后通过Softmax,得到每一个像素属于某个类别的概率,最大概率所属类别做为该像素的label,最终完成图像像素级别的分类。
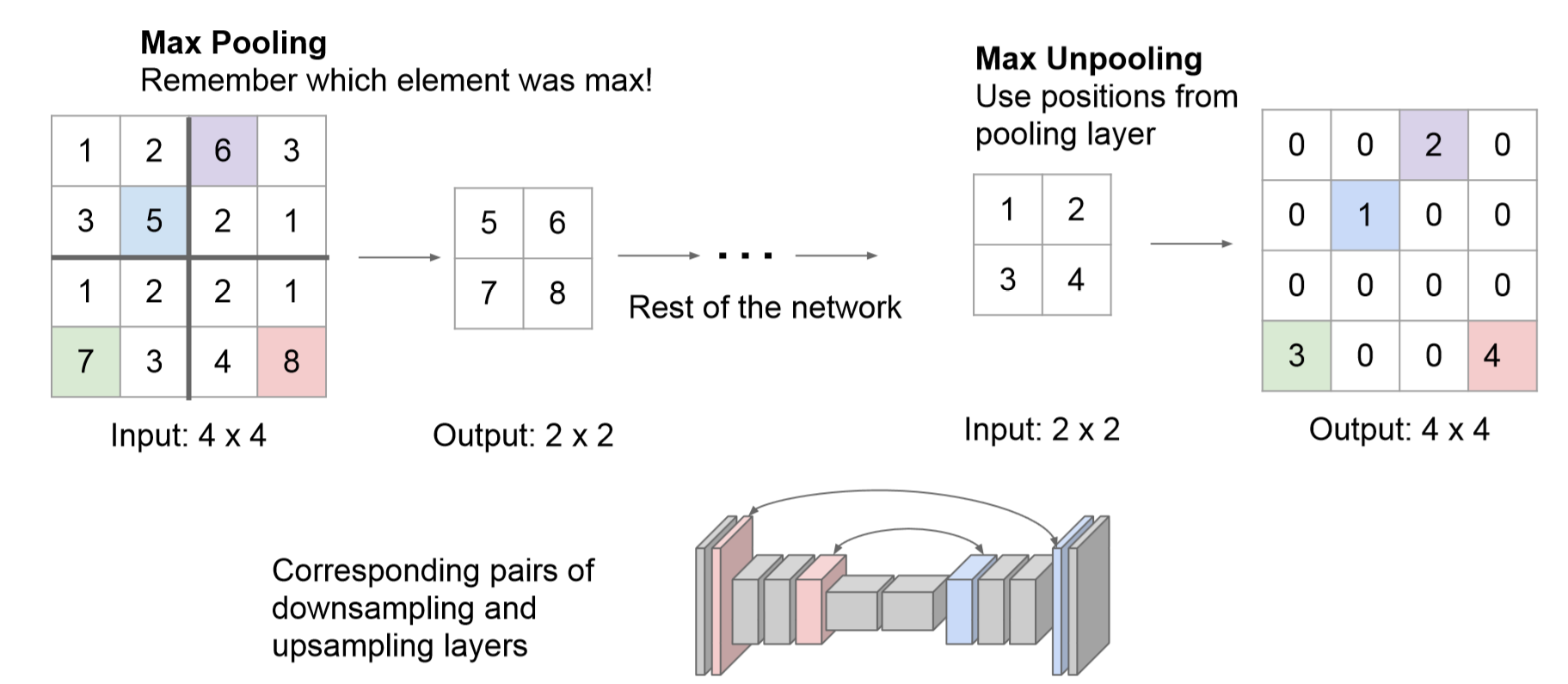
max-pooling indices(亮点)
在Encoder中,每次max-pooling,都会保存max权值在2x2filter中的相对位置;在Decoder中,根据保存的indices进行上采样:首先对输入的特征图放大两倍,然后把输入特征图的数据根据Encoder中pooling层的索引位置放入,其他位置为0。
利用池化索引来执行非线性上采样的优点:(1)保留了部分重要的边界信息,改善了网络模型对于边界的描述 (2)减少了FCN中因上采样而需要训练的参数 (3)能在极小修改的条件下与Encoder-Decoder网络模型相结合。
3 实验
3.1 评价指标
使用如下几种指标(1)global accuracy(G)(2)class average accuracy(C) (3)mIoU:比类平均准确率更严格,因为它惩罚FP预测,然而mIoU并不是类别平衡cross-entropy损失函数的优化目标(其优化目标是准确率最大化)。这三种指标在语义分割评价指标中介绍过。还有对边界描述的评价指标boundary F1-measure (BF):涉及计算边界像素的F1指标。给定一个像素容错距离,计算预测值和ground truth类别边界之间的精确度和召回率。作者使用图像对角线的0.75%作为容错距离。与mIoU相比,BF的评判结果更符合人类对语义分割效果的判定。
3.2 Decoder Variants
很多语义分割网络有相同的Encoder,仅在Decoder上有所不同。这边选择比较FCN和SegNet的解码技术。
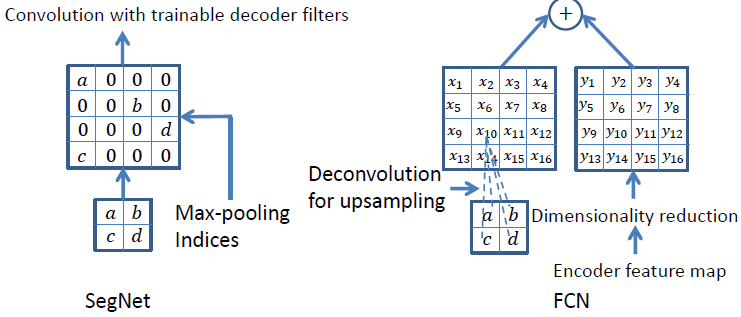
如上图所示,SegNet使用最大池化索引来上采样,后面再接Conv训练学习。这个上采样不需要训练学习,只是占用了一些存储空间。FCN使用转置卷积进行上采样,这一过程需要学习,然后将Encoder中对应的特征矩阵降维后相加。为了分析SegNet并将其性能与FCN进行比较,作者设计了以下几种变种。
- SegNet-Basic:4 encoders + 4 decoders,使用池化索引,卷积后加Bn,不用bias和ReLu。在所有编码器和解码器层上选择7×7的恒定内核大小以提供用于平滑标记的宽上下文。
- SegNet-Basic-SingleChannelDecoder:解码器的卷积用的单通道,显著减少了可训练参数的数量和推理时间。
- SegNet-Basic-EncoderAddition:池化索引后接卷积 + 逐元素add
- FCN-Basic:将encoder中的特征图利用1x1的卷积进行维度缩减至K通道(k为类别数)然后作为decoder的输入。decoder中上采样使用8x8大小的转置卷积,上采样后的特征矩阵也是K通道。两者逐元素相加。上采样核使用双线性插值权进行初始化。
- FCN-Basic-NoAddition:不使用特征矩阵的逐元素add(也就是没有跳跃连接),只学习上采样核。FCN解码器模型要求在推理过程中存储编码器特征图。例如,以180×240分辨率以32位浮点精度存储FCN Basic第一层的64个特征图需要11MB。这可以通过对11个特征图进行降维来缩小,这需要大约1.9MB的存储空间。另一方面,SegNet对池索引的存储成本几乎可以忽略不计(如果每2×2个池窗口使用2位存储,则为0.17MB)。
- FCN Basic NoDimReduction:更占用内存的FCN,没有针对编码器特征图执行维度缩减。这意味着与FCN-Basic不同,最终编码器特征图在传递到解码器网络之前不会压缩到K个通道。因此,每个解码器末端的通道数与相应的编码器相同(即64)。
- Bilinear-Interpolation:使用固定双线性插值权重的上采样,不需要学习。
3.3 训练
- CamVid道路场景数据集,由367个训练图像和233个测试RGB图像(白天和黄昏场景)组成,分辨率为360×480,分割11个类别
- 随机梯度下降(SGD),lr = 0.1,momentum = 0.9
- 在每个epochs之前,训练集被打乱,然后按顺序挑选mini-batch(12幅图像),从而确保每个图像在一个epochs中只使用一次
- 选择在验证数据集上性能最高的模型
- 交叉熵损失 + median frequency balancing,当训练集中每个类的像素数量有很大变化时(例如道路、天空和建筑物像素主导CamVid数据集),则需要根据真实类别对损失进行不同的加权。
median frequency balancing:
(1)计算整个训练集中各个类别出现的频率: fc = 训练集中被标记为c的像素数/训练集中所有图片的总像素数 c=1,...,k
(2)选出集合[f1,...fk]中的中位数fmedian
(3)为每个类别的loss分配权重wc = fmedian / fc c=1,...,k
3.4 分析
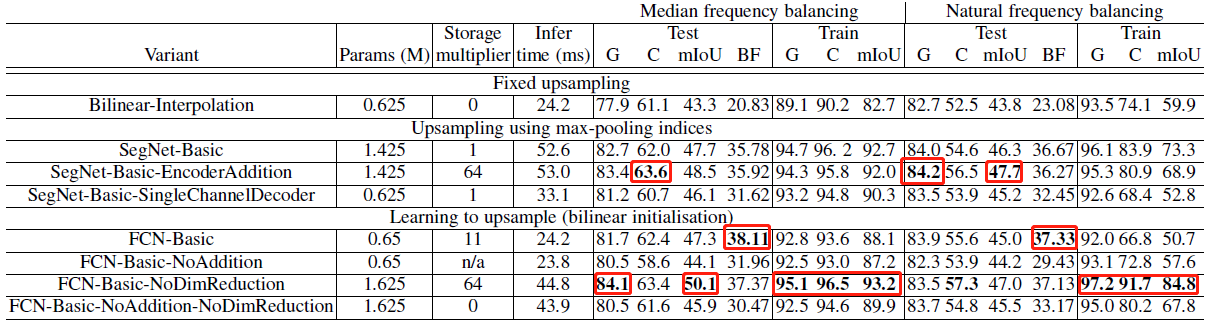
在各网络已训练至均收敛的条件下,各变体的评价结果如上表所示。结果表明:
- (1) Decoder需要训练,使用双线性插值作为Decoder的效果最差。
- (2) SegNet-Basic和FCN-Basic性能相近,但后者由于保存各层的feature map消耗更多内存。
- (3) FCN-Basic-NoAddition的性能差于结构最相近的SegNet-Basic,表明Encoder中信息的重要性。
- (4) 不对Encoder的输出进行压缩,能带来性能的提升,但在保存feature map时会增大内存消耗。
- (5) 与FCN-Basic-NoAddition和FCN-Basic-NoAddition-NoDimReduction相比,SegNet-Basic-SingleChannelDecoder虽然丢失了部分信息,但仍保留了部分Encoder中的信息,因此性能优于前两者。
- (6) 在不限制内存和推断时间的条件下,FCN-Basic-NoDimReduction和SegNet-EncoderAddition达到了最优的性能,FCN-Basic-NoDimReduction的BF1最高,表明存储空间和准确率之间存在着权衡。
作者总结了如下要点:
- 将encoder的特征图全部存储时,性能最好。 尤其是对于边缘的分割
- 当限制存储时,可以使用适当的decoder(例如SegNet类型)来存储和使用encoder产生的特征图(维数降低,max-pooling indices)的压缩形式来提高性能。
- 更大的decoder提高了网络的性能
3. SegNet算法详解
【论文笔记】SegNet的更多相关文章
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
随机推荐
- 国产GOWIN实现低成本实现CSI MIPI转换DVP
CSI MIPI转换DVP,要么就是通用IC操作,如龙讯芯片和索尼芯片,但是复杂的寄存器控制器实在开发太累.对于FPGA操作,大部分都是用xilinx的方案,xilinx方案成本太高,IP复杂. 而用 ...
- locust的 -T,--tags使用
官网的TAG配置说明:-T [TAG [TAG ...]], --tags [TAG [TAG ...]]List of tags to include in the test, so only ta ...
- Java学生信息管理系统源码
学生信息管理系统 功能说明 学生信息管理,包括学生.班级.院系.课程.成绩等的管理. 本程序仅供学习食用. 工程环境 JDK IntelliJ IDEA MySQL 运行说明 1.安装JDK. 2.导 ...
- NIFI简介
NIFI简介 首先是官网地址:Apache NiFi,不过会百度的估计都能搜到 因为后面的工作一定会用到,所以大致的听了一下讲解操作之类的 大概感觉就是NIFI是个web端的一种控制数据走向的工具?可 ...
- 模拟IDC spark读写MaxCompute实践
简介: 现有湖仓一体架构是以 MaxCompute 为中心读写 Hadoop 集群数据,有些线下 IDC 场景,客户不愿意对公网暴露集群内部信息,需要从 Hadoop 集群发起访问云上的数据.本文以 ...
- 更便捷:阿里云DCDN离线日志转存全新升级
简介: 1月6日,阿里云CDN年度产品升级发布会中,阿里云CDN产品专家邓建伟宣布DCDN离线日志转存全新升级,并对离线日志转存方案的价值.应用及使用进行了详细解读. 在日常CDN加速服务过程中会产生 ...
- [FAQ] swagger-php 支持 Authorization Bearer token 校验的用法
@OA\SecurityScheme 可以是 Controller 层面也可以是 Action 层面. 类型 type="apiKey". in="header" ...
- [FE] G2Plot 更新图表的两种方式
第一种是使用 G2Plot 对象上的 changeData 方法,如果不涉及到全局 title 等这些的更改,可以采用这种方式. 也就是说,只有纯数据方面的变动,使用 changeData 更新图表数 ...
- [PHP] 自定义 laravel/passport 的误区讲解
Passport 的 Client 模型对应用户是默认的 User 模型.使用的 guards 是 api. 如果你发现自定义 passport 时总是调试不成功,那么很有可能是以下原因. /** * ...
- dotnet 警惕 C# 的 is var 写法
本文将和大家介绍 C# 语言设计里面,我认为比较坑的一个语法.通过 is var 的写法,会让开发者误以为 null 是不被包含的,然而事实是在这里的 var 是被赋予含义的,将被允许 null 通过 ...