【论文笔记】SegNet
【深度学习】总目录
SegNet是Cambridge提出旨在解决自动驾驶或者智能机器人的图像语义分割深度网络,开放源码,基于caffe框架。SegNet运用编码-解码结构和最大池化索引进行上采样,最主要的贡献是它在效率上的提升(内存和时间)。文章很长,消融实验写的很详细,了解一下对以后改模型有所帮助。最后与DeepLab-LargeFOV和DeconvNet的对比实验我没有细看,这边先不写了。
原文地址:https://arxiv.org/abs/1511.00561
复现详解:http://mi.eng.cam.ac.uk/projects/segnet/tutorial.html
1 Motivation
最近的一些方法尝试直接采用用于类别预测的深度体系结构来进行像素级标记。结果虽然非常令人鼓舞,但结果看起来还是粗糙的。这主要是因为最大池化和子采样降低了特征图的分辨率。我们设计SegNet的动机来自于将低分辨率特征映射到输入分辨率以实现像素级分类。这种映射必须产生对精确的边界定位有用的特征。
道路场景理解需要对外观(道路、建筑)、形状(汽车、行人)进行建模,并理解不同类别(如道路和人行道)之间的空间关系(上下文)。在典型的道路场景中,大多数像素属于道路、建筑等大类,因此网络必须产生平滑的分割。引擎还必须能够根据物体的形状描绘物体,尽管它们的尺寸很小。因此,在提取的图像表示中保留边界信息是重要的。从计算角度来看,在推理过程中,网络必须在内存和计算时间方面都有效。网络需要有端到端训练的能力,以便使用有效的权重更新技术(如随机梯度)联合优化网络中的所有权重。
2 网络结构
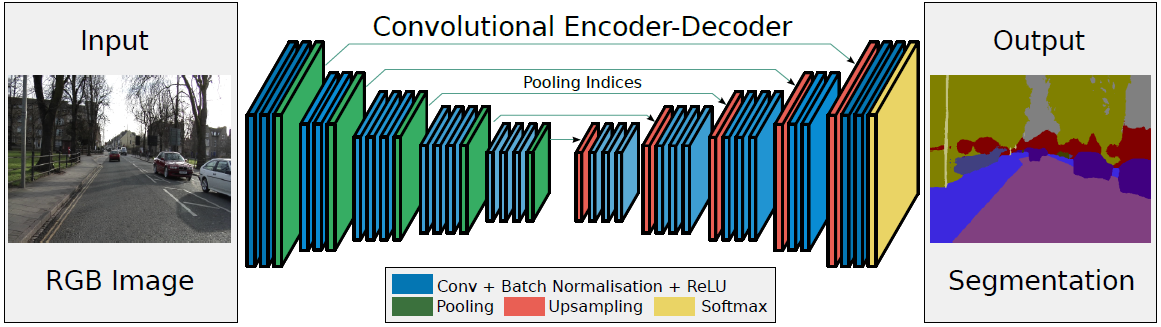
- 左边是Encoder:卷积提取特征,通过pooling增大感受野,同时图片变小。使用的是VGG16的前13层卷积网络,去除全连接层可以保留更高分辨率的特征图,并且能够显著地减小网络的参数(134M->14.7M)
- 右边是Decoder:Upsamping就是Pooling的逆过程,将图片变成两倍大小,再用index信息直接将数据放回对应位置,后面再接Conv训练学习。
- 最后通过Softmax,得到每一个像素属于某个类别的概率,最大概率所属类别做为该像素的label,最终完成图像像素级别的分类。
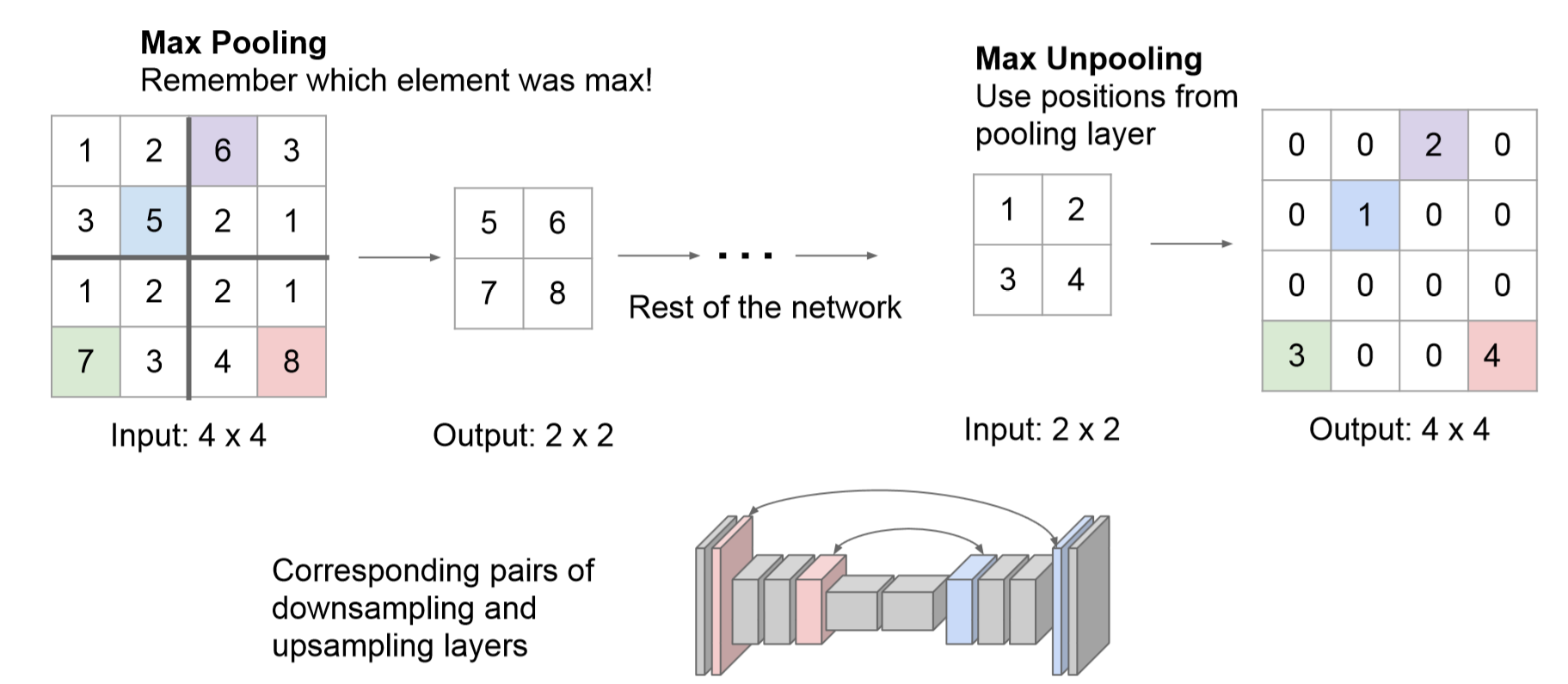
max-pooling indices(亮点)
在Encoder中,每次max-pooling,都会保存max权值在2x2filter中的相对位置;在Decoder中,根据保存的indices进行上采样:首先对输入的特征图放大两倍,然后把输入特征图的数据根据Encoder中pooling层的索引位置放入,其他位置为0。
利用池化索引来执行非线性上采样的优点:(1)保留了部分重要的边界信息,改善了网络模型对于边界的描述 (2)减少了FCN中因上采样而需要训练的参数 (3)能在极小修改的条件下与Encoder-Decoder网络模型相结合。
3 实验
3.1 评价指标
使用如下几种指标(1)global accuracy(G)(2)class average accuracy(C) (3)mIoU:比类平均准确率更严格,因为它惩罚FP预测,然而mIoU并不是类别平衡cross-entropy损失函数的优化目标(其优化目标是准确率最大化)。这三种指标在语义分割评价指标中介绍过。还有对边界描述的评价指标boundary F1-measure (BF):涉及计算边界像素的F1指标。给定一个像素容错距离,计算预测值和ground truth类别边界之间的精确度和召回率。作者使用图像对角线的0.75%作为容错距离。与mIoU相比,BF的评判结果更符合人类对语义分割效果的判定。
3.2 Decoder Variants
很多语义分割网络有相同的Encoder,仅在Decoder上有所不同。这边选择比较FCN和SegNet的解码技术。
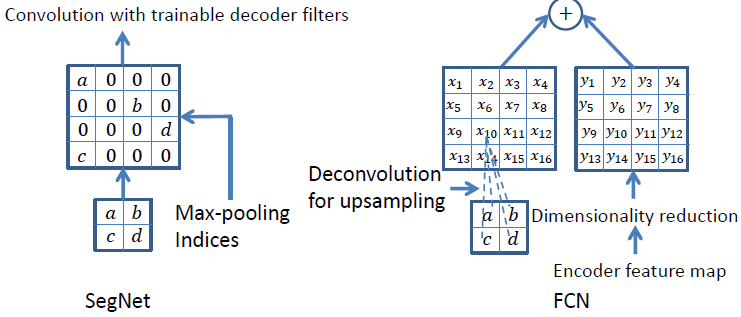
如上图所示,SegNet使用最大池化索引来上采样,后面再接Conv训练学习。这个上采样不需要训练学习,只是占用了一些存储空间。FCN使用转置卷积进行上采样,这一过程需要学习,然后将Encoder中对应的特征矩阵降维后相加。为了分析SegNet并将其性能与FCN进行比较,作者设计了以下几种变种。
- SegNet-Basic:4 encoders + 4 decoders,使用池化索引,卷积后加Bn,不用bias和ReLu。在所有编码器和解码器层上选择7×7的恒定内核大小以提供用于平滑标记的宽上下文。
- SegNet-Basic-SingleChannelDecoder:解码器的卷积用的单通道,显著减少了可训练参数的数量和推理时间。
- SegNet-Basic-EncoderAddition:池化索引后接卷积 + 逐元素add
- FCN-Basic:将encoder中的特征图利用1x1的卷积进行维度缩减至K通道(k为类别数)然后作为decoder的输入。decoder中上采样使用8x8大小的转置卷积,上采样后的特征矩阵也是K通道。两者逐元素相加。上采样核使用双线性插值权进行初始化。
- FCN-Basic-NoAddition:不使用特征矩阵的逐元素add(也就是没有跳跃连接),只学习上采样核。FCN解码器模型要求在推理过程中存储编码器特征图。例如,以180×240分辨率以32位浮点精度存储FCN Basic第一层的64个特征图需要11MB。这可以通过对11个特征图进行降维来缩小,这需要大约1.9MB的存储空间。另一方面,SegNet对池索引的存储成本几乎可以忽略不计(如果每2×2个池窗口使用2位存储,则为0.17MB)。
- FCN Basic NoDimReduction:更占用内存的FCN,没有针对编码器特征图执行维度缩减。这意味着与FCN-Basic不同,最终编码器特征图在传递到解码器网络之前不会压缩到K个通道。因此,每个解码器末端的通道数与相应的编码器相同(即64)。
- Bilinear-Interpolation:使用固定双线性插值权重的上采样,不需要学习。
3.3 训练
- CamVid道路场景数据集,由367个训练图像和233个测试RGB图像(白天和黄昏场景)组成,分辨率为360×480,分割11个类别
- 随机梯度下降(SGD),lr = 0.1,momentum = 0.9
- 在每个epochs之前,训练集被打乱,然后按顺序挑选mini-batch(12幅图像),从而确保每个图像在一个epochs中只使用一次
- 选择在验证数据集上性能最高的模型
- 交叉熵损失 + median frequency balancing,当训练集中每个类的像素数量有很大变化时(例如道路、天空和建筑物像素主导CamVid数据集),则需要根据真实类别对损失进行不同的加权。
median frequency balancing:
(1)计算整个训练集中各个类别出现的频率: fc = 训练集中被标记为c的像素数/训练集中所有图片的总像素数 c=1,...,k
(2)选出集合[f1,...fk]中的中位数fmedian
(3)为每个类别的loss分配权重wc = fmedian / fc c=1,...,k
3.4 分析
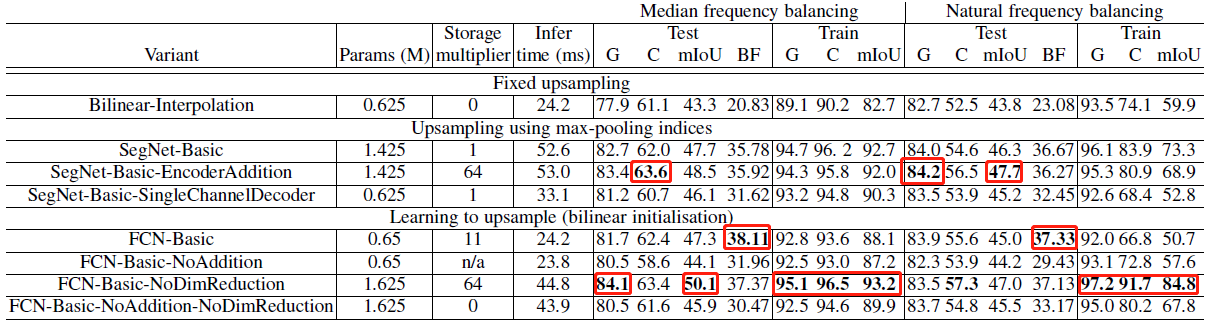
在各网络已训练至均收敛的条件下,各变体的评价结果如上表所示。结果表明:
- (1) Decoder需要训练,使用双线性插值作为Decoder的效果最差。
- (2) SegNet-Basic和FCN-Basic性能相近,但后者由于保存各层的feature map消耗更多内存。
- (3) FCN-Basic-NoAddition的性能差于结构最相近的SegNet-Basic,表明Encoder中信息的重要性。
- (4) 不对Encoder的输出进行压缩,能带来性能的提升,但在保存feature map时会增大内存消耗。
- (5) 与FCN-Basic-NoAddition和FCN-Basic-NoAddition-NoDimReduction相比,SegNet-Basic-SingleChannelDecoder虽然丢失了部分信息,但仍保留了部分Encoder中的信息,因此性能优于前两者。
- (6) 在不限制内存和推断时间的条件下,FCN-Basic-NoDimReduction和SegNet-EncoderAddition达到了最优的性能,FCN-Basic-NoDimReduction的BF1最高,表明存储空间和准确率之间存在着权衡。
作者总结了如下要点:
- 将encoder的特征图全部存储时,性能最好。 尤其是对于边缘的分割
- 当限制存储时,可以使用适当的decoder(例如SegNet类型)来存储和使用encoder产生的特征图(维数降低,max-pooling indices)的压缩形式来提高性能。
- 更大的decoder提高了网络的性能
3. SegNet算法详解
【论文笔记】SegNet的更多相关文章
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 论文笔记(1):Deep Learning.
论文笔记1:Deep Learning 2015年,深度学习三位大牛(Yann LeCun,Yoshua Bengio & Geoffrey Hinton),合作在Nature ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
随机推荐
- 文件上传之Webshell连接方法
"感谢您阅读本篇博客!如果您觉得本文对您有所帮助或启发,请不吝点赞和分享给更多的朋友.您的支持是我持续创作的动力,也欢迎留言交流,让我们一起探讨技术,共同成长!谢谢!" Websh ...
- 第 10 章 使用pyecharts 进行数据展示
第 10 章 使用pyecharts 进行数据展示 10.1 安装 pyecharts pyecharts 是一个用于生成 Echarts 图表的类库, Echarts 是百度开源的一个数据可视化JS ...
- 冬奥幕后故事:从低碳火炬到AI裁判,十四年后中国科技再上场
北京冬奥会开幕后,一个段子在社交媒体上流传甚广:"夏奥开幕式和冬奥开幕式就差半年,这半年人类科技进步真大啊." 文|张婧怡 封面来源|北京日报客户端 冬奥季终于到来. 2月4 ...
- RocketMQ 千锤百炼--哈啰在分布式消息治理和微服务治理中的实践
简介: 随着公司业务的不断发展,流量也在不断增长.我们发现生产中的一些重大事故,往往是被突发的流量冲跨的,对流量的治理和防护,保障系统高可用就尤为重要. 作者|梁勇 背景 哈啰已进化为包括两轮出 ...
- Joint Consensus两阶段成员变更的单步实现
简介: Raft提出的两阶段成员变更Joint Consensus是业界主流的成员变更方法,极大的推动了成员变更的工程应用.但Joint Consensus成员变更采用两阶段,一次变更需要提议两条日 ...
- [FAQ] uni-app 如何让页面不展示返回箭头图标
默认情况是,有历史上一页的 页面会在左上角展示返回图标. 比如登录页不想展示返回,在跳转进来时可以使用 uni.redirectTo({}),它能够关闭其它页面,这样当前页就不会有返回箭头了. Ref ...
- VisualStudio 使用 FastTunnel 辅助搭建远程调试环境
有时候需要远程调试一些用户问题,期望能使用本机的 Visual Studio 开发环境,调试远程的用户的设备上的应用.这时会遇到的一个问题是如何让本机的 Visual Studio 可以连接上远程的用 ...
- 在 VisualStudio 给文件起一个带分号的文件名会怎样
小伙伴都知道在 Windows 下是支持文件名使用分号的,而写过 Roslyn 的小伙伴都知道,在 csproj 项目里面使用分号分割数组.那么在 VS 里面将一个文件名添加分号会如何?下面让咱写写看 ...
- 2018-6-30-dotnet-设计规范-·-抽象类
title author date CreateTime categories dotnet 设计规范 · 抽象类 lindexi 2018-6-30 9:2:38 +0800 2018-06-30 ...
- 数据可视化之matplotlib模块
一.简介 Matplotlib是一个强大的Python绘图和数据可视化的工具包.数据可视化也是我们数据分析的最重要的工作之一,可以帮助我们完成很多操作,例如:找出异常值.必要的一些数据转换等.完成数据 ...