core dump 路径定义以及监控
Core Dump 是什么?
Core Dump 是指进程异常退出时,操作系统将进程的内存状态保存到文件中,这个文件就是 Core Dump 文件,中文一般翻译为“核心转储”,哈,看起来还不如不翻译。
我们可以认为 Core Dump 是“内存快照”,但实际上,除了内存信息之外,还有些关键的程序运行状态也会同时 dump 下来,例如寄存器信息(包括程序指针、栈指针等)、内存管理信息、其他处理器和操作系统状态和信息。
Core Dump 有什么用?
一个是用于排查问题,例如程序 crash 了,我们可以通过 gdb 等工具来分析 core dump 文件,找到问题的原因。另一个是监控,我们可以通过监控手段及时发现程序 crash 了,及时处理。
程序自身产生的 Core Dump 文件一般可以用来分析程序运行到哪里出错了。
Linux 平台常用的 coredump 文件分析工具是 gdb;Solaris 平台用 pstack 和 pflags;Windows 平台用 userdump 和 windbg。
测试生成 Core Dump 文件
[root@VM-0-33-debian:~# cd /home/user
[root@VM-0-33-debian:~# ulimit -c unlimited
[root@VM-0-33-debian:~# kill -s SIGSEGV $$
这将会在你当前的 shell 下触发一个段错误,进而生成一个 core dump 文件,文件名为 core 或 core.pid,pid 是当前 shell 的进程号。
注意,ulimit -c unlimited 是告诉操作系统,不要限制 core dump 文件的大小,如果你执行 ulimit -c 看到输出 0,就表示 core dump 文件大小限制为 0 了,也就不会生成。比如我的机器环境:
[root@VM-0-33-debian:~# ulimit -a
real-time non-blocking time (microseconds, -R) unlimited
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 30148
max locked memory (kbytes, -l) 969535
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 30148
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
注意 core file size 那一行,我的环境是 0,就表示限制了 core dump 文件的生成。
Core Dump 文件路径定义
在 Linux 下,core dump 文件的路径是由 /proc/sys/kernel/core_pattern 定义的,如果这个文件不存在,或者内容为空,那么 core dump 文件就会生成在当前目录下。
[root@VM-0-33-debian:~# cat /proc/sys/kernel/core_pattern
core
上面的输出表示,core dump 文件会生成在当前目录下,文件名为 core。
我们可以通过修改 /proc/sys/kernel/core_pattern 来定义 core dump 文件的路径和文件名,例如:
[root@VM-0-33-debian:~# mkdir -p /tmp/cores
[root@VM-0-33-debian:~# chmod a+rwx /tmp/cores
[root@VM-0-33-debian:~# echo "/tmp/cores/core.%e.%p.%h.%t" > /proc/sys/kernel/core_pattern
然后,我们重新生成 core dump 文件:
[root@VM-0-33-debian:~# cd /home/user
[root@VM-0-33-debian:~# ulimit -c unlimited
[root@VM-0-33-debian:~# kill -s SIGSEGV $$
此时,我们会生成一个类似这样的文件:/tmp/cores/core.bash.8539.VM-0-33-debian.1236975953。其中,bash 是进程名,8539 是进程号,VM-0-33-debian 是主机名,1236975953 是时间戳。文件存储在 /tmp/cores 目录下。
对于 core_pattern 的定义,可以使用如下的占位符:
%p: pid
%: '%' is dropped
%%: output one '%'
%u: uid
%g: gid
%s: signal number
%t: UNIX time of dump
%h: hostname
%e: executable filename
%: both are dropped
其中,%h hostname 最好加上,假如我们把 core dump 文件存放在 NFS 上,就可以用 %h 来区分 core dump 文件来自哪个机器了。
echo "/tmp/cores/core.%e.%p.%h.%t" > /proc/sys/kernel/core_pattern 这种设置方式,是临时生效,如果机器重启,就会失效。如果想要永久生效,可以修改 /etc/sysctl.conf 文件,添加一行:
# Own core file pattern...
kernel.core_pattern=/tmp/cores/core.%e.%p.%h.%t
然后执行 sysctl -p 命令,使配置生效。
Core Dump 文件监控
一般来讲,对于规范化做的好的公司,core_pattern 是系统部交付机器的时候,统一设置好的,公司所有的机器的 core_pattern 都是一致的,会设置成一个统一的目录,例如 /opt/cores,这样就可以方便地对 core dump 新文件进行监控了。
这里,推荐大家使用 catpaw(基本介绍参考这里:太卷了,史上最简单的监控系统 catpaw 简介),catpaw 从 v0.3.0 版本开始,引入了 mtime 监控插件,可以监控近期的文件变更,进而监控新的 core dump 文件的产生。
mtime 插件的配置如下:
[[instances]]
time_span = "3m"
directory = "/opt/cores"
check = "file changed or created"
interval = "30s"
[instances.alerting]
## Enable alerting or not
enabled = true
## Same functionality as Prometheus keyword 'for'
for_duration = 0
## Minimum interval duration between notifications
repeat_interval = "5m"
## Maximum number of notifications
repeat_number = 3
## Whether notify recovery event
recovery_notification = true
## Choice: Critical, Warning, Info
default_severity = "Warning"
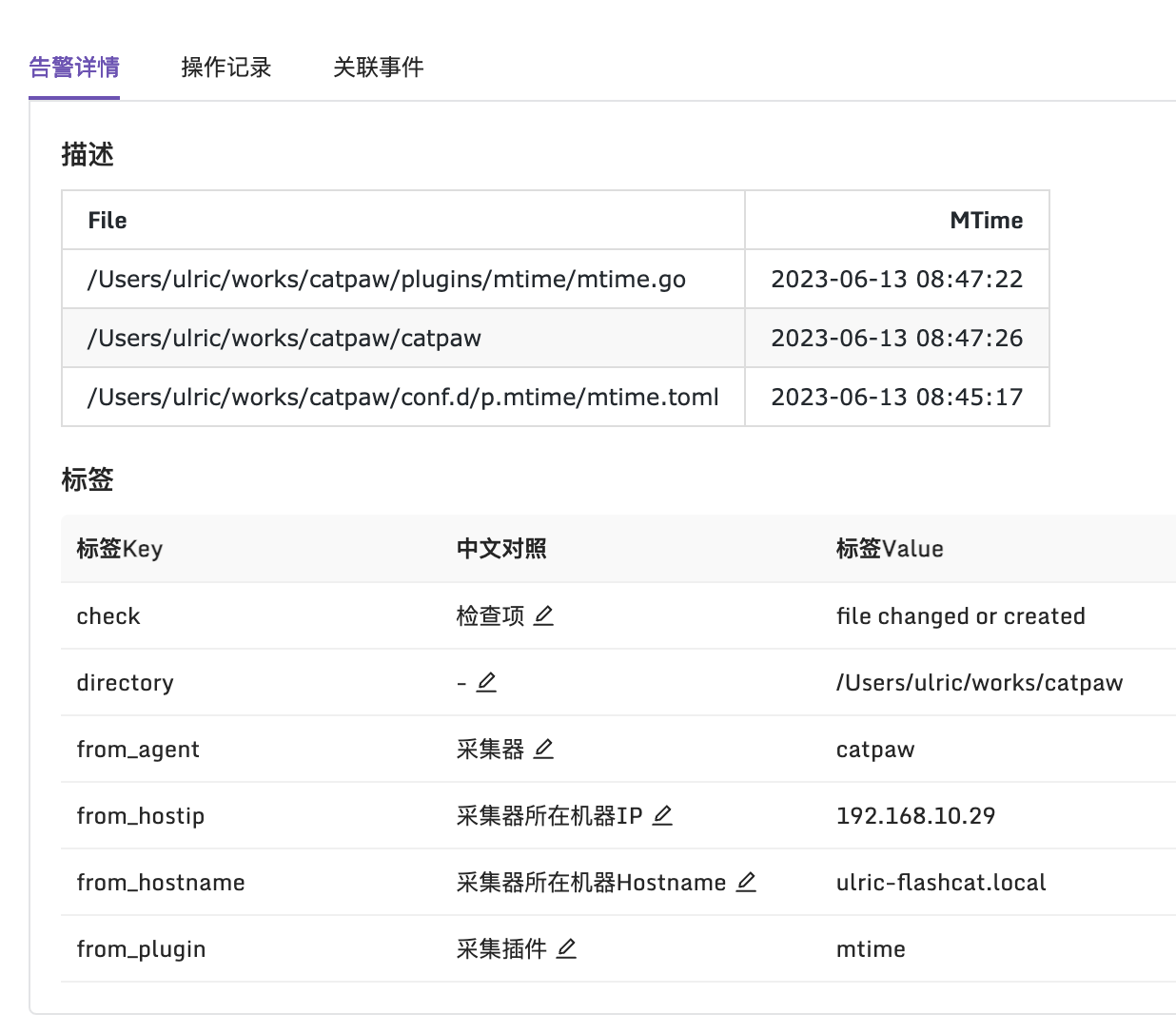
上面的意思表示,每 30s 探测一次,每次探测最近 3 分钟内是否有文件变更或新文件产生。比如我随便对某个目录做了测试,最终输出的内容长这个样子:
总结
希望本文介绍的内容对你有帮助,愿不吝点赞、在看。如果有其他这类事件监控的场景需求,也可以联系我,后面都会一并做到 catpaw 里。
虽然 FlashDuty 有免费套餐,如果就是不想用,也可以模仿 FlashDuty 的事件接收接口自己搞个 HTTP Server,接收 catpaw 的事件推送,然后自己处理,比如发送到钉钉、飞书、邮件等。
enjoy...make a better world
core dump 路径定义以及监控的更多相关文章
- 使用GDB 追踪依赖poco的so程序,core dump文件分析.
前言 在windows 下 系统核心态程序蓝屏,会产生dump文件. 用户级程序在设置后,程序崩溃也会产生dump文件.以方便开发者用windbg进行分析. so,linux 系统也有一套这样的东东- ...
- gdb调试常用实用命令和core dump文件的生成
1.生成core dump文件的方法: $ ulimit -c //查看是否为0 如果为0 $ ulimit -c unlimited 这样在程序崩溃以后会在当前目录生成一个core.xxx ...
- 【转】段错误调试神器 - Core Dump详解
from:http://www.embeddedlinux.org.cn/html/jishuzixun/201307/08-2594.html 段错误调试神器 - Core Dump详解 来源:互联 ...
- 段错误调试神器 - Core Dump详解
一.前言: 有的程序可以通过编译, 但在运行时会出现Segment fault(段错误). 这通常都是指针错误引起的. 但这不像编译错误一样会提示到文件某一行, 而是没有任何信息, 使得我们的调试变得 ...
- 关于内核转储(core dump)的设置方法
原作者:http://blog.csdn.net/wj_j2ee/article/details/7161586 1. 内核转储作用 (1) 内核转储的最大好处是能够保存问题发生时的状态. (2) 只 ...
- gdb调试常用实用命令和core dump文件的生成(转)
1.生成core dump文件的方法: $ ulimit -c //查看是否为0 如果为0 $ ulimit -c unlimited 这样在程序崩溃以后会在当前目录生成一个core.xxxx的 ...
- Core Dump 程序故障分析
1.编写一个应用程序,使用gdb+core dump进行故障分析, core dump的概念: core dump又叫核心转存:当程序在运行过程中发生异常,这时Linux系统可以把程序在运行时的内存内 ...
- Linux core dump使用
什么是 core dump? core dump是一个当进程意外终止时包含进程内存内容的文件.当程序崩溃的时候,core dump由kernel触发.core dump可以作为程序崩溃时的事后快照(p ...
- Linux Core Dump
当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内存状态记录下来,保存在一个文件中,这种行为就叫做Core Dump(中文有的翻译成“核心转储”).我们可以认为 core dump 是“内存快 ...
- core dump 是什么意思?
core dump,翻译过来讲,就是核心转储.大致上就是指,如果由于应用错误,如浮点异常.指令异常等,操作系统将会转入内核的异常处理,向对应的进程发送特定的信号(SIGNAL),如果进程中没有对这些信 ...
随机推荐
- 【知识点】如何快速开发、部署 Serverless 应用?
简介: 本文将详细介绍如何开发和部署 Serverless 应用,并通过阿里云函数计算控制台与开发者工具 Serverless Devs 进行应用的初始化.部署:最后分享应用的调试,通过科学发布.可观 ...
- 关于 Data Lake 的概念、架构与应用场景介绍
数据湖(Data Lake)概念介绍 什么是数据湖(Data Lake)? 数据湖的起源,应该追溯到2010年10月,由 Pentaho 的创始人兼 CTO, James Dixon 所提出,他提出的 ...
- Android项目架构设计深入浅出
简介:本文结合个人在架构设计上的思考和理解,介绍如何从0到1设计一个大型Android项目架构. 作者 | 璞珂 来源 | 阿里技术公众号 前言:本文结合个人在架构设计上的思考和理解,介绍如何从 ...
- LlamaIndex 常见问题解答(FAQ)
提示:如果您尚未完成,请安装 LlamaIndex 并完成起步教程.遇到不熟悉的术语时,请参考高层次概念部分. 在这个章节中,我们将从您为起步示例编写的代码开始,展示您可能希望针对不同应用场景对其进行 ...
- dotnet 记 TaskCompletionSource 的 SetException 可能将异常记录到 UnobservedTaskException 的问题
本文将记录 dotnet 的一个已知问题,且是设计如此的问题.假定有一个 TaskCompletionSource 对象,此对象的 Task 没有被任何地方引用等待.在 TaskCompletionS ...
- dotnet SemanticKernel 入门 调用原生本机技能
本文将告诉大家如何在 SemanticKernel 里面调用原生本机技能,所谓原生本机技能就是使用 C# 代码编写的原生本地逻辑技能,这里的技能可讲的可不是游戏角色里面的技能哈,指的是实现某个功能的技 ...
- 开源相机管理库Aravis例程学习(四)——multiple-acquisition-signal
目录 简介 例程代码 函数说明 g_main_loop_new g_main_loop_run g_main_loop_quit g_signal_connect arv_stream_set_emi ...
- Java设计模式-策略模式-基于Spring实现
1.策略模式 1.1.概述 策略模式是一种行为设计模式,它允许在运行时选择算法的行为.它将算法封装在独立的策略类中,使得它们可以相互替换,而不影响客户端代码.这种模式通过将算法的选择从客户端代码中分离 ...
- 大模型_2:Prompt Engineering
目录: 1.提示工程简介 2.如何写好提示词 2.1 描述清晰 2.2 角色扮演 2.3 提供示例 2.4 复杂任务分解 2.5 使用格式符区分语义 2.6 情感和物质激励 2.7 使用英语 2.8 ...
- layui.js
目录 用法: 1.在base.js里导入layui插件 2.在使用的html页面里引入 base.js lucky.js index.html 用法: 1.在base.js里导入layui插件 2.在 ...