trino on yarn
一、前言
最近在研究trino on yarn 功能,网上大部分都是关于presto on yarn文章,关于trino on yarn 资料很少,但是本质上差不多,需要修改一些内容比,主要在调试方面这个slider不是很方便,分享下实践过程。
如果Trino集群没有弹性扩缩容需求或者已经有很成熟的K8S容器部署方案你可以忽略这个功能,最后实现效果就是通过slider自动部署以及调整trino node节点的数量实现快速的扩容缩容,查询本身的消耗资源跟yarn没有很大关系,还是跟配置的trino的集群资源有关。在集群资源紧张的情况下,合理调节不同时段资源的分配,比如夜里查询请求很少的情况下,可以释放一部分node节点给Flink Spark去做计算还是很实用的。
二、环境准备
编译apache-slider-0.92.0-incubating
- 下载地址:https://archive.apache.org/dist/incubator/slider/
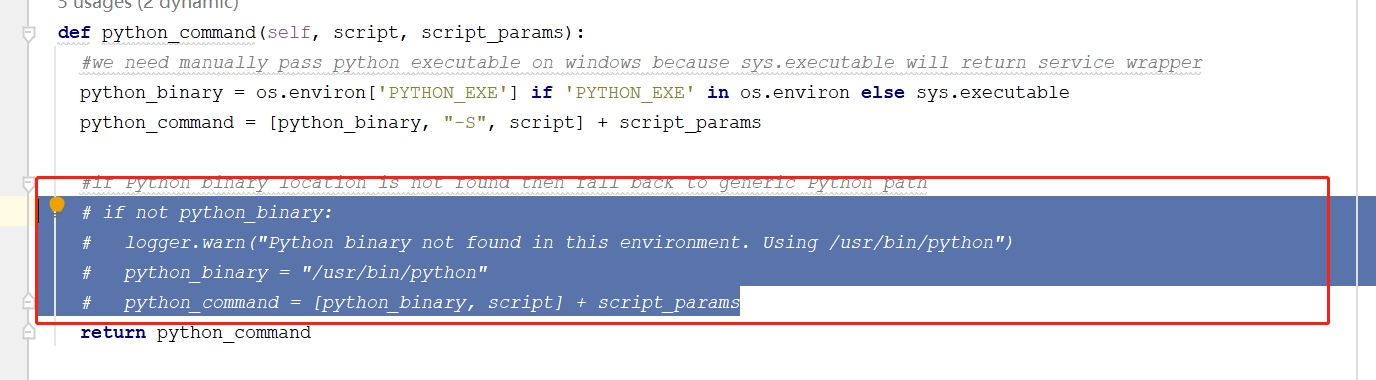
- 修改PythonExecutor.py,不然执行Python失败,参考: https://issues.apache.org/jira/browse/SLIDER-1254
def python_command(self, script, script_params):
#we need manually pass python executable on windows because sys.executable will return service wrapper
python_binary = os.environ['PYTHON_EXE'] if 'PYTHON_EXE' in os.environ else sys.executable
python_command = [python_binary, "-S", script] + script_params #if Python binary location is not found then fall back to generic Python path
if not python_binary:
logger.warn("Python binary not found in this environment. Using /usr/bin/python")
python_binary = "/usr/bin/python"
python_command = [python_binary, script] + script_params
return python_command
编译trino-yarn
1.GitHub地址:https://github.com/prestodb/presto-yarn.git
2.修改根目录pom文件

3.修改presto-yarn-package pom文件依赖
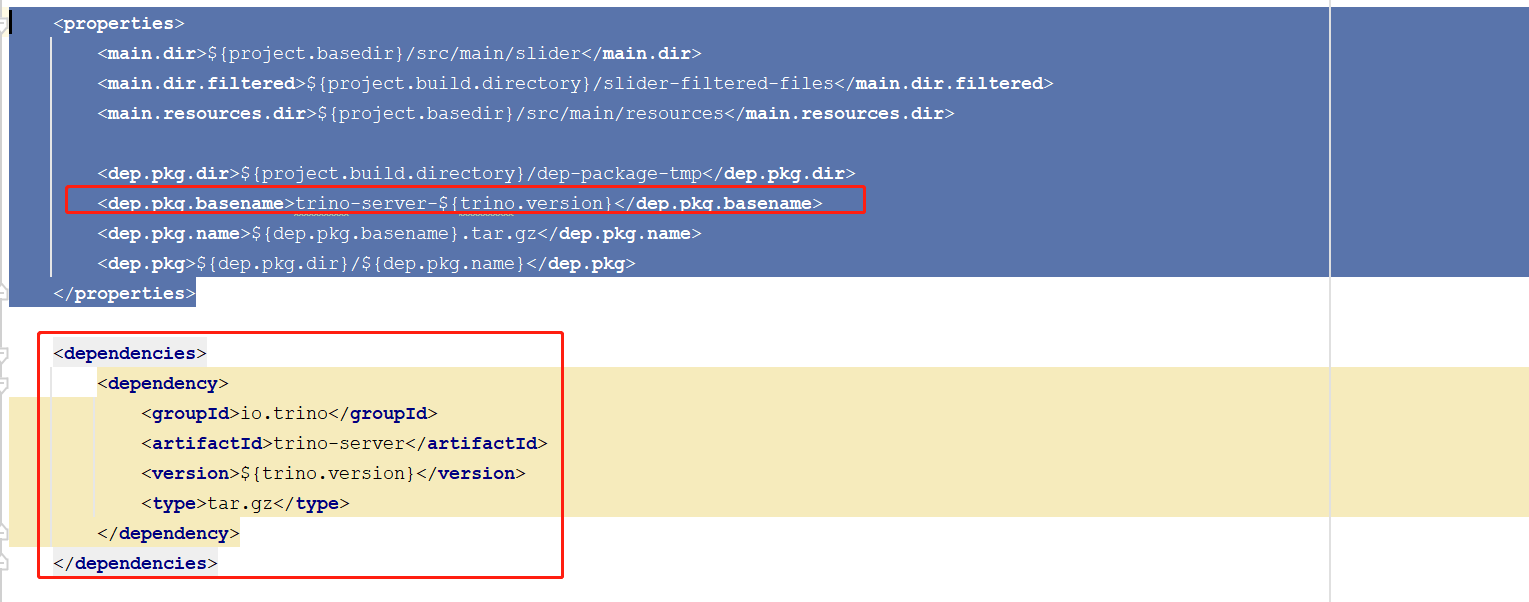

三、部署安装
1.编译好了以后把2个文件拷贝到服务器上,设置trino-yarn-package appConfig-default.json,resources-default.json,熟悉trino、presto的应该都比较熟悉,附上我的配置参考:
{
"schema": "http://example.org/specification/v2.0.0",
"metadata": {
},
"global": {
"site.global.app_user": "presto",
"site.global.user_group": "presto",
"site.global.data_dir": "/data/trino/data",
"site.global.config_dir": "/data/trino/etc",
"site.global.app_name": "trino-server-418",
"site.global.app_pkg_plugin": "${AGENT_WORK_ROOT}/app/definition/package/plugins/",
"site.global.singlenode": "true",
"site.global.coordinator_host": "192.168.2.182",
"site.global.presto_query_max_memory": "27GB",
"site.global.presto_query_max_memory_per_node": "4GB",
"site.global.presto_query_max_total_memory_per_node": "9GB",
"site.global.presto_server_port": "8089","site.global.catalog": "{'tpch': ['connector.name=system']}",
"site.global.jvm_args": "['-server', '-Xmx50G', '-XX:InitialRAMPercentage=80', '-XX:MaxRAMPercentage=80', '-XX:G1HeapRegionSize=32M', '-XX:+ExplicitGCInvokesConcurrent', '-XX:+ExitOnOutOfMemoryError', '-XX:+HeapDumpOnOutOfMemoryError', '-XX:-OmitStackTraceInFastThrow', '-XX:ReservedCodeCacheSize=512M', '-XX:PerMethodRecompilationCutoff=10000', '-XX:PerBytecodeRecompilationCutoff=10000', '-Djdk.attach.allowAttachSelf=true', '-Djdk.nio.maxCachedBufferSize=2000000', '-XX:+UnlockDiagnosticVMOptions', '-XX:+UseAESCTRIntrinsics', '-XX:+UseG1GC']",
"site.global.log_properties": "['io.trino=INFO']",
"application.def": ".slider/package/trino/trino-yarn.zip",
"java_home": "/home/presto/presto/zulu17.42.21-ca-crac-jdk17.0.7-linux_x64/bin/java"
},
"components": {
"slider-appmaster": {
"jvm.heapsize": "128M"
}
}
}
{
"schema": "http://example.org/specification/v2.0.0",
"metadata": {
},
"global": {
"yarn.vcores": "1"
},
"components": {
"slider-appmaster": {
},
"WORKER": {
"yarn.role.priority": "2",
"yarn.component.instances": "3",
"yarn.component.placement.policy": "1",
"yarn.memory": "1500"
}
}
}
详细参考:https://prestodb.io/presto-yarn/installation-yarn-configuration-options.html#appconfig-json
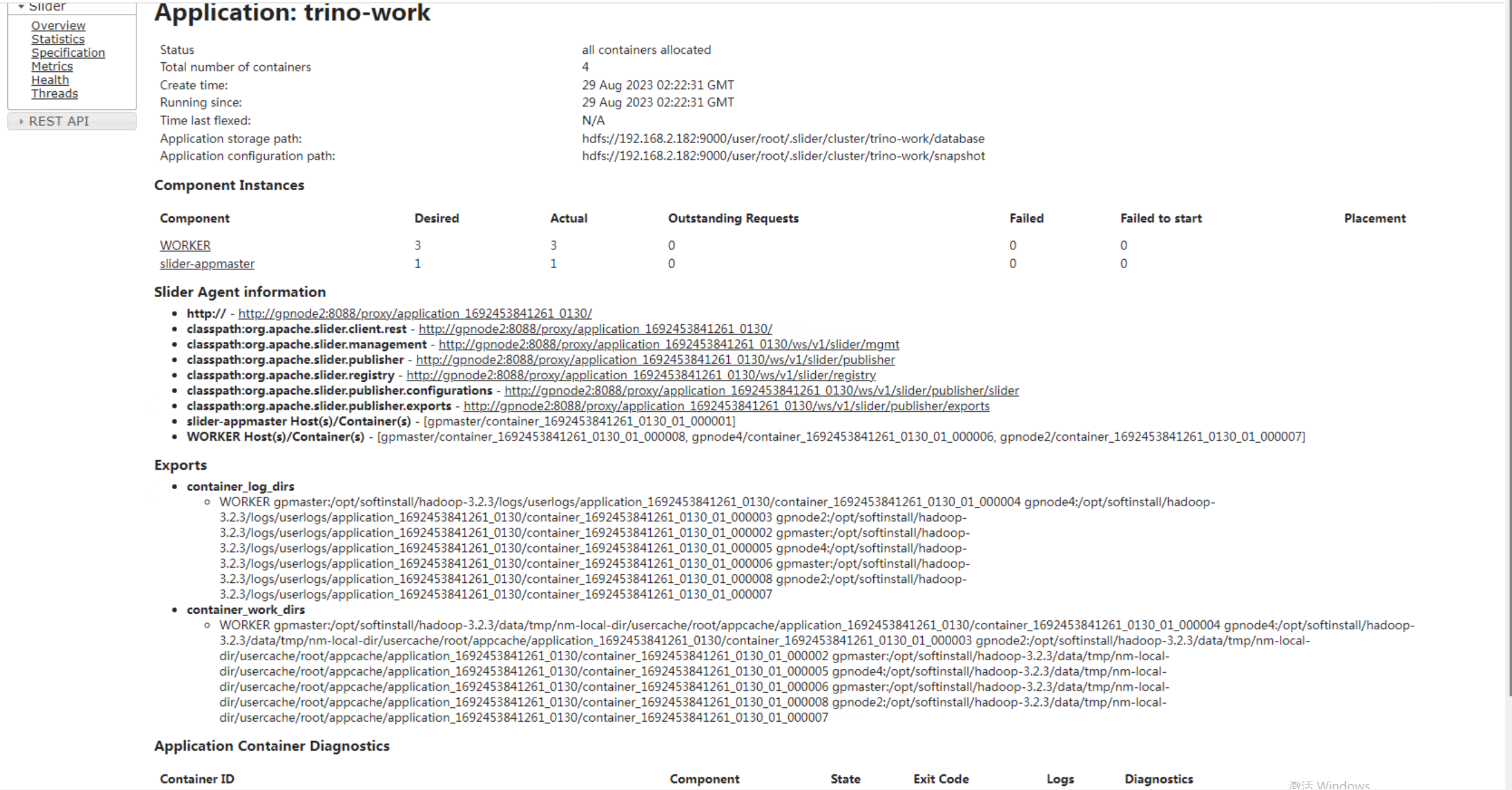
2.启动slider
../bin/slider create presto-query --template appConfig-default.json --resources resources-default.json
成功效果图
详细的可以参照这个博客,非常的详尽:PrestoOnYarn搭建及其问题解决方案总结_presto on yarn_qq_2368521029的博客-CSDN博客,(我主要写我调试的内容,这方便的内容比较少)
四、调试排错
部署到Yarn 里面后会遇到很多的问题,但是怎么调试这个还是稍微有点麻烦,我给出我的调试方法给大家一个参考。
其实程序本身就是通过动态的分发Presto-yarn包里的trino-server文件以及自动生成trino的配置文件,slider是一个通用执行命令的框架。通过日志我们可以看到实际的工作目录,以及具体的执行python脚本命令。
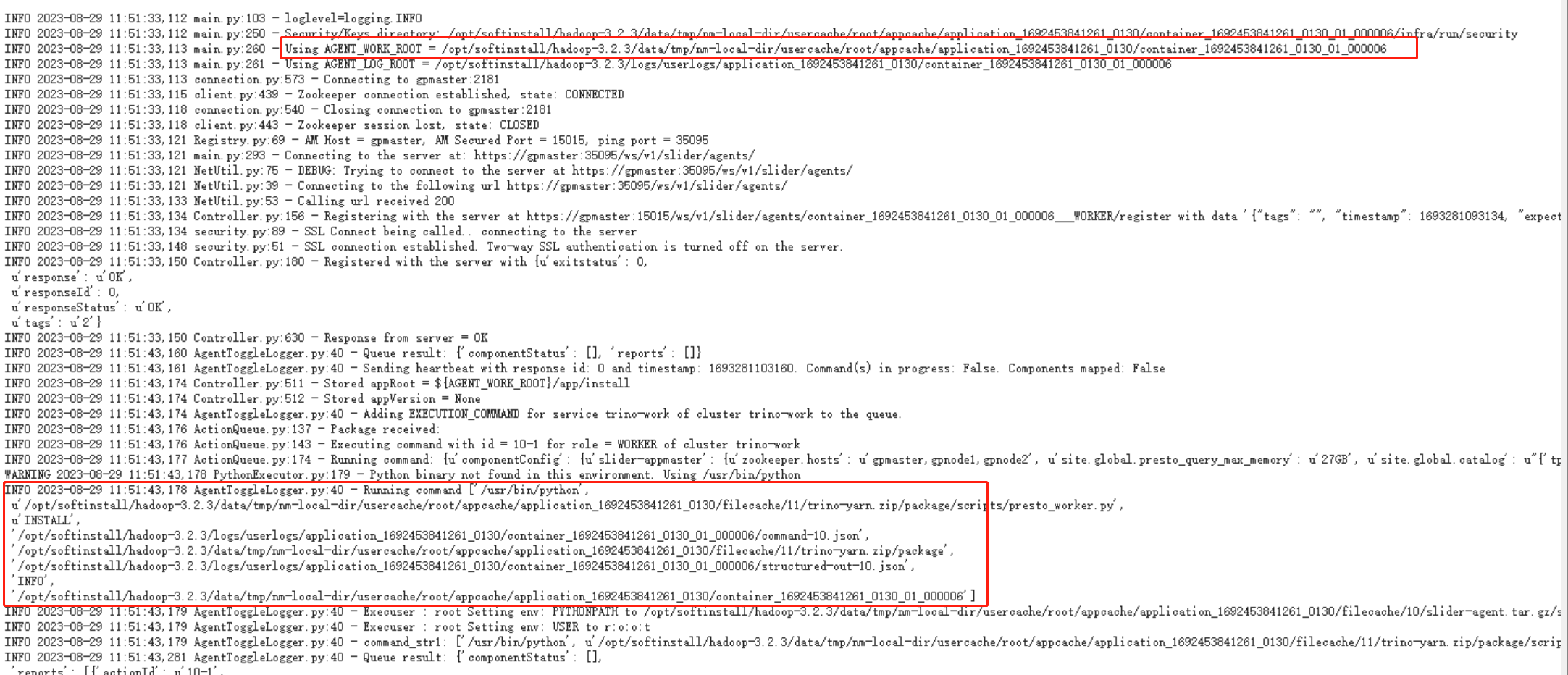
注释掉slider 这部执行语句,让程序空跑,脚本实际并没有执行。
完成1个Work节点的部署就三步,INSTALL--->START---->STATUS
根据具体打印出来的命令手动切换 AGENT_WORK_ROOT 目录,然后手动执行脚本,就能按照实际的报错进行调试,具体参数就是日志里面打印出来的拷贝,给出示例:
[root@gpmaster scripts]# export PYTHONPATH=/opt/softinstall/hadoop-3.2.3/data/tmp/nm-local-dir/usercache/root/appcache/application_1692453841261_0117/filecache/10/slider-agent.tar.gz/slider-agent/jinja2:/opt/softinstall/hadoop-3.2.3/data/tmp/nm-local-dir/usercache/root/appcache/application_1692453841261_0117/filecache/10/slider-agent.tar.gz/slider-agent
[root@gpmaster scripts]# python presto_worker.py INSTALL /opt/softinstall/hadoop-3.2.3/logs/userlogs/application_1692453841261_0117/container_1692453841261_0117_01_000002/command-1.json /opt/softinstall/hadoop-3.2.3/data/tmp/nm-local-dir/usercache/root/appcache/application_1692453841261_0117/filecache/11/trino-yarn.zip/package /opt/softinstall/hadoop-3.2.3/logs/userlogs/application_1692453841261_0117/container_1692453841261_0117_01_000002/structured-out-1.json INFO /opt/softinstall/hadoop-3.2.3/data/tmp/nm-local-dir/usercache/root/appcache/application_1692453841261_0117/container_1692453841261_0117_01_000002
2023-08-28 17:04:39,453 - Directory['/opt/softinstall/hadoop-3.2.3/data/tmp/nm-local-dir/usercache/root/appcache/application_1692453841261_0117/container_1692453841261_0117_01_000002/app/install'] {'action': ['delete']}
[root@gpmaster scripts]# python presto_worker.py START /opt/softinstall/hadoop-3.2.3/logs/userlogs/application_1692453841261_0117/container_1692453841261_0117_01_000002/command-1.json /opt/softinstall/hadoop-3.2.3/data/tmp/nm-local-dir/usercache/root/appcache/application_1692453841261_0117/filecache/11/trino-yarn.zip/package /opt/softinstall/hadoop-3.2.3/logs/userlogs/application_1692453841261_0117/container_1692453841261_0117_01_000002/structured-out-1.json INFO /opt/softinstall/hadoop-3.2.3/data/tmp/nm-local-dir/usercache/root/appcache/application_1692453841261_0117/container_1692453841261_0117_01_000002
2023-08-28 17:04:39,453 - Directory['/opt/softinstall/hadoop-3.2.3/data/tmp/nm-local-dir/usercache/root/appcache/application_1692453841261_0117/container_1692453841261_0117_01_000002/app/install'] {'action': ['delete']}
五、1个机器多个节点冲突解决
1.文件冲突:把trino的配置文件 etc和data 目录都生成到AGENT_WORK_ROOT下,这样就能解决调度到同一台机器上这2个文件冲突的问题。
主要修改params.py
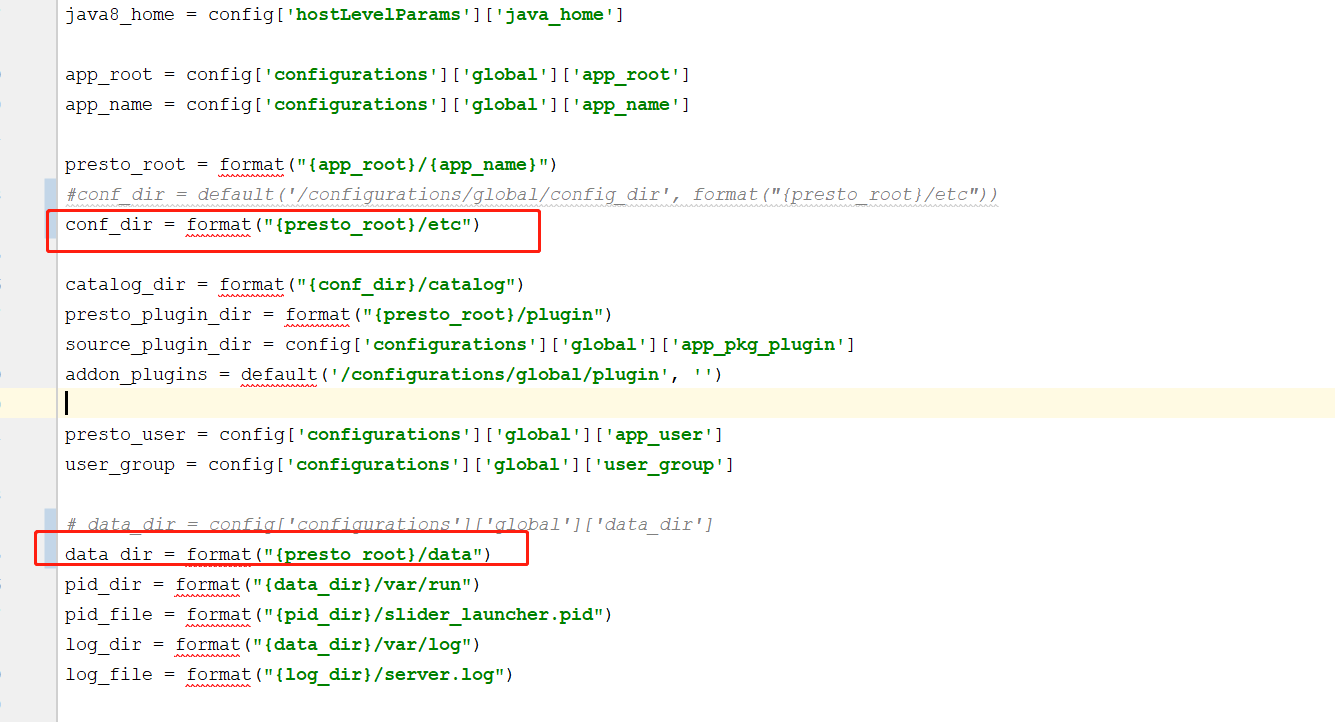
2.端口冲突:加上随机端口配置,注释掉config.properties-WORKER.j2 模板里面的http-server.http.port={{presto_work_port}},增加随机端口的配置写入。
具体参考实现trino on yarn调度到同一机器上多实例端口冲突问题处理_qq_2368521029的博客-CSDN博客
六、非公版Trino-server打包部署
我们对trino的修改过一些功能,所以正常打包的出来的文件并不能适合我们的环境,需要把我们自己的Trino给打包进去。
1.首先正常打包出来的包目录trino-yarn/package/files下就是对应的 trino-server 文件,把我们自己的Trino去掉etc和data目录,打包替换成对应的包
2.修改params.py,configure.py 以及config.properties-WORKER.j2 模板,对应生成自己需要的模板
3.打包重新上传到hdfs指定目录
../bin/slider package --install --name trino --package trino-yarn.zip --replacepkg
trino on yarn的更多相关文章
- 大数据之Yarn——Capacity调度器概念以及配置
试想一下,你现在所在的公司有一个hadoop的集群.但是A项目组经常做一些定时的BI报表,B项目组则经常使用一些软件做一些临时需求.那么他们肯定会遇到同时提交任务的场景,这个时候到底如何分配资源满足这 ...
- [大数据之Yarn]——资源调度浅学
在hadoop生态越来越完善的背景下,集群多用户租用的场景变得越来越普遍,多用户任务下的资源调度就显得十分关键了.比如,一个公司拥有一个几十个节点的hadoop集群,a项目组要进行一个计算任务,b项目 ...
- Node.js包管理器Yarn的入门介绍与安装
FAST, RELIABLE, AND SECURE DEPENDENCY MANAGEMENT. 就在昨天, Facebook 发布了新的 node.js 包管理器 Yarn 用以替代 npm .咱 ...
- 03 Yarn 原理介绍
Yarn 原理介绍 大纲: Hadoop 架构介绍 YARN 产生的背景 YARN 基础架构及原理 Hadoop的1.X架构的介绍 在1.x中的NameNodes只可能有一个,虽然可以通过Se ...
- Spark on YARN的部署
Spark on YARN的原理就是依靠yarn来调度Spark,比默认的Spark运行模式性能要好的多,前提是首先部署好hadoop HDFS并且运行在yarn上,然后就可以开始部署spark on ...
- yarn关于app max attempt深度解析,针对长服务appmaster平滑重启
在YARN上开发长服务,需要注意fault-tolerance,本篇文章对appmaster的平滑重启的一个参数做了解析,如何设置可以有助于达到appmaster平滑重启. 在yarn-site.xm ...
- Spark源码编译并在YARN上运行WordCount实例
在学习一门新语言时,想必我们都是"Hello World"程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapRedu ...
- 配置Spark on YARN集群内存
参考原文:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool 运行文件有几个G大,默 ...
- 【hadoop2.2(yarn)】基于yarn成功执行分布式map-reduce,记录问题解决过程。
hadoop2.x改进了hadoop1.x的架构, 具体yarn如何工作以及改进了什么可以在网上学, 这里仅记录我个人搭建的问题和理解,希望能帮助遇到困难的朋友. 在开始前,必须了解yarn版本的ma ...
- Spark on Yarn 学习(一)
最近看到明风的关于数据挖掘平台下实用Spark和Yarn来做推荐的PPT,感觉很赞,现在基于大数据和快速计算方面技术的发展很快,随着Apache基金会上发布的一个个项目,感觉真的新技术将会不断出现在大 ...
随机推荐
- idea 查看scala源代码
使用idea编写spark程序,想要查看源代码,点进去是compiled code private[sql] def this(sc : org.apache.spark.SparkContext) ...
- Could not resolve com.android.tools.lint:lint-kotlin:26.2.0.
好久没有使用weexplus publish android 打包apk, 今一运行失败了,提示Could not resolve com.android.tools.lint:lint-kotlin ...
- 驱动开发:内核解析PE结构导出表
在笔者的上一篇文章<驱动开发:内核特征码扫描PE代码段>中LyShark带大家通过封装好的LySharkToolsUtilKernelBase函数实现了动态获取内核模块基址,并通过ntim ...
- malloc/free 与 new/delete
malloc/free与new/delete表达式的区别?相同点: 都是用来申请堆空间不同点: 1. malloc/free是库函数; new/delete是表达式 2. malloc开空间时,并不会 ...
- 3 分钟为英语学习神器 Anki 部署一个专属同步服务器
原文链接:https://icloudnative.io/posts/anki-sync-server/ Anki 介绍 Anki 是一个辅助记忆软件,其本质是一个卡片排序工具--即依据使用者对卡片上 ...
- SQL专家云回溯某时间段内的阻塞
背景 SQL专家云像"摄像头"一样,对环境.参数配置.服务器性能指标.活动会话.慢语句.磁盘空间.数据库文件.索引.作业.日志等几十个运行指标进行不同频率的实时采集,保存到SQL专 ...
- Kali下载安装以及基础配置
Kali官网:Kali Linux | Penetration Testing and Ethical Hacking Linux Distribution Kali下载地址:Get Kali | K ...
- python笔记:第六章函数&方法
1.系统函数 由系统提供,直接拿来用或是导入模块后使用 a = 1.12386 result = round(a,2) print(result) > 1.12 2.自定义函数 函数是结构化编程 ...
- CF1654E Arithmetic Operations 题解
摘自我的洛谷博客. 题目让我们求改变数字的最少次数,那我们转化一下, 求可以保留最多的数字个数 \(cnt\),再用 \(n\) 减一下就行,即 \(res = n - cnt\). 我们先考虑两种暴 ...
- 教师节专题:AI互动课来了,即构方案助推在线教育创新升级
打开热门综艺,乘风破浪的姐姐们告诉你"用瓜瓜龙英语给孩子启蒙":走出家门,电梯口.公交站的大幅广告跟你说"2-8岁上斑马". 如果说去年的AI互动课还是浮于媒体 ...