接到一个新需求应该怎么做?(V1.0)
接到一个新需求应该怎么做?(V1.0)
1 背景
在做业务研发的时候,经常会接到一些 产品需求/技术需求, 无论需求大小,都需要一套可以重复使用的方法论,来保证整个项目的正常交付,这篇思考就是总结梳理抽象出这么一套方法论。
从毕业工作到现在,没有真正思考过这类问题,一直觉得我的工作就是每天都有新的挑战(这也许是我能持续在这个行业工作的原因),但最近思考了下:难道真的每次都是“新挑战“?在这中一定存在者解决问题的方法论,而本篇文章目的就是总结出一个「当接到一个新的需求时,怎么做?」这个问题的方法论。
v1.0 是版本,意思是后面还会有更高的版本,记录者关于这个问题,新的总结和思考。
2 思考方向
我觉得可以大致分为两个方向:(1)项目管理方向。(2)技术实现方向。
顾名思义,项目管理是为了保障整个项目能够顺利执行交付;技术实现是为了保障交付需求的质量。接下来我们一个一个的分析。
3 项目管理
前两天看到了一篇文章关于开放协作的一些思考,看完之后就在想在一个互联网公司有没有可以从中借鉴的地方,发现其实互联网公司项目管理制度跟开源社区的项目管理有一些相似性(准确的说,开源社区的项目管理挑战性更大)。
参考 关于开放协作的一些思考 中的RACI模型,我觉得可以分成如下几个阶段。
3.1 明确参与人员
这个需求需要哪些人参与进来,可能有本团队的人,也可能需要其他团队的人一起协助一起做。比如:正常需求可能需要后端团队,前端团队,测试团队,产品团队等 相关人参与,具体需要哪些领域团队的人参与进来,要仔细明确下来。
3.2 明确人员分工
参考关于开放协作的一些思考里面的RACI模型,这里面需要
(1)明确这个项目的主要负责人,即A这个角色。
(2)明确参与到这个项目里每个团队的对接人,即R和R的Leader。
(3)明确遇到问题可以咨询的人,不一定在参与人员名单中:比如技术架构专家,即C这个角色。
(4)明确哪些人是需要被通知进度的,比如技术/产品老板,比如各个团队的leader,即I这个角色。
3.3 明确里程碑
在需求迭代的过程中,应该不能只有一个交付时间,比如:小需求应该有个开发完成时间,联调时间,提测时间,测试开始时间,测试完成时间,产品验收时间,代码上线时间等。
大需求可能会有更细化的小功能迭代时间,最好设置一些明确工作进度的里程碑,这个里程碑是要根据参与人员:至少是R的leader和A讨论出来的(有一定的信服力),并且同步公开到整个项目组里面的。
3.4 进度汇报和问题反馈与解决
首先,整个项目要在关键时间点汇报进度,关键时间点不仅仅是里程碑上定好的时间点,更要有周期性的时间点:比如 每日 或者 每三天 或者 每周 定期汇报当前进度,汇报内容包括当前处于里程碑的哪一部分,距离下一个里程碑是否能够正常交付,如果不能正常交付,遇到了什么问题,问题的解决方案大概是怎么样的,预计交付的时间点是什么时候。这一阶段主打一个真实,公开。当遇到问题的时候,可以咨询RACI中C的角色,并对讨论内容和解决方案进行记录,并公开在整个项目的文档空间里面。
这里比较关键的一点是问题反馈和解决需要记录 和 信息的公开,比如:要公开参与人员的变更、公开里程碑的调整、可以说所有一切不符合预期的变更最好记录并公开出来。
4 技术实现
技术实现是为了能够让项目保质保量的按时交付,它没有明确的方法论,只有个大体的方向,而且可操作空间比较大,我们从一个较全面角度来看。
大致可以分为下面几个步骤:
- 需求分析
- 功能的基本设计
- 优化
- 保障
- 提效
4.1 需求分析
需求分析的产出目标是:
- 明确产品新增加的功能点是什么。
- 明确产品需求的合理性。
- 明确需求涉及到的团队。
- 明确相关的团队做什么事情。
需求分析可能需要做下面几个事情 - 罗列需求点:并且和需求提出者进行沟通,最终确认功能点没有遗漏。
- 明确每个团队内部需要提供的能力:这个放在需求分析阶段的目的是有可能需求点由于团队与团队之前的扯皮而流产。
4.2 功能基本设计
假如我们是实现大需求中一部分功能的小团队。在明确我这个团队需要提供的能力之后,需要做的就是这些能力的实现。
在思考做能力实现的时候,如果摸不到头绪,可以遵循三步走策略(1)功能的基本设计;(2)功能再优化;(3)功能稳定性保障;这个小模块主要集中在第一步:功能的基本设计上。
功能的基本设计自底向上大致分为:
- 模型设计 (模型设计可以学习《领域驱动设计DDD》相关的资料。)
- 存储选型 (这里存储选型一般持久化核心存储推荐 mysql)
- 逻辑代码实现 (我之前在 单品活动-C端价格计算代码重构引发的思考 里面思考了下 什么样的业务代码算是好代码 里也提到了,自底向上大概分成四部分(1) 好的模型设计;(2)好的代码分层;(3)好的业务逻辑设计;(4)好的功能实现。)
当然,仅仅做功能的基本实现是不够的,因为业务体量的不同,可能对领域提供的功能性能有一定的要求,比如电商C端的服务功能基本都是要求高QPS,高性能,所以下一步就是做逻辑优化。
4.3 优化
优化的方向也不是无迹可寻的,有一些成熟的架构可以借鉴。
- 如果能力特征是面向B端和C端的,B端重逻辑和多写操作,C端轻逻辑和多读操作,那可以将B端和C端进行CQRS架构改造,我之前做了几次B端和C端的CQRS拆分,可以参考下 :店铺架构CQRS改造 和 单品活动-C端架构演进和稳定性建设
- 如果能力特征是面向复杂搜索的,那可以朝着下面两个方向进行优化
- 将搜索能力托管给ES存储(大数据量,对响应要求不是特别高)
- 将数据内存化,之后结合 lucene 提供搜索能力(数据量不大,但是对响应要求特别高)
- 如果正常结构化数据,但是对rt要求比较高的,可以借助redis做一层缓存
- 如果对图关系比较敏感的,可以借助图数据库,比如:HugeGraph/Neo4j/GDB(阿里云)/BGraph(百度云)。
- 如果具有时许特点并且进行时序统计的,可以借助主流的TSDB
总结一下,优化大概的方向是:在核心存储是mysql的前提下,针对不同场景的特征,选择一套针对性的存储组件,然后在做数据查询链路上加一层缓存设计。
4.4 保障
每个项目对保障的要求级别是不一样的,比如有的项目只是个临时项目,出现问题对整个业务影响不大,甚至可以在出现问题的时候摘除此项目,即这种项目是可以降级的,这种保障级别就比较小,在保障上就不需要过多花费精力。如果项目是关键链路上且不能降级的(比如电商领域的商品中心),这种就需要在保障上多花费一些“成本”,而这些“成本”往往都是值得的。
从历史经历中得到的教训:在一个业务正常发展的公司,核心服务出现稳定性故障,造成的损失,往往比这个核心服务所使用的资源成本多的多。
保障大体可分为三个方向:
- 服务稳定性保障
- 数据一致性保障
- 逻辑准确性保障
下面,逐一介绍下这三个方向可以做的事情。
(1)服务稳定性保障
往往可以通过这几个手段来提高服务的可用性和稳定性(从小到大,从简单到复杂):(1)限流熔断。(2)数据冗余。(3)责任拆分。(4)异地多活。
- 熔断限流:基本的保障手段,建议每个需要进行保障的能力都要具备。当流量超过服务能提供能力的一定限制时,对超过的量进行阻断。
- 数据冗余:最简单的数据冗余是将持久化的数据冗余到内存中(比如本机内存、Redis缓存等),在这里要注意:缓存雪崩、缓存击穿、缓存穿透、热点缓存等相关问题,在缓存的使用方法上,后面会单独写一篇文章进行总结。
- 责任拆分:比如CQRS的架构改造(感兴趣的可以看这篇文章 店铺架构CQRS改造 ),责任拆分的同时,一般会掺杂数据冗余一起操作。
- 异地多活:这种模式一般分为读多活和读写多活,需要公司的运维团队一起支持。
(2)数据一致性保障
当做数据冗余的时候,就会出现数据副本,而保障副本和主数据的最终一致性是主要目标。
做数据一致性的时候,可以从 发现数据不一致 和 恢复到数据一致 两个角度来思考。如何发现数据不一致呢?可以采用扫描最近变化的数据,进行多数据源的比对。也可以采用对变更方的消息通知进行延迟之后,进行多数据源的比对。而发现数据不一致之后,也可以使用这种机制进行多数据源的最终一致性同步,以某一个数据源为准,将数据同步给其他数据源。如果出现大量数据不一致的问题,也要有手段针对性的全量数据触发这种数据同步。
最终数据一致性可以是较实时的(在电商场景中,比如是秒级别的),也可以是准实时的(比如是分钟级),还可以是不实时的(比如是天级别),推荐这三种手段都做。
(3)逻辑准确性保障
如何发现逻辑错误?这里不负责任的做法是通过业务/用户的反馈,但我们希望研发是第一批知道出了问题的人,所以要对功能做不同维度的监控,这里监控不单单是结果层面的,也要有过程层面的,研发要对每一项监控指标敏感。打个比方:如果你在做一个支付系统,不单单要监控支付成功、支付失败,还要监控微信支付成功、失败,支付宝支付成功、失败,支付金额在 0~10元档的,10~100元档的 等等。要求保障级别越高的功能,监控维度就要越全面。
上面说的都是发生了逻辑问题之后才被研发感知到,而我们要尽可能把发现问题的阶段前移到功能上线之前。单靠覆盖性测试可能会达到一定的保障效果,但由于测试样本是人准备的,无法保证人不会犯错误,所以建议在覆盖性测试之后,也要走一遍线上的流量验证,最简单的做法是对线上代码执行的过程数据进行保存,并将数据回放到开发代码里,验证结果是否一致。(这类系统有很多相关文章,可以在网上搜索关键词:流量回放系统)
4.5 提效
功能顺利上线,做完一定的稳定性保障之后,接下来可以做一些锦上添花的事情,目标是为了提高研发的开发、查问题的效率,解放研发自身。比如做一些业务工具开放给产品或业务,或者在代码运行过程层面做一些数据快照并持久化起来,帮助研发自身查问题等等,这里根据不同的业务可想想的空间比较大,不做方向上的限制。
5 总结
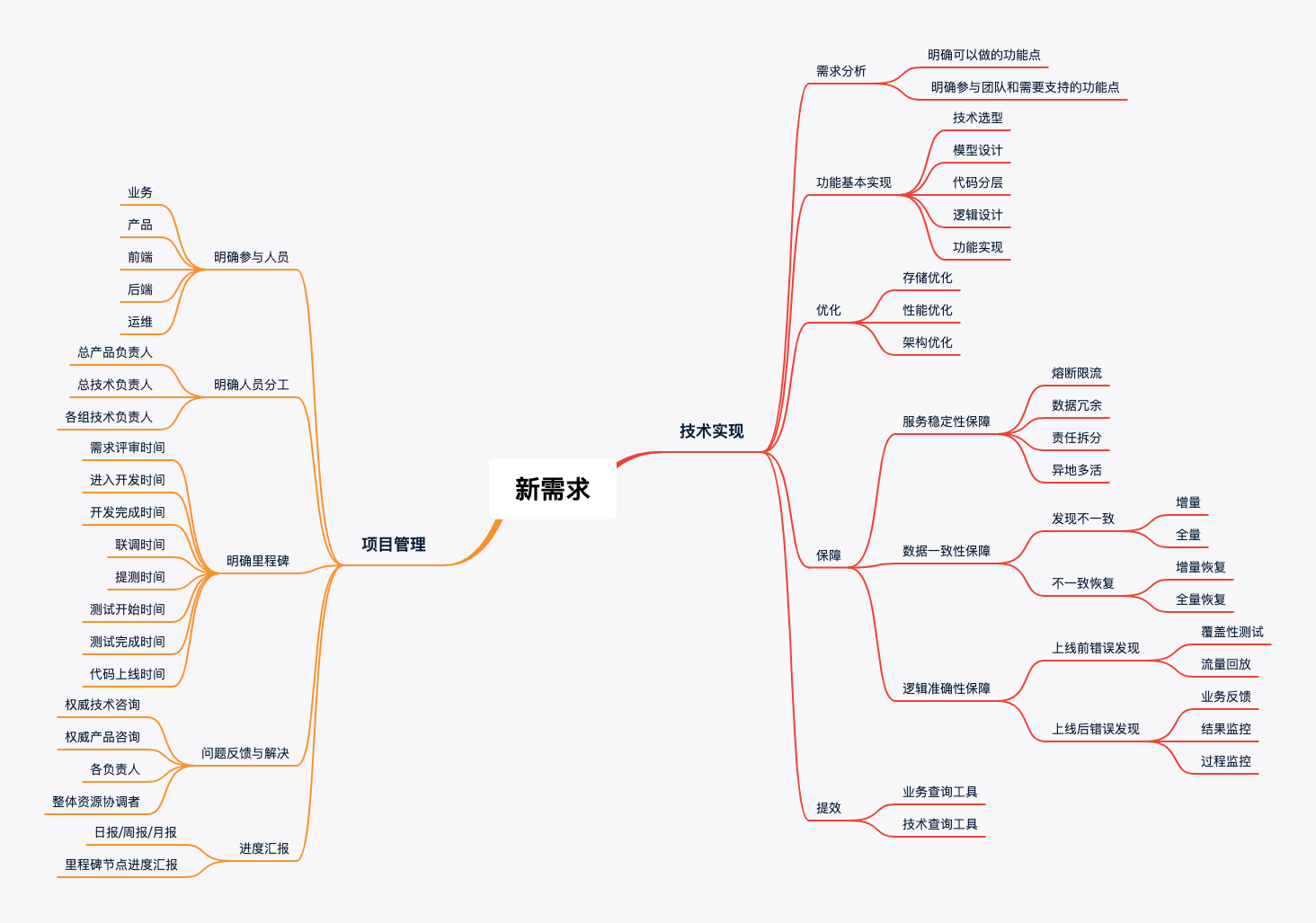
这里是V1版本的导图,后面会持续不断完善出新的版本。
接到一个新需求应该怎么做?(V1.0)的更多相关文章
- 新课程网上选课系统V1.0—适用于中小学校本课程选课、选修课选课
学校要开设选修课,人工选课实施了两年,耗时耗力,于是打算用网上选课,在网上搜索了一番,没多少实用的,有一个网上用的比较多的,功能太简单了,于是打算自己开发一个,功能参考了部分学校的功能,也有基于Aja ...
- YC-Framework版本更新:V1.0.9
分布式微服务框架:YC-Framework版本更新V1.0.9!!! 本文主要内容: 1.V1.0.9版本更新主要内容 2.YC-Framework新的征程 一.V1.0.9版本更新主要内容 (1)接 ...
- 做一个新产品需求,体验的分析文档?(例:喜马拉雅FM)
2.1 战略层 2.11 产品定位: 一款产品覆盖面广,收听节目种类齐全,资源丰富的电台APP. 以PGC为主流,通过合作方式吸纳专业的电台人,节目人,行业名人分享内容. 融合UGC,满足人们在空闲时 ...
- 【spring cloud】子模块module -->导入一个新的spring boot项目作为spring cloud的一个子模块微服务,怎么做/或者 每次导入一个新的spring boot项目,IDEA不识别子module,启动类无法启动/右下角没有蓝色图标
如题:导入一个新的spring boot项目作为spring cloud的一个子模块微服务,怎么做 或者说每次导入一个新的spring boot项目,IDEA不识别,启动类无法启动,怎么解决 下面分别 ...
- Git库搭建好之后,当要提交一个新的文件,需要做的是3个步骤
Git库搭建好之后,当要提交一个新的文件,需要做的是3个步骤 1.git add new.txt 2.git commit -m "add a new file" 3.git pu ...
- 在做爬虫或者自动化测试时新打开一个新标签页,必须使用windows切换
在做爬虫或者自动化测试时,有时会打开一个新的标签页或者新的窗口,直接使用xpath定位元素会发现找不到元素,在firefox中定位了元素还是找不到, 经过多次发现,在眼睛视野内看到这个窗口是在最前面, ...
- 使用layui 做后台管理界面,在Tab中的链接点击后添加一个新TAB的解决方法
给链接或按钮 添加 onclick="self.parent.addTab('百度','http://www.baidu.com','icon-add')" 如: <a h ...
- [PaPaPa][需求说明书][V1.0]
前 言 嘿嘿!嘿嘿!嘿嘿嘿嘿!大家好,我是XXX! 经过30K大大几篇文章在博客园怒刷存在感之后,咱们的小群瞬间从70人的数量增加到了将近400人.一下子加进来这么多人我还真是有点不适应啊! 我知 ...
- 《次元唤醒 需求规格说明书v1.0》
一.团队分工 组员 工作比例 参与范围 王诚荣 17% 原型设计,需求规格说明书整合,LOGO设计 马祎特 22% PPT制作,演讲,博客模板,用户描述 陈斌 21% 评审表格制作,引言,项目描述,功 ...
- 痞子衡嵌入式:kFlashFile v1.0 - 一个基于Flash的掉电数据存取方案
大家好,我是痞子衡,是正经搞技术的痞子.今天给大家带来的是痞子衡的个人小项目 - kFlashFile. 痞子衡最近在参与一个基于 i.MXRT1170 的项目,项目有个需求,需要在 Flash 里实 ...
随机推荐
- Selenium - 元素操作(2) - 页面滚动条
Selenium - 元素操作 函数滚动 一般元素定位,元素如果不在浏览器的可视位置(即可见只是不在可视位置),会自动把元素滚动到可视位置,但也有不会自己滚动的(比较少). 那我们就可以用seleni ...
- 【一步步开发AI运动小程序】十、姿态动作相似度比较
随着人工智能技术的不断发展,阿里体育等IT大厂,推出的"乐动力"."天天跳绳"AI运动APP,让云上运动会.线上运动会.健身打卡.AI体育指导等概念空前火热.那 ...
- JavaWeb入门必备JavaEE规范!
前言 对于学习 Java 的同学,大都是 Web 方向的.我们学习 JavaWeb 开发肯定是一个循序渐进的过程,学习前有一些前置知识要掌握,比如 JavaSE 相关知识,HTML.CSS.JavaS ...
- 自然语言处理 Paddle NLP - 词法分析技术及其应用
词法分析就是利用计算机对自然语言的形态(morphology) 进行分析,判断词的结构和类别等."简单而言,就是分词并对每个词进行分类,包括:分词.词性标注.实体识别三个任务 问答 知识图谱 ...
- js实现图片切换效果
用js实现点击按钮,图片切换的效果: 1 <div class="box" id="box"> 2 <div class="img_ ...
- 逍遥自在学C语言 | 指针函数与函数指针
前言 在C语言中,指针函数和函数指针是强大且常用的工具.它们允许我们以更灵活的方式处理函数和数据,进而扩展程序的功能. 本文将介绍指针函数和函数指针的概念,并讲解一些常见的应用示例. 一.人物简介 第 ...
- 文件系统考古 3:1994 - The SGI XFS Filesystem
在 1994 年,论文<XFS 文件系统的可扩展性>发表了.自 1984 年以来,计算机的发展速度变得更快,存储容量也增加了.值得注意的是,在这个时期出现了更多配备多个 CPU 的计算机, ...
- Oracle sql 错误 : ORA-01861: 文字与格式字符串不匹配和日期与字符串互转问题解决
正确的要这样的: public int update(String ceratedate); <update id="update" parameterType=" ...
- P3574 [POI2014] FAR-FarmCraft 吐槽 + 题解
洛谷上面的题解写的真的不太好,有很多错误,我来谈谈自己的理解. 设 \(f[i]\) 表示以 \(i\) 为根节点的子树中(包括节点 \(i\))的所有人安装好游戏所需要的时间(与下面的 \(g[i] ...
- 【Shell】数组
数组 bash 只支持一维数组. 数组下标从 0 开始,下标可以是整数或算术表达式,其值应大于或等于 0. 创建数组 # 创建数组的不同方式 nums=([2]=2 [0]=0 [1]=1) colo ...