数值优化算法-BFGS
参考:
https://www.cnblogs.com/Leo_wl/p/3367323.html
牛顿法:
使用牛顿法优化函数 f(θ) 最小值时,每次计算获得新的\(θ\)值,即\(θ_{k+1}\)为\(θ_k\)的基础上计算所得。
\(g_k\)为\(f(\theta)\)在\(θ_k\)时雅可比向量,\(H_k\)为\(θ_k\)时Hession矩阵,整体的计算式为:
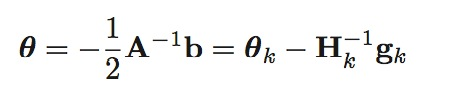
牛顿方法的步骤为:

BFGS算法
Newton算法在计算时需要用到Hessian矩阵H, 计算Hessian矩阵非常费时, 所以研究者提出了很多使用方法来近似Hessian矩阵, 这些方法都称作准牛顿算法, BFGS就是其中的一种, 以其发明者Broyden, Fletcher, Goldfarb和Shanno命名.
BFGS算法使用以下方法来近似Hessian矩阵, Bk≈Hk:
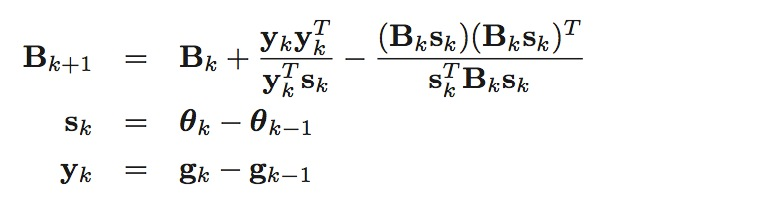
初始时可以取\(B_0=I\)
因为Hessian矩阵的大小为O(D2), 其中D为参数的个数, 所以有时Hessian矩阵会比较大, 可以使用L-BFGS(Limited-memory BFGS)算法来进行优化。
参考文献:
[1]. Machine Learning: A Probabilistic Perspective. p249-p252.
[2]. Wekipedia: L-BFGS
给出python版本调用scipy库进行bfgs的计算:
import scipy
def f(arg):
x1, x2 = arg
y = x1**2 + x2**2
return y, [2*x1, 2*x2]
ans = scipy.optimize.fmin_l_bfgs_b(f, (1000, 1000), maxiter=25)
# ans = scipy.optimize.fmin_l_bfgs_b(f, (1000, 1000), maxiter=2)
print(ans)
运行结果:

本文参考:
出处1:
源作者:Leo_wl
出处:http://www.cnblogs.com/Leo_wl/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
数值优化算法-BFGS的更多相关文章
- 优化算法-BFGS
优化算法-BFGS BGFS是一种准牛顿算法, 所谓的"准"是指牛顿算法会使用Hessian矩阵来进行优化, 但是直接计算Hessian矩阵比较麻烦, 所以很多算法会使用近似的He ...
- paper 8:支持向量机系列五:Numerical Optimization —— 简要介绍求解求解 SVM 的数值优化算法。
作为支持向量机系列的基本篇的最后一篇文章,我在这里打算简单地介绍一下用于优化 dual 问题的 Sequential Minimal Optimization (SMO) 方法.确确实实只是简单介绍一 ...
- 数值最优化:一阶和二阶优化算法(Pytorch实现)
1 最优化概论 (1) 最优化的目标 最优化问题指的是找出实数函数的极大值或极小值,该函数称为目标函数.由于定位\(f(x)\)的极大值与找出\(-f(x)\)的极小值等价,在推导计算方式时仅考虑最小 ...
- 一小部分机器学习算法小结: 优化算法、逻辑回归、支持向量机、决策树、集成算法、Word2Vec等
优化算法 先导知识:泰勒公式 \[ f(x)=\sum_{n=0}^{\infty}\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n \] 一阶泰勒展开: \[ f(x)\approx ...
- SMO优化算法(Sequential minimal optimization)
原文:http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988419.html SMO算法由Microsoft Research的John C. ...
- deeplearning.ai 改善深层神经网络 week2 优化算法 听课笔记
这一周的主题是优化算法. 1. Mini-batch: 上一门课讨论的向量化的目的是去掉for循环加速优化计算,X = [x(1) x(2) x(3) ... x(m)],X的每一个列向量x(i)是 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.6_2.9Momentum/RMSprop/Adam优化算法
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.6 动量梯度下降法(Momentum) 另一种成本函数优化算法,优化速度一般快于标准 ...
- [DeeplearningAI笔记]改善深层神经网络_优化算法2.3_2.5_带修正偏差的指数加权平均
Optimization Algorithms优化算法 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.3 指数加权平均 举个例子,对于图中英国的温度数据计算移动平均值或者说是移动平均值( ...
- 跟我学算法-吴恩达老师(mini-batchsize,指数加权平均,Momentum 梯度下降法,RMS prop, Adam 优化算法, Learning rate decay)
1.mini-batch size 表示每次都只筛选一部分作为训练的样本,进行训练,遍历一次样本的次数为(样本数/单次样本数目) 当mini-batch size 的数量通常介于1,m 之间 当 ...
- 优化深度神经网络(二)优化算法 SGD Momentum RMSprop Adam
Coursera吴恩达<优化深度神经网络>课程笔记(2)-- 优化算法 深度机器学习中的batch的大小 深度机器学习中的batch的大小对学习效果有何影响? 1. Mini-batch ...
随机推荐
- Json输出List集合对象和map对象 JSON格式
Json输出List集合对象和map对象 JSON格式 //Json输出List集合对象 [{"属性1":["值1"],"属性2":&quo ...
- .NET使用原生方法实现文件压缩和解压
前言 在.NET中实现文件或文件目录压缩和解压可以通过多种方式来完成,包括使用原生方法(System.IO.Compression命名空间中的类)和第三方库(如:SharpZipLib.SharpCo ...
- zabbix---监控Oracle12c数据库
使用插件:orabbix用于监控oracle实例的zabbix插件 orabbix插件下载地址:http://www.smartmarmot.com/product/orabbix/download/ ...
- nginx中多个server块共用upstream会相互影响吗
背景 nginx中经常有这样的场景,多个server块共用一个域名. 如:upstream有2个以上的域名,nginx配置两个server块,共用一个upstream配置. 那么,如果其中一个域名发生 ...
- Mysql 聚合函数嵌套使用
Mysql 聚合函数嵌套使用 目的:Mysql 聚合函数嵌套使用 聚合函数不可以直接嵌套使用,比如: max(count(*)) 思路:但是可以嵌套子查询使用(先分组取出count值, 再将count ...
- 在Linux驱动中使用proc子系统
在Linux驱动中使用proc子系统 背景 proc文件系统是个简单有用的东东:驱动创建一个proc虚拟文件,应用层通过读写该文件,即可实现与内核的交互. 本文适用于3.10以后的内核,v3.10以前 ...
- STM32的内存管理(转)
背景 这里针对STM32F407芯片+1M外部内存的内存管理!(全篇是个人愚见,如果错误,请不吝指出!) 定义 首先,定义3个内存池,分别是内部SRAM,外表SRAM和CCM:通过指定内存中的绝对地址 ...
- FFmpeg新旧接口对照使用一览
背景 根据例程学习调用ffmpeg 库方法的时候,发现了一堆警告. main.cpp:81:37: warning: 'AVStream::codec' is deprecated [-Wdeprec ...
- 网络OSI七层模型及各层作用 tcp-ip
背景 虽然说以前学习计算机网络的时候,学过了,但为了更好地学习一些物联网协议(MQTT.CoAP.LWM2M.OPC),需要重新复习一下. OSI七层模型 七层模型,亦称OSI(Open System ...
- Chrome插件:Postman Interceptor 调试的终极利器
今天给大家介绍一款非常实用的工具--Postman Interceptor. 这个工具可以捕捉任何网站的请求,并将其发送到Postman客户端. 对于经常和API打交道的程序员来说,Postman I ...