多巴胺所表达的prediction error信号
Dopamine reward prediction-error signalling: a two-component response (Wolfram Schultz; NATURE REVIEWS | NEUROSCIENCE)
中脑的多巴胺系统(SN、VTA)、纹状体、OFC、杏仁核等部位都会表达诸如奖赏的量、可能性、主观价值、效用、风险等信号。
在SN和VTA里面,大部分的多巴胺神经元都会通过一个短暂的Phasic的反应(一过性的反应)来编码temporal reward prediction error,即表达期待的奖赏与现实可得到的奖赏之间的差值。这一脑细胞的活动信号,刚好跟强化学习里面的prediction error的功效是一致的。
多巴胺细胞按照其反应的速度或模式来分,会有三种亚型:第一种是快速的(Phasic的),在刺激出现之后100、200毫秒即会反应的亚秒级的多巴胺信号;第二种是更慢的,会在刺激出现之后10来分钟左右才会得到最强烈的信号;第三种是Tonic,它是与Phasic的反应相对的,不是突发的一过性信号,而是始终存在的持续性的信号。
这三种信号之中,只有亚秒级的多巴胺信号编码的是prediction error的信息,其余的两种则会表达压力、注意力、运动等信息。
并且,这种亚秒级的多巴胺信号会包含两个成分。下图中0秒的位置代表一个刺激的出现的话,第一个成分是下图中蓝色的部分,是对于突然出现刺激的反应,接下来这个反应会消失,取而代之的是红色部分,表达的是奖赏的价值的信号。
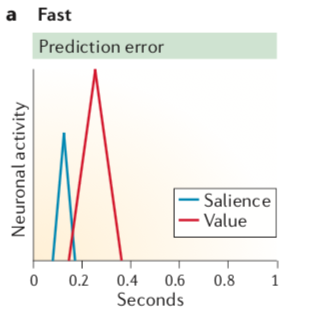
这片Review文章就是来具体考察多巴胺细胞的这种Phasic的反应的,它的初期成分是无差别地检测出潜在的奖赏(包含刺激本身是厌恶的或者中性的情况),后期成分是表达价值的信息的。并且这一表示“奖赏”的PE信号实际上可能是编码“效用”(Utility)的PE的信号。
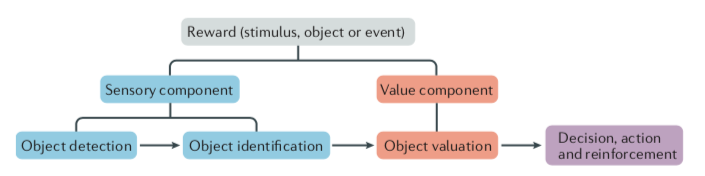
奖赏首先是通过其物理特性(大小、形状、颜色等Physical Salience)来让人感知到,这就是初期成分的来源,之后进一步与已知的东西进行比较,判断其是否是新奇的(Novelty Salience)或是惊讶的(Surprise Salience),等这一判别过程完成之后,才会进行价值评估(Valuation),价值将奖赏和其他的物体或是刺激区分了开来。价值因其能激发人的动力(Motivational Salience)所以有价值的东西才能吸引人的注意。
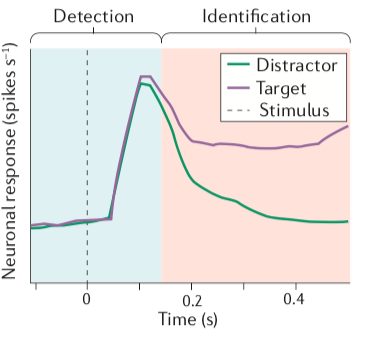
然而,这一先检测刺激的有无,然后才对价值进行区分的逐级处理反应模式并非局限于多巴胺细胞,比如在前额叶的Frontal Eye Field(FEF)中也有类似的反应。
这是让猴子来看两种刺激,但只追踪其中某个目标,刚开始的时候不论是要追踪的目标还是错误目标,FEF的神经元都会对他有反应(下图的绿线和紫线的高峰位置),在刺激出现大约150ms之后才会对要追踪的和不要追踪的目标产生差异性的反应。如果是看到了要追踪的目标则神经元会持续活跃(紫色),反之则开始沉默(绿色)。
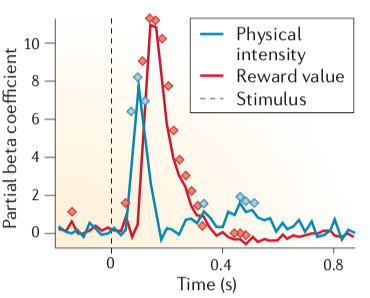
对于多巴胺细胞而言,如果仅仅是使用简单的、快速呈现的刺激(一个可以获得奖赏、一个不可以),就很难发现它会存在这种层级式的反应,所以要不然用统计的方法(计算偏回归系数),要不然就把刺激的处理时间延长,从而区分出这两个不同的信号。如下图中将多巴胺细胞的反应区分成对于物理性刺激的反应(蓝色)和对于奖赏价值(红色)的反应的两个成分。
有些多巴胺神经元不存在或者只是存在较弱的初期成分,对于存在初期成分的神经元来说,各种感官刺激形式(视觉、听觉、味觉等)以及不论是奖赏还是可预测奖赏的刺激、或是没有奖赏的刺激、厌恶性刺激以及预测奖赏会消失的刺激都会激发它们初期成分的反应。初期成分的反应对于刺激的出现时间是极为敏感的,因此它正是在编码时序预测误差(temporal prediction error)。
初期成分的强弱会受到一些因素的左右。比如,
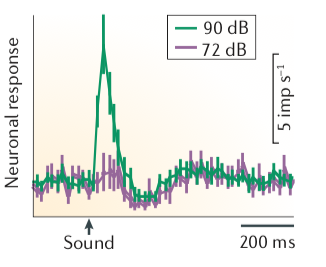
- 更强的刺激会带来更强的多巴胺发放(下方第一张图中90分贝就比72分贝要引发更强的反应)。弱的物理刺激只会诱发很小的或根本不引发多巴胺的发放(除非它们跟奖赏连在一起)。
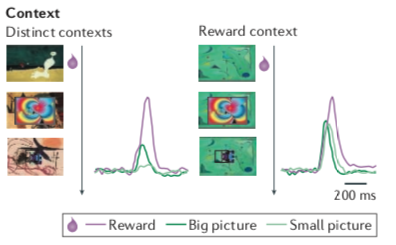
- 环境(context)的作用:不跟奖赏联系在一起的刺激只会引发很小的多巴胺活动,但是当它出现在曾经获得过奖赏的环境中时就会有效地引发多巴胺的活动(下方第二张图种右边的三个绿色背景的图案中,因为最上面第一跟奖赏相联系,引发了右边紫色曲线代表的多巴胺的活动,所以第二个和第三个的图案突然也会一定程度引起右边深绿色和浅绿色代表的多巴胺的活动;与之相对,左边的竖着的三张图,因为没有相同的背景,所以除了直接跟奖赏相联系的第一张图能引发强烈的多巴胺活动之外,其余两张图能因为的活动相对就比较小了)。可能神经元是被环境所指导的,只要是在可能获得奖赏的环境中,一旦出现一个刺激,在还没辨认清楚这个刺激是什么的时候就会开始发放,直到能确认某个刺激确实不是跟奖赏联系在一起的刺激。
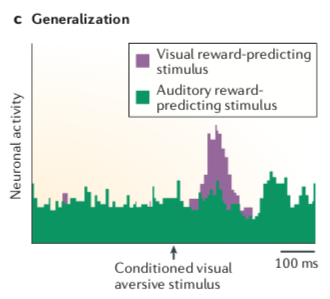
- 刺激之间的物理相似度:某个刺激跟奖赏相连,那么跟这个刺激长得差不多的刺激也会增强多巴胺的初期成分,这一过程就是“泛化(Generalization)”。比如在一堆可以预示着奖赏的声音刺激中,穿插着呈现一个图形刺激,并且这个图形刺激是跟厌恶性的东西(Air-Puf,用风吹眼睛)相连的,这一代表着厌恶的图形刺激只能激活16%的多巴胺神经元,但是如果把预示着奖赏的刺激从声音也换成图形,这时候,代表厌恶的图形刺激会激活65%的多巴胺神经元(下面第三张图中活动比绿色更强烈的紫色的部分)。也就是说,不跟奖赏联系在一起的刺激如果其物理上的(外观上的)相似度和代表奖赏的刺激越接近的话,也就越能引起更强的多巴胺的反应。
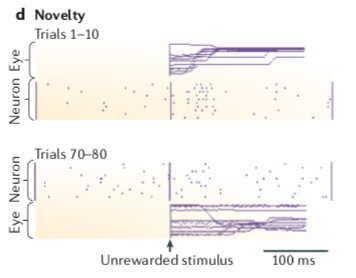
- 新奇的刺激也能激发多巴胺神经元的活动。比如下方第四张图中,新奇的刺激是在一个动物面前突然打开一个空盒子的门,图中最中间的竖线代表打开门的时间点,如果是上半部分(即动物前10次见到这种情况),神经元会在经历打开门的动作之后变得很活跃(更多的紫色的点),但是当动物习惯之后(第70~80次经历相同的情况),多巴胺神经元在看到打开门的动作之后的反应就恢复正常了。但是如果物理性的刺激很弱的话,即便是头一次见到也不会激发多巴胺的反应(好比在很安静的环境中,即便突然出现蚊子哼的声音也并不能吓我们一跳)。
这几个能促进多巴胺发放的情况的共性是:这些刺激代表着潜在的奖赏;更强烈的刺激(突然发生的一件事)可能预示着奖赏的存在,错过了它可能就会错过获得奖励,所以多巴胺神经元会对它有反应。那些跟已知的能获得奖赏的刺激长得很像的刺激,或者是新刺激出现在曾经过得过奖赏的环境的情况,更是预示着它们有更高的可能性会带来奖赏。所以多巴胺的初期成分就已经是为了获得奖赏而做好准备了。
突出性(Salience)会诱发多巴胺反应的初期成分,但这基本上仅限于刺激是奖赏性的时候,因为惩罚(Punisher)、负向奖赏预测误差(Nagtive Reward PE)和条件性的奖赏抑制因素(conditioned reward inhibitors)几乎都不会诱发这种成分(但是新奇或惊讶的刺激可以)。
无分别初期成分的优势:它并不是对于情况的误判,而是可以避免错过任何可能带来奖赏的东西。它有助于增强奖赏用来促进学习和行动的能力。更强的突出性可以带来更快的学习(Attentional Pearce–Hall learning rule),可能可以促进后续的奖赏价值评估过程,从而可以增强行为的准确度。这种出现得极早的初期成分可以让后续的反应变得更快,但是一旦发现刺激实际上没有价值的时候,后续的行动也仍然是来得及被取消的。
有分别后期成分的作用--价值评估:如果刺激代表的实际价值高于预期的话,多巴胺的后期成分就会产生正向预测误差信号(Positive PE),即多巴胺细胞会更活跃;如果刺激的价值低于预期,则产生负向预测误差信号(Negative PE),多巴胺细胞的活动会减弱;跟预期相同的话,则活动程度不变。而这正是Rescorla–Wagner model(这一模型解释了它之前无法解释的Blocking Effect,即比如在经典条件反射中,巴浦洛夫的狗知道铃声可以预测肉,所以听到铃声会流口水,之后如果每次出现铃声的时候也同时亮一个灯,虽然灯也可以预示着肉的到来,但是狗不会学会灯预示着肉这条规则,这个现象在经典理论中无法解释,因为经典理论认为既然灯能预测肉,它的效果跟铃声能预测肉是一样的,为什么狗单独看到灯不会流口水。但Rescorla–Wagner用他们的模型说明了,如果铃声能100%预测肉的出现,那么狗只通过铃声就可以预测未来,无需再加入灯的因素;学习是要靠PE来促进的,在刚开始用铃声训练的那时候狗根本不知道铃声后面居然有肉,所以产生了预测误差,肉让狗感到惊讶,但是等狗掌握了这一规则,他已经不会为铃声以及铃声加灯光后会出现肉的现象感到惊讶了,所以就不再学习了)的强化学习中至关重要的误差要素。(有必要参考这篇文章去理解条件反射是如何形成的The Origins and Organization of Vertebrate Pavlovian Conditioning,预测奖赏的过程是一个根据概率进行推理的过程)
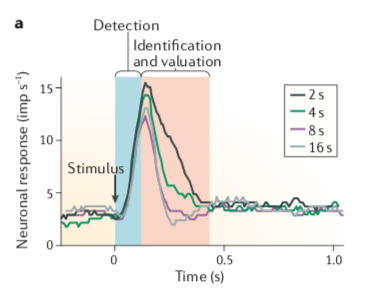
主观价值:价值必然是主观的,但是标志着期待的奖赏的价值的多巴胺信号究竟是表示主观价值还是客观价值则不明朗。为了区分是主观还是客观价值,可以这样,给出两种口味不同但客观价值相等的奖赏(比如黑加仑汁和橙汁)让猴子选择,如果猴子喜欢黑加仑汁,这证明对它来说黑加仑汁的主观价值更高。或者给予动物有风险的和无风险的两种选择,有风险的选择是果汁时多时少,无风险的是每次的量都相同,但这两种选择的平均值都是一样的,动物如果喜欢有风险的选择的话,也证明风险的选项对它的主观价值更高。动物的这种喜好甚至是传递性的,即,喜欢A胜过B,喜欢B胜过C,那么动物在A和C两者之间也会选择A的。多巴胺神经元会在选择喜欢的果汁时候发放更强,这表明它是编码主观价值的。另一个区分主观与客观价值的方法是时间贴现(Temporal discounting),奖赏的价值随着等待时间(delay)增加而减少。如下图所示,刺激之后只要等待2秒(黑色)就能获得奖赏时的多巴胺发放强度比等待16秒(灰色)要强。
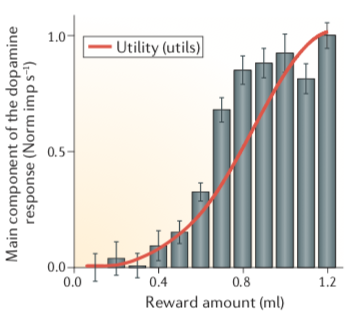
效用(Utility):经济学中对于奖赏的主观价值的定义就是效用。在某个特定时间内(比如出现刺激后的200ms内)的动作电位的数量其实就可以量化猴子的某个神经元认为该刺激所具有的(主观)价值。经济学理论中认为效用可以通过加入风险性回报选项的实验进行计算。导入风险的最简单的办法是采用等概率赌博(小的回报和大的回报以相同概率出现,即,一半一半),然后让动物选择是参加这种赌博还是每次拿一笔固定的回报(无风险),如果固定回报很小而参加赌博可以发一大笔横财的话动物会选择参与赌博,在固定回报上升到某一程度可以让动物以相同概率在赌博和固定回报中选择、不偏好赌博的时候(即达到确定性等价=certainty equivalents),所有的确定性等价的值可以被拿来构建效用函数了。在估计出下图中红色曲线表示的效用函数后,就会发现多巴胺的PE信号是跟效用函数相关的:看红色曲线,在奖赏量较低,在0.1到0.4ml的果汁的时候,多巴胺发放量较少,同时效用函数值也很低,这意味着果汁的主观价值很低,此时动物就会偏向去选择冒险性的选项;随着奖赏的进一步增多,红色曲线变陡,此时效用急升,但是在奖赏到达一定高度,大约1ml之后,效用函数又开始变得平缓,此时更多的奖赏也不会带来更大的效用了(安全的奖赏已经足够,所以更不愿去冒险了)。灰色的柱状图代表的多巴胺的发放模式跟红色曲线的趋势是一致的。
多巴胺所表达的prediction error信号的更多相关文章
- Understanding dopamine and reinforcement learning: The dopamine reward prediction error hypothesis
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Abstract 在中脑多巴胺能神经元的研究中取得了许多最新进展.要了解这些进步以及它们之间的相互关系,需要对作为解释框架并指导正在进行的 ...
- Deep and Beautiful. The Reward Prediction Error Hypothesis of Dopamine
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Contents: Abstract 1. Introduction 2. Reward-Prediction Error Meets D ...
- 【转载】Chaotic Time-Series Prediction
原文地址:https://cn.mathworks.com/help/fuzzy/examples/chaotic-time-series-prediction.html?requestedDomai ...
- 随机森林之oob error 估计
摘要:在随机森林之Bagging法中可以发现Bootstrap每次约有1/3的样本不会出现在Bootstrap所采集的样本集合中,当然也就没有参加决策树的建立,那是不是意味着就没有用了呢,答案是否定的 ...
- APUE学习笔记——10.11~10.13 信号集、信号屏蔽字、未决信号
如有转载,请注明出处:Windeal专栏 首先简述下几个概念的关系: 我们通过信号集建立信号屏蔽字,使得信号发生阻塞,被阻塞的信号即未决信号. 信号集: 信号集:其实就是一系列的信号.用sigset_ ...
- Curiosity-Driven Learning through Next State Prediction
Curiosity-Driven Learning through Next State Prediction 2019-10-19 20:43:17 This paper is from: http ...
- 【转载】 准人工智能分享Deep Mind报告 ——AI“元强化学习”
原文地址: https://www.sohu.com/a/231895305_200424 ------------------------------------------------------ ...
- 论文翻译:2020_Joint NN-Supported Multichannel Reduction of Acoustic Echo, Reverberation and Noise
论文地址:https://ieeexploreieee.fenshishang.com/abstract/document/9142362 神经网络支持的回声.混响和噪声联合多通道降噪 摘要 我们考虑 ...
- iOS开发之ReactiveCocoa下的MVVM(干货分享)
最近工作比较忙,但还是出来更新博客了,今天给大家分享一些ReactiveCocoa以及MVVM的一些东西,干活还是比较足的.在之前发表过一篇博文,名字叫做<iOS开发之浅谈MVVM的架构设计与团 ...
- RAC学习笔记
RAC学习笔记 ReactiveCocoa(简称为RAC),是由Github开源的一个应用于iOS和OS开发的新框架,Cocoa是苹果整套框架的简称,因此很多苹果框架喜欢以Cocoa结尾. 在学习Re ...
随机推荐
- C++(继承)
继承 struct Person { int age; int sex; }; struct Teacher { int age; int sex; int level; int classId; } ...
- 洛谷 Luogu P1038 [NOIP2003 提高组] 神经网络
这题看着很吓人实则很简单.求输出层,正着求很麻烦,因为知不道谁连向这个点,所以可以反向建边,反着求. 拓扑+dfs,时间复杂度 \(\text{O(n + m)}\) #include <ios ...
- 2023-08-02:给定一棵树,一共有n个点, 每个点上没有值,请把1~n这些数字,不重复的分配到二叉树上, 做到 : 奇数层节点的值总和 与 偶数层节点的值总和 相差不超过1。 返回奇数层节点分配
2023-08-02:给定一棵树,一共有n个点, 每个点上没有值,请把1~n这些数字,不重复的分配到二叉树上, 做到 : 奇数层节点的值总和 与 偶数层节点的值总和 相差不超过1. 返回奇数层节点分配 ...
- 《深入理解Java虚拟机》读书笔记:判断对象是否存活
本节内容的概要如下; 对象已死吗? 一.判断对象是否存活的算法 1.引用计数器算法 给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1:当引用失效时,计数器值就减1:任何时刻计数器为0 ...
- 1.0 Python 标准输入与输出
python 是一种高级.面向对象.通用的编程语言,由Guido van Rossum发明,于1991年首次发布.python 的设计哲学强调代码的可读性和简洁性,同时也非常适合于大型项目的开发.py ...
- 【JMeter】常用线程组设置策略
常用线程组设置策略 目录 常用线程组设置策略 一.前言 二.单场景基准测试 1.介绍 2.线程组设计 3.测试结果 三.单场景并发测试 1.介绍 2.线程组设计 3.测试结果 四.单场景容量/爬坡测试 ...
- PhotoShop Beta(爱国版)安装教程-内置AI绘画功能
PS beta版安装教程 Window和Mac版都有,里面内置AI绘画功能 ps Beta版真的太爽了,今天来和大家分享下安装教程. 很多人拿这资料卖5块 9.9 19.9,球友们直接用,建议赶紧装, ...
- 《Kali渗透基础》08. 弱点扫描(二)
@ 目录 1:OpenVAS / GVM 1.1:介绍 1.2:安装 1.3:使用 2:Nessus 2.1:介绍 2.2:安装 2.3:使用 3:Nexpose 本系列侧重方法论,各工具只是实现目标 ...
- 获取API接口返回的商品详情数据后该如何使用
获取API接口返回的商品详情数据后,我们可以使用以下方式将其处理和利用: 数据展示:我们可以将API接口返回的商品详情数据以列表.表格.图形等形式展示给用户,以便他们更好地了解商品的基本信息.特征.评 ...
- 基于velero及minio实现etcd数据备份与恢复
1.Velero简介 Velero 是vmware开源的一个云原生的灾难恢复和迁移工具,它本身也是开源的,采用Go语言编写,可以安全的备份.恢复和迁移Kubernetes集群资源数据:官网https: ...