[转帖]《Linux性能优化实战》笔记(一)—— 平均负载
最近在看极客时间的《Linux性能优化实战》课程,记录下学习内容。
一、 平均负载(Load Average)
1. 概念
我们都知道uptime命令的最后三列分别是过去 1 分钟、5 分钟、15 分钟系统的平均负载,到底平均负载是什么?

简单来说,平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数(它实际上是活跃进程数的指数衰减平均值)。
- 可运行状态的进程,是指正在使用 或者等待 CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态(Running 或 Runnable)的进程
- 不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,最常见的是等待硬件设备的 I/O 响应,也就是我们在 ps 命令中看到的 D 状态(Uninterruptible Sleep,也称为 Disk Sleep)的进程
平均负载不仅包括了正在使用 CPU 的进程,还包括等待 CPU 和等待I/O 的进程,它未必等价于CPU使用率。比如:
- CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
- I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
- 大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
2. 合理范围
平均负载表示系统对CPU资源的需求。比如当平均负载为 2 时,意味着什么呢?首先你要知道系统有几个 CPU。
-
# 查看物理CPU个数
-
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
-
# 查看逻辑CPU的个数
-
cat /proc/cpuinfo| grep "processor"| wc -l
当平均负载比 CPU 个数还大的时候,系统已经出现了过载,例如:
- 在只有 2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用
- 在 4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲
- 而在只有 1 个 CPU 的系统中,则意味着有一半的进程竞争不到 CPU
既然平均的是活跃进程数,那么最理想的,就是每个 CPU 上都刚好运行着一个进程,这样每个 CPU 都得到了充分利用。当平均负载 > CPU数 * 70% 时,你就应该分析排查负载高的问题了。一旦负载过高,就可能导致进程响应变慢,进而影响服务的正常功能。但 70% 这个数字并不是绝对的,最推荐的方法,还是把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势。当发现负载有明显升高趋势时,比如说负载翻倍了,再去做分析和调查。
二、 案例分析
下面,我们以三个示例分别来看这三种情况,并用 iostat、mpstat、pidstat 等工具,找出平均负载升高的根源。需要预先安装 stress 和 sysstat 包。
-
yum -y install epel-release
-
yum -y install stress sysstat
rpm包 http://www.rpmfind.net/linux/rpm2html/search.php?query=stress
编译安装参考 https://www.cnblogs.com/wuzm/p/11096276.html
1. 工具简介
stress 是一个 Linux 系统压力测试工具,这里我们用作异常进程模拟平均负载升高的场景。
sysstat 包含了常用的 Linux 性能工具,用来监控和分析系统的性能,我们的案例会用到mpstat 和 pidstat两个命令。
- mpstat 是一个常用的多核 CPU 性能分析工具,用来实时查看每个 CPU 的性能指标,以及所有 CPU 的平均指标。
- pidstat 是一个常用的进程性能分析工具,用来实时查看进程的 CPU、内存、I/O 以及上下文切换等性能指标。
首先查看下系统当前平均负载(测试虚拟机4c8g)

2. CPU 密集型进程场景
- 第一个终端:运行 stress 命令,模拟一个 CPU 使用率 100% 的场景
stress --cpu 1 --timeout 600

- 第二个终端:运行 uptime 命令
-
# -d 参数表示高亮显示变化的区域
-
watch -d uptime
-
..., load average: 1.00, 0.75, 0.39
可以看到平均负载慢慢在升高,到大概1
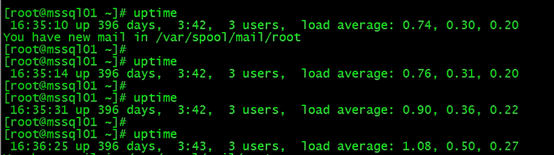
- 第三个终端:运行 mpstat 查看 CPU 使用率的变化情况
-
# -P ALL 表示监控所有CPU,后面数字5表示间隔5秒后输出一组数据
-
mpstat -P ALL 5
可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。

到底是哪个进程导致了 CPU 使用率为 100% 呢?你可以使用 pidstat 来查询:
-
# 间隔5秒后输出一组数据,-u表示CPU指标
-
pidstat -u 5 1
可以看到这个进程就是stress

3. IO密集进程场景
首先还是运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync。
stress -i 1 --timeout 600

第二个终端运行 uptime 查看平均负载的变化情况。可以看到平均负载慢慢在升高,到大概1
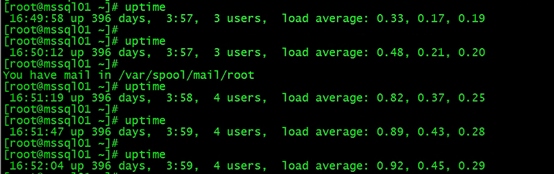
第三个终端运行 mpstat 查看 CPU 使用率的变化情况:
-
# 显示所有CPU的指标,并在间隔5秒输出一组数据
-
$ mpstat -P ALL 5 1
-
Linux 4.15.0 (ubuntu) 09/22/18 _x86_64_ (2 CPU)
-
13:41:28 CPU %usr %nice %sys %iowait %irq %soft %steal %gues
-
13:41:33 all 0.21 0.00 12.07 32.67 0.00 0.21 0.00 0.0
-
13:41:33 0 0.43 0.00 23.87 67.53 0.00 0.43 0.00 0.0
-
13:41:33 1 0.00 0.00 0.81 0.20 0.00 0.00 0.00 0.0
-
-
#可以看到,其中一个 CPU 的系统 CPU 使用率升高到了 23.87,而 iowait 高达 67.53%。
-
这说明,平均负载的升高是由于 iowait 的升高。
实际测试的时候遇到了不一样的现象,我们是%sys高但iowait不高

根据老师回复,iowait无法升高的问题,是因为案例中案例中的 stress -i 表示通过系统调用 sync() 来模拟 I/O 的问题,它的作用是刷新缓冲区内存到磁盘中这种方法实际上并不可靠。如果缓冲区内本来就没多少数据,那读写到磁盘中的数据也就不多,无法产生大的IO压力,这样大部分就都是系统调用的消耗了,这一点在使用 SSD 磁盘的环境中尤为明显。
所以,你会看到只有系统CPU使用率升高。解决方法是使用stress的下一代stress-ng,它支持更丰富的选项,比如 stress-ng -i 1 --hdd 1 --timeout 600(--hdd表示读写临时文件)
还是用 pidstat 来查询是哪个进程导致的

4. 大量进程等待CPU的场景
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。对应到数据库系统,一般就是并发压力过大或者慢sql较多。
比如,我们还是使用 stress,但这次模拟的是 16 个进程:
stress -c 16 --timeout 600

第二个终端运行 uptime 查看平均负载的变化情况。可以看到由于CPU严重过载,平均负载迅速飙升。

第三个终端运行 mpstat 查看 CPU 使用率的变化情况。可以看到所有CPU使用率基本都满了。

还是用 pidstat 来查询是哪个进程导致的

我们这个还是有点不一样,没有wait列,但也能看到是stress进程的问题

根据老师回复,pidstat输出中没有%wait的问题,是因为CentOS默认的sysstat稍微有点老,源码或者RPM升级到11.5.5版本以后就可以看到了。而Ubuntu的包一般都比较新,没有这个问题。
另外,很常见的一个错误,有些同学会拿 pidstat 中的 %wait 跟 top中的 iowait% (缩写为 wa)对比,其实这是没有意义的,因为它们是完全不相关的两个指标。
- pidstat 中, %wait 表示进程等待 CPU 的时间百分比。
- top 中 ,iowait% 则表示等待 I/O 的 CPU 时间百分比。
等待 CPU 的进程已经在 CPU 的就绪队列中,处于R状态;而等待 I/O 的进程则处于D状态。
三、 评论补充
还可以用htop看负载,因为它更直接(在F2配置中勾选所有开关项,打开颜色区分功能),不同的负载会用不同的颜色标识。比如cpu密集型的应用,它的负载颜色是绿色偏高,iowait的操作,它的负载颜色是红色偏高等等,根据这些指标再用htop的sort就很容易定位到有问题的进程。还有个更好用的atop命令,好像是基于sar的统计生成的报告,直接就把有问题的进程标红了,更直观。
CPU比喻成一辆地铁:地铁的乘客容量就是CPU个数;正在使用CPU的进程就是在地铁上的人;等待CPU的进程就是在下一站等地铁来的人;等待I/O的进程就是在下一站要上车和下车的人,虽然现在对CPU没影响,可未来会影响,所以也要考虑到平均负载上。
建议还是使用top等系统默认安装的命令,无需额外安装。
[转帖]《Linux性能优化实战》笔记(一)—— 平均负载的更多相关文章
- 深挖计算机基础:Linux性能优化学习笔记
参考极客时间专栏<Linux性能优化实战>学习笔记 一.CPU性能:13讲 Linux性能优化实战学习笔记:第二讲 Linux性能优化实战学习笔记:第三讲 Linux性能优化实战学习笔记: ...
- Linux性能优化实战(一)
一.优化方向 1,性能指标 从应用负载的视角出发,考虑"吞吐"和"延时" 从系统资源的视角出发,考虑资源使用率.饱和度等 2,性能优化步骤 选择指标评估应用程序 ...
- Linux性能优化实战学习笔记:第四十五讲
一.上节回顾 专栏更新至今,四大基础模块的最后一个模块——网络篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,热情地留言和互动.还有不少同学分享了在实际生产环境中,碰到各种性能 ...
- 《Linux 性能优化实战—倪朋飞 》学习笔记 CPU 篇
平均负载 指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,即平均活跃进程数 可运行状态:正在使用CPU或者正在等待CPU 的进程,也就是我们常用 ps 命令看到的,处于 R 状态 (Run ...
- Linux性能优化实战学习笔记:第三十一讲
一.上节回顾 上一节,我们一起回顾了常见的文件系统和磁盘 I/O 性能指标,梳理了核心的 I/O 性能观测工具,最后还总结了快速分析 I/O 性能问题的思路. 虽然 I/O 的性能指标很多,相应的性能 ...
- Linux性能优化实战学习笔记:第三十二讲
一.上节总结 专栏更新至今,四大基础模块的第三个模块——文件系统和磁盘 I/O 篇,我们就已经学完了.很开心你还没有掉队,仍然在积极学习思考和实践操作,并且热情地留言与讨论. 今天是性能优化的第四期. ...
- Linux性能优化实战学习笔记:第三十六讲
一.上节总结回顾 上一节,我们回顾了经典的 C10K 和 C1000K 问题.简单回顾一下,C10K 是指如何单机同时处理 1 万个请求(并发连接 1 万)的问题,而 C1000K 则是单机支持处理 ...
- Linux性能优化实战学习笔记:第四十三讲
一.上节回顾 上一节,我们了解了 NAT(网络地址转换)的原理,学会了如何排查 NAT 带来的性能问题,最后还总结了 NAT 性能优化的基本思路.我先带你简单回顾一下. NAT 基于 Linux 内核 ...
- Linux性能优化实战学习笔记:第四十四讲
一.上节回顾 上一节,我们学了网络性能优化的几个思路,我先带你简单复习一下. 在优化网络的性能时,你可以结合 Linux 系统的网络协议栈和网络收发流程,然后从应用程序.套接字.传输层.网络层再到链路 ...
- Linux性能优化实战学习笔记:第五十二讲
一.上节回顾 上一节,我们一起学习了怎么使用动态追踪来观察应用程序和内核的行为.先简单来回顾一下.所谓动态追踪,就是在系统或者应用程序还在正常运行的时候,通过内核中提供的探针,来动态追踪它们的行为,从 ...
随机推荐
- 斯坦福 UE4 C++ ActionRoguelike游戏实例教程 10.5.作业五 为游戏添加一个积分系统,随机生成增益道具
斯坦福课程 UE4 C++ ActionRoguelike游戏实例教程 0.绪论 概述 本篇文章将解决作业五提出的问题,使用PlayerState,在原本游戏的基础上引入积分系统,实现击杀敌人得分,拾 ...
- vue星星评分
<template> <div> <div class="xx"> <div v-for="(i, index) in list ...
- Quartz.Net系列(一):Windows任务计划程序
1.使用此电脑=>管理 系统工具=>任务计划程序=>任务计划程序库=>创建任务 创建任务 触发器 操作 条件=>去掉只有在计算机使用交流电源时才启动此任务 创建 ...
- 【DevCloud·敏捷智库】如何利用故事点做估算
背景 在某开发团队辅导的第二天,一个团队负责人咨询道:"领导经常管我要开发计划,我如何能快速的评估出预计开发完成时间呢,我们目前用工时估算,我听说过故事点估算,不知道适合吗?" 问 ...
- 物联网SIM卡和SIM卡真的不是一回事
办卡吗,兄弟? 物联网卡?相信大家第一反应都是一愣.大家听过银行卡.电话SIM卡.会员卡-等等,很多人可能都是第一次听说物联网卡.那它到底是个什么东东?它能干什么呢?今天就带大家一探究竟. 那在物联网 ...
- 昇腾实战丨DVPP媒体数据处理视频解码问题案例
摘要:本期就分享几个关于DVPP视频解码问题的典型案例,并给出原因分析及解决方法 本文分享自华为云社区<DVPP媒体数据处理视频解码问题案例>,作者:昇腾CANN . DVPP(Digit ...
- 华为云Astro的前世今生:用7年时间革新低代码开发观念
摘要:深扒华为云Astro低代码平台的前世今生,其成功之路显然是一条"个性"之路. 本文分享自华为云社区<华为云Astro的前世今生:用7年时间革新低代码开发观念>,作 ...
- 五大不良 coding 习惯,你占了几样?
在之前的文章中,我们一起解读了2021年数据成本报告.根据 IBM 和 Ponemon Institute 2021年的报告,全球平均数据泄露成本约为424万美元.为了降低数据泄露造成的成本,企业可以 ...
- 【申请教程】ChatGPT访问互联网插件
https://openai.com/blog/chatgpt-plugins 大家好,我是章北海mlpy 申请ChatGPT插件很久了,一直没下文 最近看到两种套路,我早上试了一下,看能否快速成功吧 ...
- Codeforces Round #723 (Div. 2) (A~C题题解)
补题链接:Here 1526A. Mean Inequality 给定 \(2 * n\) 个整数序列 \(a\),请按下列两个条件输出序列 \(b\) 序列是 \(a\) 序列的重排序 \(b_i ...