python全栈开发day33-进程间的通信、进程间的数据共享,进程池
一、昨日内容回顾:
1. 守护进程
1)、p.saemon,
2 )、p.terminate
3 )、p.join
2. 同步控制
1)、锁,Lock
互斥锁,解决数据安全、进程之间资源抢占问题。
2)、信号量,Semaphore
锁+计数器
3)、事件,Event
通过一个标志位flag来控制进程的阻塞和执行。
3. 多进程实现tcp协议的socket的sever端
1)子进程中不能使用input
2)允许端口的重用设置
3)妥善处理sk的close确保操作系统的资源能够被及时回收。
import socket
from multiprocessing import Process def func(conn):
conn.send(b'hello')
data = conn.recv(1024)
print(data.decode('utf-8'))
conn.close() if __name__ == '__main__':
sk = socket.socket()
sk.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sk.bind(('127.0.0.1', 9000))
sk.listen(5)
try:
while True:
con, addr = sk.accept()
p = Process(target=func, args=(con,))
p.start()
finally:
sk.close()
server
import socket sk = socket.socket()
sk.connect(('127.0.0.1', 9000))
data = sk.recv(1024)
print(data)
msg = input('>>>').encode('utf-8')
sk.send(msg)
client
二、今日内容总结:
1、进程间的通信:
1)、队列 Queue:队列是加锁的,在多进程之间对数据的管理是安全的
维护了一个先进先出的顺序,且保证了数据在进程之间是安全的。
put,get,full,empty,get_nowait,put_nowait
生产者和消费者模型:
(1)、解决生产消费供需关系,生产的东西不够吃,就再开启一个进程生产。。。
(2)、解决消费者不能结束消费完物品的循环和阻塞问题,队列中引入None,
让消费者再取的时候判断是否遇到None,遇到则结束。有几个消费者就队列中就put几个None
(3)、解决生产者生产完成后主程序才结束问题,对生产者的进程进程join阻塞
JoinableQueue:
join和task_done方法:
join会阻塞队列,直至队列中的数据被取完,且执行了一个task_done,程序才会继续执行。
from multiprocessing import Process, Queue
import time, random def consumer(name, q):
while True:
time.sleep(random.randint(1, 3))
food = q.get()
if food is None: break
print('%s吃了%s' % (name, food)) def producer(name, food, q):
for i in range(10):
time.sleep(random.randint(1, 5))
q.put('%s生产了%s%s' % (name, food, i))
print('%s生产了数据%s%s' % (name, food, i)) if __name__ == '__main__':
q = Queue()
p1 = Process(target=producer, args=('egon', '面包', q))
p2 = Process(target=producer, args=('taibai', '骨头', q))
p1.start()
p2.start()
c1 = Process(target=consumer, args=('alex', q))
c2 = Process(target=consumer, args=('firedragon', q))
c1.start()
c2.start()
p1.join()
p2.join()
q.put(None)
q.put(None)
生产者和消费者模型例子None
from multiprocessing import JoinableQueue,Process
import time def consumer(name,q):
while True:
obj = q.get()
time.sleep(0.3)
print('%s吃了一个%s' % (name, obj))
q.task_done() if __name__ == '__main__':
q = JoinableQueue()
for i in range(10):
q.put('food%s' % i)
p1 = Process(target=consumer, args=('alex', q))
p1.daemon = True
p1.start()
q.join() # 阻塞队列,直至队列的数据被取完,且执行了一个task_done()
# p1为守护进程,主程序代码执行完毕后,守护进程随之结束,里边的循环自然也结束了。
生产者和消费者模型JoinableQueue
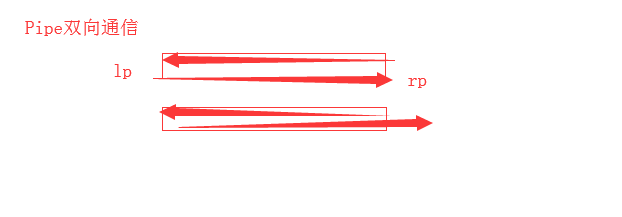
2)、管道 Pipe:底层实现是pickle,对数据的管理是不安全的,队列的实现机制就是管道+锁
双向通信:利用pickle实现的
收不到,就阻塞
# 管道的EOFError是怎么报出来的(同时关闭主进程的lp和子进程的lp就会报出EOFError)
# 管道在数据管理上是不安全的
# 队列的实现机制 就是 管道+锁
from multiprocessing import Pipe,Process
# lp,rp = Pipe()
# lp.send('hello')
# print(rp.recv())
# # print(rp.recv()) # 没有数据在此阻塞进程
# # rp.send() # 不能发送空数据
# lp.send([1,2,3])
# print(rp.recv()) def consumer(lp,rp):
lp.close() #1.这个发关闭
while True:
print(rp.recv()) if __name__ == '__main__':
lp, rp = Pipe()
Process(target=consumer, args=(lp, rp)).start()
Process(target=consumer, args=(lp, rp)).start()
Process(target=consumer, args=(lp, rp)).start()
Process(target=consumer, args=(lp, rp)).start()
#rp.close()
for i in range(100):
lp.send('food%i' % i)
lp.close() #2.这个关闭 这两关闭才会报错EOFError
管道例子
2、进程之间的数据共享,Manager
Manager创建的数据(如字典等)可以在进程之间共享,涉及数据操作要加上锁,不然会出现数据错乱。
m = Manager() dic = m.dict({‘count’:100})
with Manager() as m: dic = m.dict({‘count’:100}) 但涉及dic的操作代码必须在with的缩进执行
from multiprocessing import Lock,Manager,Process def func(dic_tmp, lock_tmp):
with lock_tmp:
dic_tmp['count'] -= 1 if __name__ == '__main__':
lock = Lock()
with Manager() as m:
dic = m.dict({'count': 50})
p_lst = []
for i in range(50):
p = Process(target=func, args=(dic, lock))
p.start()
p_lst.append(p)
for i in p_lst:
i.join()
print(dic)
50个进程同时操作一个字典的例子
3、进程池
进程池使用场景PK多进程: 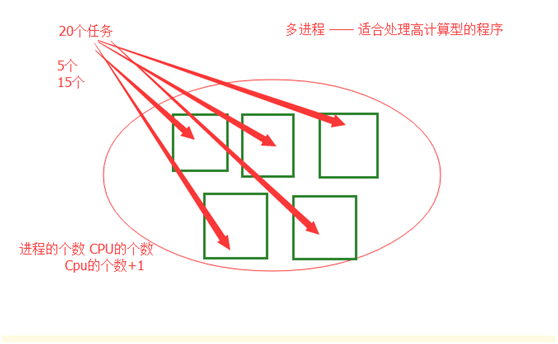
1.对于纯计算的代码,使用进程池更好(个人理解,高效利用cpu没有了节省了进程的开启和回收时间,也节省操作系统调度进程切换的时间)
2.对于高IO的代码,没有更好选择的情况下使用多进程。
总结:使用进程池比起多进程,节省了开启进程回收进程资源的时间,给操作系统调度进程降低了难度。
进程池apply(同步)添加入池方法和apply_async(异步)
使用进程池提交任务方法:
p = Pool(5)
p.appy(func=***,args=(,))) #同步提交任务 没有多进程的优势
p.apply_async(func=***,args=(,)) #异步提交任务
p.close() #关闭进程池,阻止向进程池添加新的任务
p.join() #依赖close,进程池必须先close后join(个人理解应该是要阻塞执行完进程池的任务,才进入非阻塞状态)
------代码-------
from multiprocessing import Pool,Process
import time,random def wahaha(num):
time.sleep(random.randint(1,3))
print('num:%s' % num**num) if __name__ == '__main__': # -------------------------适合高计算--------------------------------------------
p = Pool(5)
# start = time.time()
# for i in range(100):
# p.apply_async(func=wahaha,args=(i,))
#
# p.close()
# p.join()
# print(time.time()-start) start = time.time()
p.map(func=wahaha,iterable=range(101))
print(time.time()-start)
# -------------------------适合高IO--------------------------------------------
# start = time.time()
# p_lst = []
# for i in range(101):
# p = Process(target=wahaha,args=(i,))
# p.start()
# p_lst.append(p)
# for i in p_lst:
# i.join()
# print(time.time() - start)
使用map添加任务的方法以及它和普通(apply_async)方法的区别:
p.map(func=***,iterable=range(101))
优点:就是一个任务函数,个一个itetable,节省了for循环和close,join,是一种简便写法。
区别:apply_async和map相比,操作复杂,但是可以通过get方法获取返回值,而map不行。
def wahaha(num):
print(num)
return num*'*' if __name__ == '__main__': p = Pool(5)
start = time.time()
result_lst = []
for i in range(100):
res = p.apply_async(func=wahaha,args=(i,))
result_lst.append(res)
print(result_lst)
for j in result_lst:print(j.get())
p.close()
p.join()
print(time.time()-start)
apply_async使用get获取返回值
回调函数:可以接收func函数的返回值。但callback函数在主进程中运行。
p.apply_async(func=***,args=(*,),callback=回调函数))
from multiprocessing import Pool,Process
import os def wahaha(num):
print('子进程:',os.getpid())
return num**num def callb(argv):
print(os.getpid())
print(argv) if __name__ == '__main__':
print('主进程', os.getpid())
p = Pool(5)
p.apply_async(func=wahaha,args=(1,),callback=callb)
p.close()
p.join()
callback
三、预习和扩展:
python全栈开发day33-进程间的通信、进程间的数据共享,进程池的更多相关文章
- python全栈开发,Day41(线程概念,线程的特点,进程和线程的关系,线程和python理论知识,线程的创建)
昨日内容回顾 队列 队列:先进先出.数据进程安全 队列实现方式:管道+锁 生产者消费者模型:解决数据供需不平衡 管道 双向通信,数据进程不安全 EOFError: 管道是由操作系统进行引用计数的 必须 ...
- Python全栈开发【模块】
Python全栈开发[模块] 本节内容: 模块介绍 time random os sys json & picle shelve XML hashlib ConfigParser loggin ...
- Python全栈开发【面向对象】
Python全栈开发[面向对象] 本节内容: 三大编程范式 面向对象设计与面向对象编程 类和对象 静态属性.类方法.静态方法 类组合 继承 多态 封装 三大编程范式 三大编程范式: 1.面向过程编程 ...
- python 全栈开发之路 day1
python 全栈开发之路 day1 本节内容 计算机发展介绍 计算机硬件组成 计算机基本原理 计算机 计算机(computer)俗称电脑,是一种用于高速计算的电子计算机器,可以进行数值计算,又可 ...
- 自学Python全栈开发第一次笔记
我已经跟着视频自学好几天Python全栈开发了,今天决定听老师的,开始写blog,听说大神都回来写blog来记录自己的成长. 我特别认真的跟着这个视频来学习,(他们开课前的保证书,我也写 ...
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
- Python 全栈开发【第0篇】:目录
Python 全栈开发[第0篇]:目录 第一阶段:Python 开发入门 Python 全栈开发[第一篇]:计算机原理&Linux系统入门 Python 全栈开发[第二篇]:Python基 ...
- Python全栈开发【面向对象进阶】
Python全栈开发[面向对象进阶] 本节内容: isinstance(obj,cls)和issubclass(sub,super) 反射 __setattr__,__delattr__,__geta ...
- Python全栈开发【基础四】
Python全栈开发[基础四] 本节内容: 匿名函数(lambda) 函数式编程(map,filter,reduce) 文件处理 迭代器 三元表达式 列表解析与生成器表达式 生成器 匿名函数 lamb ...
- Python全栈开发【基础三】
Python全栈开发[基础三] 本节内容: 函数(全局与局部变量) 递归 内置函数 函数 一.定义和使用 函数最重要的是减少代码的重用性和增强代码可读性 def 函数名(参数): ... 函数体 . ...
随机推荐
- python遍历数组获取下标
代码 通过枚举实现 a = [,,,,,] for i,j in enumerate(a): print i,j 结果
- python多进程那点事儿【multiprocessing库】
前言:项目中有个需求需要对产品的日志处理,按照产品中日志的某些字段,对日志进行再次划分.比如产品的日志中含有字段id,tag=1,现在需要把tag是基数的放到一个文件中,tag是偶数的放入一个文件中. ...
- oracle sum(x) over( partition by y ORDER BY z ) 分析
之前用过row_number(),rank()等排序与over( partition by ... ORDER BY ...),这两个比较好理解: 先分组,然后在组内排名. 今天突然碰到sum(... ...
- vue学习一:新建或打开vue项目(vue-cli2)
vue-cli3的操作参考文章:vue/cli 3.0脚手架搭建,浅谈vue-cli 3 和 vue-cli 2的区别 1.前期准备: node.js环境,安装node npm或者cnpm(npm的淘 ...
- 推荐几款在Windows中比较好用的软件
gif录制软件:LICEcap 下载地址:https://www.cockos.com/licecap/ 演示
- JavaScript学习 - 基础(八) - DOM 节点 添加/删除/修改/属性值操作
html代码: <!--添加/删除/修改 --> <div id="a1"> <button id="a2" onclick=&q ...
- [转]bus error与segment error
在c程序中,经常会遇到段错误(segment error)和总线错误(bus error),这两种问题出现的原因可能如下 段错误: 对一个NULL指针解引用. 访问程序进程以外的内存空间. 实际上,第 ...
- How to Repair GRUB2 When Ubuntu Won’t Boot
Ubuntu and many other Linux distributions use the GRUB2 boot loader. If GRUB2 breaks—for example, if ...
- linux下混杂模式
混杂模式介绍: 混杂模式就是接收所有经过网卡的数据包,包括不是发给本机的包,默认情况下网卡只把发给本机的包(包括广播包)传递给上层程序,其它的包一律丢弃:简单的讲,混杂模式就是指网卡能接受所有通过它的 ...
- pom.xml的第一行报错
第一行:<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.or ...