归一化(softmax)、信息熵、交叉熵
机器学习中经常遇到这几个概念,用大白话解释一下:
一、归一化
把几个数量级不同的数据,放在一起比较(或者画在一个数轴上),比如:一条河的长度几千甚至上万km,与一个人的高度1.7m,放在一起,人的高度几乎可以被忽略,所以为了方便比较,缩小他们的差距,但又能看出二者的大小关系,可以找一个方法进行转换。
另外,在多分类预测时,比如:一张图,要预测它是猫,或是狗,或是人,或是其它什么,每个分类都有一个预测的概率,比如是猫的概率是0.7,狗的概率是0.1,人的概率是0.2... , 概率通常是0到1之间的数字,如果我们算出的结果,不在这个范围,比如:700,10,2 ,甚至负数,这样就需要找个方法,将其转换成0-1之间的概率小数,而且通常为了满足统计分布,这些概率的和,应该是1。
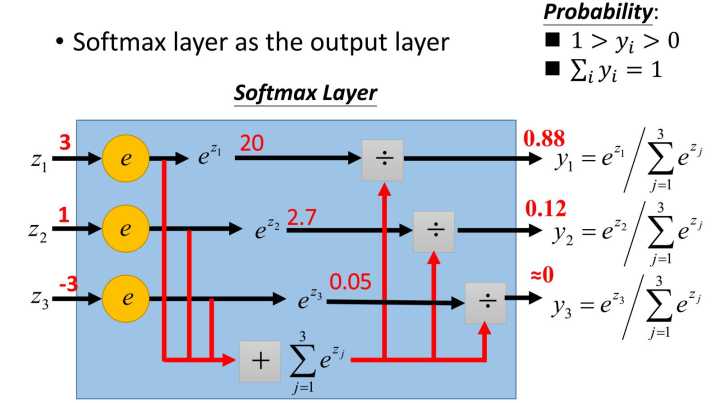
最常用的处理方法,就是softmax,原理如上图(网上淘来的)。
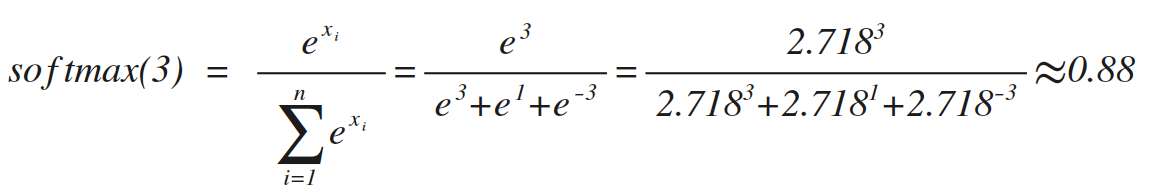
类似的softmax(1)=0.12,softmax(-3)=0,这个方法在数学上没毛病,但是在实际运用中,如果目标值x很大,比如10000,那e的10000次方,很可能超出编程语言的表示范围,所以通常做softmax前,要对数据做一下预处理(比如:对于分类预测,最简单的办法,所有训练集整体按比例缩小)
二、信息熵
热力学中的热熵是表示分子状态混乱程度的物理量,而且还有一个所谓『熵增原理』,即:宇宙中的熵总是增加的,换句话说,分子状态总是从有序变成无序,热量总是从高温部分向低温部分传递。 香农借用了这个概念,用信息熵来描述信源的不确定度。
简单点说,一个信息源越不确定,里面蕴含的信息量越大。举个例子:吴京《战狼2》大获成功后,说要续拍《战狼3》,但是没说谁当女主角,于是就有各种猜测,各种可能性,即:信息量很大。但是没过多久,吴京宣布女主角确定后,大家就不用再猜测女主角了,信息量相比就没这么大了。
这个例子中,每种猜测的可能性其实就是概率,而信息量如何衡量,可以用下面的公式来量化计算,算出来的值即信息熵:
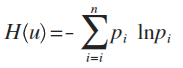
这里p为概率,最后算出来的结果通常以bit为单位。
举例:拿计算机领域最常现的编码问题来说,如果有A、B、C、D这四个字符组成的内容,每个字符出现的概率都是1/4,即概率分布为{1/4,1/4,1/4,1/4},设计一个最短的编码方案来表示一组数据,套用刚才的公式:
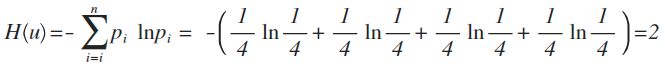
即:2个bit,其实不用算也能想明白,如果第1位0表示A,1表示B;第2位0表示C,1表示D,2位编码搞定。
如果概率变了,比如A、B、C、D出现的概率是{1,1,1/2,1/2},即:每次A、B必然出现,C、D出现机会各占一半,这样只要1位就可以了。1表示C,0表示D,因为AB必然出现,不用表示都知道肯定要附加上AB,套用公式算出来的结果也是如此。
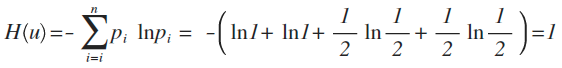
三、交叉熵
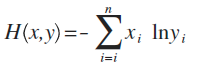
这是公式定义,x、y都是表示概率分布(注:也有很多文章喜欢用p、q来表示),这个东西能干嘛呢?
假设x是正确的概率分布,而y是我们预测出来的概率分布,这个公式算出来的结果,表示y与正确答案x之间的错误程度(即:y错得有多离谱),结果值越小,表示y越准确,与x越接近。
比如:
x的概率分布为:{1/4 ,1/4,1/4,1/4},现在我们通过机器学习,预测出来二组值:
y1的概率分布为 {1/4 , 1/2 , 1/8 , 1/8}
y2的概率分布为 {1/4 , 1/4 , 1/8 , 3/8}
从直觉上看,y2分布中,前2项都100%预测对了,而y1只有第1项100%对,所以y2感觉更准确,看看公式算下来,是不是符合直觉:

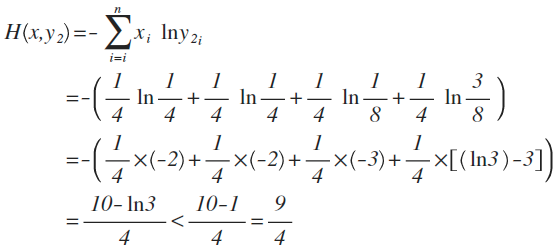
对比结果,H(x,y1)算出来的值为9/4,而H(x,y2)的值略小于9/4,根据刚才的解释,交叉熵越小,表示这二个分布越接近,所以机器学习中,经常拿交叉熵来做为损失函数(loss function)。
参考文章:
https://www.zhihu.com/question/23765351
https://www.zhihu.com/question/41252833/answer/108777563
https://www.zhihu.com/question/22178202
归一化(softmax)、信息熵、交叉熵的更多相关文章
- softmax、交叉熵
Softmax是用于分类过程,用来实现多分类的 它把一些输出的神经元映射到(0-1)之间的实数,并且归一化保证和为1,从而使得多分类的概率之和也刚好为1. Softmax可以分为soft和max,ma ...
- DL基础补全计划(二)---Softmax回归及示例(Pytorch,交叉熵损失)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 深度学习原理与框架-神经网络结构与原理 1.得分函数 2.SVM损失函数 3.正则化惩罚项 4.softmax交叉熵损失函数 5. 最优化问题(前向传播) 6.batch_size(批量更新权重参数) 7.反向传播
神经网络由各个部分组成 1.得分函数:在进行输出时,对于每一个类别都会输入一个得分值,使用这些得分值可以用来构造出每一个类别的概率值,也可以使用softmax构造类别的概率值,从而构造出loss值, ...
- softmax+交叉熵
1 softmax函数 softmax函数的定义为 $$softmax(x)=\frac{e^{x_i}}{\sum_j e^{x_j}} \tag{1}$$ softmax函数的特点有 函数值在[0 ...
- 【深度学习】softmax回归——原理、one-hot编码、结构和运算、交叉熵损失
1. softmax回归是分类问题 回归(Regression)是用于预测某个值为"多少"的问题,如房屋的价格.患者住院的天数等. 分类(Classification)不是问&qu ...
- 神经网络(NN)+反向传播算法(Backpropagation/BP)+交叉熵+softmax原理分析
神经网络如何利用反向传播算法进行参数更新,加入交叉熵和softmax又会如何变化? 其中的数学原理分析:请点击这里.
- 深度学习面试题07:sigmod交叉熵、softmax交叉熵
目录 sigmod交叉熵 Softmax转换 Softmax交叉熵 参考资料 sigmod交叉熵 Sigmod交叉熵实际就是我们所说的对数损失,它是针对二分类任务的损失函数,在神经网络中,一般输出层只 ...
- 【转载】深度学习中softmax交叉熵损失函数的理解
深度学习中softmax交叉熵损失函数的理解 2018-08-11 23:49:43 lilong117194 阅读数 5198更多 分类专栏: Deep learning 版权声明:本文为博主原 ...
- 交叉熵和softmax
深度学习分类问题结尾就是softmax,损失函数是交叉熵,本质就是极大似然...
随机推荐
- favicon.ico问题
在访问web的时候,有时出现favicon.ico 不知道这是一个什么东西,查看百度:
- nodejs后台向后台get请求
1 前言 有时在nodejs写的服务端某方法需要向服务端另一个接口发送get请求,可以使用第三方库,然后直接使用即可,此文章只是用来记录使用 2 方法 2.1 get 请求 //1. Install ...
- 微服务(Microservices )简介
概念 微服务架构风格是一种将单个应用程序作为一套小型服务开发的方法,每种应用程序都在自己的进程中运行, 并与轻量级机制(通常是HTTP资源API)进行通信. 这些服务是围绕业务功能构建的,可以通过全自 ...
- linux eclipse 报错过时的方法
重新配置jre库 https://jingyan.baidu.com/article/7f766daff5b8cd4101e1d0b4.html
- Luogu P3616 【富金森林公园】
我们首先考虑一块石头高度变化对每个高度的查询的答案的影响, 即我们要记录,对于每个高度的查询的答案 所以要离散化高度(不然哪开的下数组啊) 不难发现,一次变化的对于不同高度的影响,对于一段连续高度是相 ...
- Fiddler抓包4-工具介绍(request和response)
前言 本篇简单的介绍下fiddler界面的几块区域,以及各自区域到底是干什么用的,以便于各好的掌握这个工具 一.工具简介 1.第一块区域是设置菜单,这个前面2篇都有介绍 2.第二块区域是一些快捷菜单, ...
- js中数组去重
编写函数norepeat(arr) 将数组的重复元素去掉,并返回新的数组 [注]正序去重,会漏掉一些元素. [注]去重倒序. var arr = [10, 20, 30, 40, 30, 20, 20 ...
- MarkDown常用语法及word转MarkDown
介绍 Markdown 的目标是实现「易读易写」. 可读性,无论如何,都是最重要的.一份使用 Markdown 格式撰写的文件应该可以直接以纯文本发布,并且看起来不会像是由许多标签或是格式指令所构成. ...
- python 全栈开发,Day118(django事务,闭包,客户管理,教学管理,权限应用)
昨日内容回顾 一.django事务 什么是事务 一系列将要发生或正在发生的连续操作. 作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行. 事务处理可以确保除非事务性单元内的所有操 ...
- icomet研究
官方文档https://github.com/ideawu/icomet/wiki 如何实现的长连接:noop: 心跳消息+HTTP endless chunk 以班级ID为主键,进行班级通道的创建: ...