归一化(softmax)、信息熵、交叉熵
机器学习中经常遇到这几个概念,用大白话解释一下:
一、归一化
把几个数量级不同的数据,放在一起比较(或者画在一个数轴上),比如:一条河的长度几千甚至上万km,与一个人的高度1.7m,放在一起,人的高度几乎可以被忽略,所以为了方便比较,缩小他们的差距,但又能看出二者的大小关系,可以找一个方法进行转换。
另外,在多分类预测时,比如:一张图,要预测它是猫,或是狗,或是人,或是其它什么,每个分类都有一个预测的概率,比如是猫的概率是0.7,狗的概率是0.1,人的概率是0.2... , 概率通常是0到1之间的数字,如果我们算出的结果,不在这个范围,比如:700,10,2 ,甚至负数,这样就需要找个方法,将其转换成0-1之间的概率小数,而且通常为了满足统计分布,这些概率的和,应该是1。
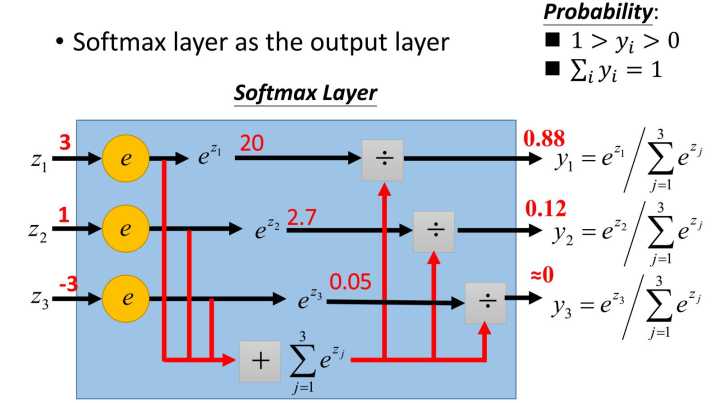
最常用的处理方法,就是softmax,原理如上图(网上淘来的)。
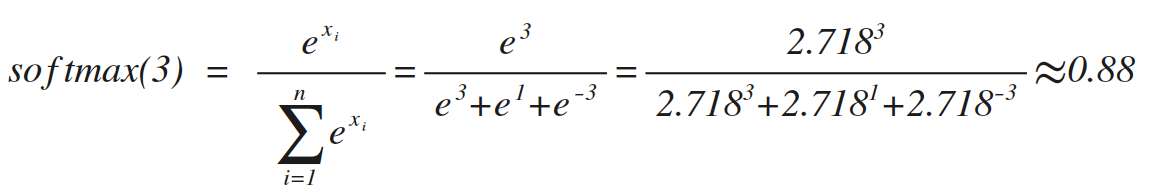
类似的softmax(1)=0.12,softmax(-3)=0,这个方法在数学上没毛病,但是在实际运用中,如果目标值x很大,比如10000,那e的10000次方,很可能超出编程语言的表示范围,所以通常做softmax前,要对数据做一下预处理(比如:对于分类预测,最简单的办法,所有训练集整体按比例缩小)
二、信息熵
热力学中的热熵是表示分子状态混乱程度的物理量,而且还有一个所谓『熵增原理』,即:宇宙中的熵总是增加的,换句话说,分子状态总是从有序变成无序,热量总是从高温部分向低温部分传递。 香农借用了这个概念,用信息熵来描述信源的不确定度。
简单点说,一个信息源越不确定,里面蕴含的信息量越大。举个例子:吴京《战狼2》大获成功后,说要续拍《战狼3》,但是没说谁当女主角,于是就有各种猜测,各种可能性,即:信息量很大。但是没过多久,吴京宣布女主角确定后,大家就不用再猜测女主角了,信息量相比就没这么大了。
这个例子中,每种猜测的可能性其实就是概率,而信息量如何衡量,可以用下面的公式来量化计算,算出来的值即信息熵:
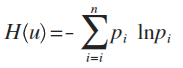
这里p为概率,最后算出来的结果通常以bit为单位。
举例:拿计算机领域最常现的编码问题来说,如果有A、B、C、D这四个字符组成的内容,每个字符出现的概率都是1/4,即概率分布为{1/4,1/4,1/4,1/4},设计一个最短的编码方案来表示一组数据,套用刚才的公式:
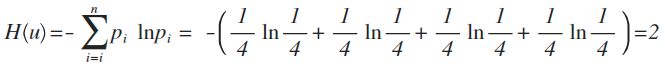
即:2个bit,其实不用算也能想明白,如果第1位0表示A,1表示B;第2位0表示C,1表示D,2位编码搞定。
如果概率变了,比如A、B、C、D出现的概率是{1,1,1/2,1/2},即:每次A、B必然出现,C、D出现机会各占一半,这样只要1位就可以了。1表示C,0表示D,因为AB必然出现,不用表示都知道肯定要附加上AB,套用公式算出来的结果也是如此。
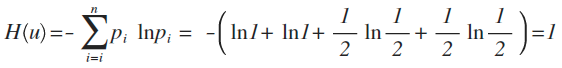
三、交叉熵
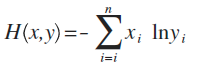
这是公式定义,x、y都是表示概率分布(注:也有很多文章喜欢用p、q来表示),这个东西能干嘛呢?
假设x是正确的概率分布,而y是我们预测出来的概率分布,这个公式算出来的结果,表示y与正确答案x之间的错误程度(即:y错得有多离谱),结果值越小,表示y越准确,与x越接近。
比如:
x的概率分布为:{1/4 ,1/4,1/4,1/4},现在我们通过机器学习,预测出来二组值:
y1的概率分布为 {1/4 , 1/2 , 1/8 , 1/8}
y2的概率分布为 {1/4 , 1/4 , 1/8 , 3/8}
从直觉上看,y2分布中,前2项都100%预测对了,而y1只有第1项100%对,所以y2感觉更准确,看看公式算下来,是不是符合直觉:

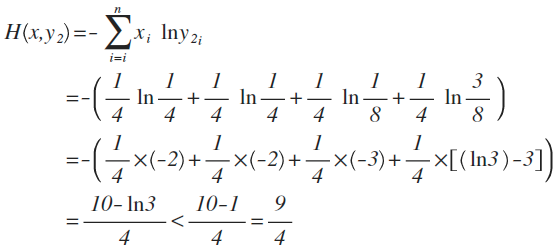
对比结果,H(x,y1)算出来的值为9/4,而H(x,y2)的值略小于9/4,根据刚才的解释,交叉熵越小,表示这二个分布越接近,所以机器学习中,经常拿交叉熵来做为损失函数(loss function)。
参考文章:
https://www.zhihu.com/question/23765351
https://www.zhihu.com/question/41252833/answer/108777563
https://www.zhihu.com/question/22178202
归一化(softmax)、信息熵、交叉熵的更多相关文章
- softmax、交叉熵
Softmax是用于分类过程,用来实现多分类的 它把一些输出的神经元映射到(0-1)之间的实数,并且归一化保证和为1,从而使得多分类的概率之和也刚好为1. Softmax可以分为soft和max,ma ...
- DL基础补全计划(二)---Softmax回归及示例(Pytorch,交叉熵损失)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 深度学习原理与框架-神经网络结构与原理 1.得分函数 2.SVM损失函数 3.正则化惩罚项 4.softmax交叉熵损失函数 5. 最优化问题(前向传播) 6.batch_size(批量更新权重参数) 7.反向传播
神经网络由各个部分组成 1.得分函数:在进行输出时,对于每一个类别都会输入一个得分值,使用这些得分值可以用来构造出每一个类别的概率值,也可以使用softmax构造类别的概率值,从而构造出loss值, ...
- softmax+交叉熵
1 softmax函数 softmax函数的定义为 $$softmax(x)=\frac{e^{x_i}}{\sum_j e^{x_j}} \tag{1}$$ softmax函数的特点有 函数值在[0 ...
- 【深度学习】softmax回归——原理、one-hot编码、结构和运算、交叉熵损失
1. softmax回归是分类问题 回归(Regression)是用于预测某个值为"多少"的问题,如房屋的价格.患者住院的天数等. 分类(Classification)不是问&qu ...
- 神经网络(NN)+反向传播算法(Backpropagation/BP)+交叉熵+softmax原理分析
神经网络如何利用反向传播算法进行参数更新,加入交叉熵和softmax又会如何变化? 其中的数学原理分析:请点击这里.
- 深度学习面试题07:sigmod交叉熵、softmax交叉熵
目录 sigmod交叉熵 Softmax转换 Softmax交叉熵 参考资料 sigmod交叉熵 Sigmod交叉熵实际就是我们所说的对数损失,它是针对二分类任务的损失函数,在神经网络中,一般输出层只 ...
- 【转载】深度学习中softmax交叉熵损失函数的理解
深度学习中softmax交叉熵损失函数的理解 2018-08-11 23:49:43 lilong117194 阅读数 5198更多 分类专栏: Deep learning 版权声明:本文为博主原 ...
- 交叉熵和softmax
深度学习分类问题结尾就是softmax,损失函数是交叉熵,本质就是极大似然...
随机推荐
- SonarQube代码质量管理工具的升级(sonarqube6.2 + sonar-scanner-2.8 + MySQL5.6+)
SonarQube升级注意事项 0. 前提条件 如果之前是使用sonarqube5.2 + sonar-runner-2.4 +MySQL5.5版本或者类似的组合. 安装方法请参照SonarQube代 ...
- SPOJ - MATSUM 二维树状数组单点更新
忘记了单点更新时要在树状数组中减去原值..wa了一发 /* 矩形求和,单点更改 */ #include<iostream> #include<cstring> #include ...
- ASP.NET Core 2 学习笔记(九)模型绑定
ASP.NET Core MVC的Model Binding会将HTTP Request数据,以映射的方式对应到参数中.基本上跟ASP.NET MVC差不多,但能Binding的来源更多了一些.本篇将 ...
- ***php进行支付宝开发中return_url和notify_url的区别分析
本文实例分析了php进行支付宝开发中return_url和notify_url的区别.分享给大家供大家参考.具体分析如下: 在支付宝处理业务中return_url,notify_url是返回些什么状态 ...
- bootstrap改变上传文件按钮样式,并显示已上传文件名
参考博文: html中,文件上传时使用的<input type="file">的样式自定义 html中<input type="file"&g ...
- RISC-V架构简介
大道至简——RISC-V架构之魂(上)https://blog.csdn.net/zoomdy/article/details/79580529 大道至简——RISC-V架构之魂(中)https:// ...
- 解决Delphi7的自带的UTF-8编码转换函数BUG
Delphi7及其以下版本的 VCL 只支持 Ansi, 所以... WideString 与 UTF8String (定义与 AnsiString 相同) 并没有办法正确的在 VCL 中显示 Del ...
- AOJ 2170 Marked Ancestor[并查集][离线]
题意: 给你一颗N个节点的树,节点编号1到N.1总是节点的根.现在有两种操作: M v: 标记节点v Q v: 求出离v最近的标记的相邻节点.根节点一开始就标记好了. 现在给一系列操作,求出所有Q操作 ...
- 解决asp.net 报错 无法获取所需的权限错误
asp.net 报错 无法获取所需的权限 无法获取所需的权限.说明: 执行当前 Web 请求期间,出现未处理的异常.请检查堆栈跟踪信息,以了解有关该错误以及代码中导致错误的出处的详细信息. 无法获取所 ...
- python全栈开发day14--内置函数和匿名函数