强化学习--Actor-Critic---tensorflow实现
完整代码:https://github.com/zle1992/Reinforcement_Learning_Game
Policy Gradient 可以直接预测出动作,也可以预测连续动作,但是无法单步更新。
QLearning 先预测出Q值,根据Q值选动作,无法预测连续动作、或者动作种类多的情况,但是可以单步更新。
一句话概括 Actor Critic 方法:
结合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法.
Actor 基于概率选行为 Critic 基于 Actor 的行为评判行为的得分,
Actor 根据 Critic 的评分修改选行为的概率.
Actor Critic 方法的优势: 可以进行单步更新, 比传统的 Policy Gradient 要快.
Actor Critic 方法的劣势: 取决于 Critic 的价值判断, 但是 Critic 难收敛, 再加上 Actor 的更新, 就更难收敛. 为了解决收敛问题, Google Deepmind 提出了 Actor Critic 升级版 Deep Deterministic Policy Gradient. 后者融合了 DQN 的优势, 解决了收敛难的问题.
Actor Critic 方法与Policy Gradinet的区别:
Policy Gradinet 中的梯度下降 :
grad[logPi(s,a) * v_t]
其中v_t是真实的reward ,通过记录每个epoch的每一个state,action,reward得到。
而Actor中的v_t 是td_error 由Critic估计得到,不一定准确哦。
Actor Critic 方法与DQN的区别:
DQN 评价网络与动作网络其实是一个网络,只是采用了TD的方法,用滞后的网络去评价当前的动作。
Actor-Critic 就是在求解策略的同时用值函数进行辅助,用估计的值函数替代采样的reward,提高样本利用率。
Q-learning 是一种基于值函数估计的强化学习方法,Policy Gradient是一种策略搜索强化学习方法
Critic估计td_error跟DQN一样,用到了贝尔曼方程,
贝尔曼方程 :
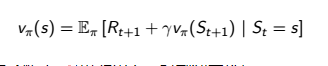
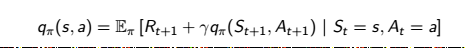
Critic利用的是V函数的贝尔曼方程,来得到TD_error,
gradient = grad[r + gamma * V(s_) - V(s)]
Q-learning 利用的是Q函数的贝尔曼方程,来更新Q函数。
q_target = r + gamma * maxq(s_next)
q_eval = maxq(s)
Actor网络的输入(st,at,TDerror)
Actor 网络与policy gradient 差不多,多分类网络,在算loss时候,policy gradient需要乘一个权重Vt,而Vt是根据回报R 累计计算的。
在Actor中,在算loss时候,loss的权重是TDerror
TDerror是Critic网络计算出来的。
Critic网络的输入(st,vt+1,r),输出TDerror
V_eval = network(st)
# TD_error = (r+gamma*V_next) - V_eval
学习的时候输入:(st, r, st+1)
vt+1 = network(st+1)
Critic网络(st,vt+1,r)
ACNetwork.py
import os
import numpy as np
import tensorflow as tf
from abc import ABCMeta, abstractmethod
np.random.seed(1)
tf.set_random_seed(1) import logging # 寮曞叆logging妯″潡
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s') # logging.basicConfig鍑芥暟瀵规棩蹇楃殑杈撳嚭鏍煎紡鍙婃柟寮忓仛鐩稿叧閰嶇疆
# 鐢变簬鏃ュ織鍩烘湰閰嶇疆涓骇鍒缃负DEBUG锛屾墍浠ヤ竴涓嬫墦鍗颁俊鎭皢浼氬叏閮ㄦ樉绀哄湪鎺у埗鍙颁笂 tfconfig = tf.ConfigProto()
tfconfig.gpu_options.allow_growth = True
session = tf.Session(config=tfconfig) class ACNetwork(object):
__metaclass__ = ABCMeta
"""docstring for ACNetwork"""
def __init__(self,
n_actions,
n_features,
learning_rate,
memory_size,
reward_decay,
output_graph,
log_dir,
model_dir,
):
super(ACNetwork, self).__init__() self.n_actions = n_actions
self.n_features = n_features
self.learning_rate=learning_rate
self.gamma=reward_decay
self.memory_size =memory_size
self.output_graph=output_graph
self.lr =learning_rate self.log_dir = log_dir self.model_dir = model_dir
# total learning step
self.learn_step_counter = 0 self.s = tf.placeholder(tf.float32,[None]+self.n_features,name='s')
self.s_next = tf.placeholder(tf.float32,[None]+self.n_features,name='s_next') self.r = tf.placeholder(tf.float32,[None,],name='r')
self.a = tf.placeholder(tf.int32,[None,],name='a') with tf.variable_scope('Critic'): self.v = self._build_c_net(self.s, scope='v', trainable=True)
self.v_ = self._build_c_net(self.s_next, scope='v_next', trainable=False) self.td_error =self.r + self.gamma * self.v_ - self.v
self.loss_critic = tf.square(self.td_error)
with tf.variable_scope('train'):
self.train_op_critic = tf.train.AdamOptimizer(self.lr).minimize(self.loss_critic) with tf.variable_scope('Actor'):
self.acts_prob = self._build_a_net(self.s, scope='actor_net', trainable=True)
# this is negative log of chosen action
log_prob = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=self.acts_prob, labels=self.a) self.loss_actor = tf.reduce_mean(log_prob*self.td_error)
with tf.variable_scope('train'):
self.train_op_actor = tf.train.AdamOptimizer(self.lr).minimize(-self.loss_actor) self.sess = tf.Session()
if self.output_graph:
tf.summary.FileWriter(self.log_dir,self.sess.graph) self.sess.run(tf.global_variables_initializer()) self.cost_his =[0] self.saver = tf.train.Saver() if not os.path.exists(self.model_dir):
os.mkdir(self.model_dir) checkpoint = tf.train.get_checkpoint_state(self.model_dir)
if checkpoint and checkpoint.model_checkpoint_path:
self.saver.restore(self.sess, checkpoint.model_checkpoint_path)
print ("Loading Successfully")
self.learn_step_counter = int(checkpoint.model_checkpoint_path.split('-')[-1]) + 1 @abstractmethod
def _build_a_net(self,x,scope,trainable): raise NotImplementedError
def _build_c_net(self,x,scope,trainable): raise NotImplementedError
def learn(self,data): batch_memory_s = data['s']
batch_memory_a = data['a']
batch_memory_r = data['r']
batch_memory_s_ = data['s_'] _, cost = self.sess.run(
[self.train_op_critic, self.loss_critic],
feed_dict={
self.s: batch_memory_s,
self.a: batch_memory_a,
self.r: batch_memory_r,
self.s_next: batch_memory_s_, }) _, cost = self.sess.run(
[self.train_op_actor, self.loss_actor],
feed_dict={
self.s: batch_memory_s,
self.a: batch_memory_a,
self.r: batch_memory_r,
self.s_next: batch_memory_s_, }) self.cost_his.append(cost) self.learn_step_counter += 1
# save network every 100000 iteration
if self.learn_step_counter % 10000 == 0:
self.saver.save(self.sess,self.model_dir,global_step=self.learn_step_counter) def choose_action(self,s):
s = s[np.newaxis,:] probs = self.sess.run(self.acts_prob,feed_dict={self.s:s})
return np.random.choice(np.arange(probs.shape[1]), p=probs.ravel())
game.py
import sys
import gym
import numpy as np
import tensorflow as tf
sys.path.append('./')
sys.path.append('model') from util import Memory ,StateProcessor
from ACNetwork import ACNetwork
np.random.seed(1)
tf.set_random_seed(1) import logging # 引入logging模块
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s') # logging.basicConfig函数对日志的输出格式及方式做相关配置
# 由于日志基本配置中级别设置为DEBUG,所以一下打印信息将会全部显示在控制台上
import os
os.environ["CUDA_VISIBLE_DEVICES"] = ""
tfconfig = tf.ConfigProto()
tfconfig.gpu_options.allow_growth = True
session = tf.Session(config=tfconfig) class ACNetwork4CartPole(ACNetwork):
"""docstring for ClassName"""
def __init__(self, **kwargs):
super(ACNetwork4CartPole, self).__init__(**kwargs) def _build_a_net(self,x,scope,trainable):
w_initializer, b_initializer = tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) with tf.variable_scope(scope):
e1 = tf.layers.dense(inputs=x,
units=32,
bias_initializer = b_initializer,
kernel_initializer=w_initializer,
activation = tf.nn.relu,
trainable=trainable)
q = tf.layers.dense(inputs=e1,
units=self.n_actions,
bias_initializer = b_initializer,
kernel_initializer=w_initializer,
activation = tf.nn.softmax,
trainable=trainable) return q def _build_c_net(self,x,scope,trainable):
w_initializer, b_initializer = tf.random_normal_initializer(0., 0.3), tf.constant_initializer(0.1) with tf.variable_scope(scope):
e1 = tf.layers.dense(inputs=x,
units=32,
bias_initializer = b_initializer,
kernel_initializer=w_initializer,
activation = tf.nn.relu,
trainable=trainable)
q = tf.layers.dense(inputs=e1,
units=1,
bias_initializer = b_initializer,
kernel_initializer=w_initializer,
activation =None,
trainable=trainable) return q batch_size = 32 memory_size =100
#env = gym.make('Breakout-v0') #离散
env = gym.make('CartPole-v0') #离散 n_features= list(env.observation_space.shape)
n_actions= env.action_space.n
env = env.unwrapped def run(): RL = ACNetwork4CartPole(
n_actions=n_actions,
n_features=n_features,
learning_rate=0.01,
reward_decay=0.9, memory_size=memory_size, output_graph=True,
log_dir = 'log/ACNetwork4CartPole/', model_dir = 'model_dir/ACNetwork4CartPole/'
) memory = Memory(n_actions,n_features,memory_size=memory_size) step = 0
ep_r = 0
for episode in range(2000):
# initial observation
observation = env.reset() while True: # RL choose action based on observation
action = RL.choose_action(observation)
# logging.debug('action')
# print(action)
# RL take action and get_collectiot next observation and reward
observation_, reward, done, info=env.step(action) # take a random action # the smaller theta and closer to center the better
x, x_dot, theta, theta_dot = observation_
r1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5
reward = r1 + r2 memory.store_transition(observation, action, reward, observation_) if (step > 200) and (step % 1 == 0): data = memory.sample(batch_size)
RL.learn(data)
#print('step:%d----reward:%f---action:%d'%(step,reward,action))
# swap observation
observation = observation_
ep_r += reward
# break while loop when end of this episode
if(episode>700):
env.render() # render on the screen
if done:
print('step: ',step,
'episode: ', episode,
'ep_r: ', round(ep_r, 2),
'loss: ',RL.cost_his[-1]
)
ep_r = 0 break
step += 1 # end of game
print('game over')
env.destroy() def main(): run() if __name__ == '__main__':
main()
#run2()
强化学习--Actor-Critic---tensorflow实现的更多相关文章
- 深度增强学习--Actor Critic
Actor Critic value-based和policy-based的结合 实例代码 import sys import gym import pylab import numpy as np ...
- 学习笔记TF053:循环神经网络,TensorFlow Model Zoo,强化学习,深度森林,深度学习艺术
循环神经网络.https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/re ...
- adaptive heuristic critic 自适应启发评价 强化学习
https://www.cs.cmu.edu/afs/cs/project/jair/pub/volume4/kaelbling96a-html/node24.html [旧知-新知 强化学习:对 ...
- Deep Learning专栏--强化学习之从 Policy Gradient 到 A3C(3)
在之前的强化学习文章里,我们讲到了经典的MDP模型来描述强化学习,其解法包括value iteration和policy iteration,这类经典解法基于已知的转移概率矩阵P,而在实际应用中,我们 ...
- 机器学习之强化学习概览(Machine Learning for Humans: Reinforcement Learning)
声明:本文翻译自Vishal Maini在Medium平台上发布的<Machine Learning for Humans>的教程的<Part 5: Reinforcement Le ...
- 深度强化学习:Policy-Based methods、Actor-Critic以及DDPG
Policy-Based methods 在上篇文章中介绍的Deep Q-Learning算法属于基于价值(Value-Based)的方法,即估计最优的action-value function $q ...
- Flink + 强化学习 搭建实时推荐系统
如今的推荐系统,对于实时性的要求越来越高,实时推荐的流程大致可以概括为这样: 推荐系统对于用户的请求产生推荐,用户对推荐结果作出反馈 (购买/点击/离开等等),推荐系统再根据用户反馈作出新的推荐.这个 ...
- 强化学习(十六) 深度确定性策略梯度(DDPG)
在强化学习(十五) A3C中,我们讨论了使用多线程的方法来解决Actor-Critic难收敛的问题,今天我们不使用多线程,而是使用和DDQN类似的方法:即经验回放和双网络的方法来改进Actor-Cri ...
- 强化学习(十五) A3C
在强化学习(十四) Actor-Critic中,我们讨论了Actor-Critic的算法流程,但是由于普通的Actor-Critic算法难以收敛,需要一些其他的优化.而Asynchronous Adv ...
随机推荐
- Java 输入/输出——重定向标准输入/输出
在System类中提供了如下三个重定向标准输入/输出方法. static void setErr(PrintStream err) Reassigns the "standard" ...
- 压缩维度oj P1173+P1174+P1164
今天在洛谷上刷dp,忽然冒出一道求最大字段和的问题,然后忘了瞬间忘了这是dp,几分钟一个贪心出来了成功ac,忽然想起自己在作dp,于是乖乖刷dp. 这个可能很多人都会但是今天有4种解法哦,本人只尝试了 ...
- delphi加载ADOQUERY
CxgridDBTableView3.ClearItems;//这里是cxgrid的表层,先清除之前的列再创建 for I:=0 to adoquery1.FieldCount-1 do begi ...
- Active MQ Fileserver 远程代码执行 (CVE-2016-3088)
ActiveMQ漏洞( CVE-2016-3088)利用拿下root权限主机 1.扫描目标主机 MacPC:~ liuxin$ nmap -Pn -p8161 -sV 192.168.xx.xx -- ...
- 内部排序->插入排序->直接插入排序
文字描述: 将一个记录插入到已排好序的有序表中,从而得到一个新的.记录数增1的有序表 示意图: 算法分析: 时间复杂度为n*n,辅助存储为1,是稳定的排序方法. 代码实现: #include < ...
- kubernetes微服务部署
1.哪些服务适合单独成为一个pod?哪些服务适合在一个pod中? message消息服务被很多服务调用 单独一个pod dubbo服务和web服务交互很高放在同一个pod里 API网关调用很多服务 ...
- 洛谷 P3521 ROT-Tree Rotations [POI2011] 线段树
正解:线段树合并 解题报告: 传送门! 今天学了下线段树合并,,,感觉线段树相关的应用什么的还是挺有趣的,今天晚上可能会整理一下QAQ? 然后直接看这道题 现在考虑对一个节点nw,现在已经分别处理出它 ...
- 深入了解HBASE架构(转)
dd by zhj: 最近的工作需要跟HBase打交道,所以花时间把<HBase权威指南>粗略看了一遍,感觉不过瘾,又从网上找了几篇经典文章. 下面这篇就是很经典的文章,对HBase的架构 ...
- (4.7)mysql备份还原——深入解析二进制日志(3)binlog的三种日志记录模式详解
关键词:binlog模式,binlog,二进制日志,binlog日志 目录概述 0.binlog概述 查看binlog日志参数设置: show variables like '%log_bin%'; ...
- OC动画:CAKeyframeAnimation
// 方法一 用法1 Value方式 //创建动画对象 CAKeyframeAnimation *animation = [CAKeyframeAnimation animationWithKeyP ...