AI应用实战课学习总结(2)hello sk-learn
大家好,我是Edison。
最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第2站,了解下scikit-learn框架(简称sk-learn)及相关的常用可视化库,一起和机器学习说声“Hello World”!
机器学习是什么?
上一篇,我们了解到:机器学习(Machine Learning)的本质是:用函数模拟事物关系。
机器学习约等于从数据中习得一个函数完成某个任务,如价格预测、图像识别等。
那么,作为一个CRUD程序员,要快速入门机器学习,基于Python语言和其丰富的机器学习生态,可以让我们快速了解入坑。
为了实现今天的目标,建议你安装以下工具:
Anaconda 3 (也可以不用,但对新手来说这个比较方便,Python也一起安装了)
Python 3.12 (如果不安装Anaconda,那么需要单独安装Python SDK)
Visual Studio Code,同时在VS Code中安装两个扩展
Python
Jupyter
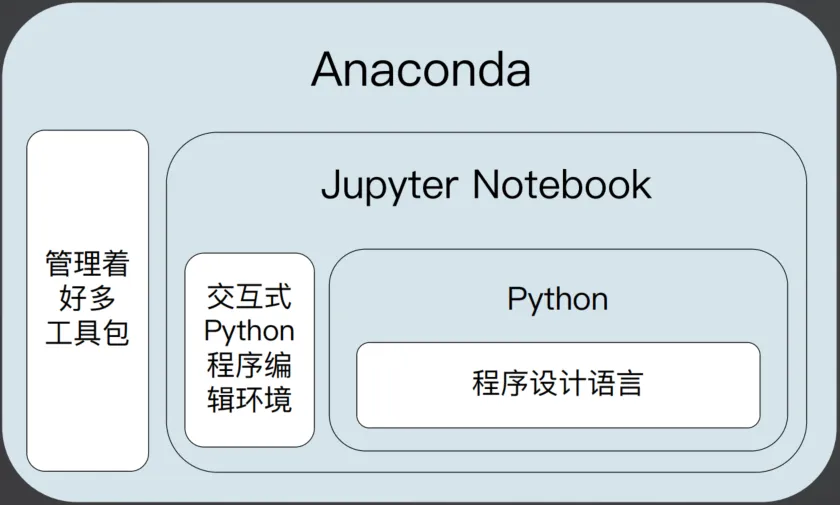
这里重点说下 Ananconda、Jupyter 和 Python 的关系,如下图所示。Jupyter Notebook是一个像学习笔记风格的Python IDE,非常适合我们这样的Python新手,不过呢,这里我们不使用独立的Jupyter Notebook,而是在Visual Studio Code使用Jupyter的扩展即可。
scikit-learn机器学习框架
有了上面的开发工具,我们就需要一把剑了,这把剑就是机器学习框架,这里我们选择scikit-learn。
在Python生态中,大多数只能称其为库(Library),而只有像TensorFlow、Pytorch和Scikit-Learn才能被称之为框架(Framework)。
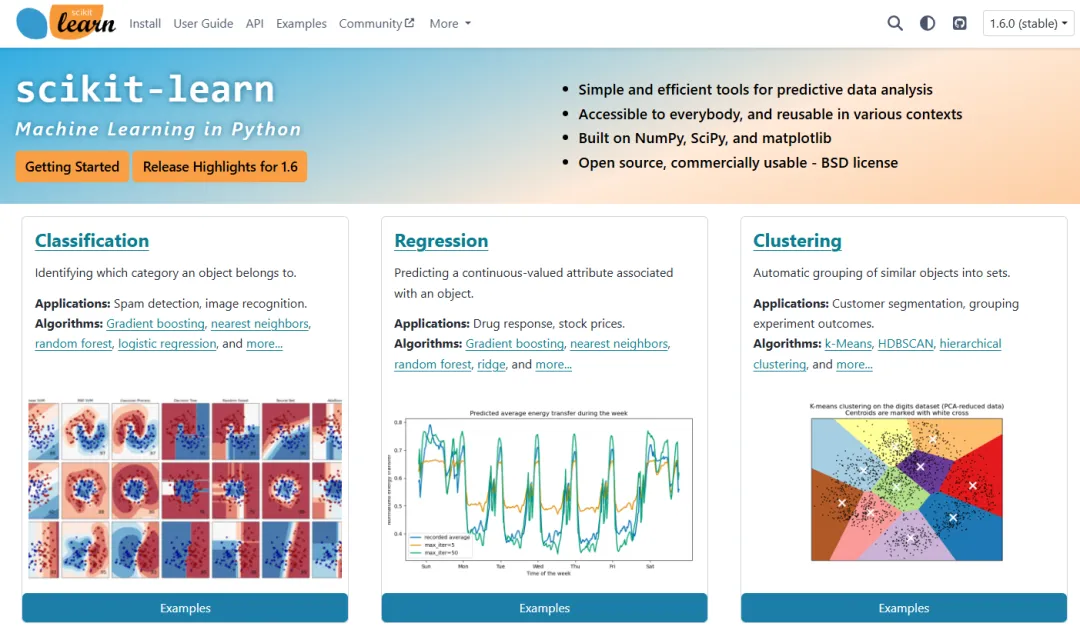
scikit-learn也称sk-learn,是目前最流行的开源机器学习工具,它基于NumPy、SciPy和Matplotlib这几个库构建,支持如下所示的各种常见的分类、回归和聚类算法,简直就是一站式算法和模型服务到家:
支持向量机(SVM)
随机森林
梯度提升
K-Means
DBSCAN等等
除此之外,scikit-learn还提供了一系列的工具,可以做数据预处理、特征选择、模型评估,还有一系列的机器学习流程的pipeline,方便我们可以直接上手做实际的项目。
最后,scikit-learn是开源项目,有广泛的社区支持,和其他开源库如NumPy, SciPy, Pandas, matplotlib, seaborn, plotly等有良好的集成,可以方便地结合在一起使用。

数据可视化展示库
做机器学习时,往往需要做一些数据分析结果的可视化展示从而让枯燥的数字变得有趣,这就可以用到几个可视化库如Matplotlib、Seaborn 以及 Plotly。
首先,Matplotlib 是 Python 生态中最老牌的可视化库,画图功能超多,从简单的折线图到复杂的3D图表都不在话下。特点是简单、灵活、支持多种图形,科研必备。
其次,Seaborn 库就是基于 Matplotlib 开发的一个统计可视化神器,它不光能画出好看的图,还自带统计功能。特点是易用、美观,专注于统计图形。
最后,Plotly是一个交互式的、开源的绘图库,它支持许多独特的图表类型,覆盖广泛的领域,如统计、金融、地理、科学和三维用例。
如何选择机器学习算法?
scikit-learn社区为机器学习新手提供了一个算法选择指南,我们可以根据现状来做选择题,可以大大提升我们的效率。
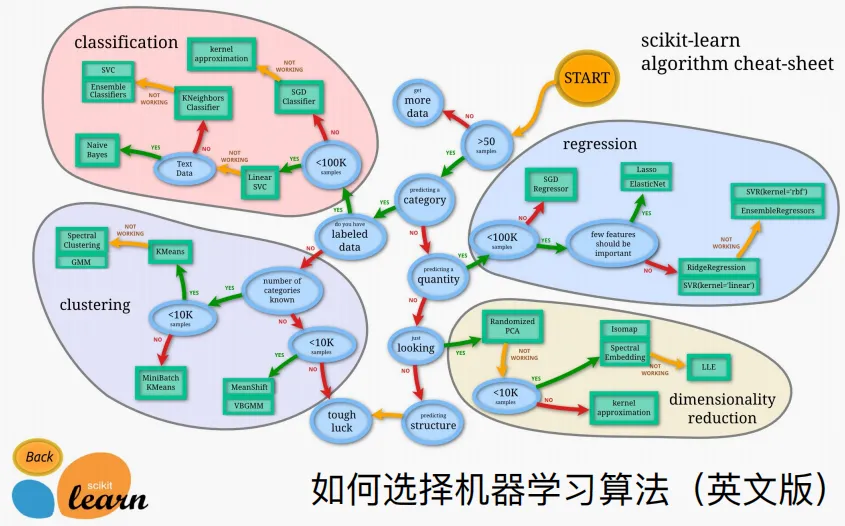
从上图可以看出,基于已有数据量和是否做类别预测,进行分支选择,就能知道该怎么玩,有点像所谓的最佳实践指南。
做预测类别,就走分类算法。如果走分类场景时数据没有标签,就走聚类算法。
预测数值,就走回归算法。
进行数据可视化,就走降维算法。
Hello World!
这里我们使用scikit-learn来写个hello world! 这是一个使用降维算法做数据展示的简单示例demo,来自scikit-learn内置的教学用的小型标准数据集:鸢尾花数据集Iris。
该数据集包含了 150 个鸢尾花的数据,其中每个数据点都有 4 个特征(萼片长度、萼片宽度、花瓣长度、花瓣宽度)和 3个标签(鸢尾草-setosa、蝴蝶花-versicolor、维吉尼亚鸢尾-virginica,代表鸢尾花的3种类别)。该数据集最初由 R.A. Fisher 在 1936 年发布,目前在sk-learn中用来做机器学习入门,测试分类算法性能 以及 进行数据可视化和降维的练习。这里,我们就在Visual Studio Code中新建一个 hello-sk-learn.ipynb 文件,开始我们的第一个机器学习程序,做一个简单的降维展示。注意:这里我们作为算法使用者,不需要关心其内部原理和实现,仅仅体验怎么用。
首先,我们从sk-learn导入数据集和加载数据集:
from sklearn import datasets # 导入数据集
iris = datasets.load_iris() # 加载数据集 print("feature names:", iris.feature_names) # 查看有哪些特征
print("tag names:", iris.target_names) # 查看有哪些标签(类别) X = iris.data # 特征
y = iris.target # 标签
这里,我们还打印出了特征集 和 标签集,显示如下内容:
feature names: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
tag names: ['setosa' 'versicolor' 'virginica']
其次,我们从sklearn导入PCA算法(做主成分分析的算法),加载模型,执行数据降维任务(这里是从4个特征降到2个特征):
from sklearn.decomposition import PCA # 导入PCA算法(主成分分析)
pca = PCA(n_components=2) # 加载模型,指定保留两个主要特征
X_r = pca.fit(X).transform(X) # 执行降维
这里的X_r就是降维后的2个主要特征集。可以看到,要做降维,只需要一个fix和transform两个函数调用即可,十分方便!基本的降维算法使用就是这两步了。
最后,为了方便我们直观看到,使用matplotlib进行一个数据展示,将降维后的特征进行可视化,通过定义三种不同的颜色来显示目标标签:
import matplotlib.pyplot as plt
target_names = iris.target_names
colors = ["navy", "turquoise", "darkorange"]
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(
X_r[y == i, 0], X_r[y == i, 1], color=color, alpha=0.8, lw=2, label=target_name
)
plt.legend(loc="best", shadow=False, scatterpoints=1)
plt.figure()
最终Run起来的结果展示如下图所示:
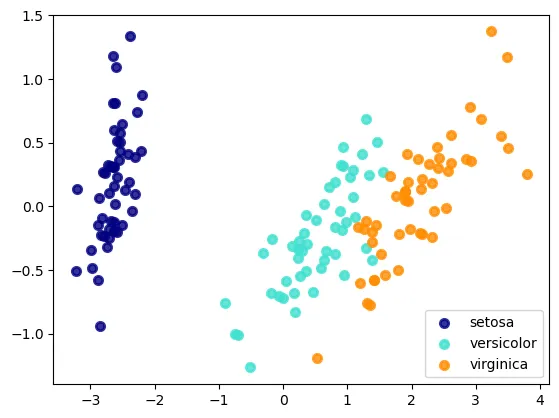
从上面的点状图可以明显地看到,在接近的特征值下,同一种类的鸢尾花会大致集中在一起。
小结
本文快速搭建了Python机器学习的开发环境,并通过一个简单的降维示例学习了scikit-learn的基本用法,完成了一个hello world程序。
最后,听闻Microsoft在Visual Studio Code中免费开放使用GitHub Copilot,这对于我们开发者来说是真正的好消息!大家都去用起来吧,有机会多多交流哈!
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)

AI应用实战课学习总结(2)hello sk-learn的更多相关文章
- DDD实战课--学习笔记
目录 学好了DDD,你能做什么? 领域驱动设计:微服务设计为什么要选择DDD? 领域.子域.核心域.通用域和支撑域:傻傻分不清? 限界上下文:定义领域边界的利器 实体和值对象:从领域模型的基础单元看系 ...
- 《Angular4从入门到实战》学习笔记
<Angular4从入门到实战>学习笔记 腾讯课堂:米斯特吴 视频讲座 二〇一九年二月十三日星期三14时14分 What Is Angular?(简介) 前端最流行的主流JavaScrip ...
- [AI开发]将深度学习技术应用到实际项目
本文介绍如何将基于深度学习的目标检测算法应用到具体的项目开发中,体现深度学习技术在实际生产中的价值,算是AI算法的一个落地实现.本文算法部分可以参见前面几篇博客: [AI开发]Python+Tenso ...
- Python第十课学习
Python第十课学习 www.cnblogs.com/yuanchenqi/articles/5828233.html 函数: 1 减少代码的重复 2 更易扩展,弹性更强:便于日后文件功能的修改 3 ...
- Python第九课学习
Python第九课学习 数据结构: 深浅拷贝 集合set 函数: 概念 创建 参数 return 定义域 www.cnblogs.com/yuanchenqi/articles/5782764.htm ...
- Python第八课学习
Python第八课学习 www.cnblogs.com/resn/p/5800922.html 1 Ubuntu学习 根 / /: 所有目录都在 /boot : boot配置文件,内核和其他 linu ...
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别 http://phunter.farbox.com/post/mxnet-tutorial1 用MXnet实战深度学 ...
- 《机器学习实战》学习笔记第十四章 —— 利用SVD简化数据
相关博客: 吴恩达机器学习笔记(八) —— 降维与主成分分析法(PCA) <机器学习实战>学习笔记第十三章 —— 利用PCA来简化数据 奇异值分解(SVD)原理与在降维中的应用 机器学习( ...
- 《机器学习实战》学习笔记第九章 —— 决策树之CART算法
相关博文: <机器学习实战>学习笔记第三章 —— 决策树 主要内容: 一.CART算法简介 二.分类树 三.回归树 四.构建回归树 五.回归树的剪枝 六.模型树 七.树回归与标准回归的比较 ...
- 《Python3 网络爬虫开发实战》学习资料
<Python3 网络爬虫开发实战> 学习资料 百度网盘:https://pan.baidu.com/s/1PisddjC9e60TXlCFMgVjrQ
随机推荐
- 泛型--java进阶day10
1.泛型 2.泛型--统一数据类型 如下图,当我们在泛型中添加不同的数据类型,add方法需要的数据类型也随之改变 [1] [2] 泛型--默认类型object 当我们不指定泛型时,泛型的默认类型为ob ...
- 包和抽象类介绍--java进阶day02
1.package包 导包第二点需要注意 a包和b包都存有Student类,c包存有测试类,我们在c中创建Student对象,系统会询问你要哪个包的Student类,并自动帮你导包 . 在导完a包的学 ...
- 【数据库】Java实体类的属性类型与数据库表字段类型对应表
JDBC类型与Java类型 JDBC类型 Java Object类型 CHAR java.lang.String VARCHAR java.lang.String LONGVARCHAR java.l ...
- `QualitySettings.asyncUploadPersistentBuffer
在 Unity 中,`QualitySettings.asyncUploadPersistentBuffer` 是一个静态属性,它控制着纹理上传到 GPU 的异步方式.当启用时(设置为 `true`) ...
- c++指针传递与引用传递
c 不支持引用传递的! 在 C++中,指针传递和引用传递是两种常用的参数传递方式,它们各自有不同的特点和适用场景.下面是两者之间的主要区别: 1. 语法和使用 指针传递 定义和调用:函数参数是一个指针 ...
- eolinker响应预处理:传参解决方法(响应数据截取后设置为变量)
特别注意:需要使用全局变量或者预处理前务必阅读本链接https://www.cnblogs.com/becks/p/13713278.html 一.案例1 1.场景描述: 后一个请求需要前一个请求提供 ...
- Vue横向滚动鼠标控制
let level_cards // 标记可移动 , move_start // 移动初始的x位置 , move_x // 移动初始的容器偏移量 , move_scroll_left // 判断是否为 ...
- Email邮箱验证码发送
以下文件保存到/static/email.txt <!DOCTYPE html> <html lang="en" xmlns:th="http://ww ...
- 读项目NeteaseCloudMusicGtk4
netease-cloud-music-gtk4 是基于 GTK4 + Libadwaita 构造的网易云音乐播放器,专为 Linux 系统打造,已在 openSUSE Tumbleweed + GN ...
- 反悔贪心&局部调整法学习笔记
一.什么是反悔贪心 反悔贪心就是在普通贪心的过程中"反悔",从而使得一些看似不太好贪心的题变成贪心可做题. 二.反悔贪心普遍流程 就是先使用一个好想的贪心策略,使用优先队列进行维护 ...