数栈技术分享:开源·数栈-扩展FlinkSQL实现流与维表的join
一、扩展FlinkSQL实现流与维表的join

二、为什么要扩展FlinkSQL?
1、实时计算需要完全SQL化
SQL是数据处理中使用最广泛的语言。它允许用户简明扼要地声明他们的业务逻辑。大数据批计算使用SQL很常见,但是支持SQL的实时计算并不多。其实,用SQL开发实时任务可以极大降低数据开发的门槛,在袋鼠云数栈-实时计算模块,我们决定实现完全SQL化。
数据计算采用SQL的优势
声明式。用户只需要表达我想要什么,至于怎么计算那是系统的事情,用户不用关心。
自动调优。查询优化器可以为用户的 SQL 生成最有的执行计划。用户不需要了解它,就能自动享受优化器带来的性能提升。
易于理解。很多不同行业不同领域的人都懂 SQL,SQL 的学习门槛很低,用 SQL 作为跨团队的开发语言可以很大地提高效率。
稳定。SQL 是一个拥有几十年历史的语言,是一个非常稳定的语言,很少有变动。所以当我们升级引擎的版本时,甚至替换成另一个引擎,都可以做到兼容地、平滑地升级。
参考链接:https://blog.csdn.net/weixin_33827965/article/details/86723623
2、实时计算还需要流与维表的JOIN
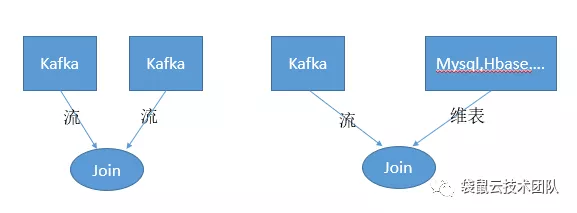
在实时计算的世界里不只是流与流的JOIN,还需要流与维表的JOIN。在去年,袋鼠云数栈V3.0版本研发期间,当时最新版本——flink1.6中FlinkSQL,已经将SQL的优势应用到Flink引擎中,但还未支持流与维表的JOIN。
FlinkSQL于2017年7月开始面向阿里巴巴集团开放流计算服务的,虽然是一个非常年轻的产品,但是到双11期间已经支撑了数千个作业,在双11期间,Blink 作业的处理峰值达到了5+亿每秒,而其中仅 Flink SQL 作业的处理总峰值就达到了3亿/秒。
参考链接:https://yq.aliyun.com/articles/457438
里先解释下什么是维表;维表是动态表,表里所存储的数据有可能不变,也有可能定时更新,但是更新频率不是很频繁。在业务开发中一般的维表数据存储在关系型数据库如mysql,oracle等,也可能存储在hbase,redis等nosql数据库。
三、FlinkSQL实现流与维表的join分步走
1、用Flink api实现维表的功能
要实现维表功能就要用到 Flink Aysnc I/O 这个功能,是由阿里巴巴贡献给Apache Flink的。
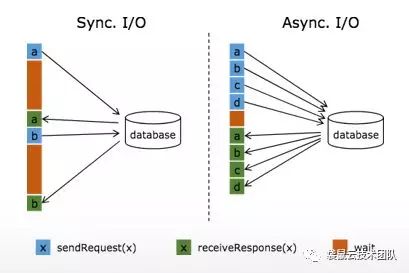
Async I/O 是由阿里巴巴贡献给社区的,于1.2版本引入,主要目的是为了解决与外部系统交互时网络延迟成为了系统瓶颈的问题。
具体介绍可以看这篇文章:http://wuchong.me/blog/2017/05/17/flink-internals-async-io/
对应到Flink 的api就是RichAsyncFunction 这个抽象类,继层这个抽象类实现里面的open(初始化),asyncInvoke(数据异步调用),close(停止的一些操作)方法,最主要的是实现asyncInvoke 里面的方法。
流与维表的join会碰到两个问题:
1)第一个是性能问题。
因为流速要是很快,每一条数据都需要到维表做下join,但是维表的数据是存在第三方存储系统,如果实时访问第三方存储系统,不仅join的性能会差,每次都要走网络io;还会给第三方存储系统带来很大的压力,有可能会把第三方存储系统搞挂掉。
所以解决的方法就是维表里的数据要缓存,可以全量缓存,这个主要是维表数据不大的情况,还有一个是LRU缓存,维表数据量比较大的情况。
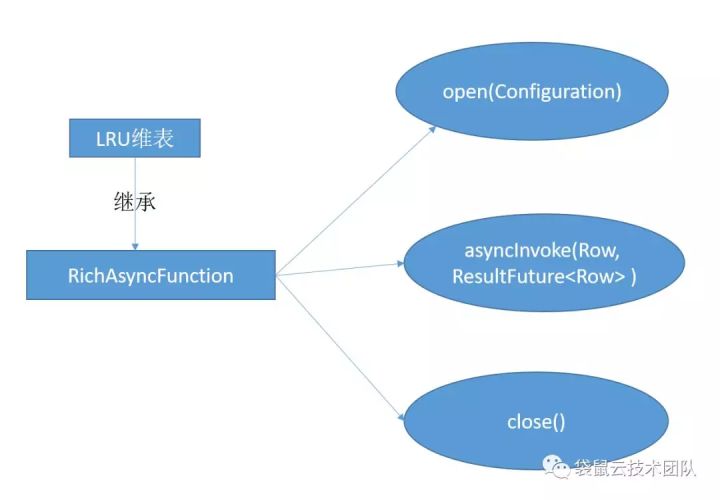
2)第二个问题是流延迟过来的数据这么跟之前的维表数据做关联。
这个就涉及到维表数据需要存储快照数据,所以这样的场景用HBase 做维表是比较适合的,因为HBase 是天生支持数据多版本的。
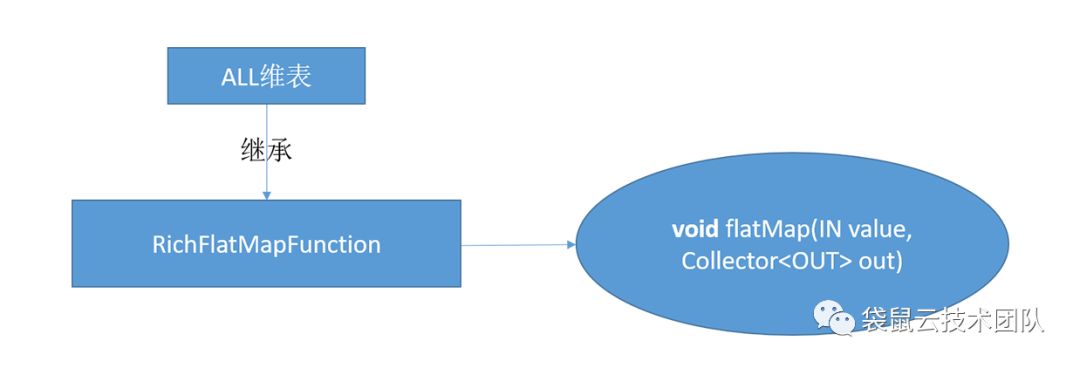
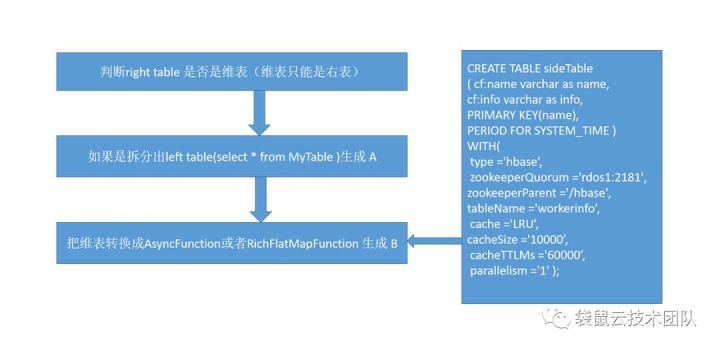
2、解析流与维表join的SQL语法转化成底层的FlinkAPI
因为FlinkSQL已经做了大部分SQL场景,我们不可能在去解析SQL的所有语法,在把他转化成底层FlinkAPI。
所以我们做的就是解析SQL语法,来找到join表里有没有维表,如果有维表,那我们会把这个join的维表的语句单独拆来,用Flink的TableAPI和StreamAPi 生成新DataStream,在把这个DataStream与其他的表在做join这样就能用SQL来实现流与维表的join语法了。
SQL解析的工具就是用Apache calcite,Flink也是用这个框架做SQL解析的。所以所有语法都是可以解析的。
1)DEMO SQL
insert
into
MyResult
select
d.channel,
d.info
from
( select a.*,b.info
from
MyTable a
join sideTable b
on a.channel=b.name
where a.channel = 'xc2’
and a.pv=10 ) as d
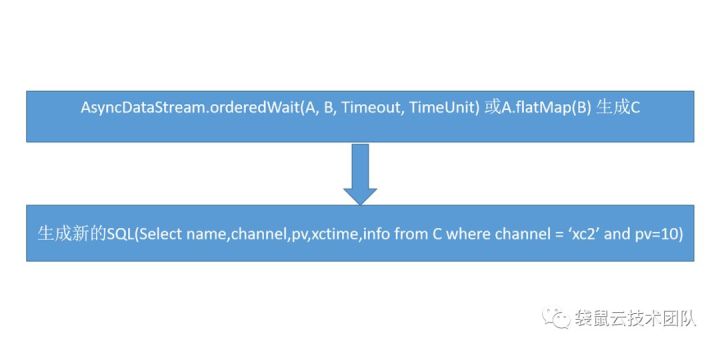
2)Calcite解析Insert into语句,拆分出子语句
select a.*,b.info from MyTable a join sideTable b on a.channel=b.name
where a.channel = 'xc2' and a.pv=10
select d.channel, d.info from d
insert into MyResult
3) Calcite继续解析select语句
old: select a.*,b.info from MyTable a join sideTable b on a.channel=b.name
where a.channel = 'xc2' and a.pv=10
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
数栈技术分享:开源·数栈-扩展FlinkSQL实现流与维表的join的更多相关文章
- 袋鼠云研发手记 | 开源·数栈-扩展FlinkSQL实现流与维表的join
作为一家创新驱动的科技公司,袋鼠云每年研发投入达数千万,公司80%员工都是技术人员,袋鼠云产品家族包括企业级一站式数据中台PaaS数栈.交互式数据可视化大屏开发平台Easy[V]等产品也在迅速迭代.在 ...
- 出栈顺序 与 卡特兰数(Catalan)的关系
一,问题描述 给定一个以字符串形式表示的入栈序列,请求出一共有多少种可能的出栈顺序?如何输出所有可能的出栈序列? 比如入栈序列为:1 2 3 ,则出栈序列一共有五种,分别如下:1 2 3.1 3 2 ...
- 【讲●解】火车进出栈类问题 & 卡特兰数应用
火车进出栈类问题详讲 & 卡特兰数应用 引题:火车进出栈问题 [题目大意] 给定 \(1\)~\(N\) 这\(N\)个整数和一个大小无限的栈,每个数都要进栈并出栈一次.如果进栈的顺序为 \( ...
- 微人事 star 数超 10k,如何打造一个 star 数超 10k 的开源项目
看了下,微人事(https://github.com/lenve/vhr)项目 star 数超 10k 啦,松哥第一个 star 数过万的开源项目就这样诞生了. 两年前差不多就是现在这个时候,松哥所在 ...
- 感知开源的力量-APICloud Studio开源技术分享会
2014.9.15 中国领先的“云端一体”移动应用云服务提供商APICloud正式发布2015.9.15,APICloud上线一周年,迎来第一个生日这一天,APICloud 举办APICloud St ...
- 性能1.84倍于Ceph!网易数帆Curve分布式存储开源
在上周刚结束的网易数字+大会上 网易数帆宣布: 开源一款名为Curve的高性能分布式存储系统, 性能可达Ceph的1.84倍! 网易副总裁.网易杭州研究院执行院长兼网易数帆总经理汪源: 基础软件的能力 ...
- 81For全栈技术网
你想了解前端吗? 你想了解后端吗? 你想了解设计吗? 81For全栈技术这里包含了互联网所有内容,81For.com是全栈技术网,包括:前端.后端.全栈.jquery.vue.react.router ...
- 第11章 拾遗5:IPv6和IPv4共存技术(1)_双栈技术和6to4隧道技术
6. IPv6和IPv4共存技术 6.1 双栈技术 (1)双协议主机的协议结构 (2)双协议栈示意图 ①双协议主机在通信时首先通过支持双协议的DNS服务器查询与目的主机名对应的IP地址. ②再根据指定 ...
- 全栈技术经理——团队管理:每周问问你的团队这这些问题 V1.0
全栈技术经理--团队管理:每周问问你的团队这这些问题 V1.0 1.本周取得了哪些进展? 通过回答这个问题可以让员工庆祝甚至夸耀一些自己的成果,包括那些跟最高优先级不相干而被忽视的小事情.借此你也 ...
- 阿里钉钉技术分享:企业级IM王者——钉钉在后端架构上的过人之处
本文引用了唐小智发表于InfoQ公众号上的“钉钉企业级IM存储架构创新之道”一文的部分内容,收录时有改动,感谢原作者的无私分享. 1.引言 业界的 IM 产品在功能上同质化较高,而企业级的 IM 产品 ...
随机推荐
- BUUCTF---这是什么
题目 题目给出apk 解题
- 分布式任务调度系统 xxl-job
微服务难不难,不难!无非就是一个消费方,一个生产方,一个注册中心,然后就是实现一些微服务,其实微服务的难点在于治理,给你一堆 微服务,如何来管理?这就有很多方面了,比如容器化,服务间通信,服务上下线发 ...
- Go 应用程序使用 dockerfile multi-stage 的问题
场景重现 一个简单的go应用,准备通过docker部署,为了减少运行时的镜像和容器体积,使用了multi-stage构建: # dockerfile 大致如下 # 一级构建使用带golang环境的镜像 ...
- Docker 实用镜像
实用镜像 nginx-proxy nginx-proxy sets up a container running nginx and docker-gen. ...
- DevOps的工作岗位的要求
## 为什么需要DevOps 不是每个人都能理解可靠的版本管理和牢固的构建系统的重要性. 也不是任何人能使得软件的发布达到可靠性,可重复性和可审计的高标准.Devops的职责就是将软件的构建和发布的流 ...
- idea git建立分支、切换分支、合并分支
为什么要建立分支 git默认的主分支名字为master,一般团队开发时,都不会在master主分支上修改代码,而是建立新分支,测试完毕后,在将分支的代码合并到master主分支上 2.操作如下: 2. ...
- px转rem适配方案之postcss-pxtorem
一.安装 npm install postcss-pxtorem --save-dev 二.增加postcss.config.js文件 在目录文件下增加postcss.config.js并添加相关配置 ...
- jmeter返回数据重新编码的方法
下图内容为请求后的返回值,红色箭头内容是需要正则处理传参给后面的接口使用 其中==后面的\U0026为未编码内容 而实际能够提交的链接为下图"&" 所以,图1请求后需要先转 ...
- Git常用命令大全:git命令基本用法
1. 常用的git命令 Git 常用的六个命令是什么? ·"git clone"克隆代码: ·"git log"查看日志: ·"git tag&quo ...
- 抽象方法(abstract)、虚方法(virtual)及接口(interface)
抽象方法(abstract).虚方法(virtual)及接口(interface) 抽象方法(abstract) 定义:abstract关键词标记的方法--抽象方法 特征: 抽象方法只能定义在抽象类里 ...