Mysql的整体架构设计
整体分层
- 连接层
- 服务层
- 存储引擎层
连接层
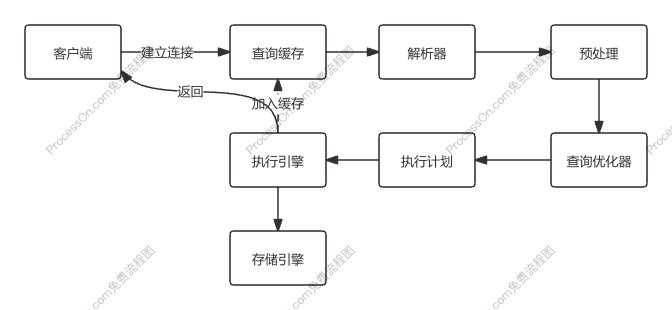
客户端要连接到服务器 3306 端口,必须要跟服务端建立连接,那么 管理所有的连接,验证客户端的身份和权限,这些功能就在连接层完成。
服务层
连接层会把 SQL 语句交给服务层,这里面又包含一系列的流程。
比如查询缓存的判断、根据 SQL 调用相应的接口,对SQL 语句进行词法和语 法的解析(比如关键字怎么识别,别名怎么识别,语法有没有错误等等)
然后就是优化器,MySQL 底层会根据一定的规则对我们的 SQL 语句进行优化,最 后再交给执行器去执行。
存储引擎
存储引擎就是数据真正存放的地方, 再往下就是内存或者磁盘
一个查询执行流程
show global variables like 'wait_timeout';常见的连接池中连接等待时间
show global variables like 'interactive_timeout';可视化工具使用的非交互式超时时间
超时时间默认8小时,可以根据系统实际情况调整。
show global status like 'Thread%';查看当前的连接数量。
Threads_cached:缓存中的线程连接数。
Threads_connected:当前打开的连接数。
Threads_created:为处理连接创建的线程数。
Threads_running:非睡眠状态的连接数,通常指并发连接数。
每产生一个连接或者一个会话,在服务端就会创建一个线程来处理。
SHOW PROCESSLIST查看当前的连接状态
链接状态:https://dev.mysql.com/doc/refman/5.7/en/show-processlist.html
常见状态:https://dev.mysql.com/doc/refman/5.7/en/thread-commands.html
show variables like 'max_connections' 查看最大连接数
不是越多越好,这个需要进行基准测试后才能找到最优解
查询优化
优化器有很多优化手段,不在这里记录,后面专门更新一下。太多了。
我们可以通过explain查看优化后的执行计划
这里也只是一个执行计划,最终走那个索引,这里不能百分之百保证。
更新的sql执行过程
缓冲池 Buffer Pool
InnnoDB 的数据都是放在磁盘上的,InnoDB 操作数据有一个最小的逻辑单位,叫做页(索引页和数据页)。对于数据的操作,不是每次都直接操作磁盘,因为磁盘的速度太慢了。InnoDB 使用了一种缓冲池的技术,也就是把磁盘读到的页放到一块内存区域里面。这个内存区域就叫Buffer Pool。
下一次读取相同的页,先判断是不是在缓冲池里面,如果是,就直接读取,不用再次访问磁盘。
修改数据的时候,先修改缓冲池里面的页。内存的数据页和磁盘数据不一致的时候, 把它叫做脏页。InnoDB里面有专门的后台线程把Buffer Pool的数据写入到磁盘,每隔一段时间就一次性地把多个修改写入磁盘,这个动作就叫做刷脏。
内存结构
Buffer Pool 主要分为 3 个部分: Buffer Pool、Change Buffer、Adaptive Hash Index,另外还有一个(redo)log buffer。
Buffer Pool
Buffer Pool 缓存的是页面信息,包括数据页、索引页;
SHOW STATUS LIKE '%innodb_buffer_pool%';
当需要更新一个数据页时,如果数据页在 Buffer Pool 中存在,那么就直接更新好了。 否则的话就需要从磁盘加载到内存,再对内存的数据页进行操作。
Change Buffer 写缓冲
如果这个数据页不是唯一索引,不存在数据重复的情况,也就不需要从磁盘加载索引页判断数据是不是重复(唯一性检查)。这种情况下可以先把修改记录在内存的缓冲 池中,从而提升更新语句(Insert、Delete、Update)的执行速度。
最后把 Change Buffer 记录到数据页的操作叫做 merge。什么时候发生 merge? 有几种情况:在访问这个数据页的时候,或者通过后台线程、或者数据库 shut down、 redo log 写满时触发。
如果数据库大部分索引都是非唯一索引,并且业务是写多读少,不会在写数据后立刻读取,就可以使用 Change Buffer(写缓冲)。写多读少的业务,调大这个值:SHOW VARIABLES LIKE 'innodb_change_buffer_max_size';
Adaptive Hash Index
(redo)Log Buffer
为了避免这个问题,InnoDB 把所有对页面的修改操作专门写入一个日志文件,并且在数据库启动时从这个文件进行恢复操作(实现 crash-safe)——用它来实现事务的持久性。
SHOW VARIABLES LIKE 'innodb_log_buffer_size'; 保存即将写入日志的数据缓冲区大小。
log buffer 写入磁盘的时机,是由innodb_flush_log_at_trx_commit参数控制。
可以看官网说的:https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
binlog
binlog 以事件的形式记录了所有的 DDL 和 DML 语句(因为它记录的是操作而不是数据值,属于逻辑日志),可以用来做主从复制和数据恢复。
跟 redo log 不一样,它的文件内容是可以追加的,没有固定大小限制。
在开启了 binlog 功能的情况下,我们可以把 binlog 导出成SQL 语句,把所有的操作重放一遍,来实现数据的恢复。
binlog 的另一个功能就是用来实现主从复制,它的原理就是从服务器读取主服务器的 binlog,然后执行一遍。

- 先记录到内存,再写日志文件
- 记录 redo log 分为两个阶段。
- 存储引擎和 Server 记录不同的日志。
- 先记录 redo,再记录 binlog。
Mysql的整体架构设计的更多相关文章
- [转]Android App整体架构设计的思考
1. 架构设计的目的 对程序进行架构设计的原因,归根到底是为了提高生产力.通过设计使程序模块化,做到模块内部的高聚合和模块之间的低耦合.这样做的好处是使得程序在开发的过程中,开发人员只需要专注于一点, ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
- 基于Hadoop的大数据平台实施记——整体架构设计
大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底是否适用于您的组织,至少在互联网上已经被吹嘘成无所不能的超级战舰.好像一夜之间我们就从互联网时代跳跃进了大 ...
- MySQL性能管理及架构设计
第1章 实例和故事 1-1 什么决定了电商双11大促的成败 老板可能会说:"是我们的英明决策和运筹帷幄". 运营和产品可能会说:"是由于我们的活动策划和产品设计" ...
- MySQL性能管理及架构设计 --- 理论篇
MySQL性能管理及架构设计 一丶IO,内存,吞吐量理解 IO 是指设备与设备之间操作次数,比如mysql与php互插内存 是程序运行都在里面执行吞吐量 是单 ...
- 【MySQL高可用架构设计】(一)-- mysql复制功能介绍
一. 介绍 Mysql的复制功能是构建基于SQL数据库的大规模高性能应用的基础,主要用于分担主数据库的读负载,同时也为高可用.灾难恢复.备份等工作提供了更多的选择. 二.为什么要使用mysql复制功能 ...
- 万字详解TDengine 2.0整体架构设计思路
导读:涛思数据8月3日将TDengine 的集群功能开源,TDengine具有超强的性能和功能,为什么能做到?它到底有哪些技术创新?今将TDengine的整体设计文档分享出来. 1: 数据模型 物联 ...
- 深度解读MRS IoTDB时序数据库的整体架构设计与实现
[本期推荐]华为云社区6月刊来了,新鲜出炉的Top10技术干货.重磅技术专题分享:还有毕业季闯关大挑战,华为云专家带你做好职业规划. 摘要:本文将会系统地为大家介绍MRS IoTDB的来龙去脉和功能特 ...
- MySQL 性能管理及架构设计指南
一.什么影响了数据库查询速度 1.1 影响数据库查询速度的四个因素 1.2 风险分析 QPS:Queries Per Second意思是“每秒查询率”,是一台服务器每秒能够相应的查询次数,是对一个特定 ...
- Nebula 架构剖析系列(零)图数据库的整体架构设计
Nebula Graph 是一个高性能的分布式开源图数据库,本文为大家介绍 Nebula Graph 的整体架构. 一个完整的 Nebula 部署集群包含三个服务,即 Query Service,S ...
随机推荐
- MyBatis——快速入门
MyBatis 快速入门 查询 tb_user 的所有信息 1.创建tb_user表,添加数据 create database mybatis; use mybatis; drop tab ...
- JDBC——案例
创建一个商品表 drop table if exists tb_brand; -- 创建tb_brand表 create table tb_brand( id int primary key auto ...
- Win11本地部署FaceFusion3最强AI换脸,集成Tensorrt10.4推理加速,让甜品显卡也能发挥生产力
FaceFusion3.0.0大抵是现在最强的AI换脸项目,分享一下如何在Win11系统,基于最新的cuda12.6配合最新的cudnn9.4本地部署FaceFusion3.0.0项目,并且搭配Ten ...
- Tauri2.0+Vite5聊天室|vue3+tauri2+element-plus仿微信|tauri聊天应用
原创tauri2.0+vue3+pinai2仿QQ/微信客户端聊天Exe程序TauriWinChat. tauri2-vue3-winchat自研vite5+tauri2.0+vue3 setup+e ...
- linux(centos7)安装curl和composer
linux(centos7)安装curl和composer 先安装curl:直接用yum装,yum curl 使用命令下载: curl -sS https://getcomposer.org/inst ...
- Diffusion系列-预备知识I -(一)
预备知识 范数 范数是一种函数,用来度量向量的大小1.在机器学习.信号处理等领域中,范数常常被用作正则化方法,通过对参数向量的范数进行约束,达到控制模型复杂度.防止过拟合等目的.常见的范数有0范数.1 ...
- 2023年第十二届数据技术嘉年华(DTC)资料分享
第十二届数据技术嘉年华(DTC 2023)已于4月8日在北京圆满落幕,大会围绕"开源·融合·数智化--引领数据技术发展,释放数据要素价值"这一主题,共设置有1场主论坛,12场专题论 ...
- DOM 的事件流
事件流分为三个阶段:捕获 ==>目标 ==>冒泡 1. 事件捕获阶段:事件传播由目标节点的祖先节点逐级传播到目标节点.先由文档的根 节点 document(window)开始触发对象,最后 ...
- watch 监视搜索关键词的变化不断发送请求返回建议
watch: { keywords: { // yarn add lodash 下载lodash包 // import { debounce } from "lodash"; 引入 ...
- 在 VMware vSphere 中构建 Kubernetes 存储环境
作者:马伟,青云科技容器顾问,云原生爱好者,目前专注于云原生技术,云原生领域技术栈涉及 Kubernetes.KubeSphere.kubekey等. 相信很多小伙伴和企业在构建容器集群时都会考虑存储 ...