前端开发系列124-进阶篇之html-parser
因为 HTML 解析的过程相对麻烦和复杂,因此为了把这个过程讲清楚,我这里先从下面这段最简单的 HTML 标签开始入手。我们专注一个点,需要做的似乎就是封装一个解析函数来完成转换,把字符串模板(template)作为函数的输入,把Tree 结构对象作为函数的输出即可。
输入 字符串模板(template)
<!-- 举例: -->
<div id="app"></div>
输出 Tree 结构对象
{
tag: "div",
attrs:[{name:"id",value:"app"}],
}
观察上面的输入和输出,我们需要逐字的扫描HTML字符串模板,提取里面的标签名称作为最终对象的 Tag 属性值,提取里面的属性节点保存到 attrs 属性中,因为标签身上可能有多个属性节点,所以 attrs 使用对象数组结构。
在扫描<div id="app"></div>字符串的时候,我们需区分开始标签、属性节点、闭合标签等部分,又因为标签的类型可以有很多种(div、span等),而属性节点的 key 和 value我们也无法限定和预估,因此在具体操作的时候似乎还需要用到 正则表达式来进行匹配,下面给出需要用到的正则表达式,并试着给出解析上述 HTML 模板字符串的 JavaScript 实现代码。
/* 形如:abc-123 */
const nc_name = `[a-zA-Z_][\\-\\.0-9_a-zA-Z]*`;
/* 形如:<aaa:bbb> */
const q_nameCapture = `((?:${nc_name}\\:)?${nc_name})`;
/* 形如:<div 匹配开始标签的左半部分 */
const startTagOpen = new RegExp(`^<${q_nameCapture}`);
/* 匹配开始标签的右半部分(>) 形如`>`或者` >`前面允许存在 N(N>=0)个空格 */
const startTagClose = /^\s*(\/?)>/;
/* 匹配属性节点:形如 id="app" 或者 id='app' 或者 id=app 等形式的字符串 */
const att =/^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<div>`]+)))?/
let template = `<div id="app"></div>`;
function parser_html(html) {
/* 在字符串中搜索<字符并获取索引 */
let textStart = html.indexOf('<');
/* 标签的开头 */
if (textStart == 0) {
/* 匹配标签的开头 */
let start = html.match(startTagOpen);
/* start的结果为:["<div","div",...] */
if (start) {
const tagInfo = {
tag: start[1],
attrs: []
}
/* 删除已经匹配过的这部分标签 html->' id="app"></div>'*/
html = html.slice(start[0].length)
/* 匹配属性节点部分 */
/* 考虑到标签可能存在多个属性节点,因此这里使用循环 */
let attr, end;
/* 换言之:(如果 end 有值那么循环结束),即当匹配到关闭标签的时候结束循环 */
while (!(end = html.match(startTagClose)) && (attr = html.match(att))) {
tagInfo.attrs.push({
name: attr[1],
value: attr[3] || attr[4] || attr[5]
})
html = html.slice(attr[0].length)
}
/* html-> ' ></div>' */
if (end) {
/* 此处可能是' >'因此第一个参数不能直接写0 */
html = html.slice(end[0].length);
/* html-> '</div>' */
/* 此处,关闭标签并不影响整体结果,因此暂不处理 */
return tagInfo;
}
}
}
}
let tree = parser_html(template);
console.log(tree);
/*
打印结果:
{ tag: 'div',
attrs: [ { name: 'id', value: 'app' } ] }
*/
console.log(parser_html(`<span id="app" title="标题"></span>`));
/*
打印结果:
{ tag: 'span',
attrs:
[ { name: 'id', value: 'app' }, { name: 'title', value: '标题' } ] }
*/
在上面的代码中,多个地方都用到了字符串的match方法,该方法接收一个正则表达式作为参数,用于进行正则匹配,并返回匹配的结果。
这里以属性匹配为例,当我们对字符串' id="app"></div>'应用正则匹配att后,得到的结果是一个数组,而如果匹配不成功,那么得到的结果为 null。

上文中处理的HTML 字符串模板比较简单,是单标签的(只有一个标签),如果我们要处理的标签结构比较复杂,比如存在嵌套关系(既标签中又有一个或多个子标签,而子标签也有自己的属性节点、内容甚至是子节点)和文本内容等。
这里简单给出HTML 字符串模板编译的示例代码,基本上解决了标签嵌套的问题,能够最终得到一棵描述 标签结构的 "Tree"。
/* 形如:abc-123 */
const nc_name = `[a-zA-Z_][\\-\\.0-9_a-zA-Z]*`;
/* 形如:<aaa:bbb> */
const q_nameCapture = `((?:${nc_name}\\:)?${nc_name})`;
/* 形如:<div 匹配开始标签的左半部分 */
const startTagOpen = new RegExp(`^<${q_nameCapture}`);
/* 匹配开始标签的右半部分(>) 形如`>`或者` >`前面允许存在 N(N>=0)个空格 */
const startTagClose = /^\s*(\/?)>/;
/* 匹配闭合标签:形如 </div> */
const endTag = new RegExp(`^<\\/${q_nameCapture}[^>]*>`);
/* 匹配属性节点:形如 id="app" 或者 id='app' 或者 id=app 等形式的字符串 */
const att = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<div>`]+)))?/
// const template = `<div><span class="span-class">Hi 夏!</span></div>`;
const template = `<div id="app" title="标题"><p>hello</p><span>vito</span></div>`
/* 标记节点类型(文本节点) */
let NODE_TYPE_TEXT = 3;
/* 标记节点类型(元素节点) */
let NODE_TYPE_ELEMENT = 1;
let stack = []; /* 数组模拟栈结构 */
let root = null;
let currentParent;
function compiler(html) {
/* 推进函数:每处理完一部分模板就向前推进删除一段 */
function advance(n) {
html = html.substring(n);
}
/* 解析开始标签部分:主要提取标签名和属性节点 */
function parser_start_html() {
/* 00-正则匹配 <div id="app" title="标题">模板结构*/
let start = html.match(startTagOpen);
if (start) {
/* 01-提取标签名称 形如 div */
const tagInfo = {
tag: start[1],
attrs: []
};
/* 删除<div部分 */
advance(start[0].length);
/* 02-提取属性节点部分 形如:id="app" title="标题"*/
let attr, end;
while (!(end = html.match(startTagClose)) && (attr = html.match(att))) {
tagInfo.attrs.push({
name: attr[1],
value: attr[3] || attr[4] || attr[5]
});
advance(attr[0].length);
}
/* 03-处理开始标签 形如 >*/
if (end) {
advance(end[0].length);
return tagInfo;
}
}
}
while (html) {
let textTag = html.indexOf('<');
/* 如果以<开头 */
if (textTag == 0) {
/* (1) 可能是开始标签 形如:<div id="app"> */
let startTagMatch = parser_start_html();
if (startTagMatch) {
start(startTagMatch.tag, startTagMatch.attrs);
continue;
}
/* (2) 可能是结束标签 形如:</div>*/
let endTagMatch = html.match(endTag);
if (endTagMatch) {
advance(endTagMatch[0].length);
end(endTagMatch[1]);
continue;
}
}
/* 文本内容的处理 */
let text;
if (textTag >= 0) {
text = html.substring(0, textTag);
}
if (text) {
advance(text.length);
chars(text);
}
}
return root;
}
/* 文本处理函数:<span> hello <span> => text的值为 " hello "*/
function chars(text) {
/* 1.先处理文本字符串中所有的空格,全部替换为空 */
text = text.replace(/\s/g, '');
/* 2.把数据组织成{text:"hello",type:3}的形式保存为当前父节点的子元素 */
if (text) {
currentParent.children.push({
text,
type: NODE_TYPE_TEXT
})
}
}
function start(tag, attrs) {
let element = createASTElement(tag, attrs);
if (!root) {
root = element;
}
currentParent = element;
stack.push(element);
}
function end(tagName) {
let element = stack.pop();
currentParent = stack[stack.length - 1];
if (currentParent) {
element.parent = currentParent;
currentParent.children.push(element);
}
}
function createASTElement(tag, attrs) {
return {
tag,
attrs,
children: [],
parent: null,
nodeType: NODE_TYPE_ELEMENT
}
}
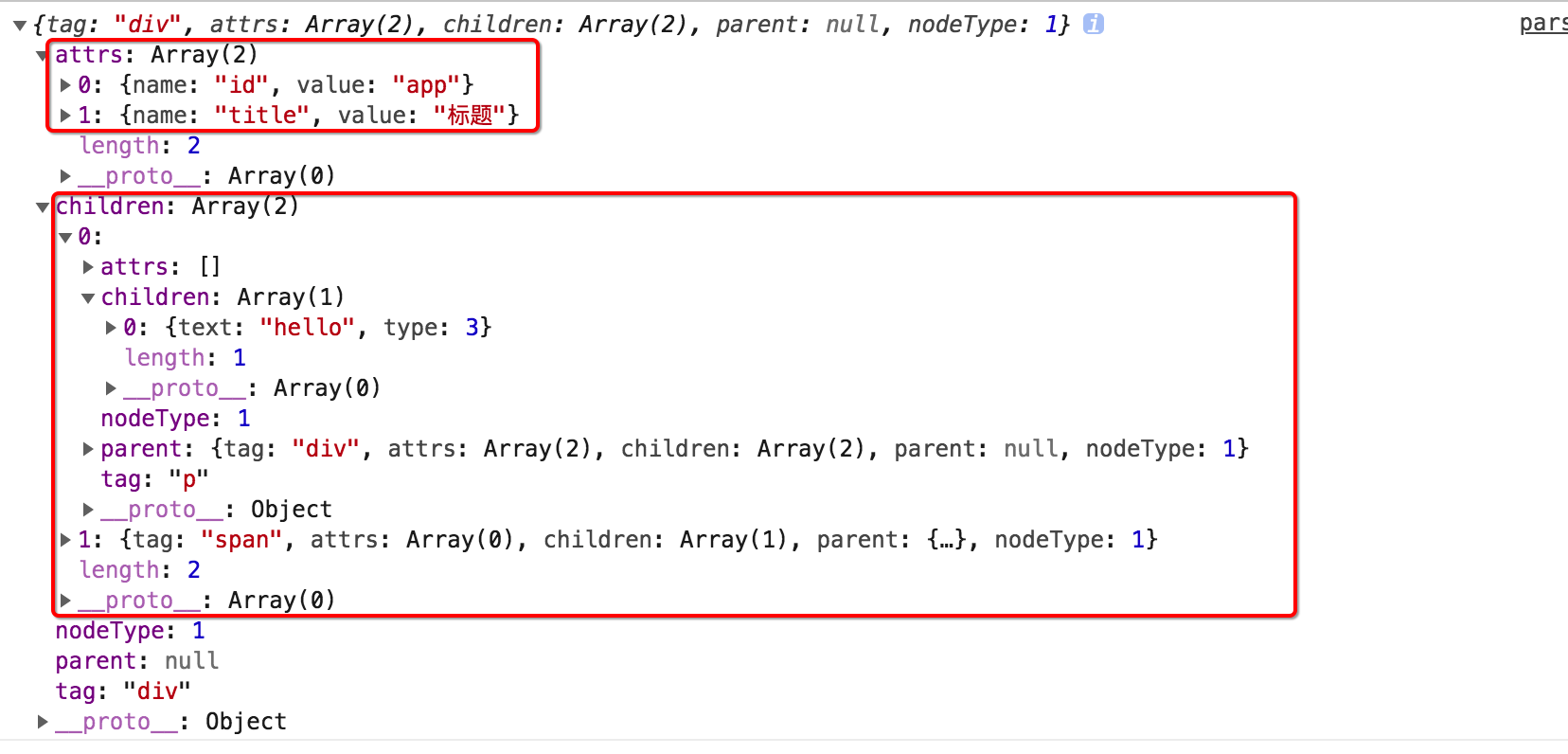
console.log(compiler(template));
执行上述代码,我们可以得到下面的显示结果。
前端开发系列124-进阶篇之html-parser的更多相关文章
- openlayers5-webpack 入门开发系列一初探篇(附源码下载)
前言 openlayers5-webpack 入门开发系列环境知识点了解: node 安装包下载webpack 打包管理工具需要依赖 node 环境,所以 node 安装包必须安装,上面链接是官网下载 ...
- leaflet-webpack 入门开发系列一初探篇(附源码下载)
前言 leaflet-webpack 入门开发系列环境知识点了解: node 安装包下载webpack 打包管理工具需要依赖 node 环境,所以 node 安装包必须安装,上面链接是官网下载地址 w ...
- 【Windows10 IoT开发系列】配置篇
原文:[Windows10 IoT开发系列]配置篇 Windows10 For IoT是Windows 10家族的一个新星,其针对不同平台拥有不同的版本.而其最重要的一个版本是运行在Raspberry ...
- ESP8266开发之旅 进阶篇② 闲聊Arduino IDE For ESP8266烧录配置
授人以鱼不如授人以渔,目的不是为了教会你具体项目开发,而是学会学习的能力.希望大家分享给你周边需要的朋友或者同学,说不定大神成长之路有博哥的奠基石... QQ技术互动交流群:ESP8266&3 ...
- 【webpack 系列】进阶篇
本文将继续引入更多的 webpack 配置,建议先阅读[webpack 系列]基础篇的内容.如果发现文中有任何错误,请在评论区指正.本文所有代码都可在 github 找到. 打包多页应用 之前我们配置 ...
- iOS开发系列--Swift进阶
概述 上一篇文章<iOS开发系列--Swift语言>中对Swift的语法特点以及它和C.ObjC等其他语言的用法区别进行了介绍.当然,这只是Swift的入门基础,但是仅仅了解这些对于使用S ...
- 旨在脱离后端环境的前端开发套件 - IDT Server篇
IDT,一个基于Nodejs的,旨在脱离后端环境的前端开发套件,目的就是能让前端开发完全脱离后端的环境,无论后端是什么模板引擎(主流),都能应付自如. IDT主要包括两大部分:Server + Bui ...
- 前端开发【第2篇:CSS】
鸡血 样式的属性多达几千个,但别担心,按照80-20原则,常用的也就几十个,你完全可以掌握它. Css初识 HTML的诞生 早期只有HTML的时候为了让HTML更美观一点,当时页面的开发者会把颜色写到 ...
- [置顶]【实用 .NET Core开发系列】- 导航篇
前言 此系列从出发点来看,是 上个系列的续篇, 上个系列因为后面工作的原因,后面几篇没有写完,后来.NET Core出来之后,注意力就转移到了.NET Core上,所以再也就没有继续下去,此是原因之一 ...
- openlayers4 入门开发系列之风场图篇
前言 openlayers4 官网的 api 文档介绍地址 openlayers4 api,里面详细的介绍 openlayers4 各个类的介绍,还有就是在线例子:openlayers4 官网在线例子 ...
随机推荐
- 【深度解析】SkyWalking 10.2.0版本安全优化与性能提升实战指南
前言 Apache SkyWalking 作为云原生可观测性领域的佼佼者,在微服务架构监控中扮演着至关重要的角色.然而,官方版本在安全性.镜像体积和功能扩展方面仍有优化空间.本文将分享一套完整的 Sk ...
- Python科学计算系列6—积分
1.定积分 例1:求下列函数的定积分 代码如下: from sympy import * x = symbols('x') f = integrate(exp(-x), (x, 0, oo)) pri ...
- Asp.net core基础(一)Entity FrameworkCore的增删查改
一.EntityFramework Core的介绍 EntityFramework Core是.net core中的ORM(object relational mapping[对象关系映射])框架,它 ...
- 网络开发中的Reactor(反应堆模式)和Proacrot(异步模式)
服务器程序重点处理IO事件,即:用户的请求读出来,反序列化,回调业务处理,回写.如果在按照面向过程的思路去写,就发挥不出CPU并发优势.那么有没有更优雅的设计方式呢? 有的兄弟,有的. Reactor ...
- MySQL 的 Change Buffer 是什么?它有什么作用?
MySQL 的 Change Buffer 1. 什么是 Change Buffer? Change Buffer 是 MySQL InnoDB 存储引擎中的一个优化机制,用于减少磁盘 I/O 操作. ...
- 2025AI应用全景图谱报告
提供AI咨询+AI项目陪跑服务,有需要回复1 加粉丝群获取报告 模型基础能力的提升加上自媒体的各种活跃,为AI应用提供了成长的温床,所以25年被称为了AI应用爆发的元年,这是有道理的,至少老板们在投钱 ...
- maven配置jdk版本
修改默认的jdk版本 在maven安装目录 apache-maven-3.6.1\conf\setting.xml 添加 <profile> <id>jdk18</id& ...
- 内网私仓全流程搭建记录(一)-Nexus3环境搭建
1.部署 1)在https://help.sonatype.com/repomanager3/product-information/download中下载对应环境及版本,此处要求3以上版本,本次以& ...
- 使用C#构建一个同时问多个LLM并总结的小工具
前言 在AI编程时代,如果自己能够知道一些可行的解决方案,那么描述清楚交给AI,可以有很大的帮助. 但是我们往往不知道真正可行的解决方案是什么? 我自己有过这样的经历,遇到一个需求,我不知道有哪些解决 ...
- python任务调度之schedule
本文通过开源项目schedule来学习定时任务如何工作 schedule简介 先来看下做做提供的一个例子 import schedule import time def job(): print(&q ...