AI智能体的技术架构与解决方案
相比于传统软件,AI智能体是一个新兴事物,技术架构和解决方案仍处在高速迭代中。所以,本文章将重点放在理清AI智能体相关的技术脉络,而非具体技术实现。更多相关知识还需要读者通过第三方搜索等方式,保持与时俱进。
一、架构总览
在技术实现的视角看,智能体分为三层:交互层、智能决策层和系统连接层,如图1所示,由智能体执行引擎统一完成编排与调度。

(图1 智能体标准参考架构)
交互层和系统连接层的开发技术与传统的软件开发一致,这里不再赘述。接下来,我们将关注的重点放在智能决策层的核心技术。
二、智能决策层,拆解智能体的核心技术
一个工程可落地的 AI 智能体智能决策层,并非仅仅是将一个大语言模型封装成接口那么简单。它的背后是一整套针对理解、推理、执行、感知和集成等多个维度的技术体系,包含以下3个核心技术:
- 智能体运行引擎
- 外部知识引入
- 外部能力引入
2.1 智能体运行引擎
智能体运行引擎是AI智能体的核心骨架,可类比于编码开发中的后端框架,如SpringBoot。它负责协调各个功能模块,编排并执行流程,并确保系统的可靠性与可扩展性。一个成熟的智能体引擎不仅仅是简单的调度器,更是一个复杂的状态管理与决策系统,如图2所示。
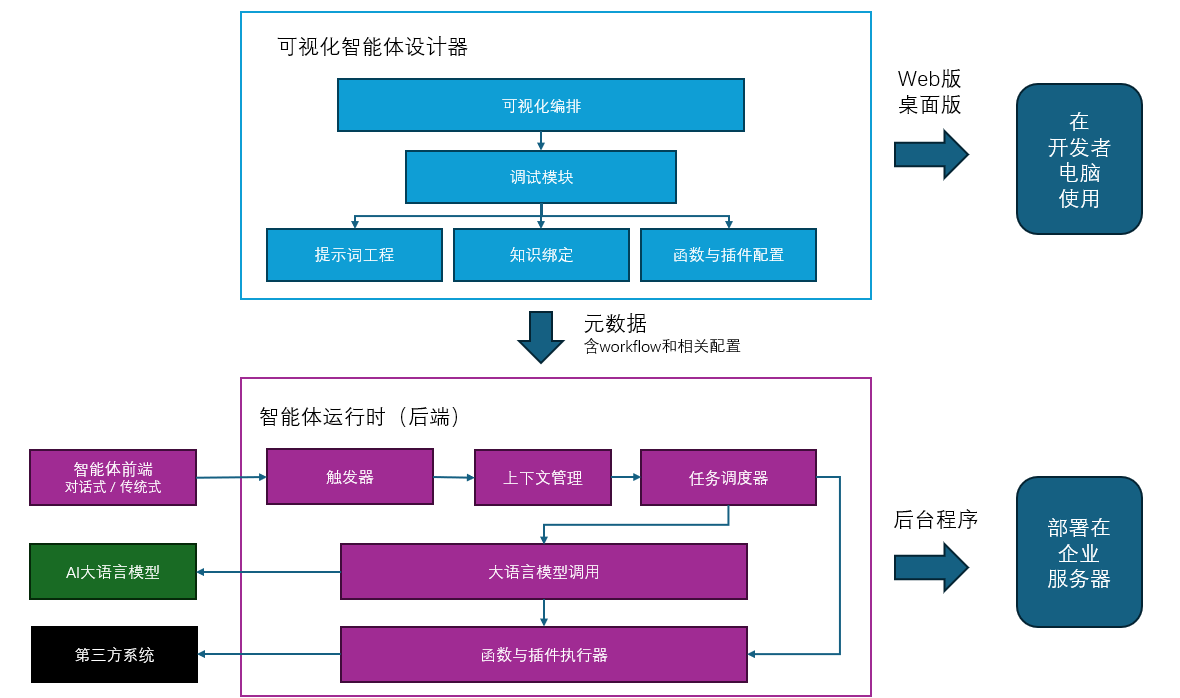
(图2 智能体运行引擎的架构图,简化版)
智能体引擎的主要职责体现在以下几个方面:
- 任务编排与执行控制:将复杂任务分解为职责相对单一的、可执行的任务序列,并管理任务间的依赖关系与执行顺序
- 状态管理与上下文保持:维护人与智能体的对话历史,确保多轮交互的连贯性
- 资源调度与负载均衡:智能体本身是一个独立运行的数字化系统,需要确保系统的稳定性
- 错误处理与自我修复:提供日志机制,检测执行异常并实施故障恢复策略,提高系统健壮性
为了提升智能体的开发效率,大部分智能体引擎会提供可视化的任务编排能力。任务编排工作可以看成是手工构建一个由多个节点构成的工作流,如图3所示,每一个节点对应了拆解后的一项任务。下图中的“Customer Insight Agent”节点就是调用“OpenAI Chat Model”(兼容OpenAI SDK的大模型)的任务。
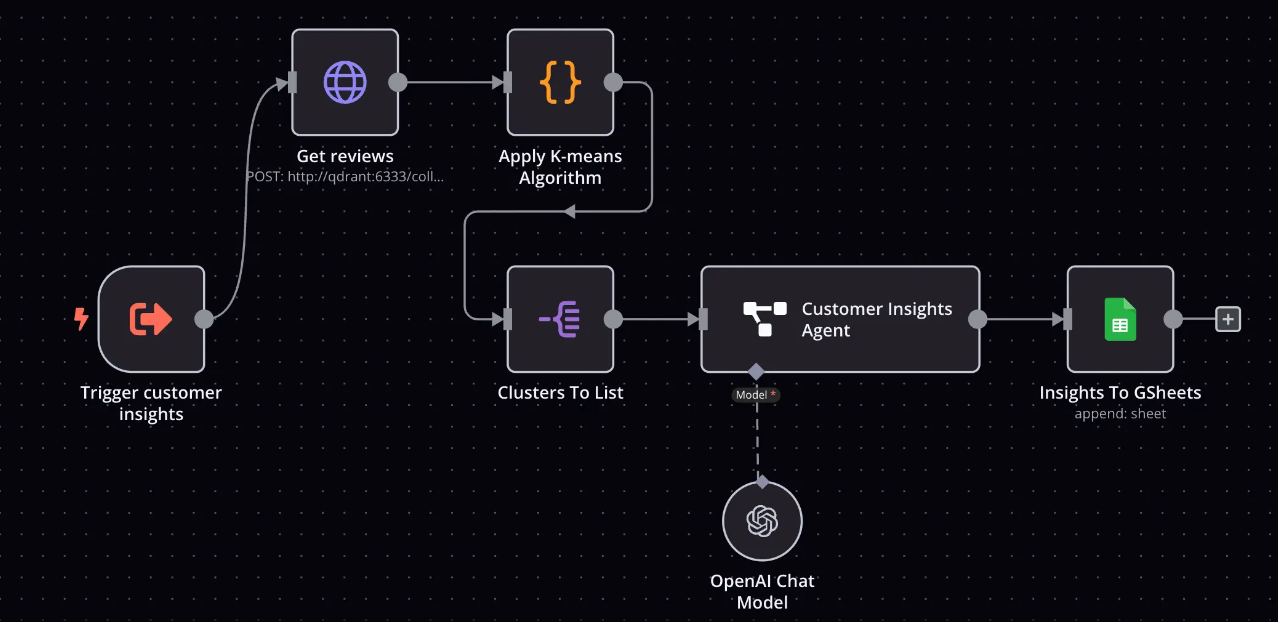
(图3 智能体工作流的示例)
作为最核心的能力,智能体引擎调用大语言模式的最核心功能,是为大模型传入提示词,接收大模型的响应。就像我们在Deepseek的网站上询问AI大模型一样,如图4所示。AI智能体的全部功能都需要依托于这个机制来实现。依然是为了提升效率,智能体引擎还会提供更多的扩展机制,实现外部知识引入和外部能力引入。
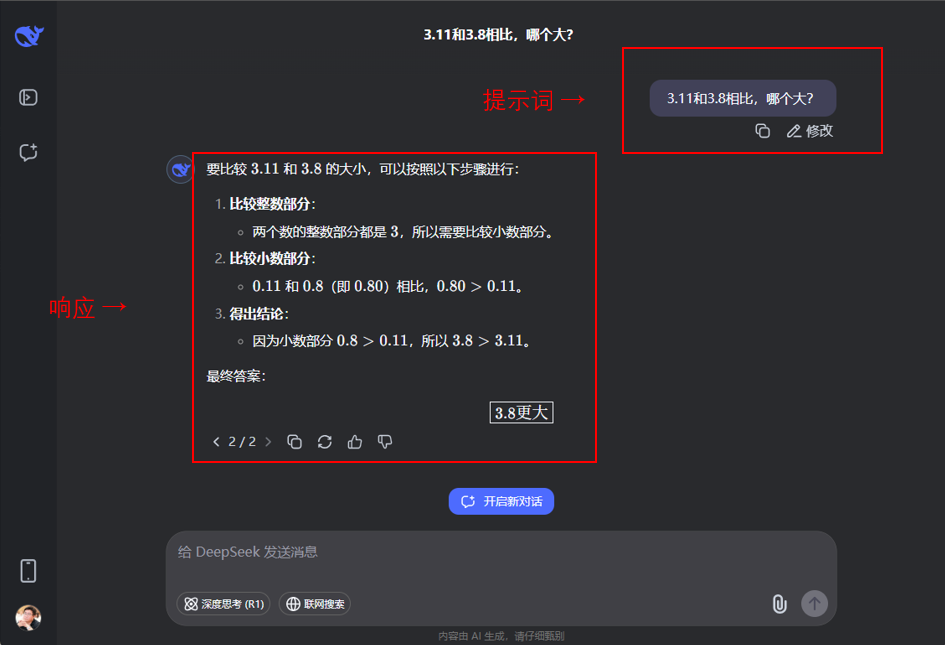
(图4 大语言模型的提示词与响应)
2.2 外部知识引入
提示:实现层面,外部知识的提供方(如知识库)通常位于AI智能体之外,智能体引擎仅需调用其接口即可完成引入工作。
尽管大语言模型(LLM)在多种任务中展现出强大的通用能力,但它们的知识主要来自预训练阶段的语料,一旦训练完成,模型的知识便固定了下来。这种静态知识局限,使得 LLM 在以下几类任务中难以胜任:
涉及组织内部、领域专有的知识内容:例如一家制造企业的设备操作规程、质量检验标准,或一家银行的风险评估规则和内部授信流程,这些内容不可能出现在公开训练语料中
涉及时效性强、经常更新的业务信息:比如电商平台的每日促销活动、物流系统的实时运单状态、企业最新的销售数据。这类信息更新频繁,需动态接入,模型本体很难预先掌握。
需要可验证、可追溯的答案来源:如医疗场景下对某药品用法的回答,需要明确引用权威指南;或政务场景下对政策解释的结果,需标明对应的政策原文出处。这些任务要求 AI 智能体不仅回答得对,还要回答得有依据。
而在真实的企业环境中,上述应用场景恰好是无法避免,甚至需要重点攻克的,如产品说明答疑、制度解读、政策判断、流程执行、知识总结等。所以,智能体引擎必须提供外部知识(这里的外部指的是大语言模型之外的知识,对于企业来说,大部分都属于“内部”知识)的获取和绑定机制,将动态的知识一并提交给大模型。
2.2.1 知识获取
外部知识的种类千差万别,存储在不同的系统中,智能体引擎需要提供差异化的获取方式。典型的知识来源于接入方式如下:
传统知识库:在OA等传统软件系统的知识库模块中,存储了大量的非结构化知识,如规章制度、标准操作流程等。这种知识库通常基于全文检索机制建立,并提供有查询接口。智能体引擎需要先将用户输入的意图拆解成关键词,然后才能调用知识库的接口获取相关的知识。
支持语义检索的矢量型知识库:生成式人工智能技术普及后,传统知识库的“升级版”,矢量型知识库诞生了。矢量型知识库在传统知识库的基础上,提供了语义检索的能力。智能体引擎将知识获取和引入的过程合二为一,可以自动将用户输入的意图发送给知识库,然后将知识和意图一起发给大模型,一次性最终结果。调用方式更简单,效果也更好。
元数据库/元数据仓库:除了上述的两种非结构化知识外,完成数据治理的企业中通常也会存在一些结构化的知识,以元数据的形式保存在数据库或数据仓库中,比如术语表、指标表等。智能体引擎需要像操作传统知识库一样,先拆解关键词,再查询这些数据库、数据仓库来获取相关知识。由于经过了数据治理,这部分知识的质量更好,可优先采用。
业务数据:另一种结构化的知识是业务数据,如销售目标、销售额等,智能体引擎获取这部分知识的方式与元数据类似,不再赘述。
2.2.2 知识绑定
智能体引擎获取到的知识,主要用于拼接提示词,让发送给AI大模型的内容中既有用户输入的意图,也包含与之相关的知识。AI大模型就会优先将这部分知识纳入推导和判断中,从而提升回答的准确率,最终达到提升智能体能力的目标。这个过程被称为“知识绑定”或“知识引入”。
对于C端场景和少量简单的企业应用场景来说,知识的来源比较单一,以矢量型知识库为主。智能体引擎提供的检索增强生成(Retrieval-Augmented Generation,RAG)模式就可以完成知识的获取和引用。具体而言,RAG有经典RAG和增强RAG两种模式,差异集中体现在智能体引擎中编排的复杂度,如图5所示。
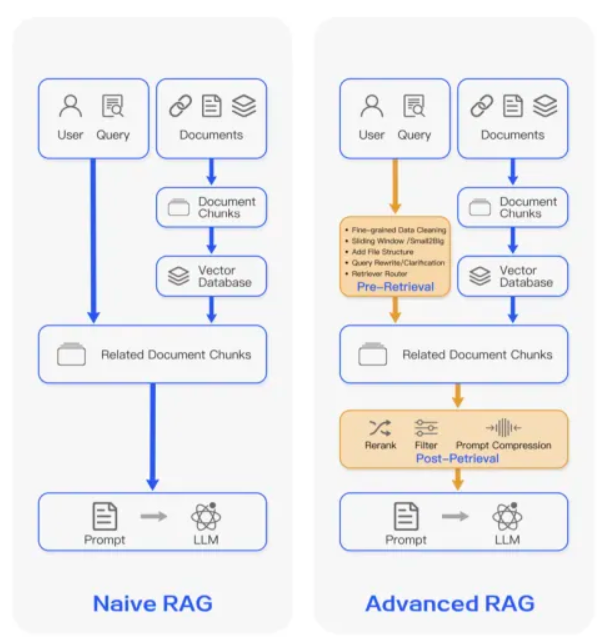
(图5 RAG的两种典型实现模式)
但是,大部分企业应用场景中涉及到的知识来源多样性强,而且大多以元数据库、第三方服务和业务数据库为主,RAG模式无法满足此类场景的要求。于是,我们需要在智能体引擎的任务编排机制中人工完成知识绑定。具体操作是,我们可以先设置一些获取知识的节点,将数据库、第三方WebAPI返回的数据存储到参数中;在调用大语言模型的节点中,使用这些参数拼接出完整的提示词,如图6所示。
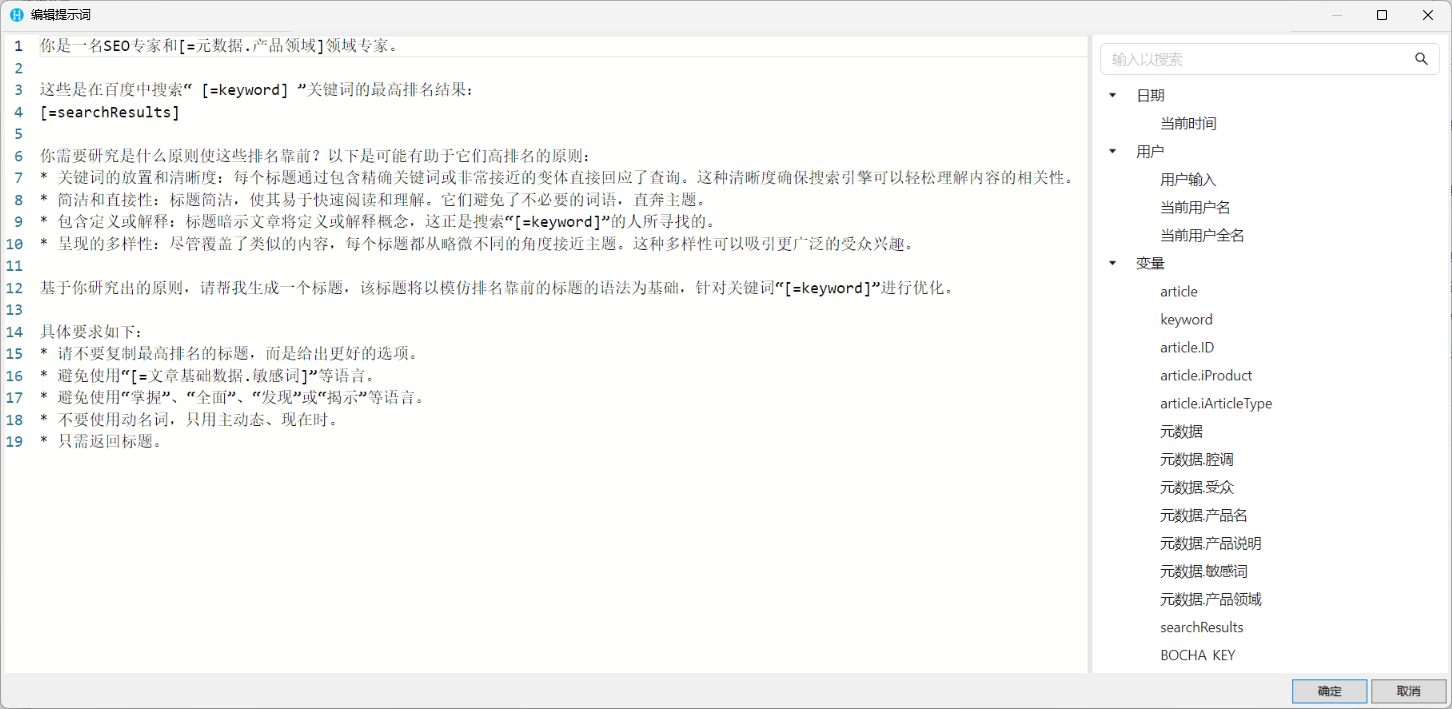
(图6 将外部知识融入提示词)
特别需要注意,外部知识引入的成效主要取决于知识本身的质量。除了覆盖面之外,知识的结构化程度越高、冲突越少,对智能体的能力提升越大,反之则越小。从部分实践案例上,未经治理的、广泛存在矛盾的知识库反而会放大AI幻觉,降低智能体的处理能力。所以,我们强烈建议企业在引入外部知识前做好知识相关的数据治理工作,治理好一个知识来源,再接入这个知识来源。
2.3 外部能力引入
这项能力是AI智能体最核心的能力。
现代AI智能体不仅要“会说”,更要“能做”。这就要求AI智能体可以将大模型以外的能力引入进来,具体而言就是要具备调用外部工具的能力(这里的外部指的也是大模型的外部,对于企业来说,这些工具大多也是部署在企业内部的)。
2.3.1 函数调用,强化大模型自身的处理能力
函数调用机制,是目前大语言模型原生支持最好的方式之一(如 OpenAI GPT 的 function calling、Anthropic 的 tool use)。
该技术的核心在于通过对工具(函数)进行结构化描述,引导模型输出所需参数,并由智能体引擎协调其他功能完成实际调用,如图7所示。
步骤如下:
- 开发者首先需要在智能体中定义能够提供给AI、供AI操作的“工具”
- 在智能体编排的“调用大模型”环节,将用户提供的提示词和上下文连同上一个步骤中工具的定义(含工具描述、参数描述等),一并交给AI服务器,等待AI服务器的响应
- 在智能体编排中,处理AI返回的函数调用指令和参数,执行该函数。如果函数是“中间节点”,则需要将函数返回结果和之前的所有提示词进行合并,调用大模型,否则就可以视为结束,将处理后的结果作为智能体的返回结果。在图7中,get_weather函数就是中间节点,调用该节点后还需要再一轮调用才能完成大模型调用工作。
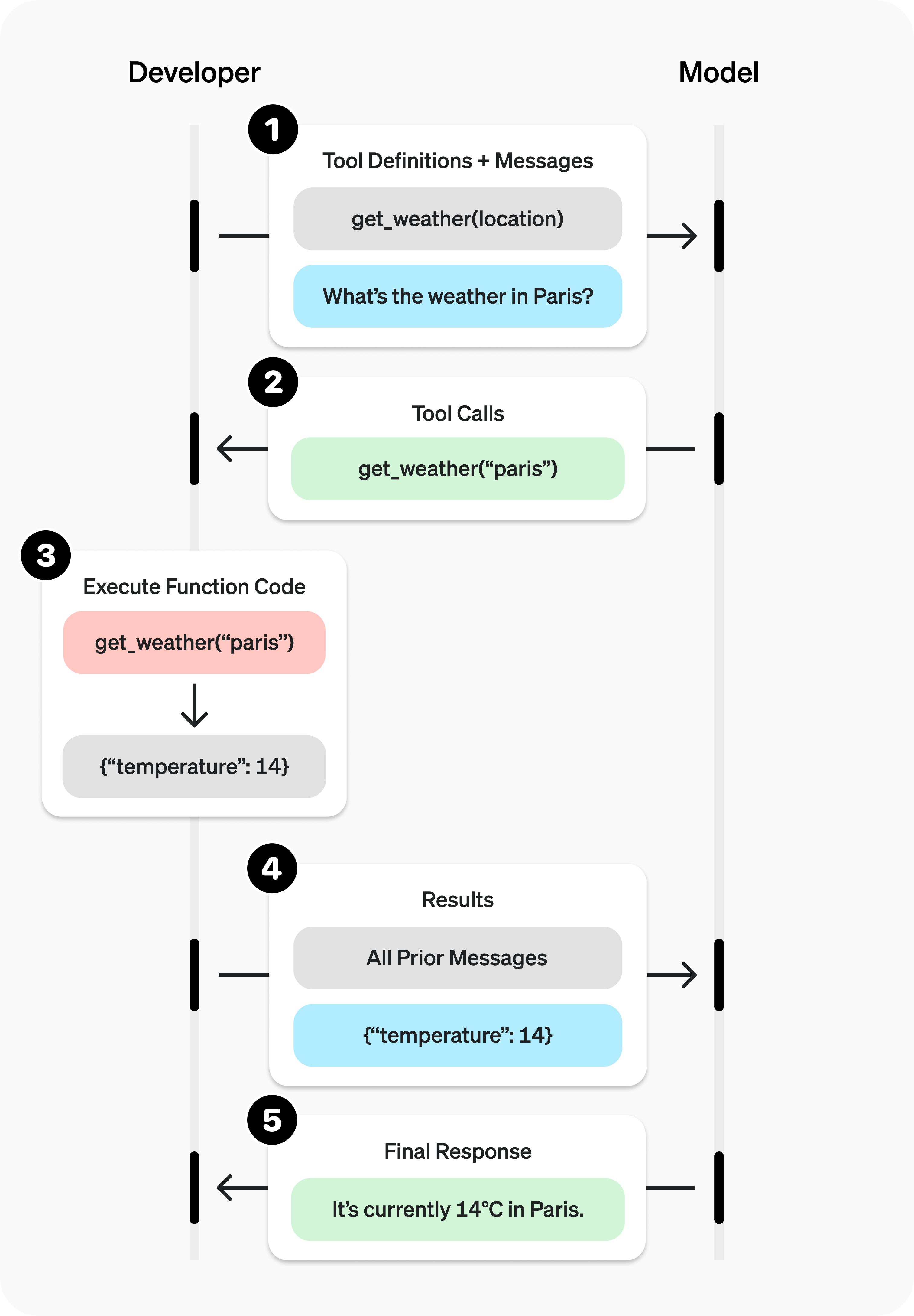
(图7 函数调用的原理示意)
函数调用机制的优势在于开发简单、易于理解和维护、与模型原生集成好,但也有不足之处,如与调用大模型环节紧密绑定,复用性欠佳等。
2.3.2 MCP,大幅提升函数的复用性
为了提升函数调用环节的可复用性,智能体引擎首先尝试的是将软件开发中私有方法的理念引入到智能体函数调用,将具体的处理逻辑抽象为“私有方法”,在调用各种AI大模型时简单封装一下就可以作为Function Calling。但这也仅仅是解决了同一个智能体或同一个大模型引擎内的复用。
为了进一步扩大复用范围,达到像npm开源社区那种程度,行业需要建立一个被广泛接受的函数封装协议和门户。于是,MCP(Model Context Protocol)进入了我们视野。MCP由Claude大模型的公司提出的开源协议,希望智能体开发者就像使用电脑上的USB接口一样,将所有符合MCP协议的函数直接引入到AI大模型中,如图8所示,实现最大程度的复用,建立全新的智能体函数库,打造AI智能体的开源生态。
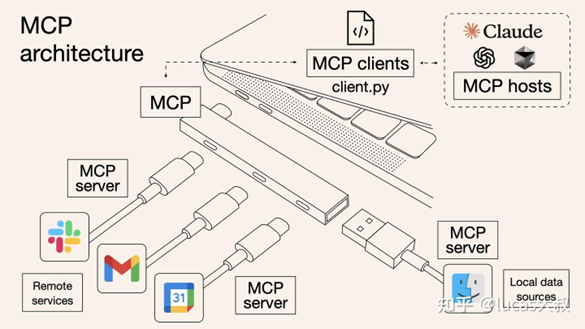
(图8 以电脑硬件接口为类比的MCP架构示意图)
MCP协议诞生于2024年底。该领域处在高速发展与变革中,能力和功能尚未定型,在企业应用场景下的价值也存在争议。但这并不影响数以千计、面向C端场景的MCP服务器不断涌现,从文件处理、在线搜索到地图路径规划、社交媒体分享,以图9所示的全球最大MCP源MCP.so为例,兼容MCP协议的软件在2025年4月就达到了7000余个。
(图9 MCP.so上的MCP服务器与客户端)
2.3.3 动态能力选择器
随着智能体应用场景的扩充,智能体引擎中注册的函数或MCP服务器数量也会迎来大幅增长,如果将其全部提交给大模型,不但会导致提示词数量超长,还会影响大模型的执行效果。该如何为不同的大模型调用场景选择合适的外部能力清单成为了关键问题。
能力选择器就是为了解决这一问题而生的。能力选择器是智能体架构中用于 “决策调度” 的核心组件,负责根据意图、上下文以及策略规则,从能力库中动态选择最佳的函数/MCP组合来完成任务。能力选择器的定位可以简单理解为连接“语言理解”和“任务执行”的中枢模块。
能力选择器的主要职责如下:
- 上下文感知与能力筛选:通过上下文(如当前业务页面、用户身份、可访问资源、数据范围等),能力选择器可根据预设规则或截止大语言模型筛选出适用的函数
- 回退与兜底机制:当匹配失败或插件调用异常时,能力选择器负责执行回退策略,如
- 调用兜底能力(默认回复、固定动作)、请求用户补充信息、引导用户手动执行等
在能力选择器的调度下,智能体引擎与外部能力协同配合,构成了AI智能体的“感知—判断—执行”链路,最终支撑起复杂企业环境下灵活、稳健的业务执行能力。
三、案例解析,看智能体各组件的协同方式
现实业务中,AI智能体通常需要智能体引擎、大语言模型(LLM)、外部能力系统(如MCP)、外部知识系统(如KAS)和用户交互层(UX)等多个组件协同工作。接下来,我们以OA系统的AI查询场景为例,展现一个基于MCP技术构建的Agent范式智能体中,多组件的协作流程。
如需扩充该智能体的能力,我们仅需要同步修改MCP1(获取审批中心能力清单)的数据、MCP3(生成工作流对话框渲染指令)和UX的逻辑即可。

AI智能体的技术架构与解决方案的更多相关文章
- 伯克利推出「看视频学动作」的AI智能体
伯克利曾经提出 DeepMimic框架,让智能体模仿参考动作片段来学习高难度技能.但这些参考片段都是经过动作捕捉合成的高度结构化数据,数据本身的获取需要很高的成本.而近日,他们又更进一步,提出了可以直 ...
- STM32W108无线传感器网络节点自组织与移动智能体导航技术
使用STM32W108无线开发板及节点完毕大规模网络的自组建,网络模型选择树型,网络组建完毕之后,使用基于接收信号强度指示RSSI(ReceivedSignal Strength Indication ...
- 人工智能AI智能加速卡技术
人工智能AI智能加速卡技术 一. 可编程AI加速卡 1. 概述: 这款可编程AI加速器卡具备 FPGA 加速的强大性能和多功能性,可部署AI加速器IP(WNN/GNN,直接加速卷积神经网络,直接运行常 ...
- DataPipeline CTO陈肃:从ETL到ELT,AI时代数据集成的问题与解决方案
引言:2018年7月25日,DataPipeline CTO陈肃在第一期公开课上作了题为<从ETL到ELT,AI时代数据集成的问题与解决方案>的分享,本文根据陈肃分享内容整理而成. 大家好 ...
- 新零售下的 AI智能货柜
公司有个智能货柜,通过微信扫码开门,拿货,自动扣款,挺智能的.还不错.研究一下原理,网上查了一下. 文章简介: 目前新零售风刮的蛮大,笔者进入该领域近一年,负责过无人便利店.智能货柜.智慧商超等产品, ...
- 揭秘阿里云WAF背后神秘的AI智能防御体系
背景 应用安全领域,各类攻击长久以来都危害着互联网上的应用,在web应用安全风险中,各类注入.跨站等攻击仍然占据着较前的位置.WAF(Web应用防火墙)正是为防御和阻断这类攻击而存在,也正是这些针对W ...
- 基于E-PUCK 2.0多智能体自主协同 高频投影定位系统
群体智能机器人是一种国际前沿的人工智能研究项目,由多个小型机器人组成的集群式解决系统,灵感源于蚂蚁.蜜蜂.鱼等群体生物,在没有统一领导的情况下,也能合作执行大量复杂的任务,比如组建一个图形,再在此基础 ...
- EventBridge助力阿里云视觉智能开放平台AI智能存储实践
本文作者:李建,阿里巴巴达摩院技术专家. 01 视觉智能开放平台(VIAPI)业务场景介绍 阿里云视觉智能开放平台(简称 VIAPI),是基于之前很多技术实践经验积累的 AI 能力的沉淀平台.目前整个 ...
- 企业架构研究总结(36)——TOGAF企业连续体和工具之企业连续体构成及架构划分
又回头看了之前文章的评论,本人也同样感慨这些文章的确像政治课本般的虚无缥缈,所以对费力看完却觉得无从下手的看官致以诚挚的歉意和理解,因为这个问题也同样困扰着笔者本人,而我能做的也只能是纸上谈兵.之前也 ...
- TOGAF企业连续体和工具之企业连续体构成及架构划分
TOGAF企业连续体和工具之企业连续体构成及架构划分 又回头看了之前文章的评论,本人也同样感慨这些文章的确像政治课本般的虚无缥缈,所以对费力看完却觉得无从下手的看官致以诚挚的歉意和理解,因为这个问题也 ...
随机推荐
- js回忆录(3) -- 循环语句,前后缀运算符
计算机对于大批量数据的处理速度比起人类不知道快了多少,因此对于重复的操作,使用循环语句处理是很方便的,对于我们前端来说,给同一标签的元素绑定事件啦,tab切换啦,左右联动效果啦,等等都可以使用循环语句 ...
- 质数测试——Fermat素数测试和MillerRabin素数测试
质数测试 今天我来填坑了,之前我在数学基础算法--质数篇这篇文章中提到我要单独讲一下MillerRabin算法,最近已经有许多粉丝在催了,所以我马不停蹄的来出这篇文章了,顺便把Fermat素数测试也讲 ...
- 【Bug记录】uniapp开发时pages.json和manifest.json注释报错解决方案
pages.json和manifest.json注释报错问题解决 增强 pages.json和 manifest.json 开发体验 json文件写注释 用 VsCode 开发 uni-app 项目时 ...
- JMeter 线程编号 __threadNum 获取不到
场景: 在 BeanShell PreProcessor 中,使用 vars.get("__threadNum") 获取不到当前线程数,如: import org.apache.j ...
- 程序员必看 Linux 常用命令(重要)
文件操作命令 find find 用于在指定目录下查找文件或子目录,如果不指定查找目录,则在当前目录下查找 命令格式:find path -option [-print] [ -exec/-ok co ...
- vue学习二(计算属性computed和监听器watch)
1.1.computed 计算属性 先写注意事项把:computed和methods的区别 //computed定义的方法我们是以属性访问的形式调用的{{computedTest}} comp ...
- Docker 运行命令
停止所有的容器 docker stop $(docker ps -aq) 启动所有的容器 docker start $(docker ps -aq) 停止容器 docker stop <容器Na ...
- Docker学习笔记:Docker 网络配置
2016-10-12 10:29:00 先知 转贴 51964 图: Docker - container and lightweight virtualization Dokcer 通过使用 Li ...
- C# - 获取枚举描述 - 使用增量源生成器
前言 C# 获取枚举描述的方法有很多, 常用的有通过 DescriptionAttribute 反射获取, 进阶的可以加上缓存机制, 减少反射的开销.今天我们还提供一种更加高效的方法,通过增量源生成器 ...
- 阅读IDEA生成的equals方法--java进阶day05
1.IDEA生成的equals方法 虽然我们之前写了equals方法,但IDEA中可以快速生成equals方法,因此,我们要能看懂IDEA生成的equals方法 1.if(this==o) 2.if( ...