关于torchvision.models中VGG的笔记
VGG 主要有两种结构,分别是 VGG16 和 VGG19,两者并没有本质上的区别,只是网络深度不一样。
对于给定的感受野,采用堆积的小卷积核是优于采用大的卷积核的,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
比如,三个步长为 $1$ 的 $3 \times 3$ 卷积核的叠加,即对应 $7 \times 7$ 的感受野(即三个 $3 \times 3$ 连续卷积相当于一个 $7 \times 7$ 卷积),如果我们假设卷积输入输出的 channel 数均为 $C$,那么三个 $3 \times 3$ 连续卷积的参数总量为 $3 \times (9 C^2)$(一个卷积核的大小 $3 \times 3 \times C$,一层有 $C$ 个卷积核,总共有三层),而如果直接使用 $7 \times 7$ 卷积核,其参数总量为 $49 C^2$。很明显 $27C^2 < 49C^2$,即减少了参数。
VGG的网络结构非常简单,全部都是 $(3,3)$ 的卷积核,步长为 $1$,四周补 $1$ 圈 $0$(使得输入输出的 $(H,W)$ 不变):
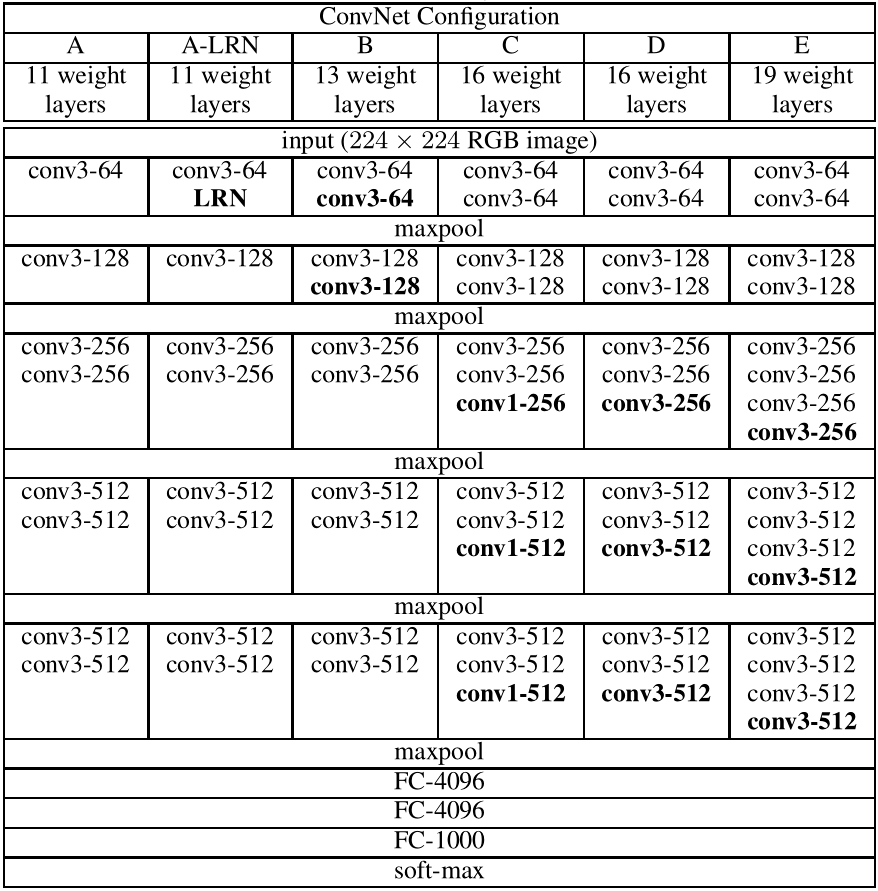
我们可以参考 torchvision.models 中的源码:
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def _vgg(arch, cfg, batch_norm, pretrained, progress, **kwargs):
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
cfgs 中的 "A,B,D,E" 就分别对应上表中的 A,B,D,E 四种网络结构。
'M' 代表最大池化层, nn.MaxPool2d(kernel_size=2, stride=2)
从代码中可以看出,经过 self.features 的一大堆卷积层之后,先是经过一个 nn.AdaptiveAvgPool2d((7, 7)) 的自适应平均池化层(自动选择参数使得输出的 tensor 满足 $(H = 7,W = 7)$),再通过一个 torch.flatten(x, 1) 推平成一个 $(batch\_size, n)$ 的 tensor,再连接后面的全连接层。
torchvision.models.vgg19_bn(pretrained=False, progress=True, **kwargs)
pretrained: 如果设置为 True,则返回在 ImageNet 预训练过的模型。
关于torchvision.models中VGG的笔记的更多相关文章
- PyTorch源码解读之torchvision.models(转)
原文地址:https://blog.csdn.net/u014380165/article/details/79119664 PyTorch框架中有一个非常重要且好用的包:torchvision,该包 ...
- 转:openwrt中luci学习笔记
原文地址:openwrt中luci学习笔记 最近在学习OpenWrt,需要在OpenWrt的WEB界面增加内容,本文将讲述修改OpenWrt的过程和其中遇到的问题. 一.WEB界面开发 ...
- VS2013中Python学习笔记[Django Web的第一个网页]
前言 前面我简单介绍了Python的Hello World.看到有人问我搞搞Python的Web,一时兴起,就来试试看. 第一篇 VS2013中Python学习笔记[环境搭建] 简单介绍Python环 ...
- Django之admin中管理models中的表格
Django之admin中管理models中的表格 django中使用admin管理models中的表格时,如何将表格注册到admin中呢? 具体操作就是在项目文件夹中的app文件夹中的admin中注 ...
- Django models中关于blank与null的补充说明
Django models中关于blank与null的补充说明 建立一个简易Model class Person(models.Model): GENDER_CHOICES=( (1,'Male'), ...
- J粒子发现40周年-丁肇中中科院讲座笔记
J粒子发现40周年-丁肇中中科院讲座笔记 华清远见2014-10-18 北京海淀区 张俊浩 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQveXVuZm ...
- models中,字段参数limit_choices_to的用法
这里,在使用 ModelForm 渲染前端页面的前提下,对于 models 中的 ManyToManyField 类型字段会在 ModelForm 中被转化为 ModelMultipleChoiceF ...
- Django——models中导入数据重复的解决办法
如果你导入数据过多,导入时出错了,或者你手动停止了,导入了一部分,还有一部分没有导入.或者你再次运行上面的命令,你会发现数据重复了,怎么办呢? django.db.models 中还有一个函数叫 ge ...
- Ant Design框架中不同的组件访问不同的models中的数据
Ant Design框架中不同的组件访问不同的models中的数据 本文记录了我在使用该框架的时候踩过的坑,方便以后查阅. 一.models绑定 在某个组件(控件或是页面),要想从某个models中获 ...
随机推荐
- TensorFlow 训练只用cpu
os.environ["CUDA_VISIBLE_DEVICES"] = ""
- 【PAT甲级】1035 Password (20 分)
题意: 输入一个正整数N(<=1000),接着输入N行数据,每行包括一个ID和一个密码,长度不超过10的字符串,如果有歧义字符就将其修改.输出修改过多少组密码并按输入顺序输出ID和修改后的密码, ...
- UCOS-III API函数
附录:UCOS-III API函数 任务管理 就绪列表 挂起队列 时间管理 信号量 消息队列 内存管理
- 本周总结(19年暑假)—— Part1
日期:2019.7.14 博客期:107 星期日 这几周正在摸索着找寻与大型数据库相关的知识,重装了电脑,配置了虚拟机的环境,继续研究了几下修改器.
- Sublime设置html头部
1.Ctrl + N,新建一个文档:2.Ctrl + Shift + P,打开命令模式,再输入 sshtml 进行模糊匹配,将语法切换到html模式:3.输入 !,再按下 Tab键或者 Ctrl + ...
- 《编写高质量iOS与OS X代码的52个有效方法》书籍目录
一.熟悉Objective-C 1.了解Objective-C语言的起源 2.在类的头文件中尽量少引入其他头文件 3.多用字面量语法,少用与之等价的方法 4.多用类型常量,少用#define预处理指令 ...
- pytorch神经网络解决回归问题(非常易懂)
对于pytorch的深度学习框架,在建立人工神经网络时整体的步骤主要有以下四步: 1.载入原始数据 2.构建具体神经网络 3.进行数据的训练 4.数据测试和验证 pytorch神经网络的数据载入,以M ...
- SVM数学原理推导
//2019.08.17 #支撑向量机SVM(Support Vector Machine)1.支撑向量机SVM是一种非常重要和广泛的机器学习算法,它的算法出发点是尽可能找到最优的决策边界,使得模型的 ...
- 《React后台管理系统实战 :三》header组件:页面排版、天气请求接口及页面调用、时间格式化及使用定时器、退出函数
一.布局及排版 1.布局src/pages/admin/header/index.jsx import React,{Component} from 'react' import './header. ...
- markdown基本语法教程
标题 一级标题 二级标题 三级标题 以此类推,总共六级标题,建议在警号后面加一个空格,这是最标准的markdown语法 列表 在markdown下: 列表的显示只需要在文字前加上-.+或*即可变为无序 ...