oracle树形查询 start with connect by
一、简介
在oracle中start with connect by (prior) 用来对树形结构的数据进行查询。其中start with conditon 给出的是数据搜索范围, connect by后面给出了递归查询的条件,prior 关键字表示父数据,prior 条件表示子数据需要满足父数据的什么条件。如下
start with id= '10001' connect by prior parent_id= id and prior num = 5
表示查询id为10001,并且递归查询parent_id=id,为5的记录。
二、实例
1、构造数据
-- 表结构
create table menu(
id varchar2(64) not null,
parent_id varchar2(64) not null,
name varchar2(100) not null,
depth number(2) not null,
primary key (id)
) -- 初始化数据
-- 顶级菜单
insert into menu values ('', '', '顶级菜单1', 1);
insert into menu values ('', '', '顶级菜单2', 1);
insert into menu values ('', '', '顶级菜单3', 1); -- 父级菜单
-- 顶级菜单1 直接子菜单
insert into menu values ('', '', '菜单11', 2);
insert into menu values ('', '', '菜单12', 2);
insert into menu values ('', '', '菜单13', 2);
insert into menu values ('', '', '菜单14', 2);
-- 顶级菜单2 直接子菜单
insert into menu values ('', '', '菜单21', 2);
insert into menu values ('', '', '菜单22', 2);
insert into menu values ('', '', '菜单23', 2);
-- 顶级菜单3 直接子菜单
insert into menu values ('', '', '菜单31', 2); -- 菜单13 直接子菜单
insert into menu values ('', '', '菜单131', 3);
insert into menu values ('', '', '菜单132', 3);
insert into menu values ('', '', '菜单133', 3); -- 菜单132 直接子菜单
insert into menu values ('', '', '菜单1321', 4);
insert into menu values ('', '', '菜单1332', 4);
生成的菜单层次结构如下:
顶级菜单1
菜单11
菜单12
菜单13
菜单131
菜单132
菜单1321
菜单1322
菜单133
菜单14
顶级菜单2
菜单21
菜单22
菜单23
顶级菜单3
菜单31
2、SQL查询
--prior放的左右位置决定了检索是自底向上还是自顶向下. 左边是自上而下(找子节点),右边是自下而上(找父节点)
--找父节点
select * from menu start with id='' connect by id = prior parent_id;

--找子节点节点
-- (子节点)id为130000的菜单,以及130000菜单下的所有直接或间接子菜单(prior 在左边, prior、parent_id(等号右边)在右边)
select * from menu start with id='' connect by prior id = parent_id ;
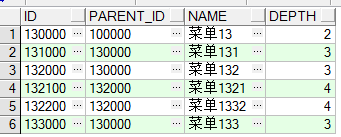
-- (父节点)id为1321的菜单,以及1321菜单下的所有直接或间接父菜单(prior、parent_id(等号左边) 都在左边)
select * from menu start with id='' connect by prior parent_id = id;
-- prior 后面跟的是(parent_id) 则是查找父节点,prior后面跟的是(id)则是查找子节点

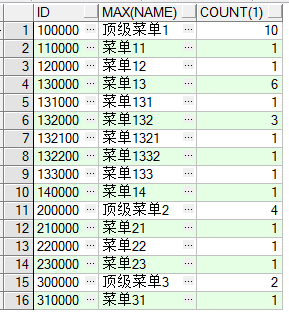
--根据菜单组分类统计每个菜单包含子菜单的个数
select id, max(name) name, count(1) from menu
group by id
connect by prior parent_id = id
order by id
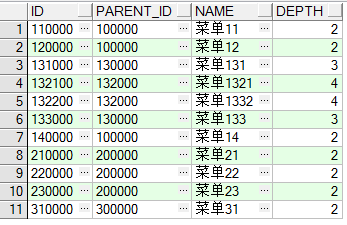
-- 查询所有的叶子节点
select t2.* from menu t2 where id not in(select t.parent_id from menu t) order by id;
三、性能问题
对于 start with connect by语句的执行,oracle会进行递归查询,当数据量大的时候会产生性能相关问题。
--生成执行计划
explain plan for select * from menu start with id='' connect by prior parent_id = id; -- 查询执行计划
select * from table( dbms_xplan.display);
语句执行计划结果如下:
Plan hash value: 3563250490 ----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 133 | 1 (0)| 00:00:01 |
|* 1 | CONNECT BY WITH FILTERING | | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID | MENU | 1 | 133 | 1 (0)| 00:00:01 |
|* 3 | INDEX UNIQUE SCAN | SYS_C0018586 | 1 | | 1 (0)| 00:00:01 |
| 4 | NESTED LOOPS | | | | | |
| 5 | CONNECT BY PUMP | | | | | |
| 6 | TABLE ACCESS BY INDEX ROWID| MENU | 1 | 133 | 1 (0)| 00:00:01 |
|* 7 | INDEX UNIQUE SCAN | SYS_C0018586 | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - access("ID"=PRIOR "PARENT_ID")
3 - access("ID"='')
7 - access("ID"=PRIOR "PARENT_ID") Note
-----
- dynamic sampling used for this statement
通过该执行计划得知,改语句执行了7步操作,才将结果集查询并返回。当需要查询条件进行过滤的时候,我们可以通过查看执行计划从而对sql进行优化。
oracle树形查询 start with connect by的更多相关文章
- [转载]oracle树形查询 start with connect by
一.简介 在oracle中start with connect by (prior) 用来对树形结构的数据进行查询.其中start with conditon 给出的是数据搜索范围, connect ...
- 整理oracle 树形查询
注:本文参考了<整理oracle 树形查询> sql树形递归查询是数据库查询的一种特殊情形,也是组织结构.行政区划查询的一种最常用的的情形之一.下面对该种查询进行一些总结: create ...
- Oracle层次查询start with connect by
博客参考:https://www.cnblogs.com/jerryxing/articles/2339352.html start with connect by 层次查询(Hierarchical ...
- Oracle树形查询
sql树形递归查询是数据库查询的一种特殊情形,也是组织结构.行政区划查询的一种最常用的的情形之一.下面对该种查询进行一些总结: start with子句: 递归的条件,需要注意的是如果with后面的值 ...
- ORACLE 树形查询 树查询
前台树结构依据个人的权限登录变化 全部我查询要依据 树的ID 查询以下全部的子节点 以及本节点的信息 select * from table start with id = #{id} connect ...
- oracle 树形表结构查询 排序
oracle 树形表结构排序 select * from Table start with parentid is null connect by prior id=parentid order SI ...
- MySql/Oracle树形结构查询
Oracle树形结构递归查询 在Oracle中,对于树形查询可以使用start with ... connect by select * from treeTable start with id='1 ...
- Oracle 层次查询 connect by
oracle 层次查询 语法: SELECT ... FROM [WHERE condition] --过 ...
- Oracle中树形查询使用方法
树形查询一般用于上下级场合,使用的特殊sql语法包括level,prior,start with,connect by等,下面将就实例来说明其用法. 表定义: create table tb_hier ...
随机推荐
- Cesium原理篇:3最长的一帧之地形(2:高度图)
这一篇,接着上一篇,内容集中在高度图方式构建地球网格的细节方面. 此时,Globe对每一个切片(GlobeSurfaceTile)创建对应的TileTerrain类,用来维 ...
- 使用QUnit进行自动化单元测试
前言 前阵子由于项目需求接触了java的单元测试JUnit,就顺带着学习了前端的单元测试:Qunit. 既然跟测试有关,不妨介绍一下测试中的黑盒测试.白盒测试以及单元测试. 1.黑盒测试:所谓的黑盒, ...
- C#基础-文件夹复制与删除
代码来源:http://blog.163.com/u_tommy_520/blog/static/20406104420147493933662/ 最近做MVC网站时刚好用到,用以提供一个完整的文件夹 ...
- 【电脑常识】如何查看电脑是32位(X86)还是64位(X64),如何知道硬件是否支持64位系统
开始->运行->输入cmd确定->输入systeminfo 回车 待加载完成,就会看到如下信息(不同版本略有差异): 一.如何查看电脑是32位(X86)还是64位(X64) 方法2: ...
- SqlServer-无限递归树状图结构设计和查询
在现实生活中,公司的部门设计会涉及到很多子部门,然后子部门下面又存在子部门,形成类似判断的树状结构,比如说评论楼中楼的评论树状图,职位管理的树状图结构等等,实现类似的树状图数据结构是在开发中经常出现的 ...
- 【Java学习系列】第1课--Java环境搭建和demo运行
本文地址 分享提纲: 1. java环境的搭建 2. java demo代码运行 3.参考文档 本人是PHP开发者,一直感觉Java才是程序的王道(应用广,科班出身),所以终于下决心跟一跟. 主要是给 ...
- Meta标签详解(HTML JAVASCRIPT)
Meta标签详解,在网上转的,希望对大家有用 您的个人网站即使做得再精彩,在“浩瀚如海”的网络空间中,也如一叶扁舟不易为人发现,如何推广 个人网站,人们首先想到的方法无外乎以下几种: ● 在搜索引擎中 ...
- browserify压缩合并源码反编译
最近在学习钉钉(一个协作应用)桌面应用的前端源码时候,发现其js源码是用browserify做模块开发.于是想还原其源码的原本的目录结构,学习它的目录分类以及业务划分. 前言 用过browserify ...
- HTML5自定义属性之data-*
HTML5 增加了一项新功能是 自定义数据属性 ,也就是 data-* 自定义属性.在HTML5中我们可以使用以 data- 为前缀来设置我们需要的自定义属性,来进行一些数据的存放.当然高级浏览器下 ...
- Java线程
线程 线程 线程(Thread)是控制线程(Thread of Control)的缩写,是程序运行的基本单位,它是具有一定顺序的指令序列(即所编写的程序代码).存放方法中定义局部变量的栈和一些共享数据 ...