Andrew Ng - 深度学习工程师 - Part 1. 神经网络和深度学习(Week 2. 神经网络基础)
=================第2周 神经网络基础===============
===2.1 二分分类===
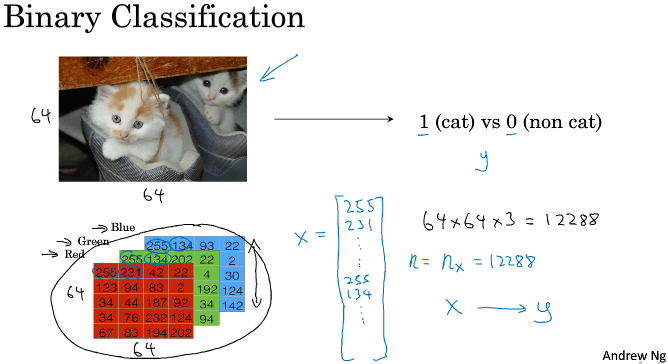
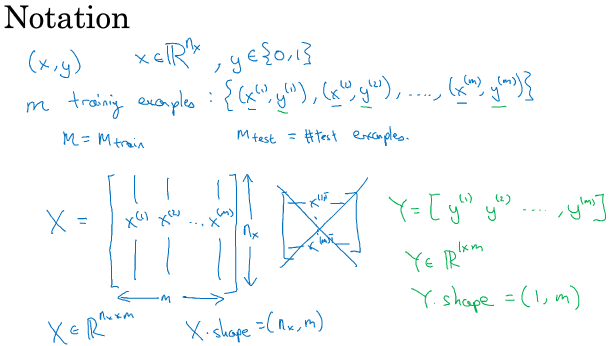
===2.2 logistic 回归===
It turns out, when you implement you implement your neural network, it will be easier to just keep b and w as separate parameters. 本课程中将分开考虑它们。
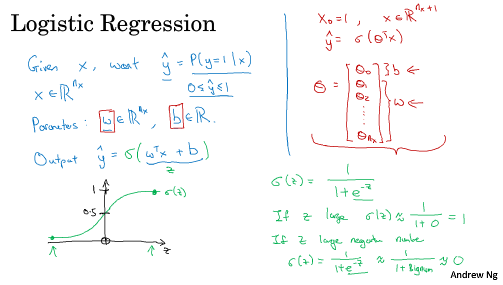

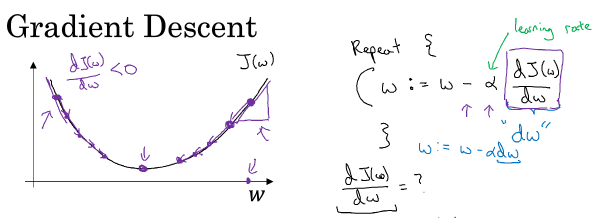


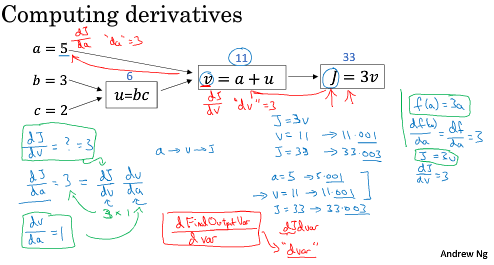


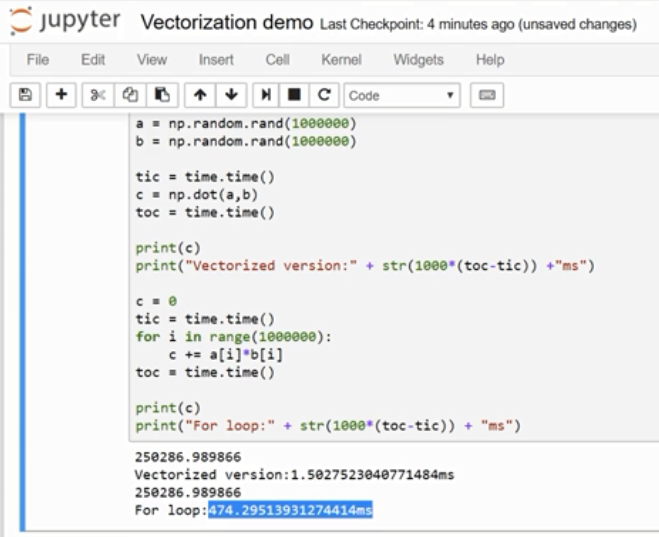


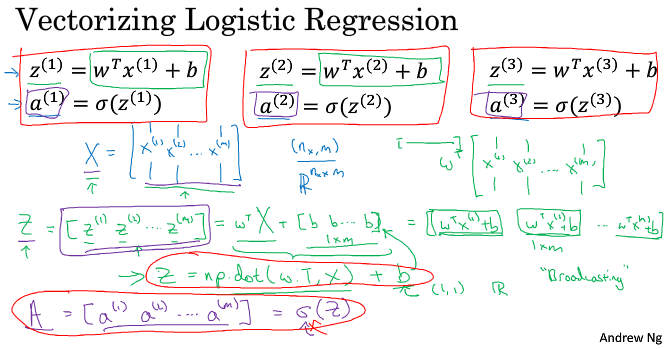
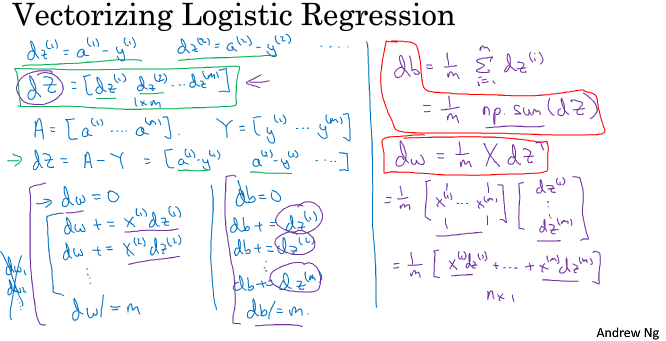



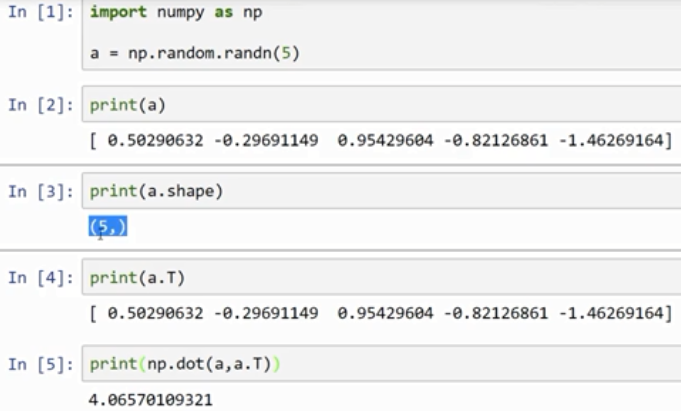
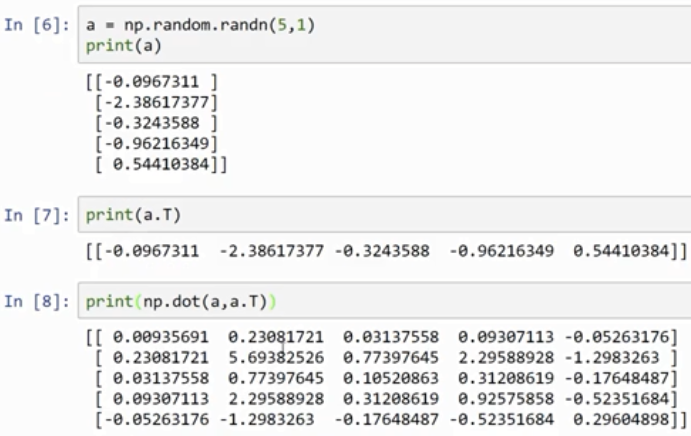
rank 1 array 的行为和行向量或列向量都不一样,which makes some of its effects nonintuitive. 我的建议是不要使用它们。如果某些时候确实得到了rank 1 array,你可以用reshape,使它的行为更好预测。

Andrew Ng - 深度学习工程师 - Part 1. 神经网络和深度学习(Week 2. 神经网络基础)的更多相关文章
- 【原】Coursera—Andrew Ng机器学习—编程作业 Programming Exercise 3—多分类逻辑回归和神经网络
作业说明 Exercise 3,Week 4,使用Octave实现图片中手写数字 0-9 的识别,采用两种方式(1)多分类逻辑回归(2)多分类神经网络.对比结果. (1)多分类逻辑回归:实现 lrCo ...
- Andrew Ng - 深度学习工程师 - Part 1. 神经网络和深度学习(Week 1. 深度学习概论)
=================第1周 循环序列模型=============== ===1.1 欢迎来到深度学习工程师微专业=== 我希望可以培养成千上万的人使用人工智能,去解决真实世界的实际问 ...
- 百度首席科学家 Andrew Ng谈深度学习的挑战和未来(转载)
转载:http://www.csdn.net/article/2014-07-10/2820600 人工智能被认为是下一个互联网大事件,当下,谷歌.微软.百度等知名的高科技公司争相投入资源,占领深度学 ...
- 《Andrew Ng深度学习》笔记1
深度学习概论 1.什么是神经网络? 2.用神经网络来监督学习 3.为什么神经网络会火起来? 1.什么是神经网络? 深度学习指的是训练神经网络.通俗的话,就是通过对数据的分析与计算发现自变量与因变量的映 ...
- 《Andrew Ng深度学习》笔记4
浅层神经网络 1.激活函数 在神经网络中,激活函数有很多种,常用的有sigmoid()函数,tanh()函数,ReLu函数(修正单元函数),泄露ReLu(泄露修正单元函数).它们的图形如下: sigm ...
- 《Andrew Ng深度学习》笔记3
浅层神经网络 初步了解了神经网络是如何构成的,输入+隐藏层+输出层.一般从输入层计算为层0,在真正计算神经网络的层数时不算输入层.隐藏层实际就是一些算法封装成的黑盒子.在对神经网络训练的时候,就是对神 ...
- 吴恩达深度学习第1课第4周-任意层人工神经网络(Artificial Neural Network,即ANN)(向量化)手写推导过程(我觉得已经很详细了)
学习了吴恩达老师深度学习工程师第一门课,受益匪浅,尤其是吴老师所用的符号系统,准确且易区分. 遵循吴老师的符号系统,我对任意层神经网络模型进行了详细的推导,形成笔记. 有人说推导任意层MLP很容易,我 ...
- 【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第一周测验【中英】
[吴恩达课后测验]Course 1 - 神经网络和深度学习 - 第一周测验[中英] 第一周测验 - 深度学习简介 和“AI是新电力”相类似的说法是什么? [ ]AI为我们的家庭和办公室的个人设备供电 ...
- DeepLearning.ai学习笔记(一)神经网络和深度学习--Week3浅层神经网络
介绍 DeepLearning课程总共五大章节,该系列笔记将按照课程安排进行记录. 另外第一章的前两周的课程在之前的Andrew Ng机器学习课程笔记(博客园)&Andrew Ng机器学习课程 ...
- [DeeplearningAI笔记]神经网络与深度学习人工智能行业大师访谈
觉得有用的话,欢迎一起讨论相互学习~Follow Me 吴恩达采访Geoffrey Hinton NG:前几十年,你就已经发明了这么多神经网络和深度学习相关的概念,我其实很好奇,在这么多你发明的东西中 ...
随机推荐
- 0421for循环各类题目
for循环要点 1.确认外层控制内容 2.确认内层控制内容 3.将打印内容与行号产生关系式 4.有的语句可以用if语句,根据字符的个数来增减char,优化代码 //部分类型只能输出奇数行,可在下半部分 ...
- Druid数据库连接池的使用
Druid 阿里提供的数据库连接池,集以上连接池优点于一身,开发使用此连接池 使用配置文件方式获取Druid数据库连接池 TestDruid package com.aff.connection; ...
- 记一次使用windbg排查内存泄漏的过程
一.背景 近期有一个项目在运行当中出现一些问题,程序顺利启动,但是观察一阵子后发现内存使用总量在很缓慢地升高, 虽然偶尔还会往下降一些,但是总体还是不断上升:内存运行6个小时候从33M上升到80M: ...
- 关于ubuntu下使用l2tpvpn和远程桌面windows系统的测试
一.背景: 2019年9月下旬到10月上旬,到海南澄迈福山度假.随身带的笔记本电脑中windows10系统因硬盘故障挂了,在另一块硬盘上的ubuntu18.04系统正常.因媳妇需要在10月1日远程回公 ...
- java继承会犯的小错误
注意事项:阅读本文前应该先了解java的继承.本文定位为已经继承基础知识. 一:试图覆盖私有方法 先上代码 public class Father { private void print() { S ...
- Spring Boot笔记(三) springboot 集成 Quartz 定时任务
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 1. 在 pom.xml 中 添加 Quartz 所需要 的 依赖 <!--定时器 quartz- ...
- Java实现 LeetCode 405 数字转换为十六进制数
405. 数字转换为十六进制数 给定一个整数,编写一个算法将这个数转换为十六进制数.对于负整数,我们通常使用 补码运算 方法. 注意: 十六进制中所有字母(a-f)都必须是小写. 十六进制字符串中不能 ...
- Java实现 蓝桥杯VIP 算法提高 分分钟的碎碎念
算法提高 分分钟的碎碎念 时间限制:1.0s 内存限制:256.0MB 问题描述 以前有个孩子,他分分钟都在碎碎念.不过,他的念头之间是有因果关系的.他会在本子里记录每一个念头,并用箭头画出这个念头的 ...
- Java中继承的详细用法
关于上一篇构造方法后的继承方法 构造方法链接 extends是继承的关键字 例: 下面的代码BB和CC就是AA的子类 允许一个父类有多个子类,但不允许一个子类有多个父类 /*final*/ class ...
- CSDN如何获得2020技术圈认证(新徽章哦)
打开CSDN APP 然后登陆上就可以了 把这些看完了就可以了