数据归一化Scaler-机器学习算法
//2019.08.03下午
#机器学习算法的数据归一化(feature scaling)
1、数据归一化的必要性:
对于机器学习算法的基础训练数据,由于数据类型的不同,其单位及其量纲也是不一样的,而也正是因为如此,有时它会使得训练集中每个样本的不同列数据大小差异较大,即数量级相差比较大,这会导致在机器学习算法中不同列数据的权重很大的差异,数量级大的数据所体现出来的影响会远远大于数量级小的数据(比如样本中不同列数据对k-近邻算法中欧拉距离大小的影响会因为数据的数量级而存在很大差异)。基于以上的问题,我们需要对于样本的每一行数据进行归一化处理,消除其大小尺寸对于算法训练效果的影响。
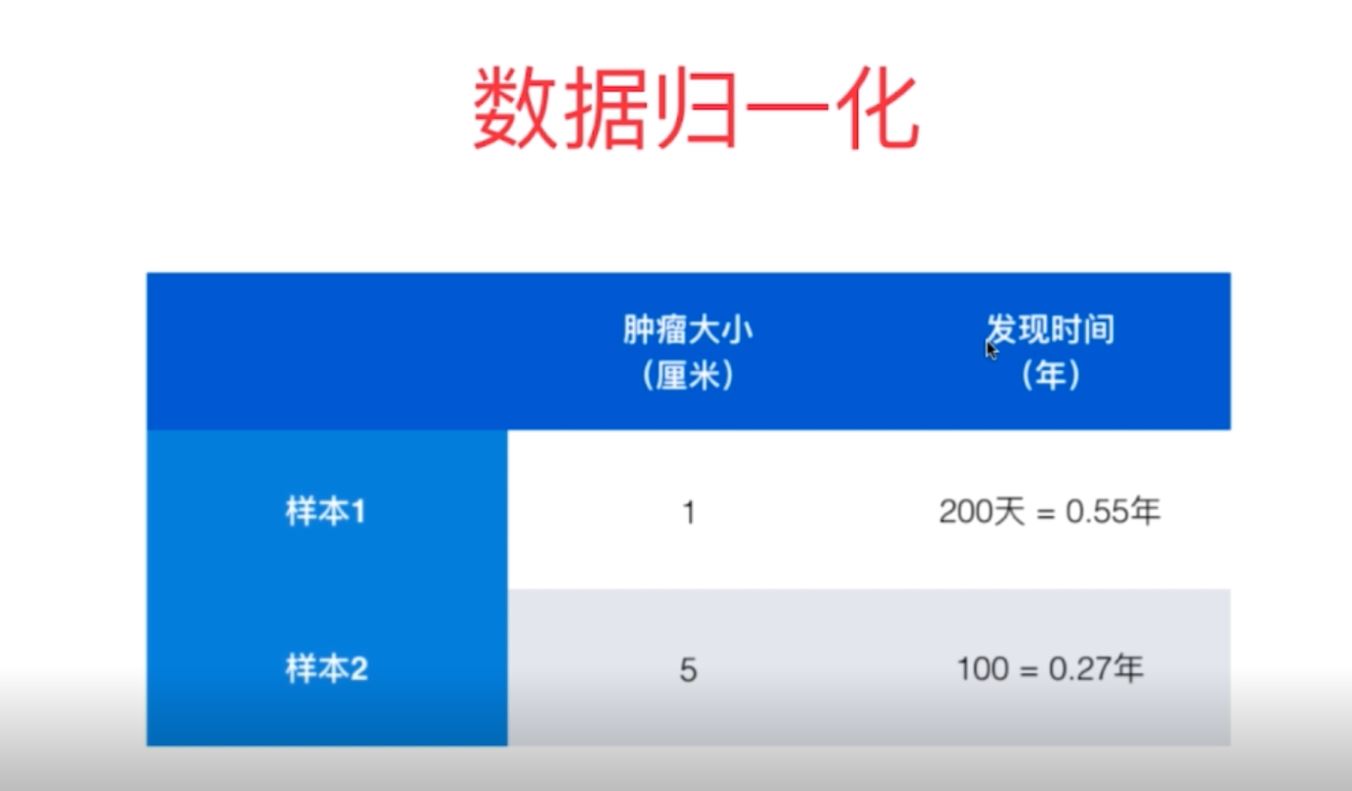
图1
2、数据归一化的处理方式:
(1)最值归一化处理方式(normalization)
将样本每一列属性数据统一归一化映射到0-1之间,最常用方法如下:

图2
这个方法是比较方便简单的归一化处理方式,主要适用于具有边界的数据(比如学生成绩,图片的像素点特征值等)
(2)均值方差归一化处理方式(standardization)
将数据归一化到正负数之间,最终处理为均值为0,方差为1的正态分布中,这种处理方式适用于数据分布没有明显的边界,数据中存在一些极端的数据值;而对于明显存在数据边界的数据也是比较适合的。

图3
综上所述,对于一般的数据分布采用均值方差归一化的方法是比较普适的。
3、数据归一化原理代码实现举例:
import numpy as np
import matplotlib.pyplot as plt
x=np.random.randint(1,100,(50,2))
print(x)
x=np.array(x,dtype=float)
print(x)
x[:,0]=(x[:,0]-np.min(x[:,0]))/(np.max(x[:,0])-np.min(x[:,0]))
x[:,1]=(x[:,1]-np.min(x[:,1]))/(np.max(x[:,1])-np.min(x[:,1])) #1均值归一化处理实现
print(x)
plt.figure()
plt.scatter(x[:,0],x[:,1],color="r")
print(np.mean(x[:,0]))
print(np.std(x[:,0]))
print(np.mean(x[:,1]))
print(np.std(x[:,1]))
x[:,0]=(x[:,0]-np.mean(x[:,0]))/(np.std(x[:,0]))
x[:,1]=(x[:,1]-np.mean(x[:,1]))/(np.std(x[:,1])) #2均值方差归一化处理方式
print(x)
plt.scatter(x[:,0],x[:,1],color="g")
plt.show()
print(np.mean(x[:,0]))
print(np.std(x[:,0]))
print(np.mean(x[:,1]))
print(np.std(x[:,1]))
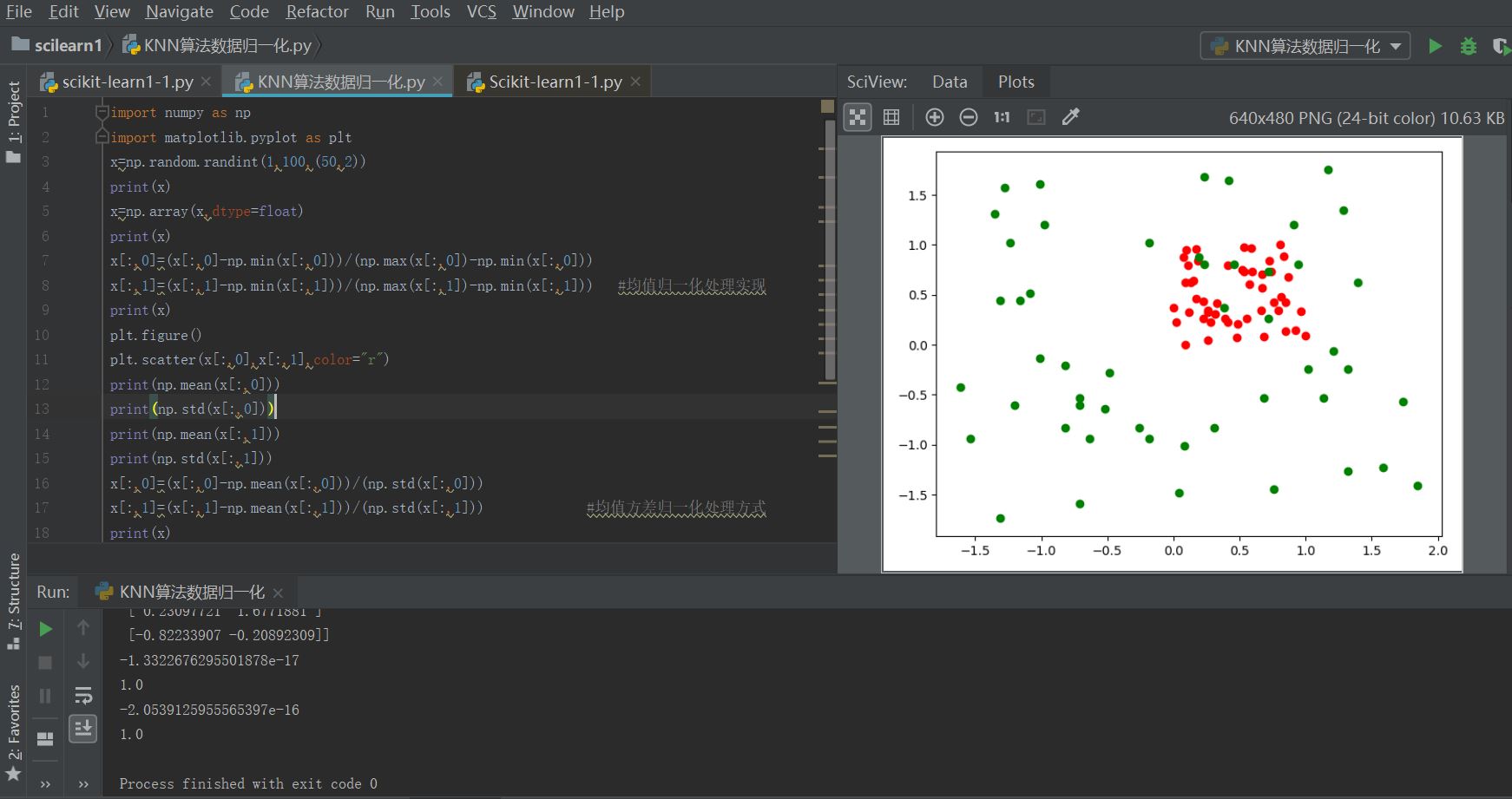
图4
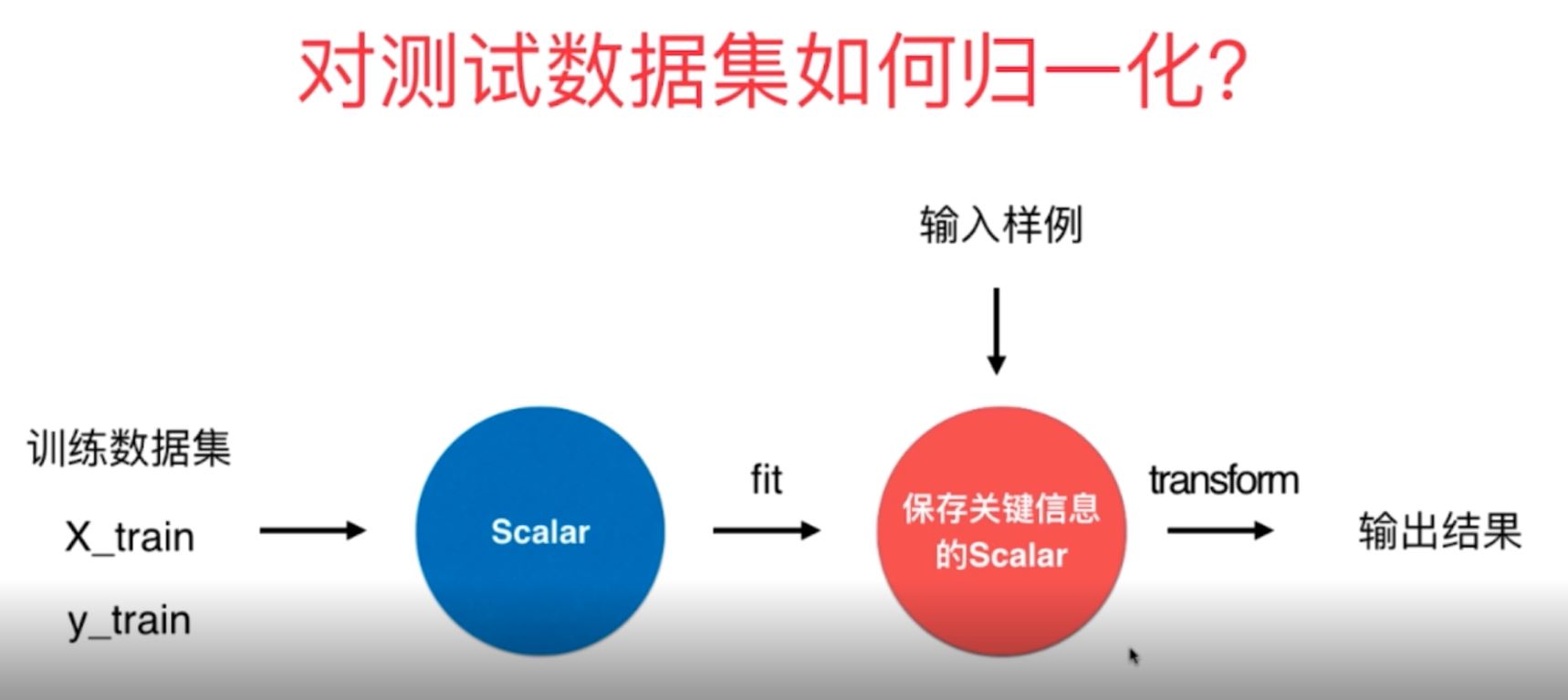
4、对于测试数据是用来模拟真实环境下的数据,而真实数据是没有固定的均值和方差的,因此在对测试数据进行处理的时候不可以利用已有测试数据集的均值与方差进行数据归一化处理,也需要使用训练数据集的平均值和方差进行相应的归一化处理.
5、在scikitlearn中有函数Scaler对于训练数据和测试数据进行相应的归一化,其归一化方式也有多种方式,常用的还是之前讲过的均值归一化MinMaxScaler和均值方差归一化函数StandardScaler,其归一化原理如上所讲。
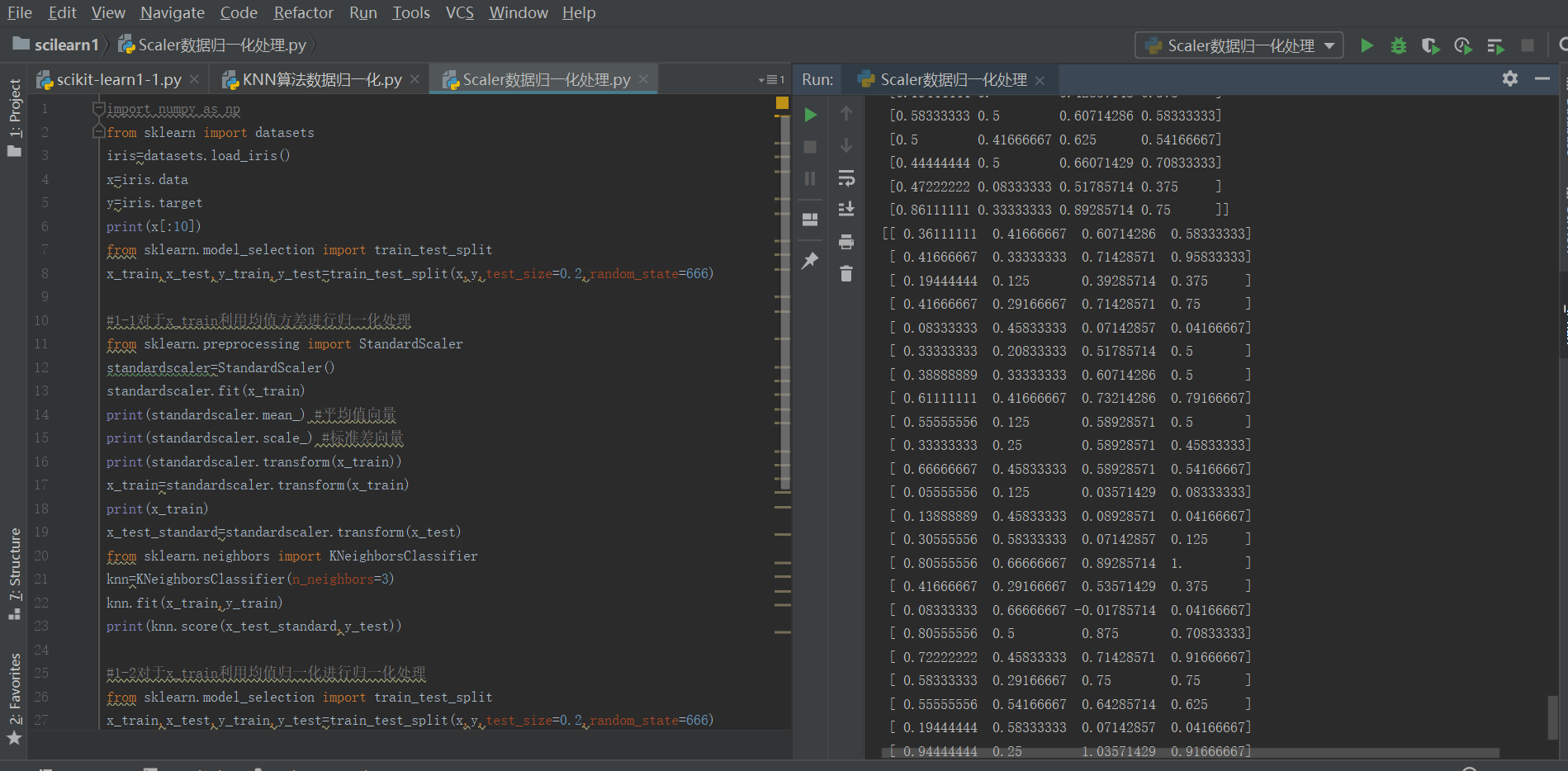
具体k-近邻算法的整体数据归一化处理、训练以及预测过程在scikitlearn中调用如下:
import numpy as np
from sklearn import datasets
#导入训练的数据集
iris=datasets.load_iris()
x=iris.data
y=iris.target #初始化属性数据和标记数据
print(x[:10])
#对于数据进行相应预处理(分割为训练集和测试集数据)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=666)
#1-1对于x_train利用均值方差StandardScaler进行归一化处理
from sklearn.preprocessing import StandardScaler
standardscaler=StandardScaler()
standardscaler.fit(x_train)
print(standardscaler.mean_) #平均值向量
print(standardscaler.scale_) #标准差向量
print(standardscaler.transform(x_train))
x_train=standardscaler.transform(x_train)
print(x_train)
x_test_standard=standardscaler.transform(x_test)
#导入相应的机器学习算法模块
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=3)
knn.fit(x_train,y_train)
print(knn.score(x_test_standard,y_test))
#1-2对于x_train利用均值MinMaxScaler进行归一化处理(整体过程与上面类似)
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=666)
from sklearn.preprocessing import MinMaxScaler
standardscaler1=MinMaxScaler()
standardscaler1.fit(x_train)
x_train=standardscaler1.transform(x_train)
print(x_train)
x_test_standard1=standardscaler1.transform(x_test)
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=3)
knn.fit(x_train,y_train)
print(x_test_standard1)
print(knn.score(x_test_standard1,y_test))
运行结果如下:
数据归一化Scaler-机器学习算法的更多相关文章
- 机器学习:数据归一化(Scaler)
数据归一化(Feature Scaling) 一.为什么要进行数据归一化 原则:样本的所有特征,在特征空间中,对样本的距离产生的影响是同级的: 问题:特征数字化后,由于取值大小不同,造成特征空间中样本 ...
- 第四十九篇 入门机器学习——数据归一化(Feature Scaling)
No.1. 数据归一化的目的 数据归一化的目的,就是将数据的所有特征都映射到同一尺度上,这样可以避免由于量纲的不同使数据的某些特征形成主导作用. No.2. 数据归一化的方法 数据归一化的方法主要 ...
- 《ServerSuperIO Designer IDE使用教程》- 7.增加机器学习算法,通讯采集数据与算法相结合。发布:4.2.5 版本
v4.2.5更新内容:1.修复服务实例设置ClearSocketSession参数时,可能出现资源无法释放而造成异常的情况.2.修复关闭宿主程序后进程仍然无法退出的问题.2.增加机器学习框架.3.优化 ...
- 【机器学习】机器学习入门02 - 数据拆分与测试&算法评价与调整
0. 前情回顾 上一周的文章中,我们通过kNN算法了解了机器学习的一些基本概念.我们自己实现了简单的kNN算法,体会了其过程.这一周,让我们继续机器学习的探索. 1. 数据集的拆分 上次的kNN算法介 ...
- 如何用Python实现常见机器学习算法-1
最近在GitHub上学习了有关python实现常见机器学习算法 目录 一.线性回归 1.代价函数 2.梯度下降算法 3.均值归一化 4.最终运行结果 5.使用scikit-learn库中的线性模型实现 ...
- 机器学习算法与Python实践之(二)支持向量机(SVM)初级
机器学习算法与Python实践之(二)支持向量机(SVM)初级 机器学习算法与Python实践之(二)支持向量机(SVM)初级 zouxy09@qq.com http://blog.csdn.net/ ...
- 【机器学习算法-python实现】KNN-k近邻算法的实现(附源代码)
,400],[200,5],[100,77],[40,300]]) shape:显示(行,列)例:shape(group)=(4,2) zeros:列出一个同样格式的空矩阵,例:zeros(group ...
- Python数据预处理:机器学习、人工智能通用技术(1)
Python数据预处理:机器学习.人工智能通用技术 白宁超 2018年12月24日17:28:26 摘要:大数据技术与我们日常生活越来越紧密,要做大数据,首要解决数据问题.原始数据存在大量不完整.不 ...
- 机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)
http://blog.csdn.net/zouxy09/article/details/20319673 机器学习算法与Python实践之(七)逻辑回归(Logistic Regression) z ...
随机推荐
- Cisco AP-格式化AP
故障情况:APC11-AP04#sho capwap ip config LWAPP Static IP ConfigurationIP Address 172.17.239.204I ...
- (转)__attribute__之section 分析详解
原文地址:__attribute__之section详解 前言 第一次接触 "section" 是在公司的一个STM32的项目代码中,前工程师将所有的初始化函数都使用的" ...
- c#活动目录操作
c#活动目录操作 https://www.cnblogs.com/ahuo/archive/2007/03/16/676853.html 添加引用 System.DirectoryServices导 ...
- nyoj 100
怒刷水题... AC代码: #include <stdio.h> int main() { int x,t,count; scanf("%d",&t); whi ...
- Day11 - B - Dice (III) LightOJ - 1248
设dp_i为已经出现了i面,需要的期望次数,dp_n=0 那么dp_i= i/n*dp_i + (n-i)/n*dp_(i+1) + 1 现在已经i面了,i/n的概率再选择一次i面,(n-i)/n的概 ...
- 「AHOI2014/JSOI2014」支线剧情
「AHOI2014/JSOI2014」支线剧情 传送门 上下界网络流. 以 \(1\) 号节点为源点 \(s\) ,新建一个汇点 \(t\),如果 \(u\) 能到 \(v\),那么连边 \(u \t ...
- 软件工程 - 防御式编程EAFP vs LBYL
概念 EAFP:easier to ask forgiveness than permission LBYL:look before you leap 代码 # LBYL def getUserInf ...
- solve License Key is legacy format when use ACTIVATION_CODE activate jetbrains-product 2019.3.1
1.the java-agent and ACTIVATION_CODE can get from this site:https://zhile.io/2018/08/25/jetbrains-li ...
- 使用git commit命令时会提示"Please tell me who you are"
在命令行中输入 git config --global user.email "邮箱地址" git config --global user.name "用户名" ...
- 19年读100本书之第二本--《OKR工作法》-克里斯蒂娜 沃特克
0,一句话概括书的内容? OKR(objective key result),即目标与关键结果. 1,我从这本书能得到什么? 2,核心内容是什么? 3,我要怎么做?