<强化学习>基于采样迭代优化agent
前面介绍了三种采样求均值的算法
——MC
——TD
——TD(lamda)
下面我们基于这几种方法来 迭代优化agent
传统的强化学习算法
||
ν
ν
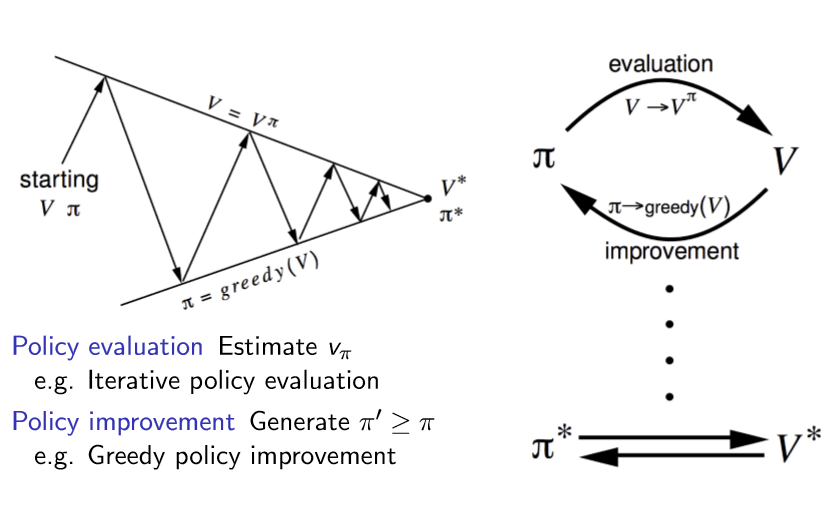
已经知道完整MDP——使用价值函数V(s)
没有给出完整MDP——使用价值函数Q(s,a)
可见我们的目标就是确定下来最优策略和最优价值函数
|
|——有完整MDP && 用DP解决复杂度较低
| ====》 使用贝尔曼方程和贝尔曼最优方程求解
|——没有完整MDP(ENV未知) or 知道MDP但是硬解MDP问题复杂度太高
| ====》 policy evaluation使用采样求均值的方法
| |—— ON-POLICY MC
| |—— ON-POLICY TD
| |____ OFF-POLICY TD
1 价值函数是V(s)还是Q(s,a)?
agent对外界好坏的认识是对什么的认识呢?是每一个状态s的好坏还是特定状态下采取特定行为(s,a)的好坏?
这取决于是什么样的问题背景。
有完整的MDP,知道从这个状态下采取某行为会有多大概率后继状态为某状态,那么我们的agent需要知道的是状态的好坏。如sutton书中的jack‘s car rental问题,方格问题等等,这些都是事先就明确知道状态行为转移概率矩阵的。丝毫没有“人工智能”的感觉。
没有完整的MDP,知道从这个状态下采取某行为会有多大概率后继状态为某状态,那么我们的agent需要知道的是状态行为对(s,a)的好坏。比如,围棋!我们下子之后,对手会把棋落哪是完全没法预测的,所以后继state是绝对不可预测,所以agent是不能用V(s)作为评价好坏的价值函数,所以agent应该在乎的是这个(s,a)好这个(s,a)不好,所以使用Q(s,a)作为价值函数。
2. ON-POLICY 和OFF-POLICY
on policy :基于策略A采样获取episode,并且被迭代优化的策略也是A
off policy :基于策略A采样获取episode,而被迭代优化的策略是B
3.为什么ε-greedy探索在on policyRL算法中行之有效?
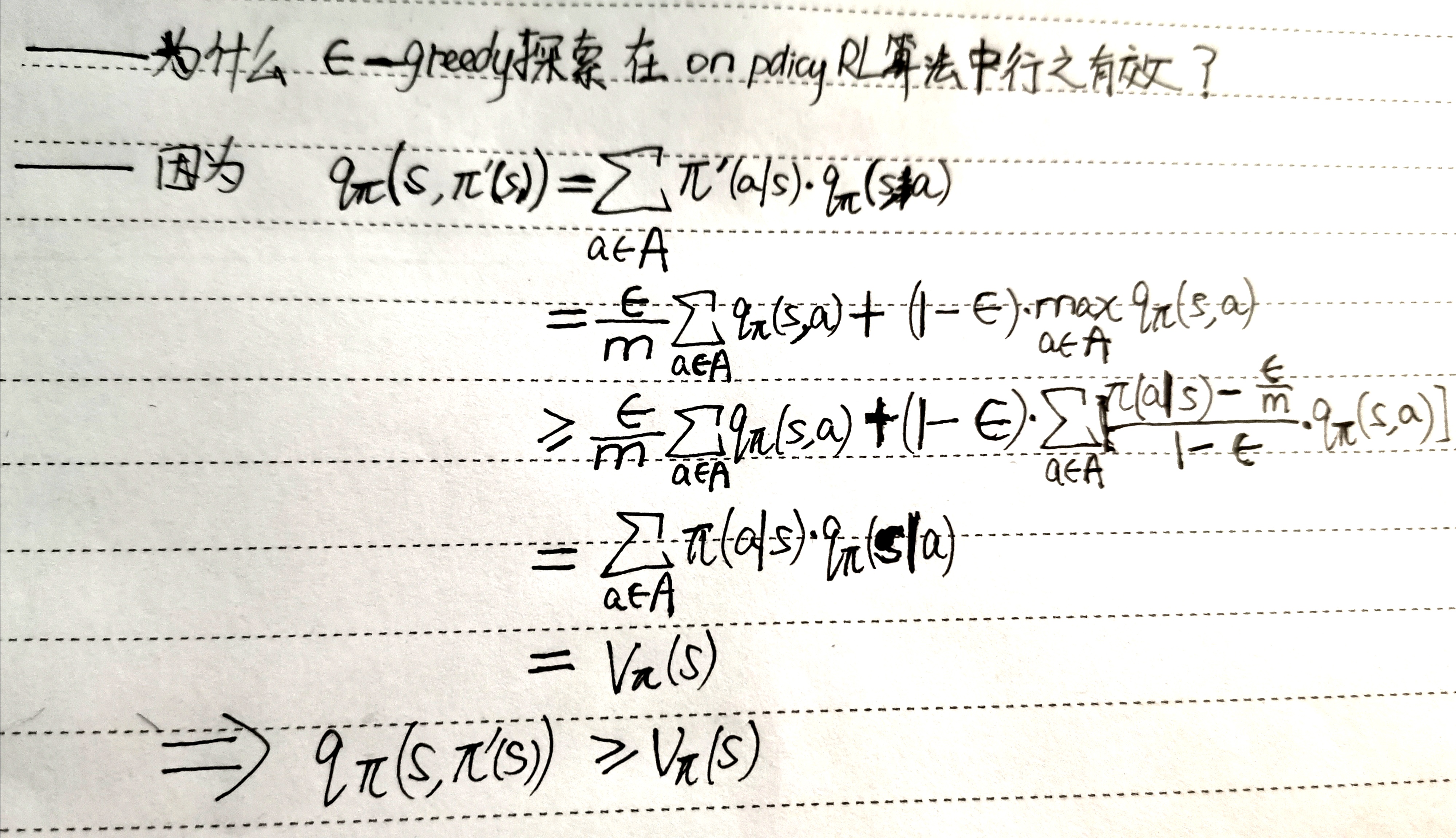
<强化学习>基于采样迭代优化agent的更多相关文章
- 强化学习之七:Visualizing an Agent’s Thoughts and Actions
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习论文(Scalable agent alignment via reward modeling: a research direction)
原文地址: https://arxiv.org/pdf/1811.07871.pdf ======================================================== ...
- 深度学习-强化学习(RL)概述笔记
强化学习(Reinforcement Learning)简介 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予 ...
- <强化学习>开门帖
(本系列只用作本人笔记,如果看官是以新手开始学习RL,不建议看我写的笔记昂) 今天是2020年2月7日,开始二刷david silver ulc课程.https://www.youtube.com/w ...
- David Silver强化学习Lecture1:强化学习简介
课件:Lecture 1: Introduction to Reinforcement Learning 视频:David Silver深度强化学习第1课 - 简介 (中文字幕) 强化学习的特征 作为 ...
- 【转载】 准人工智能分享Deep Mind报告 ——AI“元强化学习”
原文地址: https://www.sohu.com/a/231895305_200424 ------------------------------------------------------ ...
- DQN(Deep Q-learning)入门教程(一)之强化学习介绍
什么是强化学习? 强化学习(Reinforcement learning,简称RL)是和监督学习,非监督学习并列的第三种机器学习方法,如下图示: 首先让我们举一个小时候的例子: 你现在在家,有两个动作 ...
- 伯克利、OpenAI等提出基于模型的元策略优化强化学习
基于模型的强化学习方法数据效率高,前景可观.本文提出了一种基于模型的元策略强化学习方法,实践证明,该方法比以前基于模型的方法更能够应对模型缺陷,还能取得与无模型方法相近的性能. 引言 强化学习领域近期 ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
随机推荐
- Spring Boot Security JWT 整合实现前后端分离认证示例
前面两章节我们介绍了 Spring Boot Security 快速入门 和 Spring Boot JWT 快速入门,本章节使用 JWT 和 Spring Boot Security 构件一个前后端 ...
- GO常量/枚举
常量中的数据类型只可以是布尔型.数字型(整数型.浮点型和复数)和字符串型. 常量的定义格式: const identifier [type] = value 你可以省略类型说明符 [type],因为编 ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 排版:设定文本居中对齐
<!DOCTYPE html> <html> <head> <title>菜鸟教程(runoob.com)</title> <meta ...
- centos7中redis安装
官网地址:http://redis.io/ 官网下载地址:http://redis.io/download 1. 下载Redis源码(tar.gz),并上传到Linux:或 wget http://d ...
- 谈谈spring mvc与struts的区别
1.Struts2是类级别的拦截, 一个类对应一个request上下文,SpringMVC是方法级别的拦截,一个方法对应一个request上下文,而方法同时又跟一个url对应,所以说从架构本身上Spr ...
- SICP题解
这里用Common Lisp.Haskell等函数式语言. 1.2.请将下面表达式变换为前缀形式: $$ \frac{5 + 4 + (2 - (3 - (6 + \frac{4}{5})))}{3( ...
- 使用 C++ 处理 JSON 数据交换格式
一.摘要 JSON 的全称为:JavaScript Object Notation,顾名思义,JSON 是用于标记 Javascript 对象的,JSON 官方的解释为:JSON 是一种轻量级的数据传 ...
- 利用django打造自己的工作流平台(一):从EXCEL到流程化运作
因工作所需以及管理个人一些日常事项,自己基于django(一个基于python的web框架,详细介绍可查阅相关资料)开发了一个简易的工作流平台[平台地址].本文首先简要介绍工作流平台的设计思想及其在项 ...
- python基础面试题1
Python面试重点(基础篇) 注意:只有必答题部分计算分值,补充题不计算分值. 第一部分 必答题(每题2分) 简述列举了解的编程语言及语言间的区别? c语言是编译型语言,运行速度快,但翻译时间长py ...
- ROS学习笔记8-rqt_console和roslaunch
本教程来自于:http://wiki.ros.org/ROS/Tutorials/UsingRqtconsoleRoslaunch rqt_console 和 rqt_logger_level 是ro ...