<强化学习>基于采样迭代优化agent
前面介绍了三种采样求均值的算法
——MC
——TD
——TD(lamda)
下面我们基于这几种方法来 迭代优化agent
传统的强化学习算法
||
ν
ν
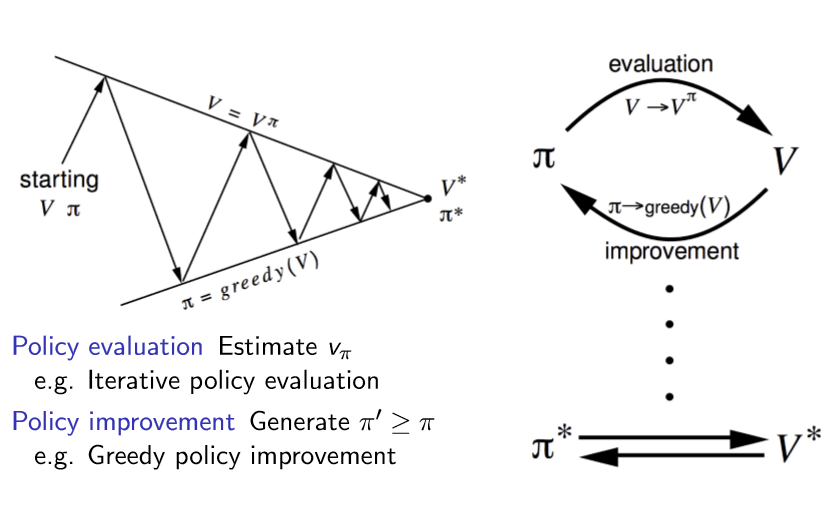
已经知道完整MDP——使用价值函数V(s)
没有给出完整MDP——使用价值函数Q(s,a)
可见我们的目标就是确定下来最优策略和最优价值函数
|
|——有完整MDP && 用DP解决复杂度较低
| ====》 使用贝尔曼方程和贝尔曼最优方程求解
|——没有完整MDP(ENV未知) or 知道MDP但是硬解MDP问题复杂度太高
| ====》 policy evaluation使用采样求均值的方法
| |—— ON-POLICY MC
| |—— ON-POLICY TD
| |____ OFF-POLICY TD
1 价值函数是V(s)还是Q(s,a)?
agent对外界好坏的认识是对什么的认识呢?是每一个状态s的好坏还是特定状态下采取特定行为(s,a)的好坏?
这取决于是什么样的问题背景。
有完整的MDP,知道从这个状态下采取某行为会有多大概率后继状态为某状态,那么我们的agent需要知道的是状态的好坏。如sutton书中的jack‘s car rental问题,方格问题等等,这些都是事先就明确知道状态行为转移概率矩阵的。丝毫没有“人工智能”的感觉。
没有完整的MDP,知道从这个状态下采取某行为会有多大概率后继状态为某状态,那么我们的agent需要知道的是状态行为对(s,a)的好坏。比如,围棋!我们下子之后,对手会把棋落哪是完全没法预测的,所以后继state是绝对不可预测,所以agent是不能用V(s)作为评价好坏的价值函数,所以agent应该在乎的是这个(s,a)好这个(s,a)不好,所以使用Q(s,a)作为价值函数。
2. ON-POLICY 和OFF-POLICY
on policy :基于策略A采样获取episode,并且被迭代优化的策略也是A
off policy :基于策略A采样获取episode,而被迭代优化的策略是B
3.为什么ε-greedy探索在on policyRL算法中行之有效?
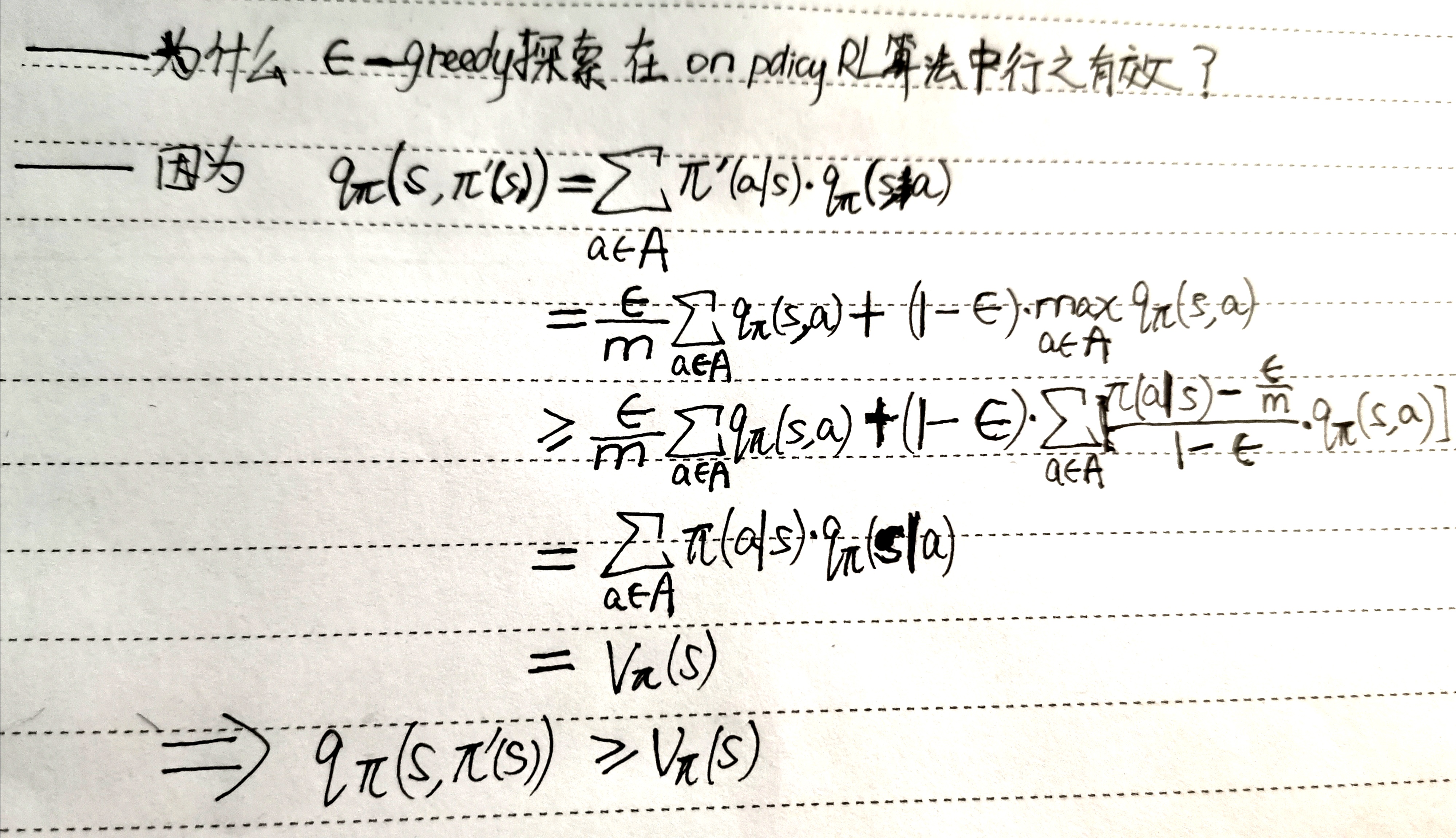
<强化学习>基于采样迭代优化agent的更多相关文章
- 强化学习之七:Visualizing an Agent’s Thoughts and Actions
本文是对Arthur Juliani在Medium平台发布的强化学习系列教程的个人中文翻译,该翻译是基于个人分享知识的目的进行的,欢迎交流!(This article is my personal t ...
- 强化学习论文(Scalable agent alignment via reward modeling: a research direction)
原文地址: https://arxiv.org/pdf/1811.07871.pdf ======================================================== ...
- 深度学习-强化学习(RL)概述笔记
强化学习(Reinforcement Learning)简介 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予 ...
- <强化学习>开门帖
(本系列只用作本人笔记,如果看官是以新手开始学习RL,不建议看我写的笔记昂) 今天是2020年2月7日,开始二刷david silver ulc课程.https://www.youtube.com/w ...
- David Silver强化学习Lecture1:强化学习简介
课件:Lecture 1: Introduction to Reinforcement Learning 视频:David Silver深度强化学习第1课 - 简介 (中文字幕) 强化学习的特征 作为 ...
- 【转载】 准人工智能分享Deep Mind报告 ——AI“元强化学习”
原文地址: https://www.sohu.com/a/231895305_200424 ------------------------------------------------------ ...
- DQN(Deep Q-learning)入门教程(一)之强化学习介绍
什么是强化学习? 强化学习(Reinforcement learning,简称RL)是和监督学习,非监督学习并列的第三种机器学习方法,如下图示: 首先让我们举一个小时候的例子: 你现在在家,有两个动作 ...
- 伯克利、OpenAI等提出基于模型的元策略优化强化学习
基于模型的强化学习方法数据效率高,前景可观.本文提出了一种基于模型的元策略强化学习方法,实践证明,该方法比以前基于模型的方法更能够应对模型缺陷,还能取得与无模型方法相近的性能. 引言 强化学习领域近期 ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
随机推荐
- Write-Up-wakanda-1
关于 下载地址:点我 哔哩哔哩:哔哩哔哩 祖传开头 信息收集 这里用vm虚拟机可能有一点问题,因为官方的是用vbox虚拟机导出的镜像文件.所以这次使用vbox虚拟机. ➜ ~ ip a show de ...
- Plastic Sprayers Manufacturer - Spray Principle, Spray Note
The Plastic Sprayers Manufacturer stated that the spray is artificial fogging. Simply put, th ...
- flask view
flask view 1. flask view 1.1. @route 写个验证用户登录的装饰器:在调用函数前,先检查session里有没有用户 from functools imp ...
- Mybatis的逆向工程以及Example的实例函数及详解
Mybatis-generator是Mybatis的逆向工程 (根据数据库中的表生成java代码) Mybatis的逆向工程会生成实例及实例对应的example,example用于添加条件,相当于w ...
- MFC TreeControl简单应用
目录 1. TreeControl添加节点 2. TreeControl菜单 3. TreeControl修改节点 4. TreeControl查找节点 5. TreeControl折叠展开节点 6. ...
- Hadoop基准测试(一)
测试对于验证系统的正确性.分析系统的性能来说非常重要,但往往容易被我们所忽视.为了能对系统有更全面的了解.能找到系统的瓶颈所在.能对系统性能做更好的改进,打算先从测试入手,学习Hadoop主要的测试手 ...
- 【 JdbcUtils 】mysql数据库查询
JdbcUtils package k.util; import java.sql.*; import java.util.ArrayList; import java.util.HashMap; i ...
- EcShop二次开发学习方法
EcShop二次开发学习方法 (2012-03-08 11:10:08) 转载▼ 标签: 京东 公用函数库 二次开发 sql语言 数据库设计 杂谈 分类: ecshop 近年来,随着互联网的发展,电子 ...
- JMeter配置JDBC测试SQL Server/MySQL/ORACLE
一.配置SQL Server 1.下载sql驱动,将sqljdbc4.jar放到JMeter安装目录/lib下. 2.启动JMeter,右键添加->配置文件->JDBC Connectio ...
- Python学习笔记001
二进制 换算: 十进制转二进制 除二取余,然后倒序排列,高位补零. 将正的十进制数除以二,得到的商再除以二,依次类推知道商为零或一时为止,然后在旁边标出各步的余数,最后倒着写出来,高位补零就可以. 二 ...