【大厂面试06期】谈一谈你对Redis持久化的理解?
Redis持久化是面试中经常会问到的问题,这里主要通过对以下几个问题进行分析,帮助大家了解Redis持久化的实现原理。
1.Redis持久化是什么?
2.Redis持久化有哪些策略?各自的实现原理是怎么样的?
3.Redis的数据恢复策略是怎么样的?
4.Redis持久化策略该如何进行选择?
1.Redis持久化是什么?
因为Redis是一个内存数据库,数据保存在内存中,一旦发生关机或者重启,内存中的数据都会丢失,所以为了能够重启时恢复数据,Redis提供了持久化的机制,正常运行期间根据策略生成持久化文件。在机器重启后,可以根据根据持久化文件恢复内存中的数据。Redis还为我们提供了持久化的机制。(虽然有主从同步,主机挂掉之后,可以让从节点成为主节点,但是如果整个机房都发生停电,那么主节点和从节点内存中的数据都会丢失,所以这也是持久化存在的意义。)
2.Redis持久化有哪些策略?
Redis持久化的策略主要有AOF持久化,RDB持久化,混合持久化。这是我自己总结的一个图:
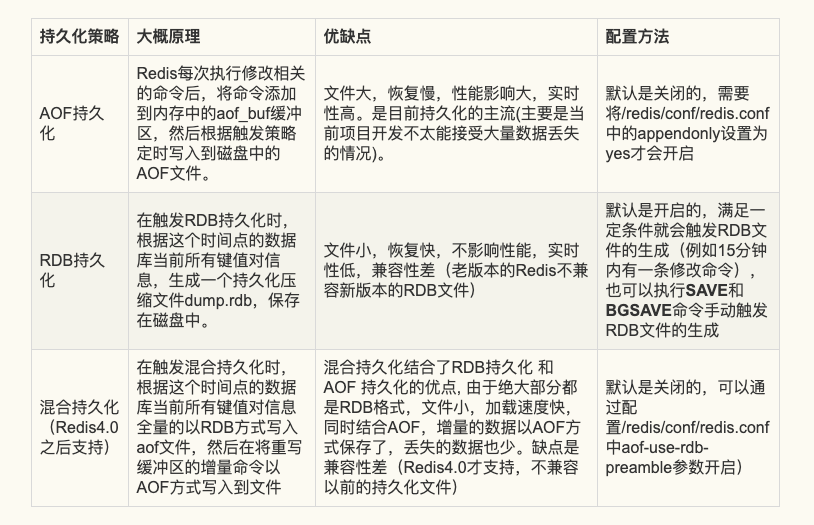
AOF持久化
执行流程
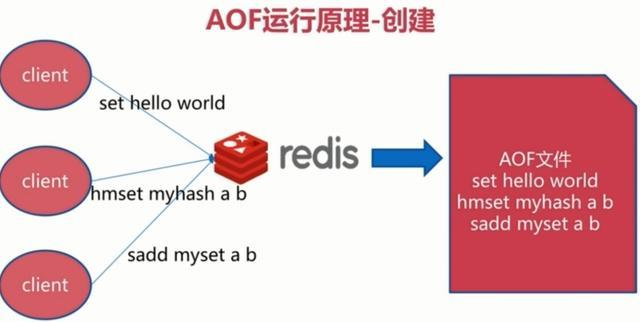
AOF持久化主要是Redis在修改相关的命令后,将命令添加到aof_buf缓存区的末尾,然后在每次事件循环结束时,
根据appendfsync的配置:
appendfsync = always 每条修改命令都会更新到磁盘上的AOF文件, 最多只会丢失当前正在写入的命令
appendfsync = everysec 每秒更新到磁盘上的AOF文件一次, 最多丢失2秒的数据(因为执行fsync命令刷盘也需要时间,下面会解释)
appendfsync = no 不自动更新到磁盘上的AOF文件,由操作系统来决定何时刷盘(linux 貌似大部分默认是 30s)。可能会丢失刷盘之前的写入数据。
(基于性能考虑一般生产环境的配置都是everysec)
(aof_buf是Redis中的SDS结构,可以理解为是一个字符串,只是对C语言的字符串做了一些优化,每次将新执行的更新命令添加到字符串末尾。)
怎么防止AOF文件越来越大?
为了防止AOF文件越来越大,可以通过执行BGREWRITEAOF命令,会fork子进程出来,读取当前数据库的键值对信息,生成所需的写命令,写入新的AOF文件。在生成期间,父进程继续正常处理请求,执行修改命令后,不仅会将命令写入aof_buf缓冲区,还会写入重写aof_buf缓冲区。当新的AOF文件生成完毕后,子进程父进程发送信号,父进程将重写aof_buf缓冲区的修改命令写入新的AOF文件,写入完毕后,对新的AOF文件进行改名,原子地(atomic)地替换旧的AOF文件。
什么是AOF文件追加阻塞?
修改命令添加到aof_buf之后,如果配置是everysec那么会每秒执行fsync操作,调用write写入磁盘一次,但是如果硬盘负载过高,fsync操作可能会超过1s,Redis主线程持续高速向aof_buf写入命令,硬盘的负载可能会越来越大,IO资源消耗更快,所以Redis的处理逻辑是会对比上次fsync成功的时间,如果超过2s,则主线程阻塞直到fsync同步完成,所以最多可能丢失2s的数据,而不是1s。
RDB持久化
RDB持久化指的是在满足一定的触发条件时(在一个的时间间隔内执行修改命令达到一定的数量,或者手动执行SAVE和BGSAVE命令),对这个时间点的数据库所有键值对信息生成一个压缩文件dump.rdb,然后将旧的删除,进行替换。
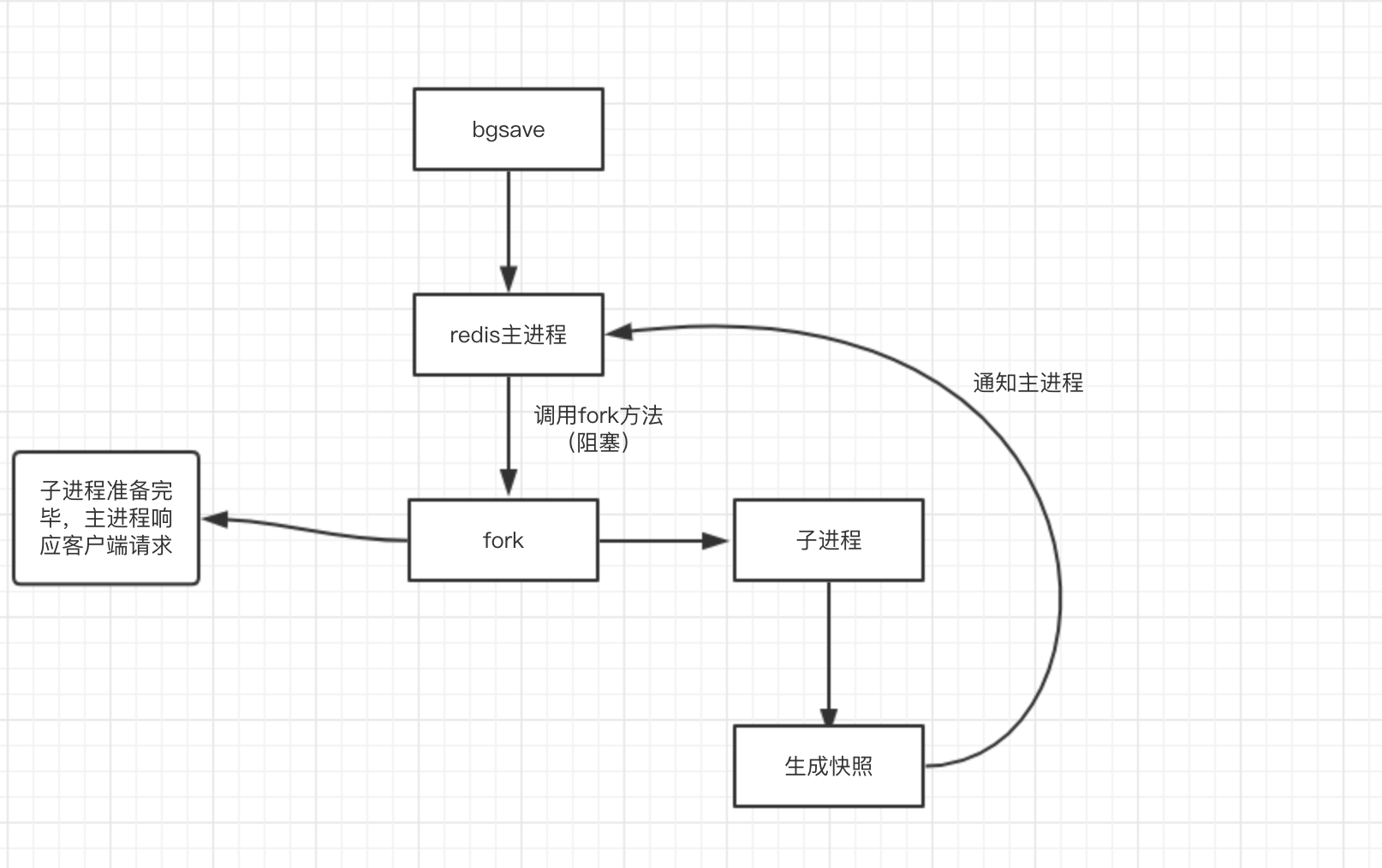
执行流程
实现原理是fork一个子进程,然后对键值对进行遍历,生成rdb文件,在生成过程中,父进程会继续处理客户端发送的请求,当父进程要对数据进行修改时,会对相关的内存页进行拷贝,修改的是拷贝后的数据。(也就是COPY ON WRITE,写时复制技术,就是当多个调用者同时请求同一个资源,如内存或磁盘上的数据存储,他们会共用同一个指向资源的指针,指向相同的资源,只有当一个调用者试图修改资源的内容时,系统才会真正复制一份专用副本给这个调用者,其他调用者还是使用最初的资源,在CopyOnWriteArrayList的实现中,也有用到,添加或者插入一个新元素时过程是,加锁,对原数组进行复制,然后添加新元素,然后替代旧数组,解锁)
//CopyOnWriteArrayList的添加元素的方法
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
混合持久化(Redis4.0+)
执行流程
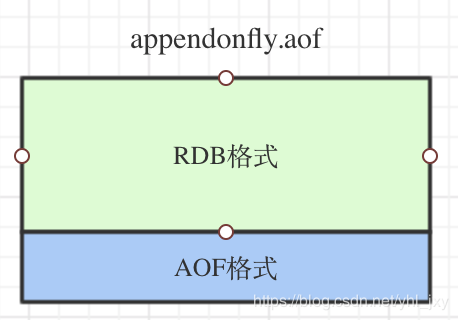
混合持久化同样也是通过bgrewriteaof命令完成的,不同的是当开启混合持久化时,fork出的子进程先将当前内存中的键值对信息全量的以RDB方式写入aof文件,然后在将重写缓冲区的增量命令以AOF方式写入到文件,写入完成后通知主进程更新统计信息,并将新的含有RDB格式和AOF格式的AOF文件替换旧的的AOF文件。简单的说:新的AOF文件前半段是RDB格式的全量数据后半段是AOF格式的增量数据,如下图:
3.Redis的数据恢复策略是怎么样的?
1.如果配置了混合持久化,那么根据混合持久化文件进行恢复数据。(Redis4.0+)
2.只配置 AOF ,重启时加载 AOF 文件恢复数据。
3.同时配置了 RDB 和 AOF ,启动时只加载 AOF文件恢复数据,如果AOF文件损坏,那么根据RDB文件恢复数据。
4.只配置 RDB,启动时加载RDB持久化文件恢复数据。
4.Redis持久化策略该如何进行选择?
(因为混合持久化是Redis 4.0之后支持的,目前一般生成环境使用的Redis版本可能都还较低,所以这里的策略选择主要是针对AOF持久和RDB持久化进行技术选型。)
以下是几种持久化方案选择的场景:
1.不需要考虑数据丢失的情况
那么不需要考虑持久化。
2.单机实例情况下
可以接受丢失十几分钟及更长时间的数据,可以选择RDB持久化,对性能影响小,如果只能接受秒级的数据丢失,只能选择AOF持久化。
3.在主从环境下
因为主服务器在执行修改命令后,会将命令发送给从服务器,从服务进行执行后,与主服务器保持数据同步,实现数据热备份,在master宕掉后继续提供服务。同时也可以进行读写分离,分担Redis的读请求。
那么在从服务器进行数据热备份的情况下,是否还需要持久化呢?
需要持久化,因为不进行持久化,主服务器,从服务器同时出现故障时,会导致数据丢失。(例如:机房全部机器断电)。如果系统中有自动拉起机制(即检测到服务停止后重启该服务)将master自动重启,由于没有持久化文件,那么master重启后数据是空的,slave同步数据也变成了空的。应尽量避免“自动拉起机制”和“不做持久化”同时出现。
所以一般可以采用以下方案:
主服务器不开启持久化,使得主服务器性能更好。
从服务器开启AOF持久化,关闭RDB持久化,并且定时对AOF文件进行备份,以及在凌晨执行bgaofrewrite命令来进行AOF文件重写,减小AOF文件大小。(当然如果对数据丢失容忍度高也可以开启RDB持久化,关闭AOF持久化)
4.异地灾备
一般性的故障(停电,关机)不会影响到磁盘,但是一些灾难性的故障(地震,洪水)会影响到磁盘,所以需要定时把单机上或从服务器上的AOF文件,RDB文件备份到其他地区的机房。
【大厂面试06期】谈一谈你对Redis持久化的理解?的更多相关文章
- 【大厂面试02期】Redis过期key是怎么样清理的?
PS:本文已收录到1.1K Star数开源学习指南--<大厂面试指北>,如果想要了解更多大厂面试相关的内容,了解更多可以看 http://notfound9.github.io/inter ...
- 【大厂面试08期】谈一谈你对HashMap的理解?
摘要 HashMap的原理也是大厂面试中经常会涉及的问题,同时也是工作中常用到的Java容器,本文主要通过对以下问题进行分析讲解,来帮助大家理解HashMap的原理. 1.HashMap添加一个键值对 ...
- 【大厂面试03期】MySQL是怎么解决幻读问题的?
问题分析 首先幻读是什么? 根据MySQL文档上面的定义 The so-called phantom problem occurs within a transaction when the same ...
- 【大厂面试07期】说一说你对synchronized锁的理解?
synchronized锁的原理也是大厂面试中经常会涉及的问题,本文主要通过对以下问题进行分析讲解,来帮助大家理解synchronized锁的原理. 1.synchronized锁是什么?锁的对象是什 ...
- 【大厂面试04期】讲讲一条MySQL更新语句是怎么执行的?
流程图 这是在网上找到的一张流程图,写的比较好,大家可以先看图,然后看详细阅读下面的各个步骤. 执行流程: 1.连接验证及解析 客户端与MySQL Server建立连接,发送语句给MySQL Serv ...
- 【大厂面试05期】说一说你对MySQL中锁的了解?
这是我总结的一个表格,是本文中涉及到的锁(因为篇幅有限就没有包括自增锁) 加锁范围 名称 用法 数据库级 全局读锁 执行Flush tables with read lock命令各整个库接加一个读锁, ...
- 4000字干货长文!从校招和社招的角度说说如何准备Java后端大厂面试?
插个题外话,为了写好这篇文章内容,我自己前前后后花了一周的时间来总结完善,文章内容应该适用于每一个学习 Java 的朋友!我觉得这篇文章的很多东西也是我自己写给自己的,比如从大厂招聘要求中我们能看到哪 ...
- 大厂面试:一个四年多经验程序员的BAT面经(字节、阿里、腾讯)
前言 上次写了篇欢聚时代的面经,公众号后台有些读者反馈说看的意犹未尽,希望我尽快更新其他大厂的面经,这里先说声抱歉,不是我太懒,而是项目组刚好有个活动要赶在春节前上线,所以这几天经常加班,只能工作之余 ...
- 从一张图开始,谈一谈.NET Core和前后端技术的演进之路
从一张图开始,谈一谈.NET Core和前后端技术的演进之路 邹溪源,李文强,来自长沙.NET技术社区 一张图 2019年3月10日,在长沙.NET 技术社区组织的技术沙龙<.NET Core和 ...
随机推荐
- Crystal | 水晶方法的七大特征,你了解吗?
本文摘自敏捷开发 20世纪90年代末,Alistair Cockburn提出水晶方法论. 自2001年的敏捷宣言提出以来,以极限编程为首的一系列敏捷方法逐渐走入大众视野,其中就包括水晶方法(Cryst ...
- MyCat水平分库
一.什么是水平分库 将一张表水平切分到多个库中 1.1分片原则 1.需要分片的表是少数的 2.能不切分尽量不要切分 3.日志表可以采取归档方式 4.选择合适的切分规则和分片建,确保数据分片均匀,否则依 ...
- hdu3861他的子问题是poj2762二分匹配+Tarjan+有向图拆点 其实就是求DAG的最小覆盖点
The King’s Problem Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Other ...
- Python中ThreadLocal的理解与使用
一.对 ThreadLocal 的理解 ThreadLocal,有的人叫它线程本地变量,也有的人叫它线程本地存储,其实意思一样. ThreadLocal 在每一个变量中都会创建一个副本,每个线程都可以 ...
- SQL——处理列中NULL值
处理NULL值 - 数据库中某列为NULL值,使用函数在列值为NULL时返回固定值. SQLServer:ISNULL(col,value) 示例:SELECT ISNULL(co ...
- NO.5 CCS运行demo(云端)
我们在demo的README中发现如果程序在云端运行会有很酷的界面而且功能会多一些. 首先我们在CCS开始界面点击Resourse Explorer 然后在浏览器中找到对应的demo 打开GUI界面, ...
- 工作中oracle常用操作
常用数据库操作 启动数据库监听器lsnrctl start 停止数据库监听器lsnrctl stop 登录oraclesqlplus / as sysdba启动oralcestartup;关闭orac ...
- CTR学习笔记&代码实现6-深度ctr模型 后浪 xDeepFM/FiBiNET
xDeepFM用改良的DCN替代了DeepFM的FM部分来学习组合特征信息,而FiBiNET则是应用SENET加入了特征权重比NFM,AFM更进了一步.在看两个model前建议对DeepFM, Dee ...
- MySQL不香吗,清华架构师告诉你为什么还要有noSQL?
强烈推荐观看: 阿里P8架构师谈(数据库系列):NoSQL使用场景和选型比较,以及与SQL的区别_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliwww.bilibili.com noSQL的大概 ...
- Rocket - tilelink - RegionReplicator
https://mp.weixin.qq.com/s/XZVCdt50tM6lavchGm9GRg 简单介绍RegionReplicator的实现. 1. 基本介绍 根据mask ...