第二十篇ORM查询与SQL语句
ORM查询与SQL语句
多表操作
创建模型
实例:我们来假定下面这些概念,字段和关系
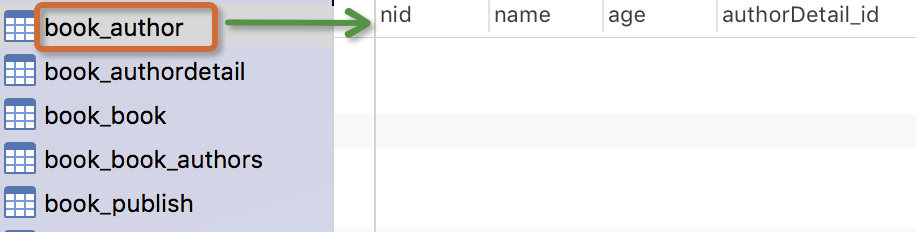
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
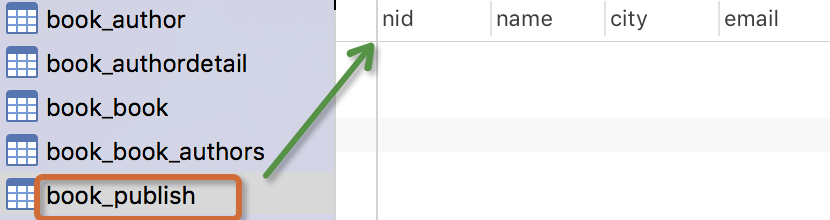
出版商模型:出版商有名称,所在城市以及email。
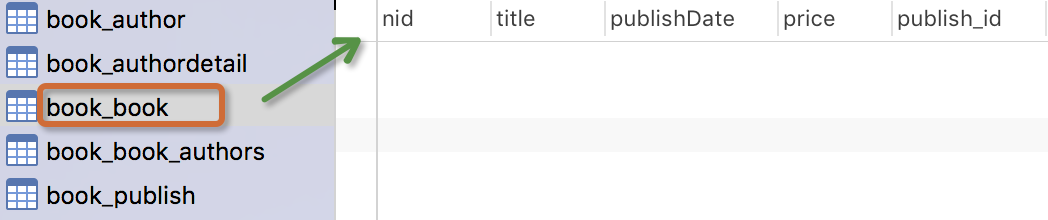
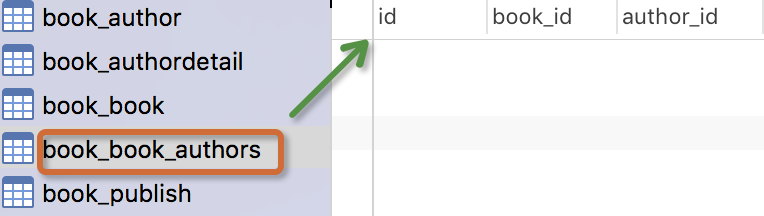
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
模型建立如下:
from django.db import models # Create your models here. class Author(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=)
age=models.IntegerField() # 与AuthorDetail建立一对一的关系
authorDetail=models.OneToOneField(to="AuthorDetail",on_delete=models.CASCADE) class AuthorDetail(models.Model): nid = models.AutoField(primary_key=True)
birthday=models.DateField()
telephone=models.BigIntegerField()
addr=models.CharField( max_length=) class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=)
city=models.CharField( max_length=)
email=models.EmailField() class Book(models.Model): nid = models.AutoField(primary_key=True)
title = models.CharField( max_length=)
publishDate=models.DateField()
price=models.DecimalField(max_digits=,decimal_places=) # 与Publish建立一对多的关系,外键字段建立在多的一方
publish=models.ForeignKey(to="Publish",to_field="nid",on_delete=models.CASCADE)
# 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表
authors=models.ManyToManyField(to='Author',)
生成表如下:

注意事项:
- 表的名称
myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称 id字段是自动添加的- 对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
- 这个例子中的
CREATE TABLESQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。 - 定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加
models.py所在应用的名称。 - 外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
添加表纪录
操作前先简单的录入一些数据:
publish表:

author表:
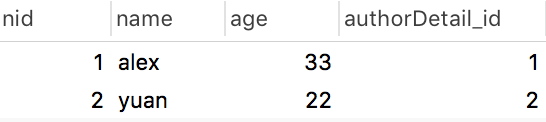
authordetail表:
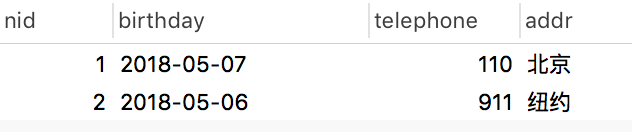
一对多
方式1:
publish_obj=Publish.objects.get(nid=)
book_obj=Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=,publish=publish_obj) 方式2:
book_obj=Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=,publish_id=)

核心:book_obj.publish与book_obj.publish_id是什么?
多对多

# 当前生成的书籍对象
book_obj=Book.objects.create(title="追风筝的人",price=200,publishDate="2012-11-12",publish_id=1)
# 为书籍绑定的做作者对象
yuan=Author.objects.filter(name="yuan").first() # 在Author表中主键为2的纪录
egon=Author.objects.filter(name="alex").first() # 在Author表中主键为1的纪录 # 绑定多对多关系,即向关系表book_authors中添加纪录
book_obj.authors.add(yuan,egon) # 将某些特定的 model 对象添加到被关联对象集合中。 ======= book_obj.authors.add(*[])
数据库表纪录生成如下:
book表

book_authors表

核心:book_obj.authors.all()是什么?
多对多关系其它常用API:
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[])
book_obj.authors.clear() #清空被关联对象集合
book_obj.authors.set() #先清空再设置
关联管理器(RelatedManager)
基于对象的跨表查询
一对多查询(Publish 与 Book)
正向查询(按字段:publish):
# 查询主键为1的书籍的出版社所在的城市
book_obj=Book.objects.filter(pk=).first()
# book_obj.publish 是主键为1的书籍对象关联的出版社对象
print(book_obj.publish.city)
反向查询(按表名:book_set):
publish=Publish.objects.get(name="苹果出版社")
#publish.book_set.all() : 与苹果出版社关联的所有书籍对象集合
book_list=publish.book_set.all()
for book_obj in book_list:
print(book_obj.title)
一对一查询(Author 与 AuthorDetail)
正向查询(按字段:authorDetail):
egon=Author.objects.filter(name="egon").first()
print(egon.authorDetail.telephone)
反向查询(按表名:author):
# 查询所有住址在北京的作者的姓名 authorDetail_list=AuthorDetail.objects.filter(addr="beijing")
for obj in authorDetail_list:
print(obj.author.name)
多对多查询 (Author 与 Book)
正向查询(按字段:authors):
# 金瓶眉所有作者的名字以及手机号 book_obj=Book.objects.filter(title="金瓶眉").first()
authors=book_obj.authors.all()
for author_obj in authors:
print(author_obj.name,author_obj.authorDetail.telephone)
反向查询(按表名:book_set):
# 查询egon出过的所有书籍的名字
author_obj=Author.objects.get(name="egon")
book_list=author_obj.book_set.all() #与egon作者相关的所有书籍
for book_obj in book_list:
print(book_obj.title)
注意:
你可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 FOO_set 的名称。例如,如果 Article model 中做一下更改:
publish = ForeignKey(Book, related_name='bookList')
那么接下来就会如我们看到这般:
# 查询 人民出版社出版过的所有书籍 publish=Publish.objects.get(name="人民出版社")
book_list=publish.bookList.all() # 与人民出版社关联的所有书籍对象集合
基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的 model 为止。
关键点:正向查询按字段,反向查询按表名。
一对多查询
# 练习1: 查询苹果出版社出版过的所有书籍的名字与价格(一对多)
# 正向查询 按字段:publish
queryResult=Book.objects
.filter(publish__name="苹果出版社")
.values_list("title","price")
# 反向查询 按表名:book
queryResult=Publish.objects
.filter(name="苹果出版社")
.values_list("book__title","book__price")
多对多查询
# 练习2: 查询alex出过的所有书籍的名字(多对多)
# 正向查询 按字段:authors:
queryResult=Book.objects
.filter(authors__name="yuan")
.values_list("title")
# 反向查询 按表名:book
queryResult=Author.objects
.filter(name="yuan")
.values_list("book__title","book__price")
混合使用
# 练习3: 查询人民出版社出版过的所有书籍的名字以及作者的姓名
# 正向查询
queryResult=Book.objects
.filter(publish__name="人民出版社")
.values_list("title","authors__name")
# 反向查询
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("book__title","book__authors__age","book__authors__name")
# 练习4: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称
queryResult=Book.objects
.filter(authors__authorDetail__telephone__regex="")
.values_list("title","publish__name")
注意:
反向查询时,如果定义了related_name ,则用related_name替换表名,例如:
publish = ForeignKey(Blog, related_name='bookList')
练习1: 查询人民出版社出版过的所有书籍的名字与价格(一对多)
# 反向查询 不再按表名:book,而是related_name:bookList queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("bookList__title","bookList__price")
第二十篇ORM查询与SQL语句的更多相关文章
- Python开发【第二十篇】:缓存
Python开发[第二十篇]:缓存redis&Memcache 点击这里 Python之路[第九篇]:Python操作 RabbitMQ.Redis.Memcache.SQLAlchemy ...
- MySql实现分页查询的SQL,mysql实现分页查询的sql语句 (转)
http://blog.csdn.net/sxdtzhaoxinguo/article/details/51481430 摘要:MySQL数据库实现分页查询的SQL语句写法! 一:分页需求: 客户端通 ...
- MySql实现分页查询的SQL,mysql实现分页查询的sql语句(转)
http://blog.csdn.net/sxdtzhaoxinguo/article/details/51481430 摘要:MySQL数据库实现分页查询的SQL语句写法! 一:分页需求: 客户端通 ...
- MySQL5.6 怎样优化慢查询的SQL语句 -- 慢日志介绍
近期有个开发团队抱怨我们平台包括的mysql cluster不行,总是报mysql的"heartbeat Error".分析了他们收集的日志.没有发现mysql cluster节点 ...
- Python之路【第二十篇】:待更新中.....
Python之路[第二十篇]:待更新中.....
- ASP.NET实现列表页连接查询 拼接sql语句 绑定grivdView
ASP.NET实现列表页连接查询 拼接sql语句 如图效果: 基本需求:1.当页面第一次加载的时候默认查询一个月时间(或者说是登陆者所属权限的所有数据)的数据绑定到gridView 2.添加查询条件时 ...
- 查询拼接SQL语句,多条件模糊查询
多条件查询,使用StringBuilder拼接SQL语句,效果如下: 当点击按钮时代码如下: private void button1_Click(object sender, EventArgs e ...
- oracle数据库查询日期sql语句(范例)、向已经建好的表格中添加一列属性并向该列添加数值、删除某一列的数据(一整列)
先列上我的数据库表格: c_date(Date格式) date_type(String格式) 2011-01-01 0 2012-03-07 ...
- mysql按年度、季度、月度、周、日统计查询的sql语句
本文介绍一些mysql中用于查询的sql语句,包括按年度.季度.月度.周.日统计查询等,有需要的朋友,可以参考下. 一.年度查询 查询 本年度的数据 SELECT * FROM blog_arti ...
随机推荐
- 2_04_MSSQL课程_查询_类型转换、表联合、日期函数、字符串函数
类型转换 Convert(目标类型,转换的表达式,格式规范) Cast(表达式 as 类型) select Convert(nvarchar(32)),CustomerId))+Title from ...
- .net高手:forms验证中中<forms loginUrl="" defaultUrl="">defaulturl和loginurl的区别
.net高手:forms验证中中<forms loginUrl="" defaultUrl="">defaulturl和loginurl的区别 d ...
- 「NOIP2016」愤怒的小鸟
传送门 Luogu 解题思路 首先这个数据范围十分之小啊. 我们考虑预处理出所有可以带来贡献的抛物线 三点确定一条抛物线都会噻 然后把每条抛物线可以覆盖的点状压起来,然后状压DP随便转移就好了. 有一 ...
- 2018--Linux面试题
1.企业场景面试题:buffer与Cache的区别. 2.企业场景面试题:redhat与CentOS的区别. 3.企业场景面试题: 描述RAID 0 1 5 10的特点. 4.企业场景面试题:32位 ...
- gpg加密和解密
linux:gpg加密和解密 1 创建密钥 2 查看私钥 3 导出公钥 4 导出私钥 5 导入秘钥 5.1 公钥 6 公钥加密 7 私钥解密 创建密钥 gpg --gen-key 你要求输入一下内容, ...
- springboot整合quartz并持久化到数据库
首先,这里的持久化是是如果当服务器宕机时,任务还在为我们保存.并且在启动服务器之后仍然可以自动执行 一.创建quartz 建表语句mysql的,quartz 2.3.0版本 DROP TABLE IF ...
- HTML中用自定义字体实现小图标icon(不是原作, 只是一个研究笔记)
最近在做一个项目时, 研究了一下新浪微博的前端, 看到首页中那个图标了吗, 以前看到这类效果的第一反应就是用一个gif之类的图标做出来!! 但在研究的过程, 发现了一个小技巧, 注意那个em标签中的文 ...
- xilinx FPGA课程学习总结
一时冲动,跑步进入了FPGA的大门,尤老师是教练,我之前一直做嵌入式软件,数字电路也是十年前大学课堂学过,早已经还给老师了.FPGA对于我来说完全是小白,所以.老师的课程,对于我来说至关重要!因为见过 ...
- python 文件与文件夹相关
1.判断文件夹是否存在,不存在则创建文件夹: if not os.path.exists(path): os.makedirs(path) 2.判断文件是否存在,存在就删除: os.path.exis ...
- 【转载】UnityWebRequest的初步使用及常用方法解析
文章来源:https://blog.csdn.net/qwe25878/article/details/85051911#_35 今天,来学习一下Unity新的网络请求方式UnityWebReques ...