zookeeper3台机器集群环境的搭建
三台机器zookeeper的集群环境搭建
Zookeeper 集群搭建指的是 ZooKeeper 分布式模式安装。 通常由 2n+1
台 servers 组成。 这是因为为了保证 Leader 选举(基于 Paxos 算法的实
现) 能过得到多数的支持,所以 ZooKeeper 集群的数量一般为奇数。
Zookeeper 运行需要 java 环境, 所以需要提前安装 jdk。 对于安装
leader+follower 模式的集群, 大致过程如下:
- 配置主机名称到 IP 地址映射配置
- 修改 ZooKeeper 配置文件
- 远程复制分发安装文件
- 设置 myid
- 启动 ZooKeeper 集群
如果要想使用 Observer 模式,可在对应节点的配置文件添加如下配置:
peerType=observer
其次,必须在配置文件指定哪些节点被指定为 Observer,如:
server.1:localhost:2181:3181:observer
|
服务器IP |
主机名 |
myid的值 |
|
192.168.52.100 |
node01 |
1 |
|
192.168.52.110 |
node02 |
2 |
|
192.168.52.120 |
node03 |
3 |
第一步:下载zookeeeper的压缩包,下载网址如下
http://archive.apache.org/dist/zookeeper/
我们在这个网址下载我们使用的zk版本为3.4.9
下载完成之后,上传到我们的linux的/export/softwares路径下准备进行安装
第二步:解压
解压zookeeper的压缩包到/export/servers路径下去,然后准备进行安装
cd /export/softwares
tar -zxvf zookeeper-3.4.9.tar.gz -C ../servers/

第三步:修改配置文件
第一台机器修改配置文件
cd /export/servers/zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg
mkdir -p /export/servers/zookeeper-3.4.9/zkdatas/
vim zoo.cfg
dataDir=/export/servers/zookeeper-3.4./zkdatas autopurge.snapRetainCount= autopurge.purgeInterval= server.=node01:: server.=node02:: server.=node03::
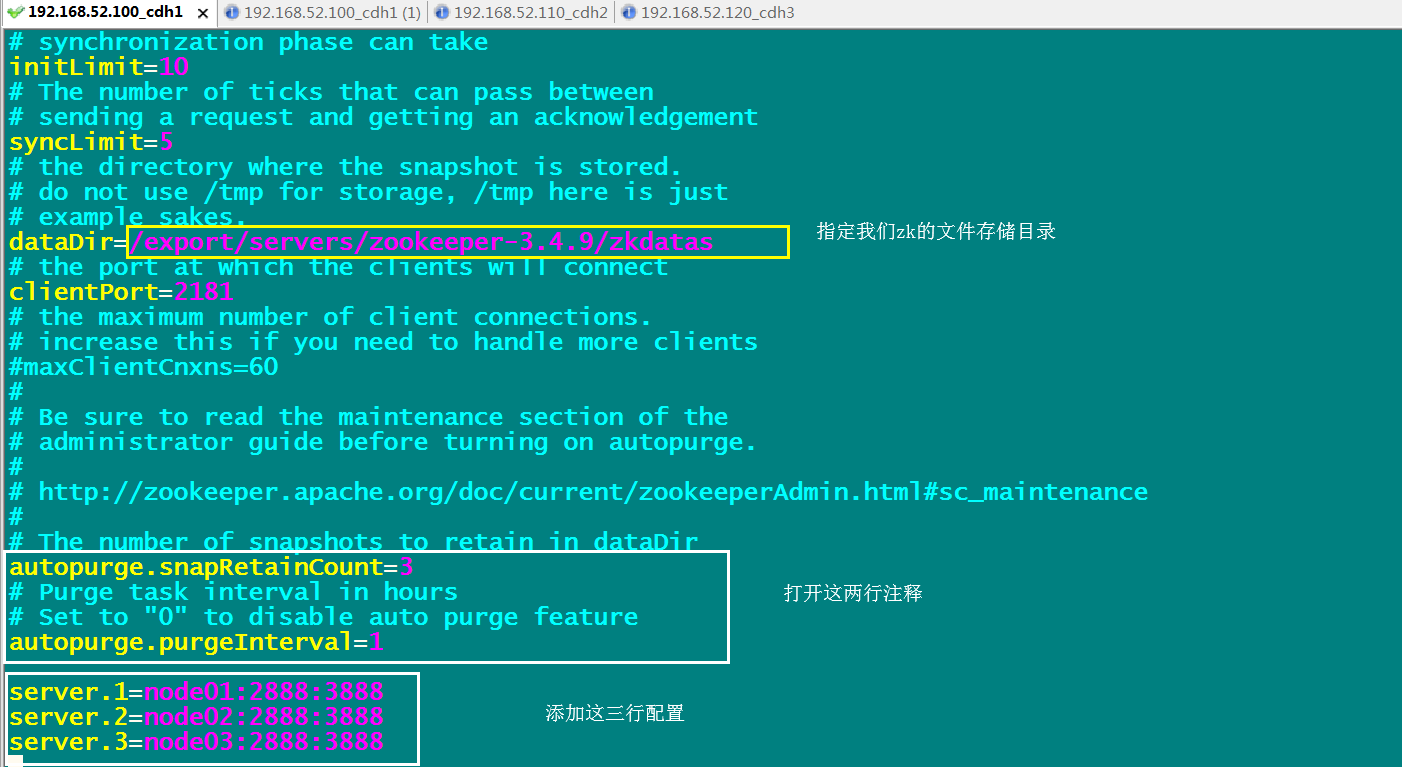
第四步:添加myid配置
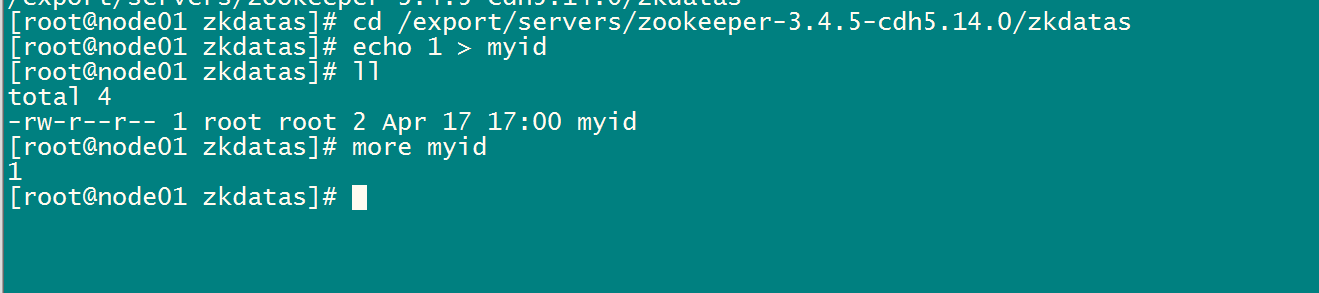
在第一台机器的
/export/servers/zookeeper-3.4.9/zkdatas/这个路径下创建一个文件,文件名为myid ,文件内容为1
echo > /export/servers/zookeeper-3.4./zkdatas/myid
第五步:安装包分发并修改myid的值
安装包分发到其他机器
第一台机器上面执行以下两个命令
scp -r /export/servers/zookeeper-3.4./ node02:/export/servers/ scp -r /export/servers/zookeeper-3.4./ node03:/export/servers/
第二台机器上修改myid的值为2
echo 2 > /export/servers/zookeeper-3.4.9/zkdatas/myid

第三台机器上修改myid的值为3
echo > /export/servers/zookeeper-3.4./zkdatas/myid

第六步:三台机器启动zookeeper服务
三台机器启动zookeeper服务
这个命令三台机器都要执行
/export/servers/zookeeper-3.4./bin/zkServer.sh start
查看启动状态
/export/servers/zookeeper-3.4./bin/zkServer.sh status
zookeeper3台机器集群环境的搭建的更多相关文章
- Nacos集群环境的搭建与配置
Nacos集群环境的搭建与配置 集群搭建 一.环境: 服务器环境:CENTOS-7.4-64位 三台服务器IP:192.168.102.57:8848,192.168.102.59:8848,192. ...
- Linux下Hadoop2.7.3集群环境的搭建
Linux下Hadoop2.7.3集群环境的搭建 本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安 ...
- centos6.5环境下zookeeper-3.4.6集群环境部署及单机部署详解
centos6.5环境下Zookeeper-3.4.6集群环境部署 [系统]Centos 6.5 集群部署 [软件]准备好jdk环境,此次我们的环境是open_jdk1.8.0_101 zookeep ...
- hadoop集群环境的搭建
hadoop集群环境的搭建 今天终于把hadoop集群环境给搭建起来了,能够运行单词统计的示例程序了. 集群信息如下: 主机名 Hadoop角色 Hadoop jps命令结果 Hadoop用户 Had ...
- redis集群环境的搭建和错误分析
redis集群环境的搭建和错误分析 redis集群时,出现的几个异常问题 09 redis集群的搭建 以及遇到的问题
- ElasticSearch 5.2.2 集群环境的搭建
在之前 ElasticSearch 搭建好之后,我们通过 elasticsearch-header 插件在查看 ES 服务的时候,发现 cluster-health 显示的是 YELLOW. Why? ...
- 基于原生态Hadoop2.6 HA集群环境的搭建
hadoop2.6 HA平台搭建 一.条件准备 软件条件: Ubuntu14.04 64位操作系统, jdk1.7 64位,Hadoop 2.6.0, zookeeper 3.4.6 硬件条件 ...
- Linux下Hadoop2.6.0集群环境的搭建
本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安装与配置 现在直接到Oracle官网(http:/ ...
- Linux下Hadoop2.7.1集群环境的搭建(超详细版)
本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 一.基础环境 ...
随机推荐
- Qt:代码里存在中文时带来的问题
一.报错: 常量中有换行符 方法1: 把文本文件转化为unicode或者utf-8, 同是还要带上QString::fromLocal8Bit() 还有其他方法,感觉不靠谱 二.显示异常:乱码 QSt ...
- mysql类型转换函数convert与cast的用法,及SQL server的区别
首先,convert函数 字符集转换 : CONVERT(xxx USING gb2312) 类型转换和SQL Server一样,不过类型参数上有不同: CAST(xxx AS 类型) ...
- JMeter Http请求之content-type用法
转载自https://www.cnblogs.com/imyalost/p/6726795.html 本文讲三种content-type以及在Jmeter中对应的参数输入方式 第一部分:目前工作中涉及 ...
- C#接口的作用实例解析
一.接口的作用: 我们定义一个接口: public interface IBark { void Bark(); } 1. 再定义一个类,继承于IBark,并且必需实现其中的Bark()方法 pub ...
- [CQOI2014]数三角形 题解(找规律乱搞)
题面 其实这道题不用组合数!不用容斥! 只需要一个gcd和无脑找规律(滑稽 乍一看题目,如果单纯求合法三角形的话情况太多太复杂,我们可以从局部入手,最终扩展到整体. 首先考虑这样的情况: 类似地,我们 ...
- python中的缓存技术
python缓存技术 def console(a,b): print('进入函数') return (a,b) print(console(3,'a')) print(console(2,'b')) ...
- C++——extern
1.当它与"C"一起连用时,如: extern "C" void fun(int a, int b);则告诉编译器在编译fun这个函数名时按着C的规则去翻译相应 ...
- 20140702 赋值构造函数的形参为什么一定用引用。string类的赋值运算函数的注意点
1.复制构造函数为什么一定要用引用,而不是用值 类名::复制构造函数(类名&引用名) 传递引用,可以避免复制,如果一个数据相当大的化,进行复制会浪费很多时间的. 类名::复制构造函数(类名 变 ...
- HBase1.0.0 实现数据增删查
HBase1.0.0 即Hadoop 2.6 采用maven 的方式实现HBase数据简单操作 import java.io.IOException; import java.util.ArrayLi ...
- JDK8新特性之函数式接口
什么是函数式接口 先来看看传统的创建线程是怎么写的 Thread t1 = new Thread(new Runnable() { @Override public void run() { Syst ...