Hadoop学习之路(9)ZooKeeper安装
文章目录
1、环境准备
1.1下载zooKeeper
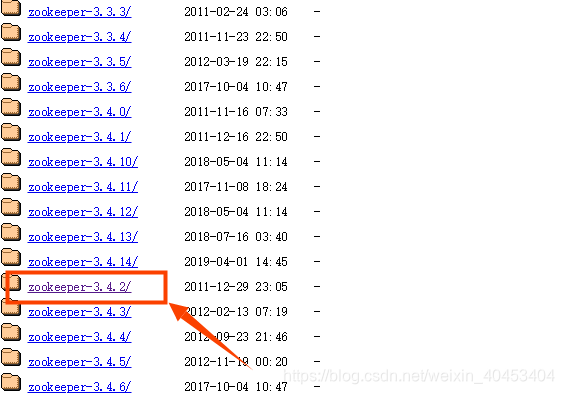
查阅hadoop2.7.3的文档我们可以看到hadoop2.7.3在搭建高可用的时候使用的是zookeeper-3.4.2版本,所以我们也按照hadoop官网的提示,接下来我们安装zookeeper-3.4.2版本.进入官网下载ZooKeeper3.4.2版本
官网地址:https://zookeeper.apache.org/
点击Download

1.3安装zooKeeper
#1.把zookeeper的压缩安装包解压到/opt/bigdata/目录下
[root@node1 ~]# tar -xzvf zookeeper-3.4.2.tar.gz -C /opt/bigdata/ #输入完命令后回车
#2.切换到bigdata目录下
[root@node1 ~]# cd /opt/bigdata/
#3.按照安装hadoop的方式,将zookeeper的安装目录的所属组修改为hadoop:hadoop
#修改zookeeper安装目录的所属用户和组为hadoop:hadoop
[root@node1 bigdata]# chown -R hadoop:hadoop zookeeper-3.4.2/
#4.修改zookeeper安装目录的读写权限
[root@node1 bigdata]# chmod -R 755 zookeeper-3.4.2/
1.4配置zooKeeper环境变量
#1.切换到hadoop用户目录下
[root@node1 bigdata]# su - hadoop
Last login: Thu Jul 18 16:07:39 CST 2019 on pts/0
[hadoop@node1 ~]$ cd /opt/bigdata/zookeeper-3.4.2/
[hadoop@node1 zookeeper-3.4.2]$ cd ..
[hadoop@node1 bigdata]$ cd ~
#2.修改hadoop用户下的环境变量配置文件
[hadoop@node1 ~]$ vi .bash_profile
# Get the aliases and functions
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
HADOOP_HOME=/opt/bigdata/hadoop-2.7.3
SPARK_HOME=/opt/spark-2.4.3-bin-hadoop2.7
M2_HOME=/opt/apache-maven-3.0.5
#3.新增zookeeper的环境变量ZOOKEEPER_HOME
ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.2/
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$M2_HOME/bin
#4.将zookeeper的环境变量ZOOKEEPER_HOME加入到path中
PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin:$ZOOKEEPER_HOME/bin
export JAVA_HOME
export HADOOP_HOME
export M2_HOME
export SPARK_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
#5.导出zookeeper环境变量
export ZOOKEEPER_HOME
#6.保存修改内容
:wq! #记得回车
#7.使得环境变量生效
[hadoop@node1 ~]$ source .bash_profile
#8.输入zk然后按键盘左侧的Tab键
[hadoop@node1 ~]$ zk
#有如下的提示,表名zookeeper的配置完成
zkCleanup.sh zkCli.cmd zkCli.sh zkEnv.cmd zkEnv.sh zkServer.cmd zkServer.sh
[hadoop@node1 ~]$ zk
1.5 修改zookeeper集群配置文件
将目录切换到zookeeper的安装目录下的conf目录下复制zoo_sample.cfg文件为zoo.cfg
[hadoop@node1 ~]$ cd /opt/bigdata/zookeeper-3.4.2/conf/
[hadoop@node1 conf]$ ll
total 12
-rwxr-xr-x 1 hadoop hadoop 535 Dec 22 2011 configuration.xsl
-rwxr-xr-x 1 hadoop hadoop 2161 Dec 22 2011 log4j.properties
-rwxr-xr-x 1 hadoop hadoop 808 Dec 22 2011 zoo_sample.cfg
#1.复制zoo_sample.cfg模板配置文件为正式的配置文件zoo.cfg
[hadoop@node1 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@node1 conf]$ ll
total 16
-rwxr-xr-x 1 hadoop hadoop 535 Dec 22 2011 configuration.xsl
-rwxr-xr-x 1 hadoop hadoop 2161 Dec 22 2011 log4j.properties
-rwxr-xr-x 1 hadoop hadoop 808 Jul 19 11:20 zoo.cfg
-rwxr-xr-x 1 hadoop hadoop 808 Dec 22 2011 zoo_sample.cfg
[hadoop@node1 conf]$
修改dataDir的值为 dataDir=/var/lib/zookeeper,在文件的末尾添加如下配置:
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
修改完配置文件记得保存
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/var/lib/zookeeper
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
开课吧
kaikeba.com
精选领域名师,只为人才赋能 6
1.6 创建myid文件
在节点node1,node2,node3对应的/var/lib/zookeeper目录下(dataDir配置的目录/var/lib/zookeeper)创建myid文
件,几个文件内容依次为1,2,3
如下图我们切换到root用户,在/var/lib目录下创建zookeeper目录,因为hadoop用户对/var/lib目录没有写权限,
所以我们在创建zookeeper目录时需要切换到root用户(拥有最大权限)
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
#修改完配置文件记得保存
1.6 创建myid文件
在节点node1,node2,node3对应的/var/lib/zookeeper目录下(dataDir配置的录/var/lib/zookeeper)创建myid文件,几个文件内容依次为1,2,3。切换到root用户,在/var/lib目录下创建zookeeper目录,因为hadoop用户对/var/lib目录没有写权限,所以我们在创建zookeeper目录时需要切换到
root用户(拥有最大权限)
[hadoop@node1 conf]$ vi zoo.cfg
#1.切换到root用户
[hadoop@node1 conf]$ su - root
Password:
Last login: Fri Jul 19 10:53:59 CST 2019 from 192.168.200.1 on pts/0
#2.创建zookeeper目录
[root@node1 ~]# mkdir -p /var/lib/zookeeper
#3.进入到/var/lib/zookeeper/目录
[root@node1 ~]# cd /var/lib/zookeeper/
You have new mail in /var/spool/mail/root
#4.创建myid配置文件
[root@node1 zookeeper]# touch myid
#5.编辑myid文件,输入1,我们目前编辑的是node1的节点的myid文件,node2的myid内容为2,node3的myid内容为3
[root@node1 zookeeper]# vi myid
You have new mail in /var/spool/mail/root
#6.查看一下myid文件内容为1
[root@node1 zookeeper]# cat myid
1
You have new mail in /var/spool/mail/root
1.7 修改myid目录权限
#1.配置完成后记得修改zookeeper目录的所属组和读写权限
[root@node1 zookeeper]# cd ..
You have new mail in /var/spool/mail/root
#2.修改zookeeper目录所属组
[root@node1 lib]# chown -R hadoop:hadoop zookeeper/
#3.修改zookeeper目录的读写权限为755
[root@node1 lib]# chmod -R 755 zookeeper/
[root@node1 lib]#
2、复制zookeeper
#1.复制/var/lib目录下的zookeeper目录到node2和node3的/var/lib目录下
[root@node1 lib]# scp -r zookeeper node2:$PWD
[root@node1 lib]# scp -r zookeeper node3:$PWD
#2.复制zookeeper安装目录到node2和node3的安装目录下/opt/bigdata目录下
[root@node1 lib]# scp -r /opt/bigdata/zookeeper-3.4.2/ node2:/opt/bigdata/
[root@node1 lib]# scp -r /opt/bigdata/zookeeper-3.4.2/ node3:/opt/bigdata/
3、修改node2和node3节点zookeeper的相关目录权限
修改node2节点zookeeper 相关目录权限
#1.修改zookeeper的myid配置目录所属组和读写权限
[root@node2 lib]# cd ~
[root@node2 ~]# chown -R hadoop:hadoop /var/lib/zookeeper
[root@node2 ~]# chmod -R 755 /var/lib/zookeeper
#2.修改zookeeper安装目录所属组和读写权限
[root@node2 ~]# chown -R hadoop:hadoop /opt/bigdata/zookeeper-3.4.2/
You have new mail in /var/spool/mail/root
[root@node2 ~]# chmod -R 755 /opt/bigdata/zookeeper-3.4.2/
[root@node2 ~]#
修改node3节点zookeeper 相关目录权限
#1.修改zookeeper的myid配置目录所属组和读写权限
[root@node3 bigdata]# cd ~
You have new mail in /var/spool/mail/root
[root@node3 ~]# chown -R hadoop:hadoop /var/lib/zookeeper
[root@node3 ~]# chmod -R 755 /var/lib/zookeeper
#2.修改zookeeper安装目录所属组和读写权限
[root@node3 ~]# chown -R hadoop:hadoop /opt/bigdata/zookeeper-3.4.2/
You have new mail in /var/spool/mail/root
[root@node3 ~]# chmod -R 755 /opt/bigdata/zookeeper-3.4.2/
[root@node3 ~]#
4、修改node2和node3的myid文件内容
修改node2节点zookeeper 的myid内容为2:
[root@node2 ~]# vi /var/lib/zookeeper/myid
You have new mail in /var/spool/mail/root
[root@node2 ~]# cat /var/lib/zookeeper/myid
2
[root@node2 ~]#
修改node3节点zookeeper 的myid内容为3
[root@node3 ~]# vi /var/lib/zookeeper/myid
You have new mail in /var/spool/mail/root
[root@node3 ~]# cat /var/lib/zookeeper/myid
3
[root@node3 ~]#
5、配置node2和node3的zookeeper环境变量
我们在node1节点上直接将hadoop用户的环境变量配置文件远程复制到node2和node3的hadoop用户家目录下
#1.如果当前登录用户是root用户,需要切换到hadoop用户下,如果当前用户是hadoop用户,请将目录切换到hadoop用
户的家目录下,在进行环境变量文件的远程复制.
[root@node1 lib]# su - hadoop
Last login: Fri Jul 19 11:08:44 CST 2019 on pts/0
[hadoop@node1 ~]$ scp .bash_profile node2:$PWD
.bash_profile 100% 681
64.8KB/s 00:00
[hadoop@node1 ~]$ scp .bash_profile node3:$PWD
.bash_profile 100% 681
156.8KB/s 00:00
[hadoop@node1 ~]$
5.1 使得node2和node3的环境变量生效
使得node2的hadoop的环境变量生效
#注意:切换到hadoop用户下
#1.使得环境变量生效
[hadoop@node2 ~]$ source .bash_profile
#2.输入zk然后按键盘左侧的Tab键
[hadoop@node2 ~]$ zk
#3.有如下命令和shell脚本的提示,说明zookeeper的环境变量配置成功.
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
zkCli.cmd zkEnv.cmd zkServer.cmd
[hadoop@node2 ~]$ zk
使得node3的hadoop的环境变量生效
#注意:切换到hadoop用户下
[root@node3 bigdata]# su - hadoop
Last login: Thu Jul 18 15:37:50 CST 2019 on :0
#1.使得环境变量生效
[hadoop@node3 ~]$ source .bash_profile
#2.输入zk然后按键盘左侧的Tab键
[hadoop@node3 ~]$ zk
#3.有如下命令和shell脚本的提示,说明zookeeper的环境变量配置成功.
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
zkCli.cmd zkEnv.cmd zkServer.cmd
[hadoop@node3 ~]$ zk
6.启动zookeeper集群
6.1 启动zookeeper集群
启动zookeeper集群需要手动分别依次在三台机器上启动,启动前需要在三台机器上都将用户切换为hadoop用户.
node1上启动zookeeper
[hadoop@node1 ~]$ zkServer.sh start
JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.2/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@node1 ~]$
node2上启动zookeeper
[hadoop@node2 ~]$ zkServer.sh start
JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.2/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@node2 ~]$
node3上启动zookeeper
[hadoop@node3 ~]$ zkServer.sh start
JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.2/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@node3 ~]$
6.2 查看zookeeper集群状态
使用zkServer.sh status命令在三个节点分别执行查看状态
在node1上查看
[hadoop@node1 bin]$ zkServer.sh status
JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.2/bin/../conf/zoo.cfg
Mode: follower
[hadoop@node1 bin]$
在node2上查看
[hadoop@node2 bin]$ zkServer.sh status
JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.2/bin/../conf/zoo.cfg
Mode: follower
[hadoop@node2 bin]$
在node3上查看
[hadoop@node3 bin]$ zkServer.sh status
JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.2/bin/../conf/zoo.cfg
Mode: leader
[hadoop@node3 bin]$
至此我们zookeeper集群安装完成.
6.3 zooKeeper安装遇到问题
由于按照hadoop2.7.3版本官方文档中使用zookeeper-3.4.2版本,但是zookeeper-3.4.2版本比较低,我们在启动zookeeper后,可以使用jps命令或者ps -ef|grep zookeeper命令查看zookeeper主进程的状态,但是我们发现是正常的,如果我们使用zkServer.sh status命令查看zookeeper的状态却显示是异常的,不管启动多少次都会得到同样的结果。
[hadoop@node1 bin]$ zkServer.sh status
JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.2/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
[hadoop@node2 bin]$ zkServer.sh status
JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.2/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
[hadoop@node3 bin]$ zkServer.sh status
JMX enabled by default
Using config: /opt/bigdata/zookeeper-3.4.2/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
分析主要有以下两个原因造成:
1.centos7上没有安装nc工具.
2.zookeeper启动脚本中的nc命令在不同的linux版本中使用了无效的参数导致获取状态异常或者获取的状态为
空状态导致的。
解决方法:
1.使用yum 在三个节点上分别安装nc工具
yum install nc -y
2.修改zookeeper安装目录下的bin目录下的zkServer.sh脚本文件内容
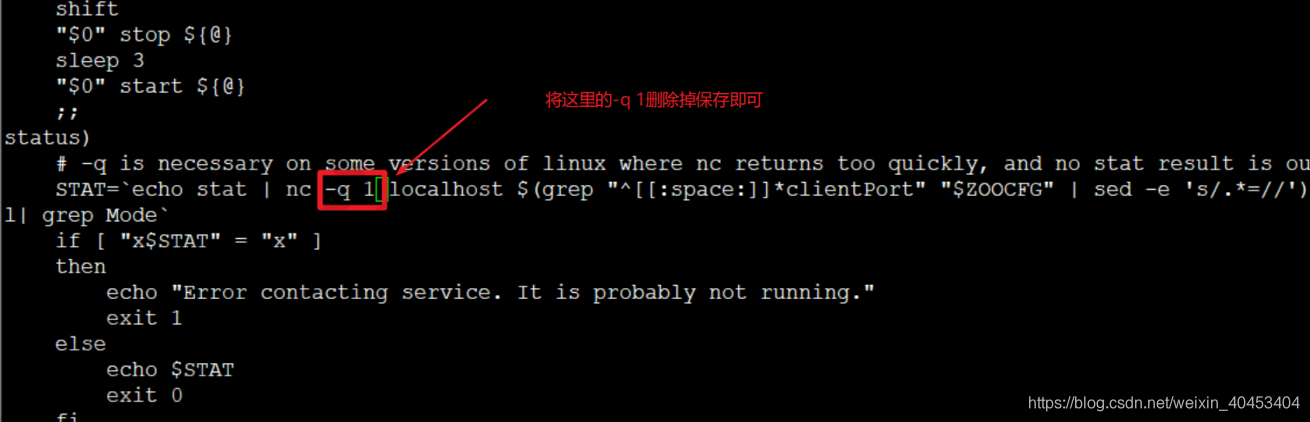
修改完成后我们在使用zkServer.sh status就能看到zookeeper的状态了
Hadoop学习之路(9)ZooKeeper安装的更多相关文章
- hadoop学习之路1--centos7群集安装
一. 安装centos7 1. 设置硬盘为单文件40G.CPU 2核.内存2G.其他默认. 2. 安装时选择gnome,具备操作界面,并增加hadoop的账号. a) ...
- 《Hadoop学习之路》学习实践
(实践机器:blog-bench) 本文用作博文<Hadoop学习之路>实践过程中遇到的问题记录. 本文所学习的博文为博主“扎心了,老铁” 博文记录.参考链接https://www.cnb ...
- 阿里封神谈hadoop学习之路
阿里封神谈hadoop学习之路 封神 2016-04-14 16:03:51 浏览3283 评论3 发表于: 阿里云E-MapReduce >> 开源大数据周刊 hadoop 学生 s ...
- 我的 Delphi 学习之路 —— Delphi 的安装
标题:我的 Delphi 学习之路 -- Delphi 的安装 作者:断桥烟雨旧人伤 1. Delphi 版本的选择 Delphi 版本众多,我该选择哪一个,这确实是个问题,自从 Borland 公司 ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop学习之路(二)Hadoop发展背景
Hadoop产生的背景 1. HADOOP最早起源于Nutch.Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取.索引.查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题—— ...
- 小强的Hadoop学习之路
本人一直在做NET开发,接触这行有6年了吧.毕业也快四年了(6年是因为大学就开始在一家小公司做门户网站,哈哈哈),之前一直秉承着学要精,就一直一门心思的在做NET(也是懒吧).最近的工作一直都和大数据 ...
- 3.Hadoop集群搭建之Zookeeper安装
前期准备 下载Zookeeper 3.4.5 若无特殊说明,则以下操作均在master节点上进行 1. 解压Zookeeper #直接解压Zookeeper压缩包 tar -zxvf zookeepe ...
- 我的hadoop学习之路
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上. Ha ...
随机推荐
- How to make as map two or more device located in the same media pool by using ddboost + nw
How to make as map two or more device located in the same media pool by using ddboost + nw ? That is ...
- 根据navigator.userAgent返回值识别 浏览器
function validBrowser(){ var u_agent = navigator.userAgent; var browser_name='Failed to identify the ...
- Jmeter之上传文件
前言 我们可以利用postman工具来测试上传文件的接口,那么假如要利用Jmeter工具来进行上传接口的测试,又该如何测试呢? 上传文件的接口地址:/pinter/file/api/upload:接口 ...
- pytorch之 sava_reload_model
import torch import matplotlib.pyplot as plt # torch.manual_seed(1) # reproducible # fake data x = t ...
- Linux 下用 superpi 测试 CPU 性能
- 面试官:你说你熟悉jvm?那你讲一下并发的可达性分析
这是why技术的第35篇原创文章 上面这张图是我还是北漂的时候,在鼓楼附近的胡同里面拍的. 那天刚刚下完雨,路过这个地方的时候,一瞬间就被这五颜六色的门板和自行车给吸引了,于是拍下了这张图片.看到这张 ...
- 51nod 1002 数塔取值问题 dp
动态规划 1002 数塔取数问题 1.0 秒 131,072.0 KB 5 分 1级题 一个高度为N的由正整数组成的三角形,从上走到下,求经过的数字和的最大值. 每次只能走到下一层相邻的数上,例如 ...
- NOIP2012-------跳石头(C语言)
#include<stdio.h> ]; int check(long mid, long n, long m) { long last, i, ans; last = a[]; ans ...
- oracle-11g-R2监听文件配置
客户端连接oracle数据库时出现如下错误: Listener refused the connection with the following error: ORA-, TNS:listener ...
- Vue中的递归组件
递归函数我们都再熟悉不过了,也就是函数自己调用自己.递归组件也是类似的,在组件的template内部使用组件自身.那递归组件有什么使用场景呢? 我们都知道树这个数据结构就是一种递归的结构,因此我们可以 ...