python短域名数据分析框架
本文数据源及分析方法均参考《利用python进行数据分析》一书。但我重新对数据分析目标和步骤进行了组织,可以更加清晰的呈现整个挖掘分析流程。
分析对象为美国某短域名网站记录的短域名生成数据(http://1usagov.measuredvoice.com/)。数据基本结构如下,可以看到内容包括所用浏览器和操作系统(’a’)、用户所在时区(’tz’)等信息。
records[0]
#[Out]# {u'a': u'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.78 Safari/535.11',
#[Out]# u'al': u'en-US,en;q=0.8',
#[Out]# u'c': u'US',
#[Out]# u'cy': u'Danvers',
#[Out]# u'g': u'A6qOVH',
#[Out]# u'gr': u'MA',
#[Out]# u'h': u'wfLQtf',
#[Out]# u'hc': 1331822918,
#[Out]# u'hh': u'1.usa.gov',
#[Out]# u'l': u'orofrog',
#[Out]# u'll': [42.576698, -70.954903],
#[Out]# u'nk': 1,
#[Out]# u'r': u'http://www.facebook.com/l/7AQEFzjSi/1.usa.gov/wfLQtf',
#[Out]# u't': 1331923247,
#[Out]# u'tz': u'America/New_York',
#[Out]# u'u': u'http://www.ncbi.nlm.nih.gov/pubmed/22415991'}
分析目标包括:(1)得到各地区用户的数量统计并绘图;(2)得到各地区windows和非windows用户的数量统计并绘图。
针对分析任务1:得到各地区用户的数量统计并绘图
1)从文件读取数据
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
#此处为文件所在路径
path = 'D:\\apython\\usagov_bitly_data2012-03-16-1331923249.txt'
import json
records = [json.loads(line) for line in open(path)]
2)抽取用户时区信息
df = DataFrame(records)
timezones = df['tz'].fillna("missing")
timezones[timezones == ''] = "unknown"
timezones.head(2)
#[Out]# 0 America/New_York
#[Out]# 1 America/Denver
3)汇总统计时区信息
tz_counts = timezones.value_counts()
tz_counts.head(2)
#[Out]# America/New_York 1251
#[Out]# unkown 521
4)利用统计信息绘图
top10 = tz_counts[:10]
top10.plot(kind='barh')
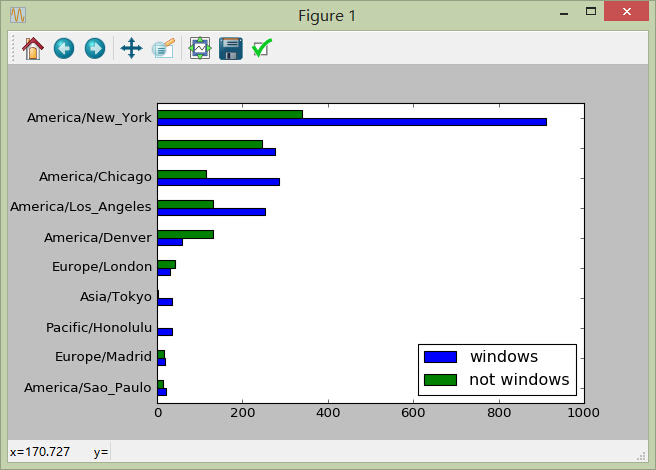
针对分析任务2:得到各地区windows和非windows用户的数量统计并绘图
其中有几个步骤与任务1相同,不再重复介绍,统一标注为“同任务1”。
1)从文件读取数据
同任务1
2)抽取用户时区信息
同任务1
3)抽取操作系统信息
cdf = df[df.a.notnull()]
ops = ['windows' if ('Windows' in x) else 'not windows' for x in cdf['a']]
ops[:10]
#[Out]# ['windows',
#[Out]# 'not windows',
#[Out]# 'windows',
#[Out]# 'not windows',
#[Out]# 'windows',
#[Out]# 'windows',
#[Out]# 'windows',
#[Out]# 'windows',
#[Out]# 'not windows',
#[Out]# 'windows']
4)根据时区、系统信息分组
groups = cdf.groupby(['tz',ops])
groups.size()[:2]
#[Out]# tz
#[Out]# not windows 245
#[Out]# windows 276
5)汇总统计分组后的信息
mgroups = groups.size().unstack()
mgroups = mgroups.fillna(0)
mgroups[:2]
#[Out]# not windows windows
#[Out]# tz
#[Out]# 245 276
#[Out]# Africa/Cairo 0 3
mgroups['sum'] = mgroups.sum(axis = 1)
#获取用户总量前10的地区
tsum10 = mgroups.sort_values('sum')[-10:]
tsum10
#[Out]# not windows windows sum
#[Out]# tz
#[Out]# America/Sao_Paulo 13 20 33
#[Out]# Europe/Madrid 16 19 35
#[Out]# Pacific/Honolulu 0 36 36
#[Out]# Asia/Tokyo 2 35 37
#[Out]# Europe/London 43 31 74
#[Out]# America/Denver 132 59 191
#[Out]# America/Los_Angeles 130 252 382
#[Out]# America/Chicago 115 285 400
#[Out]# 245 276 521
#[Out]# America/New_York 339 912 1251
tsum10 = tsum10.drop('sum', axis = 1)
tsum10
#[Out]# windows not windows
#[Out]# tz
#[Out]# America/Sao_Paulo 20 13
#[Out]# Europe/Madrid 19 16
#[Out]# Pacific/Honolulu 36 0
#[Out]# Asia/Tokyo 35 2
#[Out]# Europe/London 31 43
#[Out]# America/Denver 59 132
#[Out]# America/Los_Angeles 252 130
#[Out]# America/Chicago 285 115
#[Out]# 276 245
#[Out]# America/New_York 912 339
6)利用统计信息绘图
tsum10.plot(kind='barh')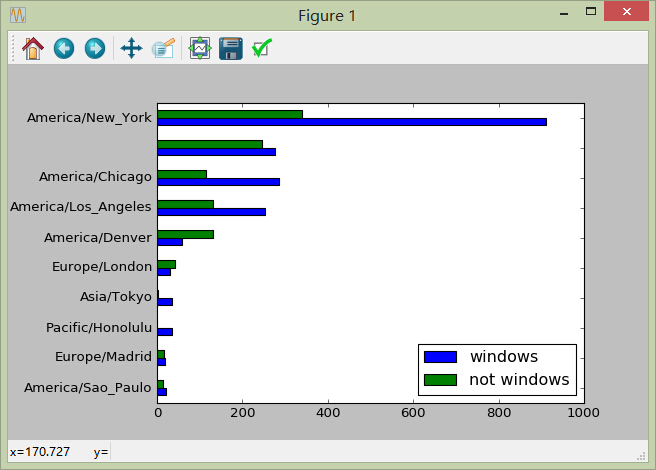
python短域名数据分析框架的更多相关文章
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- Python几种主流框架
从GitHub中整理出的15个最受欢迎的Python开源框架.这些框架包括事件I/O,OLAP,Web开发,高性能网络通信,测试,爬虫等. Django: Python Web应用开发框架 Djang ...
- Python金融大数据分析PDF
Python金融大数据分析(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1CF2NhbgpMroLhW2sTm7IJQ 提取码:clmt 复制这段内容后打开百度网盘 ...
- python三大web框架Django,Flask,Flask,Python几种主流框架,13个Python web框架比较,2018年Python web五大主流框架
Python几种主流框架 从GitHub中整理出的15个最受欢迎的Python开源框架.这些框架包括事件I/O,OLAP,Web开发,高性能网络通信,测试,爬虫等. Django: Python We ...
- Django,Flask,Tornado三大框架对比,Python几种主流框架,13个Python web框架比较,2018年Python web五大主流框架
Django 与 Tornado 各自的优缺点Django优点: 大和全(重量级框架)自带orm,template,view 需要的功能也可以去找第三方的app注重高效开发全自动化的管理后台(只需要使 ...
- 《Python金融大数据分析》高清PDF版|百度网盘免费下载|Python数据分析
<Python金融大数据分析>高清PDF版|百度网盘免费下载|Python数据分析 提取码:mfku 内容简介 唯一一本详细讲解使用Python分析处理金融大数据的专业图书:金融应用开发领 ...
- python金融大数据分析PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:7k4b 内容简介 唯一一本详细讲解使用Python分析处理金融大数据的专业图书:金融应用开发领域从业人员必读. Python凭借其简单.易读.可扩展性以及拥有巨大而活跃的科学计算社区 ...
- Python 什么是flask框架?快速入门
一:Python flask框架 前言 1.Python 面向对象的高级编程语言,以其语法简单.免费开源.免编译扩展性高,同时也可以嵌入到C/C++程序和丰富的第三方库,Python运用到大数据分析. ...
- 3.Python编程语言基础技术框架
3.Python编程语言基础技术框架 3.1查看数据项数据类型 type(name) 3.2查看数据项数据id id(name) 3.3对象引用 备注Python将所有数据存为内存对象 Python中 ...
随机推荐
- 如何开发mis系统--整理
1.含义: 所谓MIS(管理信息系统--Management Information System)系统,主要指的是进行日常事务操作的系统.这种系统主要用于管理需要的记录,并对记录数据进行相关处理,将 ...
- 剑指offer-整数中1出现的次数
题目描述 求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?为此他特别数了一下1~13中包含1的数字有1.10.11.12.13因此共出现6次,但是对于后面问题他就没辙了. ...
- virtualbox 中centOS在不能ssh
这个重要跟虚拟机的网络设置有关系.废话不多说. 针对一个网卡的形式.可以如下进行配置 1.网络-- 连接方式还选择“网络地址转换(NAT)” 其他不变,展开高级,设置端口转发 主机IP设为本机IP, ...
- Oracle中事务处理控制用法
oracle 事物控制包括 COMMINT ROLLBACK SAVEPOINT avepoint是事务内部允许部分rollback的标志符.因为事务中对记录做了修改,我们可以在事务中创建savepo ...
- java继承,final,super,Object类,toString,equals,
Java中的内部类:成员内部类静态内部类方法内部类匿名内部类 内部类的主要作用如下: 1. 内部类提供了更好的封装,可以把内部类隐藏在外部类之内,不允许同一个包中的其他类访问该类 2. 内部类的方法可 ...
- C++ 保留有效小数 保留有效数字
1.需要头文件 #include <iomanip> 2. 要保留两位有效小数 cout<<setiosflags(ios::fixed)<<setprecisio ...
- Java获取路径(getResource)
package com.zhi.test; public class PathTest { public static void main(String[] args) { System.out.pr ...
- laravel注册行为的方法和逻辑
public function register() { //验证: $this->validate(\request(), [ 'name' => 'required|min:3|uni ...
- Win10系列:UWP界面布局进阶5
提示框 在Windows应用商店应用程序中可以使用提示框来向用户显示提示信息,例如可以通过对话框来询问用户当前需要执行的操作,还可以通过弹出窗口来显示需要注意的信息.本节将向读者介绍如何在Window ...
- Javascript this 的一些总结
1.1.1 摘要 相信有C/C++.C#或Java等编程经验的各位,对于this关键字再熟悉不过了.由于Javascript是一种面向对象的编程语言,它和C/C++.C#或Java一样都包含this关 ...