selenium-java web自动化测试工具抓取百度搜索结果实例
selenium-java web自动化测试工具抓取百度搜索结果实例
这种方式抓百度的搜索关键字结果非常容易
抓长尾关键词,根据热门关键词去抓更多内容可以用
抓google,百度的这种内容容易给屏蔽,用这种就不会了
1.新建maven项目,引入selenium-java

<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.8.1</version>
</dependency>
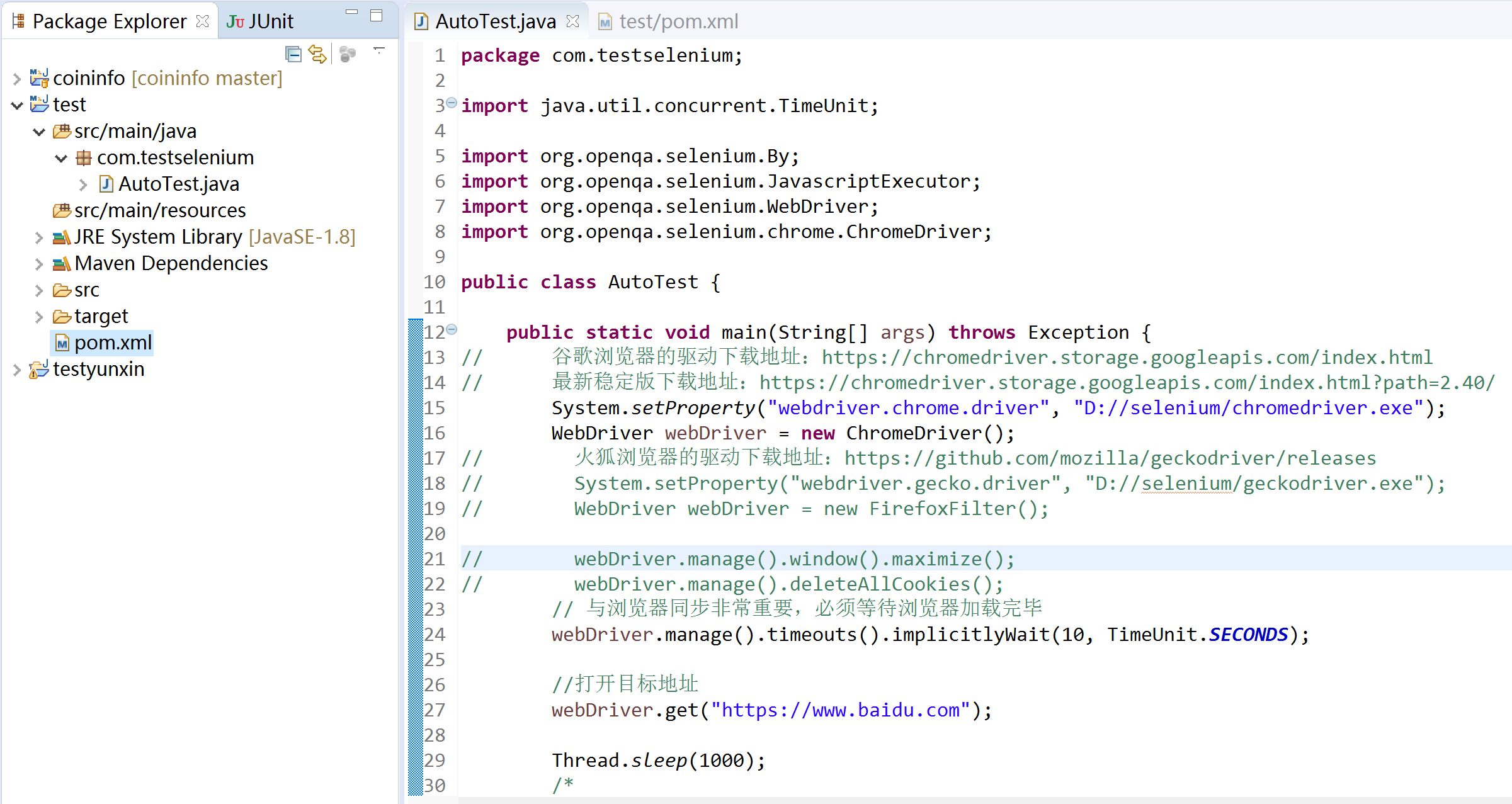
2.写代码(因为自动化测试速度极快,每个步骤后都稍微停顿了下方便看效果)
package com.testselenium; import java.util.concurrent.TimeUnit; import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver; public class AutoTest { public static void main(String[] args) throws Exception {
// 谷歌浏览器的驱动下载地址:https://chromedriver.storage.googleapis.com/index.html
// 最新稳定版下载地址:https://chromedriver.storage.googleapis.com/index.html?path=2.40/
System.setProperty("webdriver.chrome.driver", "D://selenium/chromedriver.exe");
WebDriver webDriver = new ChromeDriver();
// 火狐浏览器的驱动下载地址:https://github.com/mozilla/geckodriver/releases
// System.setProperty("webdriver.gecko.driver", "D://selenium/geckodriver.exe");
// WebDriver webDriver = new FirefoxFilter(); // webDriver.manage().window().maximize();
// webDriver.manage().deleteAllCookies();
// 与浏览器同步非常重要,必须等待浏览器加载完毕
webDriver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS); //打开目标地址
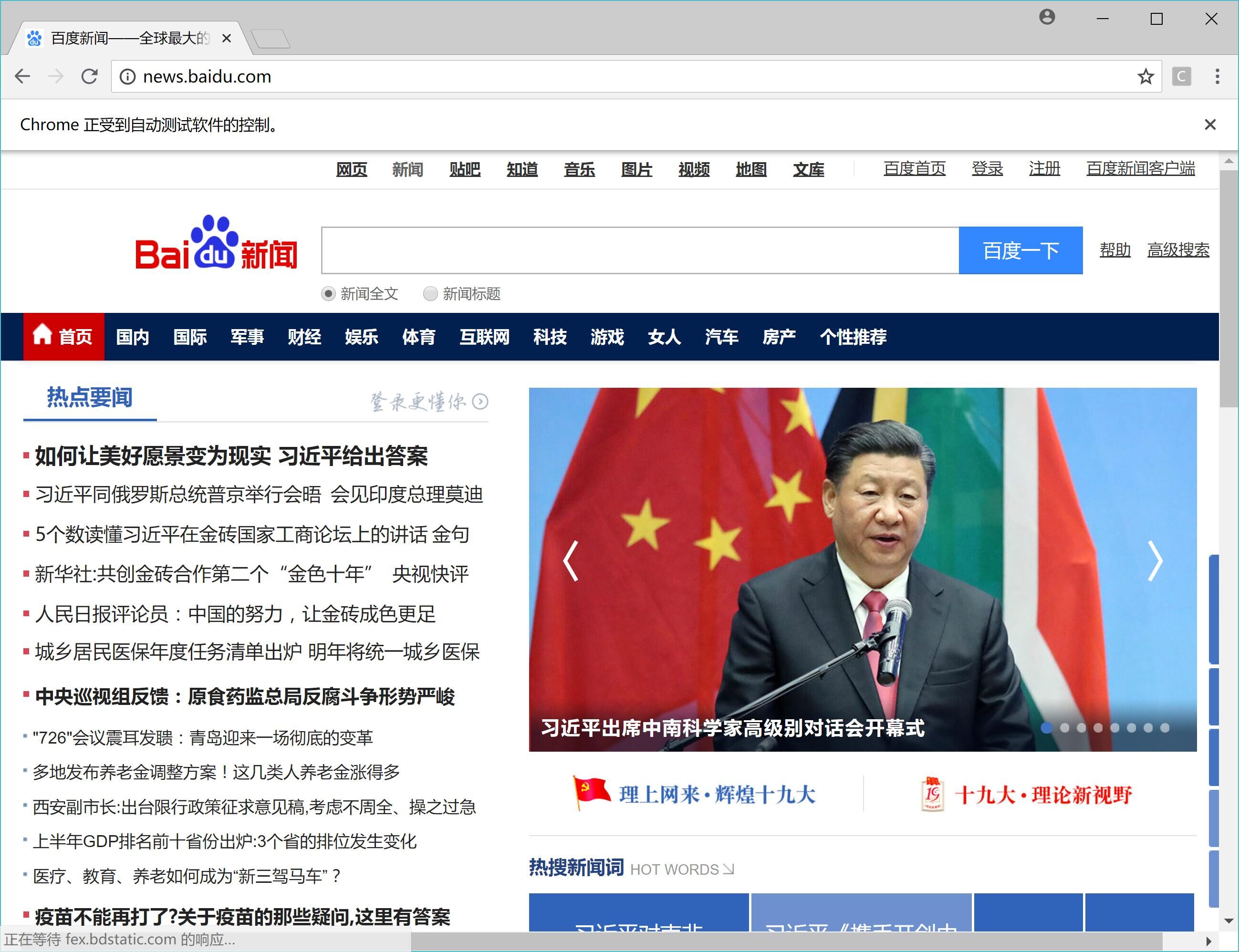
webDriver.get("https://www.baidu.com"); Thread.sleep(1000);
/*
// webDriver.findElement(By.xpath("/html/body/div/div[1]/a")).click();
// webDriver.findElement(By.cssSelector("html body div#app div.loginPage form.el-form.fromBox button.el-button.loginBtn")).click();
webDriver.findElement(By.cssSelector(".head_wrapper > div#u1 > a:nth-child(1)")).click();
Thread.sleep(1000);
webDriver.findElements(By.className("a3")).forEach(x -> {
System.out.println(x.getText());
});
*/
//输入关键字搜索
webDriver.findElement(By.cssSelector("input#kw")).sendKeys("java");
webDriver.findElement(By.cssSelector("input#su")).click();
Thread.sleep(1000);
webDriver.findElements(By.className("t")).forEach(x -> {
System.out.println(x.getText());
}); //暂停5秒钟后关闭
Thread.sleep(5000);
// webDriver.quit(); //跳转到我的博客
Thread.sleep(3000);
webDriver.get("https://www.cnblogs.com/zdz807"); Thread.sleep(1000);
//打开标题为 下一页
webDriver.findElement(By.partialLinkText("下一页")).click(); Thread.sleep(1000);
//移动到底部
//((JavascriptExecutor) webDriver).executeScript("window.scrollTo(0, document.body.scrollHeight)");
//移动到指定的坐标(相对当前的坐标移动)
((JavascriptExecutor) webDriver).executeScript("window.scrollBy(0, 700)");
Thread.sleep(1000);
//移动到窗口绝对位置坐标,如下移动到纵坐标1600像素位置
((JavascriptExecutor) webDriver).executeScript("window.scrollTo(0, 1600)");
Thread.sleep(1000);
//移动到指定元素,且元素底部和窗口底部对齐
((JavascriptExecutor) webDriver).executeScript("arguments[0].scrollIntoView(false);", webDriver.findElement(By.cssSelector("#ftCon"))); //暂停5秒钟后关闭
Thread.sleep(5000);
webDriver.quit(); }
}



Starting ChromeDriver 2.40.565498 (ea082db3280dd6843ebfb08a625e3eb905c4f5ab) on port 38505
Only local connections are allowed.
七月 27, 2018 7:42:47 下午 org.openqa.selenium.remote.ProtocolHandshake createSession
信息: Detected dialect: OSS
java.com: Java 与您官网
Java_百度百科
Java SE Development Kit 8 - Downloads
Java 教程 | 菜鸟教程
java吧_百度贴吧
Oracle Technology Network for Java Developers | Oracle ...
Java - ImportNew
Java 运算符 | 菜鸟教程
ImportNew - 专注Java & Android 技术分享
Java SE - Downloads | Oracle Technology Network | Oracle
深圳java学习难吗_java培训多久能学会?
java 菜鸟也能学的Java 4个月挑战月薪上万
java-中国数万程序员的选择-官方首页
java深圳菜鸟也能学的java 4个月挑战月薪上万
selenium-java web自动化测试工具抓取百度搜索结果实例的更多相关文章
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
- C#+Selenium抓取百度搜索结果前100网址
需求 爬取百度搜索某个关键字对应的前一百个网址. 实现方式 VS2017 + Chrome .NET Framework + C# + Selenium(浏览器自动化测试框架) 环境准备 创建控制台应 ...
- java使用htmlunit工具抓取js中加载的数据
htmlunit 是一款开源的java 页面分析工具,读取页面后,可以有效的使用htmlunit分析页面上的内容.项目可以模拟浏览器运行,被誉为java浏览器的开源实现.这个没有界面的浏览器,运行速度 ...
- 使用轻量级JAVA 爬虫Gecco工具抓取新闻DEMO
写在前面 最近看到Gecoo爬虫工具,感觉比较简单好用,所有写个DEMO测试一下,抓取网站 http://zj.zjol.com.cn/home.html,主要抓取新闻的标题和发布时间做为抓取测试对象 ...
- 使用python抓取百度搜索、百度新闻搜索的关键词个数
由于实验的要求,需要统计一系列的字符串通过百度搜索得到的关键词个数,于是使用python写了一个相关的脚本. 在写这个脚本的过程中遇到了很多的问题,下面会一一道来. ps:我并没有系统地学习过pyth ...
- web自动化测试---自动化脚本设置百度搜索每页显示条数
前面学的都是基础知识,本篇将进入实战练习 以百度“搜索设置”为对象进行测试用例的写作: 百度的搜索设置在首页的“设置”里面,鼠标悬停之后即可显示,如下图红框位置: 测试目标是,修改每页的显示条数为50 ...
- python爬取百度搜索结果ur汇总
写了两篇之后,我觉得关于爬虫,重点还是分析过程 分析些什么呢: 1)首先明确自己要爬取的目标 比如这次我们需要爬取的是使用百度搜索之后所有出来的url结果 2)分析手动进行的获取目标的过程,以便以程序 ...
- 开源Web自动化测试工具Selenium IDE
Selenium IDE(也有简写SIDE的)是一款开源的Web自动化测试工具,它实现了测试用例的录制与回放. Selenium IDE目前版本为 3.6 系列,支持跨浏览器运行,所以IDE的UI从原 ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
随机推荐
- tr 命令
[root@localhost .txt abcdefg [root@localhost .txt |tr [a-z] [A-Z] ABCDEFG // 把文件小写字母变成大写字母
- Laravel删除产品-CRUD之delete(destroy)
上一篇讲了Laravel编辑产品-CRUD之edit和update,现在我们讲一下删除产品,方法和前面的几篇文章类似,照着ytkah来操作吧 1,controller的function destroy ...
- RN animated缩放动画
效果图: 代码: import React, {Component} from 'react'; import { AppRegistry, StyleSheet, Text, Animated, T ...
- FastList使用
之前使用的组件是ListView,当时要添加一个下拉刷新,上拉加载的功能,所以对ListView做了一些封装,但是后来看官方文档,不建议再使用ListView,因为效率问题,做过Android的朋友都 ...
- Emmagee——开源Android性能测试工具
工具:Emmagee作者:孔庆云 网易(杭州)质量保证部 开源地址:https://github.com/NetEase/Emmagee Wiki:https://github.com/NetEase ...
- Redis入门到高可用(九)——无序set
一.结构 特点:无序,无重复,支持集合间操作 二.主要API smembers : 无序:(会阻塞)小心使用,可用sscan代替 spop: 从集合中弹出元素,每次只能弹出一个: 三.实战 抽奖系统 ...
- eclipse快键
工作中经常用到的几个eclipse快捷键 ctrl+alt+箭头下或上-----------------复制当前行 ctrl+q -------------让光标返回最后一次修改的地方 ctrl+d ...
- Html-根据不同的分辨率设置不同的背景图片
@media only screen and (min-width: 1024px) //当分辨率width >= 1024px 时使用1.jpg作为背景图片 { ...
- Object 转 json 工具类
/** * 把数据对象转换成json字符串 DTO对象形如:{"id" : idValue, "name" : nameValue, ...} * 数组对象形如 ...
- [django]modelform实现的多文件上传
实现效果 代码 models.py from django.db import models import uuid class UUIDTools(object): ""&quo ...